«1С:Автоматизированная проверка конфигураций» (АПК) предназначена для автоматизированной проверки конфигураций и расширений конфигурации, разработанных на платформе «1С:Предприятие 8», на соответствие стандартам и иным требованиям технического характера.
АПК существенно расширяет платформенную проверку конфигурации и выполняет статический анализ технического качества конфигураций и расширений в автоматическом режиме, не требуя их запуска. При этом код конфигурации (расширения конфигурации) может быть написан как на русском, так и на английском языках или их сочетании.
Техническое качество решений

Для разработки технически качественных решений на платформе «1С:Предприятие 8» необходимо придерживаться выработанных стандартов и рекомендаций «Системы стандартов и методик разработки конфигураций для платформы 1С:Предприятие 8». Эти стандарты предполагают соблюдение правил разработки конфигураций на платформе «1С:Предприятие 8», в частности, принципов построения архитектуры конфигурации, ее запуска и работы, правил написания кода и правил орфографии в программном коде и текстах.
Регулярное выполнение проверок и исправление найденных ошибок в процессе разработки прикладных решений способствует значительному повышению качества работ, однако выполнение проверок даже небольших конфигураций на постоянной основе вручную бывает проблематично.
Основные возможности
АПК выполняет проверку технического качества конфигураций в следующих вариантах:
Разовая проверка конфигурации на соответствие стандартам разработки
- Разовая автоматическая проверка конфигураций на соответствие актуальным стандартам разработки конфигураций на платформе «1С:Предприятие 8» для получения детального представления о качестве конкретной версии прикладного решения (например, при сертификации на статус «1С:Совместимо»).
Регулярная автоматическая проверка конфигурации на соответствие стандартам разработки
Это рекомендуемый вариант для непрерывной интеграции (CI, англ. Continuous Integration) с целью выявления ошибок и несоответствий стандартам на ранней стадии разработки. Непрерывная интеграция — практика частой сборки и тестирования продукта с целью выявления и устранения ошибок почти сразу же, как только они были привнесены.
Для этого в распоряжении у разработчика есть целый ряд средств:
- Гибкая настройка области и графика проверки:
- проверка конфигурации по расписанию для планирования запуска проверки по определенному удобному графику;
- автоматическое обновление проверяемой конфигурации из сетевого хранилища конфигурации (при коллективной разработке); при этом выполняется инкрементальная проверка только последних измененных объектов, что многократно ускоряет проверку в целом и позволяет выполнять проверки чаще.
- проверка как групп требований, так и отдельных стандартов, в том числе отдельная платформенная проверка конфигурации;
- проверка всех или только указанных объектов конфигурации;
- проверка объектов конфигурации с учетом заданных исключений.
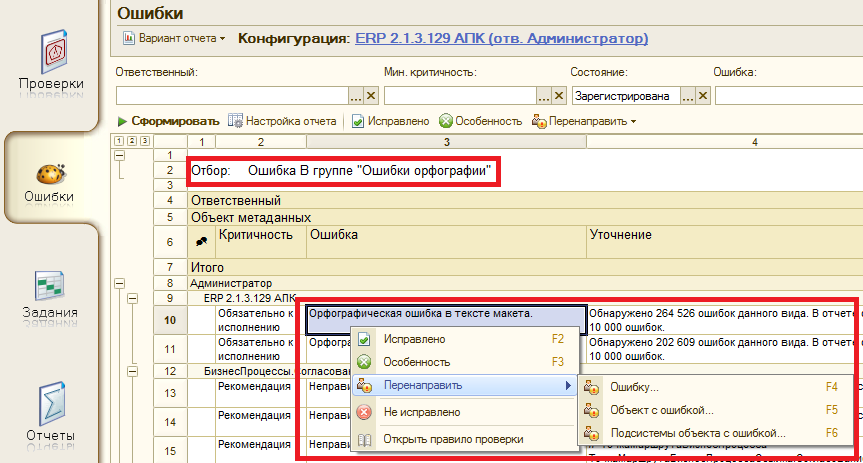
- установка различных состояний ошибок (зарегистрирована, исправлена, особенность);
- учет особенностей, указанных ответственным при проверке конфигурации, и синхронизация их с найденными ошибками при последующих проверках;
- перенаправление ошибок другим ответственным;
- комментирование ошибок и особенностей с целью повышения их информативности;
- дополнение словаря верных слов в случае выявления ложной орфографической ошибки.
Проверка орфографии
Для более тщательной проверки конфигурации на орфографические ошибки и исключения ложных ошибок применяется сервис «Проверка правописания: Яндекс.Спеллер». Орфография проверяется как в именах переменных, параметров, процедур, функций, так и в комментариях в коде, в именах и синонимах метаданных, а также в макетах.
Сервисные возможности
- Выгрузка и загрузка списка ответственных для их переноса между различными конфигурациями в одной или между несколькими базами АПК.
- Выгрузка и загрузка особенностей конфигурации в файл для учета этих особенностей при проверке других конфигураций, основанных на исходной.
- Выгрузка и загрузка словаря верных слов для его актуализации в других базах.
Сравнение качества различных конфигураций
Для сравнения качества можно выполнить проверку нескольких конфигураций в одной информационной базе АПК и построить сводный отчет по выявленным ошибкам в интересующих конфигурациях.
Расширяемость
Предусмотрена возможность разработки собственных правил проверки конфигурации для автоматического контроля внутренних регламентов разработки прикладных решений.
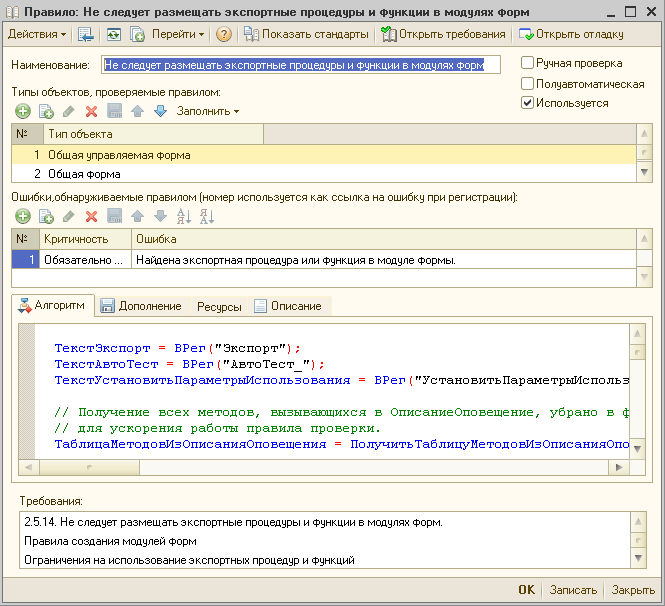
Порядок распространения и использования
Получить дистрибутив финальной версии могут зарегистрированные пользователи системы «1С:Предприятие 8», имеющие действующую подписку на информационно-технологическое сопровождение (ИТС), а также партнеры фирмы «1С».
Дистрибутив финальной версии распространяется следующими способами:
- в составе диска ИТС;
- на сайте поддержки пользователей.
Для использования финальной версии «1С:Автоматизированная проверка конфигураций» необходима платформа «1С:Предприятие 8» версии 8.3.6 и выше.
Приобретение клиентских лицензий специально для работы с данной конфигурацией не требуется. Документация и примеры проверок включены в продукт в электронном виде.
- /
- /
-
Проверка конфигурации 1С с помощью АПК
Вступление
Согласно официальному сайту «1С:Автоматизированная проверка конфигураций» (АПК) предназначена для автоматизированной проверки конфигураций, разработанных на платформе «1С:Предприятие 8», на соответствие стандартам и иным требованиям технического характера.
Ее использование рекомендовано фирмой 1С еще с 2009 года для проверки качества решений, разрабатываемых на платформе 1С. Обязательно используется при получении сертификата «1С Совместимо».
В данной статье мы разберем базовый функционал конфигурации достаточный для полноценной проверки.
Для проведения проверки необходимо сделать 3 основных шага:
1. Добавление данных о проверяемой конфигурации и настройка проверки.
2. Собственно, проведение проверки.
3. Формирование отчета об ошибках.
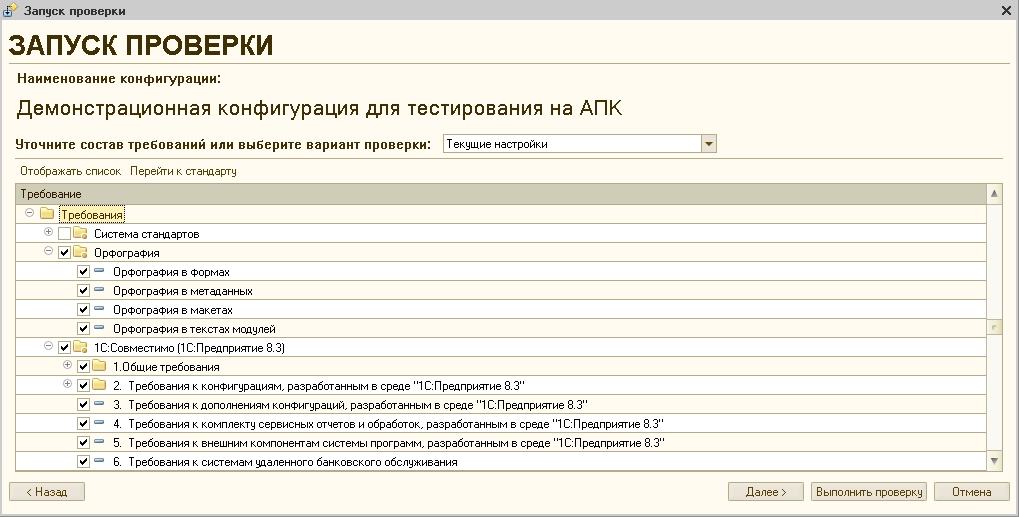
Шаг 1. Проверка кода 1С на соответствие стандартам начинается с добавления данных и настройки проверки
Добавить конфигурацию для проверки можно либо из раздела «Проверки», либо из списка конфигураций (Меню -> Настройки -> Конфигурации).

Заполняем данные проверяемой конфигурации.

На вкладке «Подключения» необходимо указать путь к исполняемому файлу и версию 1с, а также путь к источнику проверки, пользователя и пароль (если есть) для доступа в базу. Источником проверки могут быть файлы конфигурации *.cf, выгрузки базы *.dt, а также хранилище конфигурации или файловая база (проверка серверных баз не поддерживается). После этого можно проверить подключение.
На вкладке «Проверяемые требования» необходимо выбрать состав проверяемых требований, либо отметив их вручную, либо выбрав из списка вариантов проверки. Также необходимо выбрать тип проверки «Конфигурация» или «Библиотека». При выборе варианта «Конфигурация» требования, входящие в подгруппу «Разработка и использование библиотек», будут исключены из проверки вне зависимости от того, выбраны они или нет.

- Вкладка «Исключения из проверки» —настройка отборов объектов для проверки.
- На вкладке «Библиотечные конфигурации» заполняем (если надо) список конфигураций, которые указываются в качестве библиотечных (встроенных в данную конфигурацию).
- Вкладка «Особенности» содержит ошибки, которые были помечены как особенность. Они могут периодически выгружаться в файл. При помещении ошибки в особенность обязательно должна быть указана причина (выбирается из соответствующего справочника).
- На вкладке «Причины особенностей» можно заполнить список причин, используемых для этой конкретной конфигурации.
- Вкладка «Расписание». Здесь можно запланировать запуск проверки конфигурации по определенному расписанию.
- Вкладка «Расширения». На данной вкладке представлен список расширений конфигурации.
Имеет три сценария проверки:
- «Конфигурация (без расширений)» — будет проверяться только конфигурация.
- «Только расширения» — будут проверяться расширения, для которых установлен флаг в списке расширений.
- «Конфигурация и расширения» — будут проверяться конфигурация и расширения, для которых установлен флаг в списке расширений.
Шаг 2. Проверка 1С на ошибки
Выбираем конфигурацию для проверки, либо убеждаемся, что нужная конфигурация уже выбрана, и запускаем проверку.
Здесь возможны два варианта:
- Собрать данные и проверить. В этом случае из источника проверки будет заново считана структура конфигурации.
- Перепроверить по ранее собранным данным – проверка будет проводиться по ранее считанной структуре.
Проверку также можно настроить вручную (требования и объекты), а можно автоматически (настройки будут взяты из настроек конфигурации, сделанных на предыдущем этапе). В зависимости от настроек, величины конфигурации и скорости железа, проверка может проводиться от нескольких секунд до нескольких часов.
В результате данные о проверке добавятся в список проверок этой конфигурации.

Проверка базы 1с 8.3 на ошибки
Шаг3. Проверка кода 1С заканчивается сформированным отчетом об ошибках

На основании этого отчета мы проводим работу над ошибками в конфигурации, отработанная ошибка помечается как исправленная или помещается в особенности (при следующем формировании отчета их уже не будет).
Рассмотрение полного функционала конфигурации – назначение ответственных, отчеты по работе, интеграция с «Системой проектирования прикладных решений» (СППР) и пр. и пр. выходит за рамки данной статьи. Для проведения полноценной проверки, описанного здесь вполне достаточно.
Конечно лучше ознакомиться с системой стандартов 1С и вести разработку так, чтобы минимизировать любые ошибки, чего всем и желаю.
МОЖЕМ ПОМОЧЬ
У вас есть задачи для программистов 1С? Вам сюда

Заголовок в две строки, вот такой заголовок
Далеко-далеко за словесными горами в стране гласных и согласных живут рыбные тексты.
Нажимая на кнопку отправить вы соглашаетесь с политикой конфиденциальности сайта
Заголовок в две строки, вот такой заголовок
Далеко-далеко за словесными горами в стране гласных и согласных живут рыбные тексты.
Оглавление
- Снижение качества кода со временем
- Воспринимаемая сложность кода
- Критерии качественного кода
- Работоспособность
- Покрытие тестами
- Наименования
- Оформление
- Компактность
- Комментирование
- Дублирование
- Качество кода и производительность
- Делаем и сохраняем код качественным
- 1С:Автоматизированная проверка конфигураций
- SonarQube
- Организация процесса работы
- Сложности использования АПК
- Переход на SonarQube
- Очередь за 1C:EDT + SonarQube
- Следить за качеством кода сложно и нет времени
Снижение качества кода со временем
При выпуске программных продуктов и оказании услуг естественным является желание измерить их качество. Понимание того, насколько качественным является продукт, помогает при его продаже и доработках, поскольку жизненно необходимо знать насколько мы соответствуем тому, что можно назвать «хорошо».
В статьях и книгах о качестве кода можно увидеть следующий график зависимости производительности разработки от времени жизни проекта:

© Источник: книга «Чистый код», Роберт Мартин
Падение производительности разработки вызвано тем, что в некачественном коде разработчики «вязнут», как в грязи. Такой код сложен для понимания и требует неоднократного редактирования. Чаще всего нет тестов, поэтому приходится только догадываться, на какие части программы могли повлиять внесенные изменения. В большинстве случаев это приводит к упущенным при тестировании ошибкам. При работе с прикладным кодом 1С мы точно так же можем столкнуться с вышеописанными проблематиками.
Отрезок с производительностью 0 на графике — это «бунт», когда команда говорит: «Мы не можем больше вносить изменения». В этот момент начинается рефакторинг: обновление версии БСП и связанных библиотек, переписывание функциональных блоков, изменение архитектуры. Такой рефакторинг откладывает развитие продукта.
Кроме проблемы производительности, в продуктах с низким качеством кодовой базы «фактор автобуса» равен или стремится к 1.
Фактор автобуса (bus-factor) — это число человек, которое нужно сбить автобусом, чтобы проект перестал развиваться. Хорошим значением является количество участников команды (звучит жестоко, но описывает ситуацию на проекте).
В некоторых командах практикуется назначение ответственного за изменения части программы сотрудника. Никто, кроме него, не способен быстро и правильно вносить изменения в этот функционал. Недоступность такого человека приводит к существенным проблемам.
На первый взгляд кажется, что хорошо быть таким незаменимым человеком. Но по факту такой разработчик становится «заложником» блока. Есть желание развиваться и двигаться дальше, а приходится все время возвращаться назад.
Воспринимаемая сложность кода
Обратимся к картинке ниже, она состоит из большого количества мазков. Наш мозг не может работать с таким количеством объектов одновременно. Он прекрасно справляется с крупными объектами: озеро, цветы, деревья, так как их немного. Если мы сосредоточимся на деталях отдельно взятого цветка, мы сможем разглядеть мазки, из которых он состоит. Однако остальные объекты более не в фокусе нашего внимания.

То же самое и при работе с кодом. Когда пишем код, мы работаем с небольшим количеством объектов одновременно и их состав постоянно меняется. Процесс написания кода выглядит приблизительно следующим образом:
- Нашли фрагмент кода, в котором нужно внести изменение.
- Написали строчку в этой функции.
- Перешли в другую, добавили десять строчек.
- Перешли в третью, удалили пару строк.
- Вернулись в первую, написали еще строчку.
- Проверили, что работает.
- Поместили.
В нашем представлении мы реализовали «красивую картинку».
А в хранилище помещение на две с половиной тысячи строки. И на деле для другого человека это выглядит, как на следующем «шедевре»: высокое искусство, но ничего не понятно. Первый возникающий вопрос: «Что это такое? С какого места начинать разбираться?». Непонятно, сложно.

Еще сложнее, если предложенное решение отличается от привычного нам. Используются неизвестные нам алгоритмы и методики.
По мере профессионального развития мы воспринимаем код по-разному. «Новички» в программировании обычно способны в основном оперировать мелкими сущностями: идентификаторы, операторы и вызовы методов. По мере развития наш мозг тренируется. Насмотревшись на различные варианты реализации одних и тех же алгоритмов, становится проще отстраниться от деталей и перейти на более высокий уровень. Мы перестаем видеть код, а видим объекты и связи между ними.
В процессе обучения разработчик учится не только решать технические проблемы, но и перераспределять сложность кода, закрывая его за функциями обертками, вынося в отдельные модули или комментируя. Есть огромное множество способов перераспределять сложность. Но пока мы им учимся, успеваем написать какое-то количество сложного кода.
Критерии качественного кода
Если спросить 10 начинающих разработчиков: «Что такое качественный код?», они могут перечислить такие характеристики, как
- простой,
- понятный,
- поддерживаемый,
- работающий.
К сожалению, это не больше, чем общие слова. На деле же они не могут дать точный ответ. Когда мы сталкиваемся с хорошим кодом, мы с ним работаем, а он не мешается и не запоминается. Но при этом каждый разработчик запомнит код, который доставил ему боль, и вспомнит его не раз «добрым» словом. Более опытные разработчики говорят приблизительно те же слова, могут еще вспомнить несколько методик разработки, самые популярные на данный момент SOLID и YAGNI.
SOLID набор принципов в объектно-ориентированном программировании, призванный помочь в создании программных систем, которые будет легко поддерживать и расширять в течение долгого времени.
| S | Принцип единственной ответственности (single responsibility principle). Для каждой сущности должна существовать единственная причина для изменения. |
| O | Принцип открытости/закрытости (open–closed principle). Программные сущности должны быть открыты для расширения, но закрыты для модификации. |
| L | Принцип подстановки Лисков (Liskov substitution principle). Объекты в программе должны быть заменяемыми на экземпляры их подтипов без изменения правильности выполнения программы |
| I | Принцип разделения интерфейса (interface segregation principle). Много интерфейсов, специально предназначенных для клиентов, лучше, чем один интерфейс общего назначения |
| D | Принцип инверсии зависимостей (dependency inversion principle). Зависеть нужно от абстракций, а не реализаций. |
Прямые отголоски на SOLID в стандартах 1С найти сложно, но их можно найти в типовых конфигурациях и библиотеках.
Обратим внимание на объект Отчет. Для его построения в платформе используются объекты КомпоновщикМакета, СхемаКомпоновкиДанных, КомпоновщикНастроек, МакетКомпоновкиДанных, ПроцессорКомпоновкиДанных, ПроцессорВывода. Такое разнообразие объектов позволяет легко расширить функционал. Например, процессоров вывода реализовано два: в коллекцию и табличный документ, а замена одного на другой не нарушает всю цепочку. Такое разделение указывает на принципы S и L.
Вся библиотека БСП с большим количеством подсистем и программных интерфейсов для каждой из них, указывает на использование принципов S, I, D.
Хорошим примером принципа D будет подсистема Организации. В каждой конфигурации свой объект Организации и структура его хранения. Получалось, что подсистемы БСП зависели от реализации в типовых конфигурациях. Это усложняет внедрение и обновление функционала. Подсистема Организации реализовывает интерфейс и структуру описывающие абстрактную организацию с предопределенными полями. Что позволяет развернуть зависимость на обратную. БСП зависит от интерфейса и конфигурация зависит от него же, так как его реализует.
YAGNI («You aren’t gonna need it»; с англ. — «Вам это не понадобится») — процесс и принцип проектирования ПО, при котором в качестве основной цели и/или ценности декларируется отказ от избыточной функциональности, — то есть отказ добавления функциональности, в которой нет непосредственной надобности.
SOLID говорит нам, что мы должны быть готовы к предстоящим изменениям, а YAGNI утверждает, что не следует писать лишнего, нужно делать рефакторинг в момент необходимости. Данные методики немного противоречат друг другу. Получается, что за все время развития программирования мы так до конца и не сформулировали, что такое качественный код. Мировая практика показывает, что даже если не известно, как «хорошо», то все равно очевидно, когда «плохо». И отсюда вывод: не будем делать «плохо» и постепенно приблизимся к границе «хорошо».
Практика плохих и хороших решений собрана в системе стандартов разработки на «1С:Предприятие». Стандарты регулярно обновляются и расширяются, так как и сама платформа, и мир вокруг нее развиваются.
Для более детального анализа качества кода можно выделить ряд показателей:
- работоспособность,
- покрытие тестами,
- наименования,
- оформление,
- компактность,
- комментирование,
- дублирование.
Давайте поговорим чуть подробнее о каждом показателе качества кода.
Работоспособность
Статические анализаторы позволяют нам анализировать код, не запуская его. Очень удобно, когда возможности статического анализа встроены в IDE. Тогда подобные ошибки вылавливаются автоматически прямо в момент написания кода.

Покрытие тестами
Покрытие кода тестами позволяет программистам перестать бояться вносить изменения в работающий код. Если будет допущена ошибка, мы сможем сразу ее обнаружить. Боязнь прикоснуться к работающему коду помогает множиться некачественному коду. Программист, вместо того чтобы переписать прежний код, пытается найти «безопасное» место для новых правок. И общая картина начинает превращаться в мозаику.
Абсолютно не важно какой вид тестирования вы используете. Разные тесты подходят в разных ситуациях. У себя мы большинство задач решаем через сценарные тесты. Об этом мы подробнее писали в статье «Подходы к сценарному тестированию на примере 1С:Общепит и 1С:Сценарное тестирование».
Наименования
Один из важнейших аспектов, так как наименования несут самую большую долю информации о коде. Хорошие наименования могут направлять и подсказывать путь в коде, а плохие только забивают слоты для объектов в нашем фокусе внимания. Кажется, очень очевидная вещь: наименования должны быть понятными. В качестве примера можно рассмотреть функцию, выбирающую остатки номенклатуры с названием ПолучитьТаблицуНоменклатуры вместо ОстаткиНоменклатуры.
Плохие наименования ведут к лишним вопросам, на которые приходится тратить время, как на рисунке ниже.

Данный метод выполняет рекурсивный обход цепочки документов и формирует перечень актуальных заказов по определенным правилам, но ничто нам об этом не говорит.
Оформление
Опытные программисты с лёгкостью улавливают закономерности в коде. И если сущности одинаково оформлены, их проще вычленять из текста. Хорошее оформление увеличивает скорость чтения кода в разы.

На приведенных ниже рисунках отформатированный код с рисунка, показанного выше. Мы видим разницу и она несущественна. Но если не вчитываться, код кажется разным. Поэтому, если решили контролировать оформление, очень важно добиваться того, чтобы оно было одинаковым на всем проекте, иначе весь эффект от оформления не раскрывается в полной мере.


Компактность
Компактность говорит нам о том, что по возможности следует сокращать количество строк, не увеличивая сложность кода.
Рассмотрим следующий код:

Такой код допустим и скорее всего получился таким по историческим причинам. Скорее всего, между Иначе и ИначеЕсли было еще несколько блоков ИначеЕсли, которые потом удалили в процессе развития продукта. Этот код можно сократить, не потеряв его функциональности.

Но не следует злоупотреблять. Пустая строка, между разными смысловыми блоками, поможет быстрее прочитать и понять код. А несколько простых конструкций обычно лучше одной сложной.

Операторы ветвления сами по себе сложные, а их вложенность особенно мешает восприятию.

Комментирование
Комментарии перетягивают сложность с кода на себя, облегчая его понимание. Плохие комментарии засоряют код, не неся новой информации. Со временем большинство из нас развивает выборочную слепоту и просто не обращает на них внимание, но для новичков эта проблема стоит довольно остро. Хороший комментарий объясняет не что делает код, а зачем он это делает.
Рассмотрим пример:

Комментарий «Настроим блокировку элементов формы» уже полностью содержится в имени процедуры «Блокировать элементы формы» и его можно безболезненно удалить.
«Дальнейшие операции выполняются только для новых объектов» является констатацией факта — следующий код завершит выполнение обработчика для ранее записанных объектов. Даже неопытный разработчик на платформе сможет сделать такой вывод сам, без нашей подсказки. Но гораздо интереснее ему будет понять, почему здесь прерывается выполнение.

Дублирование
Возникает на проекте по нескольким причинам:
- Работа нескольких программистов над похожими задачами в разных частях проекта.
- Копирование уже существующего участка с внесением минимальных исправлений.
- Лень.
Также встречается дублирование, когда конкретные участки кода отличаются внешне, хотя и выполняют одну и ту же задачу. Такое дублирование бывает довольно сложно обнаружить и исправить.
Это самый спорный из всех пунктов. Кажется, так просто — не должно быть кода, который дублируется. Но сколько ошибок было привнесено из-за того, что один код применялся в местах, изменения в которых выполняются для разных заказчиков по разным причинам и разными людьми. Или строились безумные конструкции огромной вложенности, чтобы устранить дублирование в две строчки кода.
Бороться нужно с явным дублированием. При таком дублировании у кода совпадают назначение, реализация и потребитель.
Качество кода и производительность
Распространенный вопрос: как быть с производительностью программы? Ведь в процессе разработки, для облегчения восприятия код часто пишется не оптимально, что может приводить к замедлению программы. Это важный вопрос, но мы не будем его рассматривать в рамках данной статьи.
Производительность важна для комфортной работы пользователей и нельзя пренебрегать ей, предпочитая качество и чистоту кода в проекте, надеясь на вычислительные мощности современных серверов. Но производительность гораздо проще настраивать на проекте, где заботятся о качестве кода:
- В структурированном коде проще проводить анализ производительности.
- В работе с производительностью важным аспектом является эксперимент. А в качественный код проще и быстрее вносить изменения. Вследствие снижается время затрачиваемое на проверку гипотезы.
Качественный код помогает писать программы быстрее. На первом этапе они медленнее работают, но мы можем быстро привести их к оптимальному состоянию.
Делаем и сохраняем код качественным
Можно долго перечислять инструменты и практики, которые помогут вам работать с качеством кода. Но наиболее эффективно заняться формированием культуры написания качественного кода. Команда должна понимать преимущества достижения результата не только в краткосрочной перспективе, но и в будущем. Такая команда сама добьется качественного кода и усовершенствования процессов разработки на проекте.
Неплохо показала себя практика code review, которая позволяет повысить качество и выполняет образовательную функцию. Бытует мнение, что code review должны выполнять более опытные разработчики по отношению к менее опытным. Но это не совсем так: ревью новичков более опытных разработчиков позволяет под новым углом взглянуть на код, который мы пишем. Понять, где мы усложняем код или используем устаревшие методики и шаблоны разработки.
Для упрощения работы с качеством нам понадобится инструмент для измерения показателей качества, обнаружения ошибок, отслеживания динамики изменений на проекте. В сообществе прижилось два инструмента для этих задач «Автоматизированная проверка качества» и SonarQube.
1С:Автоматизированная проверка конфигураций
Данный продукт предназначен для проверки конфигураций на платформе «1С:Предприятие 8» на соответствие принятым стандартам разработки и иных технических требований.
Отлично подходит для сценария, когда периодически собираются замечания и исправляются с последующей проверкой результата.
Продукт разрабатывался под 1С и в нем предусмотрены ряд моментов свойственным только этой группе продуктов:
- Фильтрация проверяемых объектов по подсистемам.
- Сбор замечаний в разрезе метаданных.
- Назначение ответственных за качество в блоках сотрудников. Такой ответственный не является единоличным владельцем блока, а только следит за поддержанием качества в блок.
- Фильтрация замечаний из библиотечных конфигураций.
Поддерживает работу как с хранилищем конфигураций, dt и cf файлами, так и с выгруженной в файлы конфигурацией.
Выгрузка в файлы поддерживается только в формате конфигуратора.
При выполнении анализа потребляет небольшое количество ресурсов процессора и оперативной памяти, занимает значительное место на жестком диске. Время анализа сильно зависит от размеров конфигурации и может составлять от 30 минут до 16 часов при полной проверке конфигурации. Для ускорения процесса анализа существует возможность проверять только измененные с предыдущей проверки объекты, но это не работает с рядом ошибок и периодически придется делать полный анализ.
Вход в инструмент происходит легко. Эта конфигурация 1С, которая говорит с пользователем на понятных ему терминах. Разобраться, что к чему достаточно просто. Для выполнения первой проверки достаточно заполнить карточку с описанием конфигурации.

После создания карточки нужно создать новую проверку и подождать. После чего можно будет приступить к анализу отчета с ошибками.


Как можно увидеть, в описании ошибки указано описание проблемы, ссылка на стандарт и место обнаружения, но нет контекста. Поэтому для работы с системой нужно постоянно держать открытым список ошибок и переключаться между ним и конфигуратором.
SonarQube
Этот инструмент изначально разрабатывался под другие языки программирования, а поддержка 1С в нем появилась позднее и сейчас активно развивается.
Плагинов для sonarqube несколько. У себя мы используем версию развиваемую сообществом 1c-syntax (https://github.com/1c-syntax/
sonar-bsl-plugin-community). За что хочется сказать отдельное спасибо.
SonarQube позволяет решать задачи по:
- поиску ошибок в конфигурации на основе стандартов и общих принципов разработки;
- расчету показателей качества;
- отслеживанию динамики изменений, связанных с качеством кода на проекте;
- отображению покрытия кода тестами.
SonarQube как и АПК можно использовать для периодического поиска ошибок и их исправления. Но вся мощь инструмента раскрывается при использовании технологии разветвленной разработки.
Технология разветвленной разработки — организация разработки подразумевающая, разработку крупных блоков отдельно от места хранения стабильной версии исходного кода. После разработки и тестирования изменения переносятся в стабильную версию. Если взять за основу разработку на хранилищах, то мы все доработки ведем в отдельных базах/хранилищах, а когда закончим сравнением/объединением переносим в хранилище. Такой вариант разработки призван повысить качество разработки и тестирования, обеспечить непрерывное развитие конфигурации. Но появляются накладные расходы связанные организацией процесса разработки, налаживанием инфраструктуры. Если использовать отличные от хранилищ технологии потребуется в них погружаться.
Нам кажется, что лучше всего подходит система контроля версий git. Можно использовать технологию разветвленной разработки на хранилищах, предлагаемую 1С (https://its.1c.ru/db/v8std/
content/709/hdoc). Но для анализа придется все равно выгружать данные из хранилищ и раскладывать по веткам в git. Так как только при использовании git возможно вычислить автоматически, кто допустил ошибку.
При своей работе инструмент потребляет существенные ресурсы процессора и оперативной памяти. Но скорость его работы высокая, анализ даже самых крупных конфигураций на ограниченных мощностях не превышает 1 часа. Например: анализ ERP на 12 ядрах и 16 Гб оперативной памяти занимает около 20 минут в сонар сканере.
За разнообразие возможностей приходится платить высоким порогом входа. Сначала потребуется разобраться с компонентами самого SonarQube, организовать выгрузку хранилищ в git, организовать запуск анализа выгруженных исходников. Общая схема может например выглядеть так:

Как настроить каждый из этих компонентов в рамках данной статьи описывать не будем. Только рассмотрим их функции.
GitConverter выполняет одностороннюю синхронизацию хранилища конфигурации с репозиторием git. Для хранения центрального git репозитория мы выбрали продукт gitlab.
SonarQube состоит из трех компонентов:
- База данных, мы используем postgresql.
- Sonar Scanner. Выполняет анализ исходного кода. Формирует список ошибок и показателей для ядра. Располагаться должен на одном сервере с анализируемыми данными.
- Сервер SonarQube. Занимается обработкой собранных ошибок и показателей. Записью результатов в базу данных. Взаимодействие с пользователем посредством веб-интерфейса.
Jenkins управляет доставкой исходного кода с gitlab и запуск сканера. Запуск может происходить по расписанию или триггеру (например, изменению исходного кода).
С помощью всех этих инструментов мы выполнили анализ и перешли в SonarQube. На главном экране мы можем почерпнуть информацию о проекте в целом. Количестве ошибок, уязвимостей, дефектов, дублирующихся участках и времени на исправление.

Перейдя к списку проблем можно настроить отображение за счет всевозможных фильтров. Каждой проблеме присваивается пользователь внесший данную проблему в код. Для этого используется история изменений в git. На проблему назначается последний менявший строку кода пользователь.
Из карточки проблемы возможно перейти к ее подробному описанию или посмотреть место расположения ошибки в коде для более детальной оценки.


Все замечания делятся на три основных вида.
К ошибкам относятся проблемы способные привести к выбросу исключения во время работы конфигурации или радикальной потери производительности.


Уязвимости указывают на возможные проблемы с безопасностью.

Дефекты — это самая многочисленная группа замечаний. К ней относится все, что может мешать восприятию кода. Яркий представитель этой группы превышение показателя когнитивной сложности.


С главного экрана проекта можно перейти к отчетам о динамике изменений. Их использование поможет понять в каком состоянии проект, и куда он движется.

Организация процесса работы
На проектах разработки мы попробовали разные подходы к работе с качеством кода.
Сначала использовали АПК. За блоками в конфигурации были закреплены ответственные. Раз в неделю проверяли конфигурацию и все найденное исправляли или отмечали как особенность. Занимало это около трех-четырех часов на разработчика в неделю.
Сложности использования АПК
- Первая сложность связана с тем, что поиск виновника некачественного кода требует времени, поэтому ответственные за блоки разработчики тратили больше времени не на исправление ошибок, а на выявление сотрудника внесшего эти изменения. И порой ответственный исправлял замечание сам, вместо того, чтобы тратить усилия на поиски виноватого. Такой подход приводил к нарастанию напряженности в команде.
- Вторая сложность связана с тем, что процесс перехода к контексту некачественного кода требует времени. К тому же при работе с замечаниями не хватало контекста для определения их актуальности.
- Третья сложность связана с тем, что организовать непрерывный процесс мониторинга некачественного кода практически невозможно. Приходилось «замораживать» состояние конфигурации после анализа, исправлять и далее объединять с рабочей конфигурацией, которая могла за это время значительно уйти вперед. Это связано с тем, что, замечания отмеченные как особенности постоянно возвращались, стоило внести малейшие изменения в модуль, где они находятся. А после внесения исправлений требовалось перепроверять блоки.
Переход на SonarQube
Для обхода накопившихся проблем перешли на использование SonarQube. Стали проверять проект каждую ночь, а исправлять по утрам. Время немного сократилось за счет удобства. А напряженность спала, так как каждый из разработчиков исправляет свой код. Но перепроверки избежать не получилось, так как правятся изменения уже попавшие в основное хранилище.
Очередь за 1C:EDT + SonarQube
Сейчас мы перешли на разветвленную модель разработки. На одном из проектов используем разветвленную модель на хранилищах, а второй полностью перевели на разработку в 1C:EDT.
1C:EDT — это современная расширяемая среда разработки прикладных решений. Она создана на основе свободной интегрированной среды разработки модульных кроссплатформенных приложений Eclipse, широко используемой разработчиками во всем мире.
Проверять теперь мы стали не только главное хранилище/ветку, но и каждую «ветку» отдельно. Такая проверка позволяет исправить все замечания до попадания кода в главное хранилище/ветку.
Следить за качеством кода сложно и нет времени
Следить за качеством кода на проекте сложно, тем более, если на вашем проекте нет носителей культуры написания качественного кода. Но как только качественный код станет виден на фоне прочего кода, останавливаться уже не захочется.
Может показаться, что порог вхождения для построения культуры слишком сложен и «дорог», но если его не преодолеть, то раз за разом мы будем оказываться в зоне «бунта», показанной на графике в начале этой статьи.
Если вы один пытаетесь создавать культуру кода в вашей команде, всегда можете вспомнить, что когда Игнац Земмельвейс в 1847 году впервые рекомендовал врачам мыть руки перед осмотром пациентов, его советы были отвергнуты на том основании, что у врачей слишком много работы и на мытье рук у них нет времени. У него ушло много времени и сил, чтоб доказать, что это оправдано. И ваши усилия не останутся напрасными.
Всегда есть срочные задачи и каждый раз кажется, что сейчас неподходящий момент, чтобы начать следить за кодом. Но если уделять внимание только настоящему, то потеряем возможность получить преимущество в будущем. Вот что по этому поводу пишет Роберт Мартин в своей книге «Чистый код»:
«Программисты сталкиваются с основным парадоксом базовых ценностей. Каждый разработчик, имеющий сколько-нибудь значительный опыт работы, знает, что предыдущий беспорядок замедляет его работу. Но при этом все разработчики под давлением творят беспорядок в своем коде для соблюдения графика. Короче, у них нет времени, чтобы работать быстро!
Настоящие профессионалы знают, что вторая половина этого парадокса неверна. Невозможно выдержать график, устроив беспорядок. На самом деле этот беспорядок сразу же замедлит вашу работу, и график будет сорван.
Единственный способ выдержать график — и единственный способ работать быстро — заключается в том, чтобы постоянно поддерживать чистоту в коде».
Статьи по теме качества кода, упомянутые выше:
- Подходы к сценарному тестированию на примере 1С:Общепит и 1С:Сценарное тестирование.
- Jenkins в разработке конфигураций 1С.
Автор статьи
Проверка конфигурации
Механизм проверки предназначен для выполнения проверки логической
целостности, поиска некорректных ссылок, синтаксического контроля модулей в
различных режимах запуска, а также логическая проверка модулей.
Выполнение проверки конфигурации также можно выполнить с помощью параметра командной строки пакетного режима запуска /CheckConfig (ключи режимов проверки также указаны в перечне тестов механизма).
Для выполнения проверки конфигурации выберите пункт “Конфигурация —
Проверка конфигурации…“.
Несущественные предупреждения проверки конфигурации
Область применения: управляемое приложение, мобильное приложение, обычное приложение.
1. Следующие предупреждения проверки конфигурации не являются существенными для работоспособности прикладных решений и поэтому не подлежат обязательному исправлению:
- Пустой обработчик (для обработчиков оповещений в программных модулях);
- Неразрешимые ссылки на объекты метаданных (в формах и в справке);
- Неразрешимые ссылки на картинки (в формах);
- Неправильные пути к данным (в формах).
Кроме того методика поиска и исправления подобных мест отсутствует.
2. При регламентной проверке конфигурации не следует включать флажок Поиск использования синхронных вызовов, так как в результатах проверки выводятся, в том числе, корректные места вызовов в коде, который не исполняется в веб-клиенте (например, серверный код).
1С:Автоматизированная проверка конфигураций
Общая информация о конфигурации
«1С:Автоматизированная проверка конфигураций» (АПК) предназначена для автоматизированной проверки конфигураций, разработанных на платформе «1С:Предприятие 8», на соответствие стандартам и иным требованиям технического характера.
АПК существенно расширяет платформенную проверку конфигурации и выполняет статический анализ технического качества конфигураций в автоматическом режиме, не требуя их запуска.
Previous ArticleЭлектронные весы
Предлагаю познакомиться с инструментом «Автоматизированная проверка конфигураций» и получить практику его применения
Большое спасибо Максиму Дерюшеву за существенные дополнения и замечания, которые позволили сделать эту публикацию лучше
-
Базовая информация об АПК
-
Настройка подключения к проверяемой базе и проверок по умолчанию
-
Проведение проверок
-
Результат проверки
-
Отчеты АПК
-
Правила проверки конфигураций
-
Фильтрация объектов при проведении проверок
-
Подведение итогов
В последнее время все чаще стали появляться публикации, нацеленные на выработку и поддержание качества разработки. На упорядочивание не только работы пользователей с результатами труда разработчиков, но и труда самих разработчиков 1С. Примерами могут служить как выступления на последних конференциях Инфостарт, так и ряд вебинаров, затрагивающих в том числе вопросы автоматизированного тестирования, код-ревью, применения инструментов, популярных в других ИТ-сферах. Часть хороших материалов есть в открытом доступе:
Открытый инструментарий счастливого 1С-ника
Friday’s Club 16.12.2023
Пост-вебинар «Разработка через автоматизацию, в помощь типовому 1С-нику»
Разработка через автоматизацию, в помощь типовому 1С-нику
BDD в 1С
Разработка на 1С по промышленным стандартам
Действительно, сложность конфигураций 1С с каждым годом увеличивается, команды растут, выходят продукты, содержащие более 5 000 000 строк кода. Без упорядочивания потоков кода работать становится сложно. И речь не только о поддержании минимального порядка — префиксации новых объектов, соглашений о комментариях или раскидывании объектов по подсистемам. С ростом команд и усложнением конфигураций становится понятна необходимость придерживаться стандартов в более широком их понимании.
А чтобы не оставаться сапожниками без сапог, хорошо иметь для этих целей подходящие инструменты. На конференциях и вебинарах, в том числе перечисленных выше, предлагаются интересные инструменты. В то же время достаточно малоизвестная конфигурация от самой фирмы 1С тоже заслуживает внимания. Как вы уже поняли из названия публикации, продукт этот называется “Автоматизированная проверка конфигураций”. Он бесплатен, доступен каждому пользователю (формально для использования требуется доступ к ИТС), достаточно прост в использовании, но пока что не очень распространен.
Отчасти это объясняется тем, что фирма 1С сама активно продвигает идею соблюдения стандартов и использования подходящих для этого инструментов только среди разработчиков тиражных решений через сертификацию “1С:Совместимо”. Влияние идеи соблюдения стандартов и чистоты кода в отношении широких масс разработчиков, не занимающихся тиражными решениями, чувствуется гораздо слабее. Даже ознакомление с основными стандартами разработки находится под условным замком — наличием доступа к ИТС (информация устарела, в настоящее время, на 2023-2023 год, доступ открыт без регистрации):
https://its.1c.ru/db/v8std
Базовая информация об АПК
Конфигурация АПК предназначена для автоматического поиска ошибок и отклонений от стандартов в конфигурациях. Ее применение рекомендовано фирмой 1С еще с 2009 года, причем не только в фирмах-разработчиках тиражных решений, но и для прочих компаний, в которых производится доработка и адаптация типовых решений:
https://1c.ru/news/info.jsp?id=10018
Первое впечатление о конфигурации может дать страница на сайте 1С:
http://v8.1c.ru/acc/
На ней описаны основные возможности этого инструмента и сказано, что он помогает:
-
соблюдать типовые стандарты разработки и выполнять платформенные проверки конфигурации
-
создавать и соблюдать собственные правила проверки конфигурации
-
соблюдать стандарты, требуемые для получения статуса 1С:Совместимо
-
выполнять проверки по расписанию
-
проверять орфографические ошибки
-
присваивать выявленным ошибкам конфигурации различные статусы, в том числе отмечать их как “особенности” не требующие исправления
-
выполнять рассылку сообщений об ошибках ответственным сотрудникам и собственно назначение ответственных за различные объекты
-
слегка облегчать процесс проведения проверки самостоятельно выполняя некоторые действия вроде обновления конфигурации демо-базы из хранилища, возможности поэтапной проверки и т.д.
-
упомянута даже возможность интеграции с СППР
Другим источником общей информации может служить публикация в интернет-журнале PCMagazine:
Часть 1 , Часть 2
Помимо этих обзорных материалов, информации в сети по АПК и ее применению почти нет. Хорошей новостью является то, что в поставку самой конфигурации включено руководство пользователя в формате PDF. Некоторые вопросы раскрыты в руководстве не так подробно, как хотелось бы. Но все же руководство есть и позволяет научиться выполнять основные приемы при работе с конфигурацией.
Для того, чтобы не повторять руководство пользователя здесь будет рассмотрен пример применения АПК для проверки типовой конфигурации, а не демо-конфигурации из поставки АПК. Также попробуем рассмотреть детали работы, о которых в руководстве не сказано.
Начнем с нуля. Загрузить последнюю версию АПК можно по следующей ссылке:
https://releases.1c.ru/project/ACC
На момент публикации этой статьи последним релизом является 1.1.12.26 от 30.01.17, но сначала она писалась для версии 1.1.11.16, поэтому часть скриншотов и замечаний будет относится к этой версии. Для работы с АПК 1.1 потребуется платформа версии не ниже 8.3.6. После установки поставки конфигурации в списке шаблонов конфигураций появляются три новых пункта:
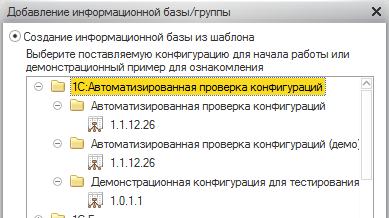
Первый шаблон — это чистая база АПК. Все стандартные правила в ней присутствуют, но нет загруженных данных о демо-базе для тестирования, которые присутствуют во втором шаблоне.
Второй шаблон “Автоматизированная проверка конфигурации (демо)” после разворачивания содержит загруженную информацию о демо базе (находящейся в третьем шаблоне). Его можно использовать, чтобы посмотреть как работают отчеты и стандартные проверки. Лучше всего работу с этой базой изучать вооружившись руководством пользователя из поставки, так как примеры в руководстве рассчитаны именно на эту демо-базу:
АПК работает таким образом, что при выполнении новых проверок загружает информацию из проверяемой конфигурации через COM-соединение. Для этого ей нужна существующая файловая “подопытная” база. Поэтому если есть желание не только ознакомиться с интерфейсом демо-базы, но провести полный цикл с работы с проверяемой базой, то имеет смысл также развернуть еще одну файловую базу из третьего шаблона “Демонстрационная конфигурация для тестирования”.
В этом случае получим две базы данных — одна демонстрационная АПК с уже загруженной информацией о проверяемой Демо-базе и сама проверяемая Демо-база, позволяющая быстро ознакомиться с процессом подключения и проведения новых проверок.
Отмечу, что после экспериментов с демо-базами чистую базу АПК можно и не разворачивать. Проверки рабочих конфигураций можно выполнять на той же конфигурации что и проверки демо-базы. В АПК можно загрузить информацию о любом количестве проверяемых баз.
Вообще принцип работы АПК похож на работу “Конвертации данных”. Работа в конфигураторе АПК не требуется (хотя, как станет понятно далее, без нее вряд ли получится обойтись совсем). Информация о структуре проверяемых конфигураций загружается в пользовательском режиме. В нем же задаются и алгоритмы проверок конфигурации в виде кода на языке 1С:Предприятия, который затем самой системой исполняется с помощью оператора “Выполнить”. В коде можно и нужно применять встроенные в АПК (не платформенные) методы — процедуры и функции, которые выполняют работу с автоматически создаваемыми объектами. Объекты необходимые для проведения проверки конфигурации создаются самой системой и становятся доступны в коде обработчиков проверок. Подробное описание этих методов, объектов и обработчиков можно получить из 6-ой главы «Руководства пользователя».
Конфигурация АПК почти полностью построена на справочниках, регистрах сведений и обработках. В общем если вы знакомы с “Конвертацией данных” то принципы работы с АПК будут понятны. Более того, если не возникнет явной необходимости в собственных алгоритмах проверок, то сначала можно будет ограничиться стандартными проверками и не изучать встроенные методы и программные объекты системы. Тогда почти всю настройку можно сделать мышкой и кажется, что для многих задач этого будет достаточно.
Настройка подключения к проверяемой базе и проверок по умолчанию
После запуска демо базы перед нами предстает такой интерфейс:
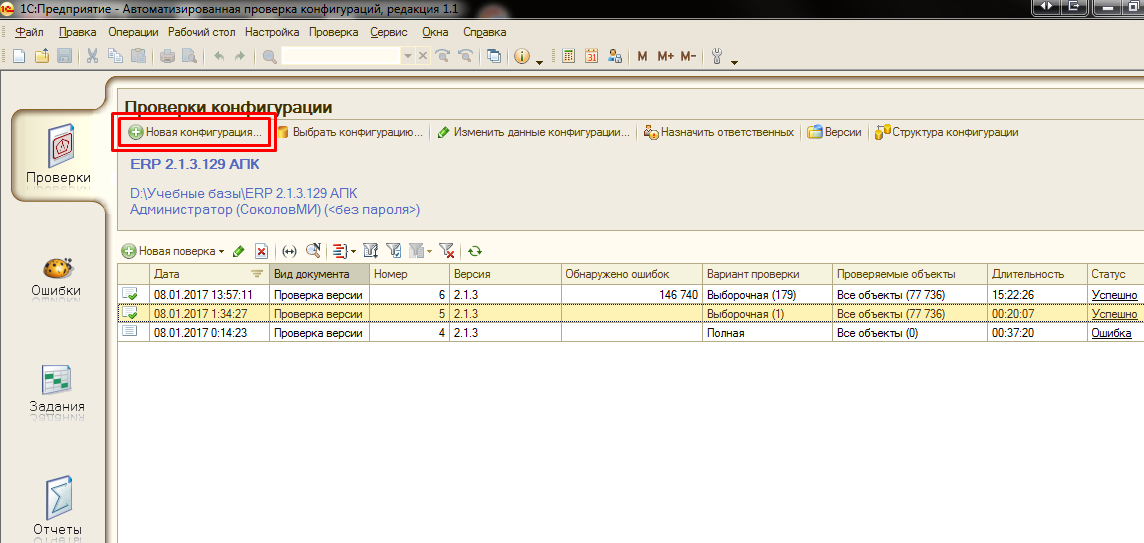
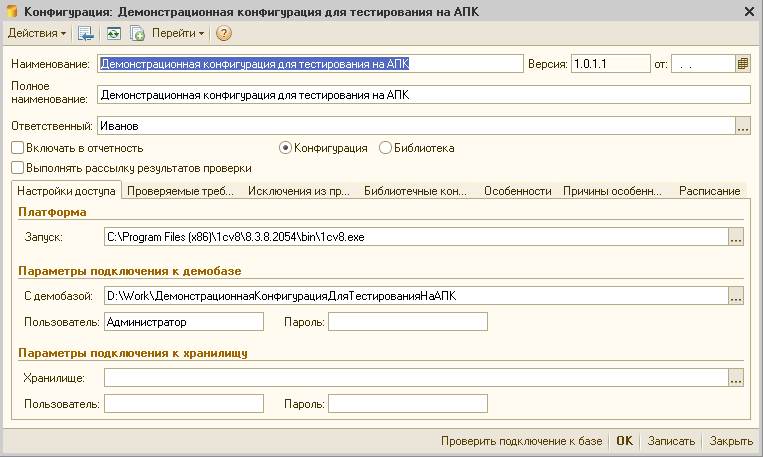
Предназначение разделов с точки зрения разработчиков АПК можно прочитать в руководстве. Мы же пойдем по порядку и сначала добавим новую конфигурацию. Нажмем на кнопку “Новая конфигурация”. Система предложит заполнить параметры подключения. Фактически открывается форма элемента справочника “Конфигурации” :
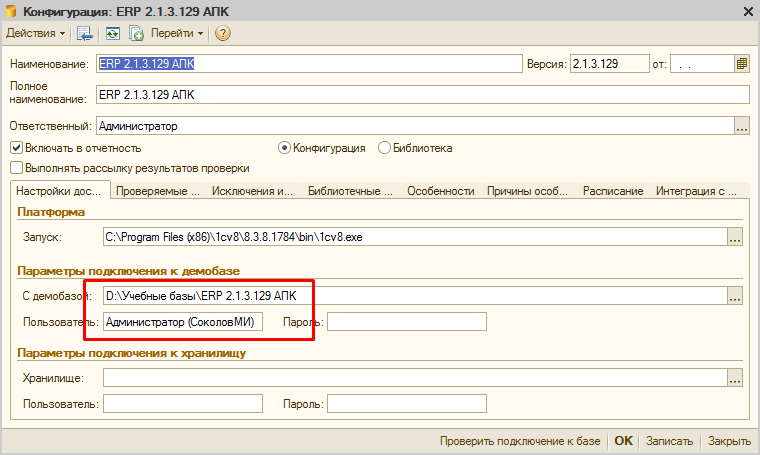
Наименование и полное наименование — это произвольные текстовые поля, только чувство прекрасного и длина поля может ограничить вас в том, что будет в них указано. А вот дальше ограничения более жесткие. Нужно указать полный путь к исполняемому файлу платформы 1С. В более ранних версиях АПК дополнительно нужно указать версию платформы с которой идет работа. Напомню, что АПК может проверять конфигурации только на платформе версии 8.3.6 и выше.
Информация от разработчиков:
Если будет указан путь к платформе ниже, то при COM-соединении будет выдана ошибка. Причина в следующем. В связи с развитием платформы и новых проверок АПК собираются сведения (свойства метаданных), появившиеся только в платформе 8.3.6 или выше. Таким образом, при проверке на версии, например, 8.2 при сборе таких сведений, естественно, будет выдана ошибка. А так как эти новые проверки, как правило, являются приоритетными, то выставлен запрет на запуск проверки ниже, чем 8.3.6. В обратном случае (если клиенту принципиальная версия платформы ниже), то предполагается, что для проверки своей конфигурации он может воспользоваться предыдущими версиями АПК.
Далее нужно указать путь к демо-базе и параметры подключения к ней. Под демо-базой в данном случае понимается не что иное, как специально выделенная файловая база, которая содержит в себе проверяемую конфигурацию. Возможностей для подключения SQL базы в АПК нет. При желании это можно доработать, но большого смысла в этом нет. Во первых выполняется просто проверка конфигурации, а не юнит-тестирование или нагрузочное тестирование. В этом случае даже для крупных конфигураций вроде ERP 2 достаточно просто пустой файловой базы, содержащей актуальную конфигурацию. Во вторых, в соответствии со стандартами 1С любая конфигурация должна быть рассчитана на работу не только с SQL-базой но и на работу в файловом варианте.
Если у вас ведется разработка с применением хранилища, то АПК способна автоматически обновить конфигурацию базы данных из хранилища перед выполнением нового тестирования. Для этого предназначена нижняя группа параметров на скриншоте.
Замечу также, что СППР как и АПК требует файловой базы для загрузки информации о конфигурации. Поэтому если вы решили вести разработку с применением технологий, предлагаемых 1С, с применением АПК и СППР, то для обоих этих систем будет достаточно создать одну файловую базу, при необходимости подключив ее к хранилищу конфигураций и настроив автоматическое обновление конфигурации из хранилища перед загрузкой данных.
Выбор между режимами “Конфигурация” и “Библиотека” определяет жесткость проверок. Для режима “Библиотека” проверки жестче. Библиотека — это конфигурация встраиваемая в другие, а значит она должна удовлетворять определенным правилам и “думать не только о себе”. Если навести курсор на оба варианта переключателя, то выплывет подсказка с описанием различий проверки. В частности, для библиотеки будут проверены все выбранные требования. Для конфигурации не проверяются требования из группы «Разработка и использование библиотек» вне зависимости от того, выбраны они или нет. Данная группа требований содержит очень долговременные правила проверки, предназначенные действительно только для библиотек.
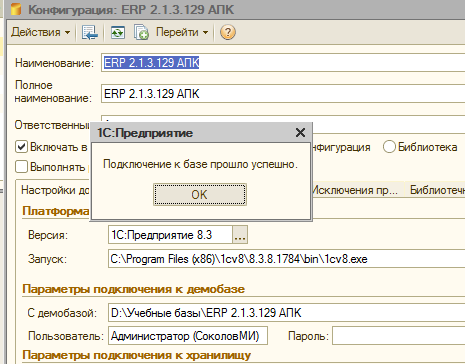
Важный момент для версии 1.1.11.16 и более ранних версий АПК (в верии 1.1.12.26 эта ошибка устранена). После того, как настройки заданы и элемент справочника “Конфигурации” записан, можно проверить подключение. Но в первый раз система может выдать ошибку об отсутствии подключения.
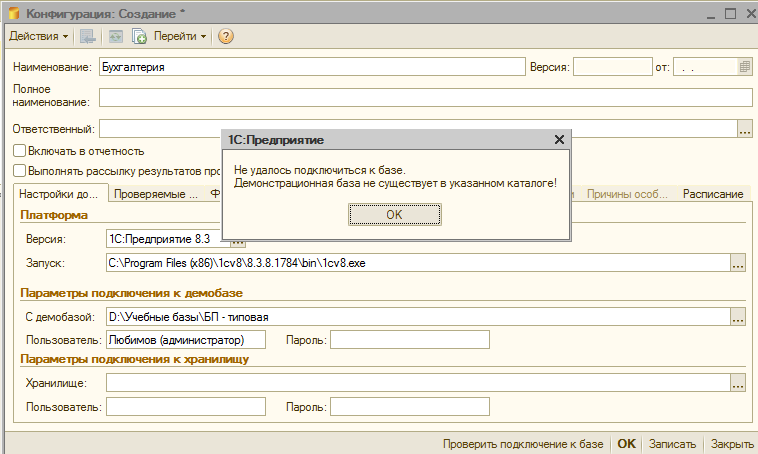
Это обманчивое сообщение. Если пути и пользователи заданы правильно просто нужно предварительно записать элемент этого справочника и только потом проверять подключение. Тогда система отчитается об успешном подключении. Проверка подключения к большой базе, например ERP может занимать до 1-2 минут:
Фактически сейчас мы создали новый элемент справочника «Конфигурации». Теперь открыть его можно разными способами:
- Через меню “Настройки” -> “Конфигурации”
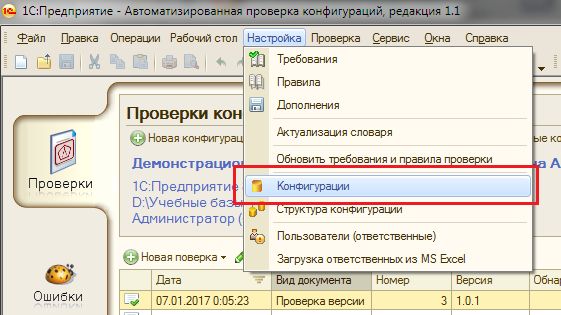
- В разделе “Проверки” нажать “Выбрать конфигурацию”
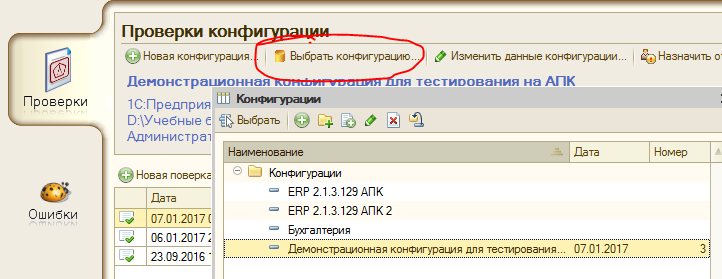
- Или просто открыть справочник “Конфигурации” через меню “Операции”
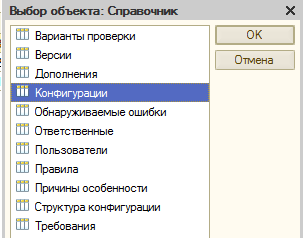
Вернемся к окну настройки конфигураций.
На второй вкладке “Проверяемые требования” можно настроить то, какие проверки мы хотим выполнять над нашей конфигурацией. Доступны два предопределенных варианта : “Полная проверка” — проверка на соответствие системе стандартов https://its.1c.ru/db/v8std и контроль орфографии , а также “1С:Совместимо” — проверка на соотвествие стандартам 1С:Совместимо http://1c.ru/rus/products/1c/predpr/compat/soft/requirements.htm
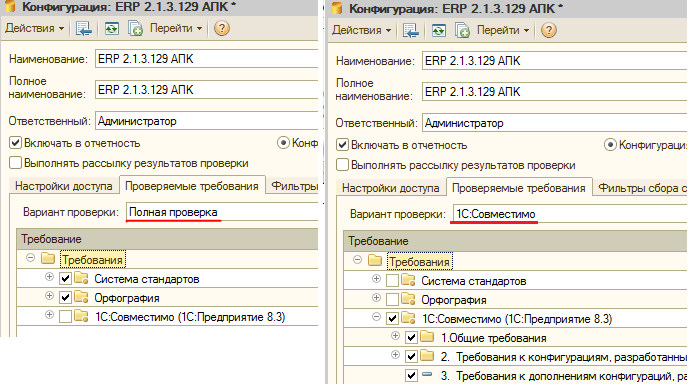
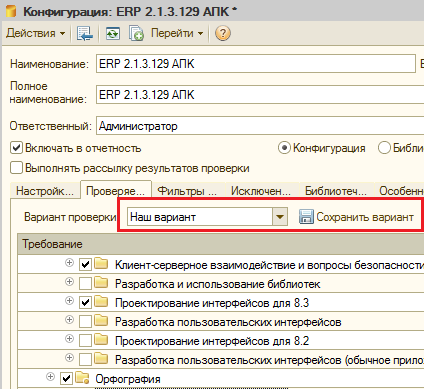
Также можно настроить произвольный набор проверяемых требований, после этого вбить в поле “Вариант проверки” произвольное представление варианта и сохранить его под этим наименованием по кнопке “Сохранить вариант”. Варианты сохраняются в привязке к конфигурациям, то есть ту же настройку нельзя будет автоматически применить к другим элементам справочника «Конфигурации»:
Сделаю замечание для тех, кто планирует применять АПК для нескольких конфигураций, и не хочет настраивать проверки для каждой из них отдельно. Переносить настройки проверки между конфигурациями можно написав простейший скрипт, если знать, что хранятся они в регистре сведений «Требования к конфигурации», а сами варианты проверок хранятся в одноименном справочнике:
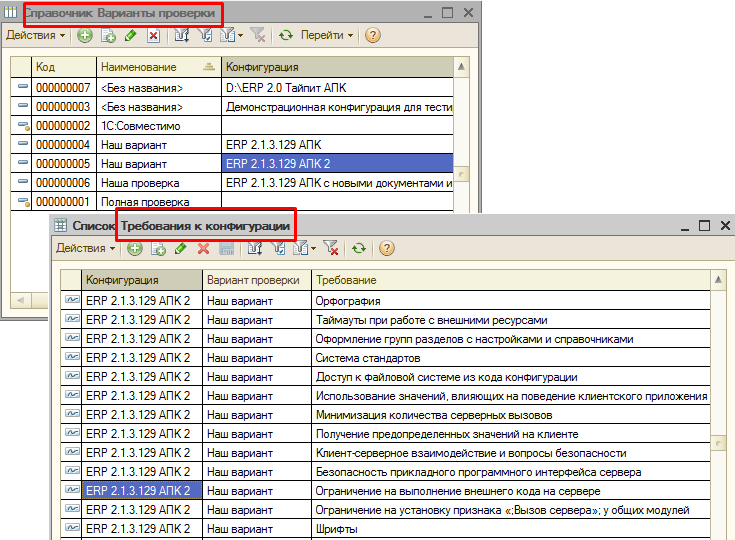
Список проверок достаточно объемный. Каждое требование — это стандарт разработки, придерживаясь которого можно сделать наши продукты лучше. Но возможность отключать отдельные требования или их группы тоже не лишняя. Например на большинстве предприятий можно ограничиться вариантом “Полная проверка” (орфография + система стандартов) и не делать проверок на “1С:Совместимо”. Или контролировать хотя бы орфографию, так как не бывает такого, чтобы разработка годами велась без единой орфографической ошибки.
Список выбранных здесь требований — это список по умолчанию, для автоматически проводимых проверок. При пошаговом выполнении проверки можно будет переопределить указанные здесь значения.
Информация от разработчиков:
Есть смысл подробнее рассказать, что такое группа «Система стандартов», и чем она отличается от двух других групп. Итак, начнем с группы «1С:Совместимо». Как уже было ранее написано, это обязательный набор стандартов для получения определенного статуса для своей конфигурации. Грубо говоря, это — костяк, которому обязательно должны соответствовать все конфигурации без исключения. К слову, данная группа стандартов не проверяет конфигурацию на орфографические ошибки…
Далее «Орфография» — группа стандартов, которая проверяет конфигурацию только на орфографические ошибки. Каждый уважающий себя разработчик может проверить свою конфигурацию на орфографию. В этой группе собраны все правила проверки, отслеживающие орфографию в текстах модулей, метаданных (имя, синоним, комментарий), элементах форм, макетах, в общем, везде, где можно проверить текст. «Из коробки» проверяется только русский текст, но как верно замечено в комментариях, для других языков можно загрузить свои словари и даже заменить ими идущий в поставке конфигурации.
А теперь про группу «Система стандартов». Она является самой глобальной и содержит в себе проверки двух остальных предопределенных групп требований, а также дополнительные специализированные проверки. Для клиентов ошибки этой группы являются скорее рекомендациями, хотя для типовых конфигураций большинство ошибок, конечно, обязательны к исправлению. Т.о. если какой-либо стандарт описан в группе «1С:Совместимо» или «Орфография», он без сомнения будет также описан и в группе «Система стандартов», однако, может быть, более подробно и с более глубокими проверками.
На вкладке «Исключения из проверки» настраивается различная фильтрация. Например можно настроить проверки так, чтобы проверялись только добавленные вами в типовую конфигурацию объекты с определенным префиксом вроде “мф_СуперТаможеннаяДекларация”.
Или, если вы ведете разработку с добавлением всех измененных или добавленных объектов в определенную подсистему для разработки, то проверку имеет смысл выполнять только в рамках этой подсистемы, а неизменные объекты типовой конфигурации находящиеся на “замке” обходить стороной. Если необходимо временно исключить какой-либо настроенный фильтр при проведении проверок не нужно удалять его. Достаточно снять флаг использования (вторая колонка):
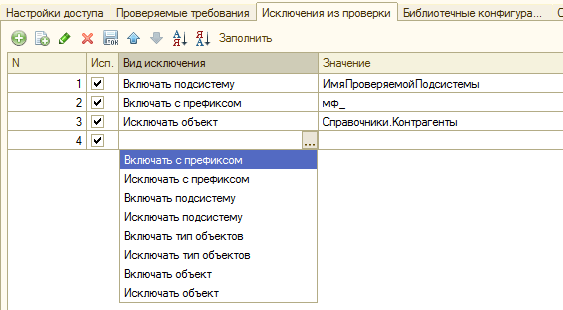
Функция фильтрации очень полезная и с ней имеет смысл поэксперементировать, что и сделаем далее. Сразу скажу, что разрешающие проверки вроде «Включать подсистему» и «Включать с префиксом» работают по «ИЛИ». То есть объект попадет в проверку если он будет удовлетворять одному либо другому условию. Это не всегда удобно. К счастью, изменить подобное поведение очень просто. Подробнее этот вопрос будет рассмотрен в разделе посвященному фильтрации, как и вопрос влияния фильтров на время проведения проверок
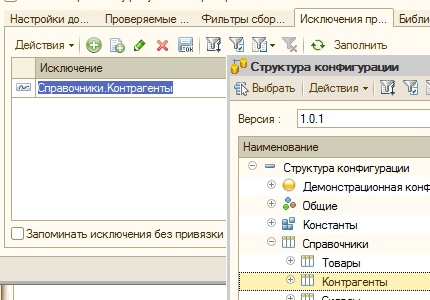
В версии АПК 1.1.11.16 и более ранних версиях настройки фильтрации были разделены на две вкладки — “Фильтры сбора требований” и “Исключения при сборе данных”, но смысл был тот же самый:
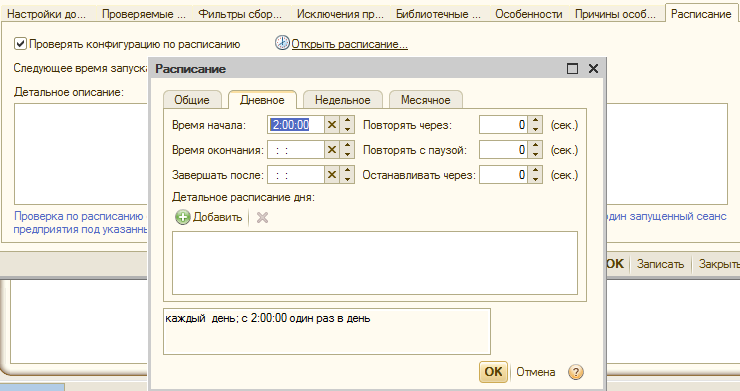
Также в форме настройки можно задать необходимость проведения проверок по расписанию:
Это настройка не для работы через регламентное задание. Для запуска проверки по расписанию требуется чтобы АПК была запущена в пользовательском режиме и работала. При старте системы в модуле обычного приложения вызывается метод ПриНачалеРаботыСистемы() где подключается обработчик ожидания ЗапускПроверкиПоРасписанию(), который и выполняет проверку по расписанию. Если есть желание запускать проверку регламентным заданием систему придется доработать. Если заглянуть в конфигурацию АПК то можно увидеть что в ней есть всего два регламентных задания и оба они не связаны с проверками по расписанию:

Информация от разработчиков:
Объяснение очень простое. Если АПК развернута в SQL-варианте , то при указании пути к конфигурации (точнее, демо-базе) на клиенте, проверка попросту не запустится, т.к. регламентное задание всегда работает на сервере. В файловом варианте АПК, безусловно, больше бы подошло регламентное задание, а не обработчик ожидания.
Расписание — это не последняя из возможных вкладок. Если включить в системе интеграцию с “Системой проектирования прикладных решений”, то появится еще одна вкладка “Интеграция с СППР”, позволяющая настроить автоматическую регистрацию ошибок в СППР. Настройка интеграции на уровне системы выполняется в форме констант (“Операции” — “Константы”).
Функционал интеграции с СППР предназначался разработчиками АПК для внутреннего использования в фирме 1С (об этом сказано в «Руководстве пользователя», стр.28). Однако уверен, что для тех компаний, которые в своей работе уже используют СППР или планируют ее использовать, этот функционал будет интересен. Его можно взять за образец для реализации своего механизма интеграции или разобраться с ним и использовать «из коробки»:
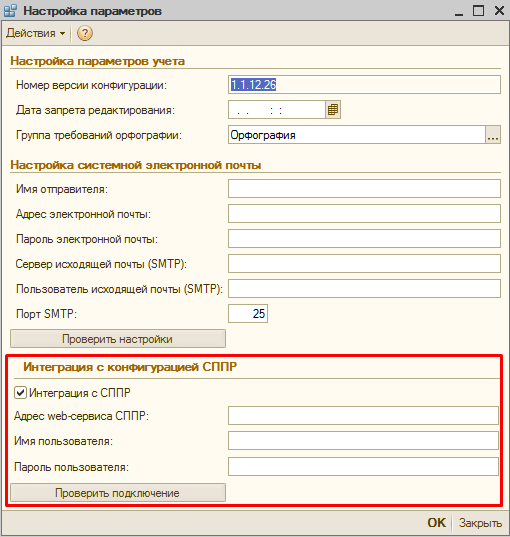
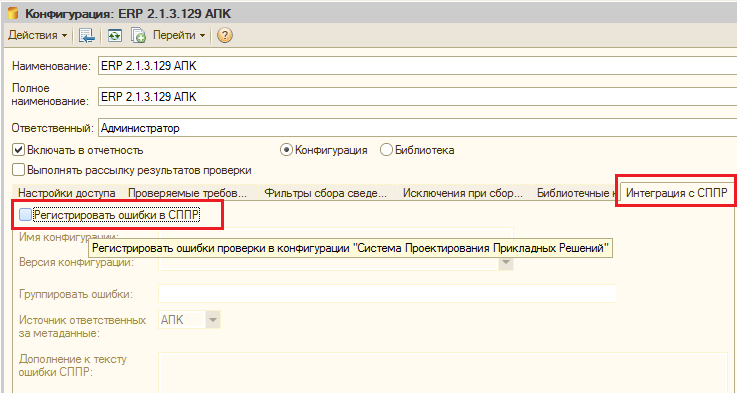
При этом возможно как подключение АПК к веб-сервису поднятому со стороны СППР, так и наоборот, можно в СППР настроить подключение к веб-сервису поднятому на стороне АПК:
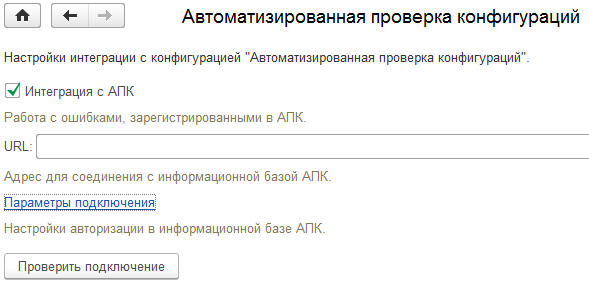
Проведение проверок
После проведенных настроек подключения и выбора проводимых проверок можно переходить к выполнению проверок.
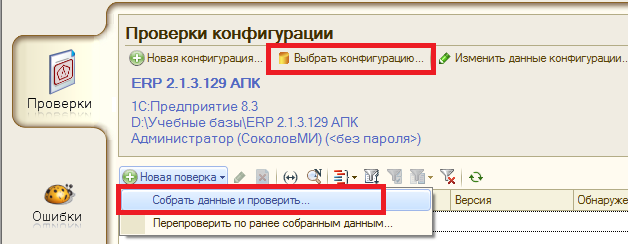
Для проведения новой проверки необходимо сначала сделать проверяемую конфигурацию текущей. Все новые проверки производятся над “текущей конфигурацией”. Для этого в разделе “Проверки” необходимо нажать “Выбрать конфигурацию” и затем выбрать элемент справочника конфигурации, который будет назначен “текущим”.
При нажатии на кнопку “Новая проверка” система предложит два варианта — провести проверку заново выполнив подключение к проверяемой конфигурации, заново собрав данные, либо провести проверку ранее собранных данных.
Возможность проводить проверки по ранее собранным данным позволяет поэтапно выполнять длительные проверки. Например сначала можно собрать данные о конфигурации и выполнить проверку с фильтрацией по части подсистем. Затем включить фильтры по другим подсистемам и вторую проверку делать уже по ранее собранным данных, что позволит выполнить ее значительно быстрее.
Информация от разработчиков:
Здесь надо также сказать, что теперь состав собираемых данных напрямую зависит от выбранных требований. Например, выбрано одно требование «Орфография в текстах модулей». Если открыть карточку самого требования и перейти на вкладку «Этапы проверки», то можно увидеть, что выбран только 1 флажок «Заполнить сведения о модулях»:
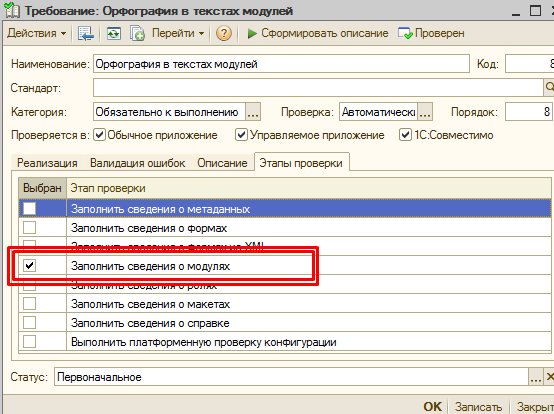
Это означает, что при проверке конфигурации на орфографию в текстах модулей, будет выполнен только сбор текстов модулей (не будут собраны ни свойства объектов метаданных, ни элементы форм, ни макеты — все виды сбора информации можно выделить по остальным флажкам).
Такой функционал зависимости собираемой информации от выбранных требований появился относительно недавно, ранее при каждой проверке со сбором данных выполнялся сбор всей информации. Так вот ранее этот вариант очень помогал: выбиралось какое-то одно требование, например, те же модули, выполнялся сбор всей информации, исправлялись ошибки по этому одному требованию, затем выбиралось следующее требование, например, уже орфография в элементах форм, и запускалась проверка уже по собранным данным, т.к. элементы форм не менялись и т.д.
Сейчас им также можно пользоваться, но проверить по собранным данным можно уже только те требования, сведения по которым были собраны ранее. Ну и нельзя не сказать, что этот вариант проверки крайне необходим разработчикам новых проверок для отладки, тестирования, ускорения и выявления неточностей в правилах проверок, т.к. не надо каждый раз пересобирать данные.
Поскольку у нас еще никакие данные не были собраны выберем пункт “Собрать и проверить данные…”. Откроется окно в котором можно выбрать проведение либо автоматической проверки, по ранее проведенным в окне новой конфигурации настройкам, либо переопределить эти настройки. Выбор варианта “Вручную” особенно удобен на начальном этапе ознакомления с системой , когда можно повлиять на каждый следующий шаг.
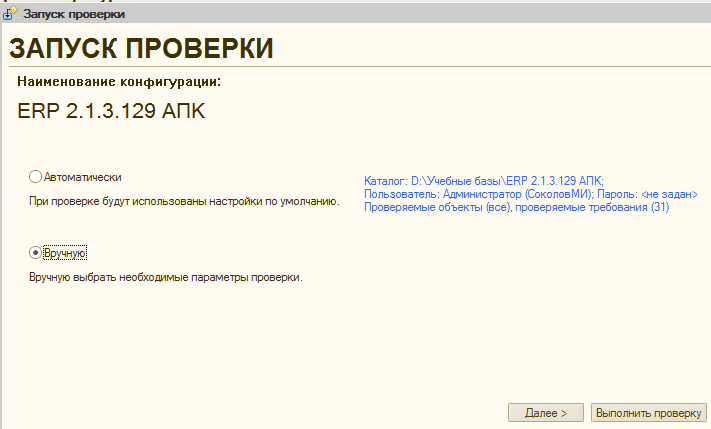
Нажимая на кнопку “Далее” можно переопределить все настройки , которые описывались в предыдущем разделе этой публикации, включая проводимые проверки. Правда следует учитывать что если не выбрать ни одной проверки на соответствующем шаге, то система посчитает, что нужно выполнить ВСЕ проверки, а не просто подключиться и загрузить информацию об объектах из проверяемой базы:
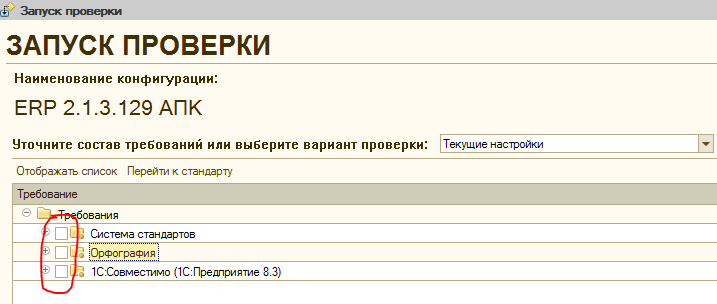
Поэтому если целью запуска является не полная проверка, а обновление структуры конфигурации или тестовый прогон АПК и ознакомление с процессом, то снимать все флажки на этом шаге не следует. В первый раз целесообразно отметить только какой-нибудь один элемент, например — “Платформенная проверка конфигурации” в следующей ветке:
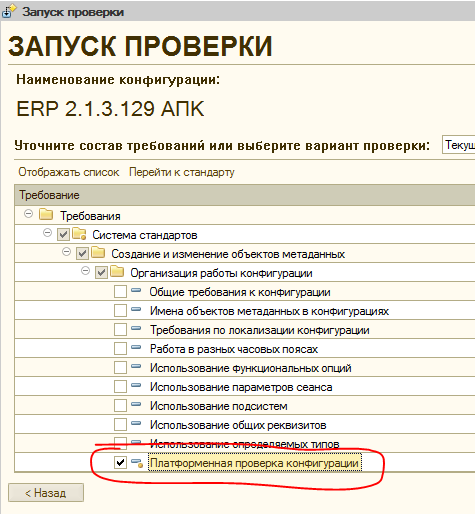
В этом случае список шагов проверки будет примерно следующим:

и может занять всего 20 минут даже на ERP. Но этого будет достаточно, чтобы получить представление о том, как собственно происходит процесс. Хотя платформенная проверка может преподнести сюрприз и затянуться надолго, поэтому можно выбрать и другой элемент попроще.
На последнем шаге можно также установить фильтры на проверяемые объекты. Правда, если это первая проверка конфигурации, то в АПК еще не будет информации о структуре конфигурации. В этом случае дерево конфигурации на этом шаге будет пустым, но его можно загрузить кнопкой «Прочитать структуру конфигурации» прямо из этого же окна:
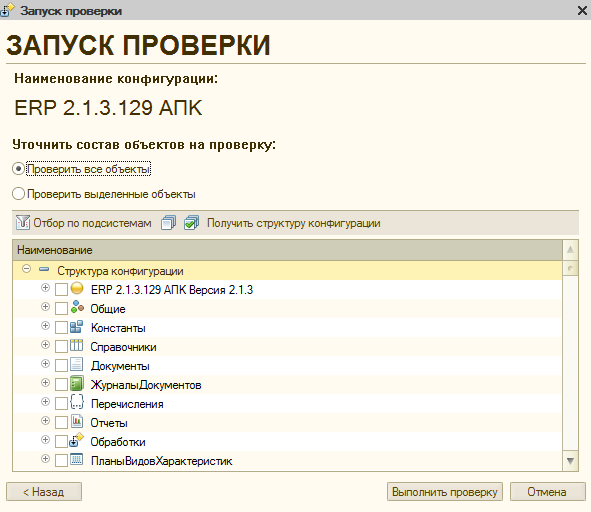
Теперь остается нажать кнопку “Выполнить проверку”. Начнется процесс проведения проверок. С миганием окон 1С и выводом лога процесса в окно сообщений. Вывод лога сделан очень неудобно. Окно проверки висит модально и если заранее не подумать о том, чтобы окно сообщений было видно, то о происходящем нельзя будет ничего узнать пока процесс не закончится:
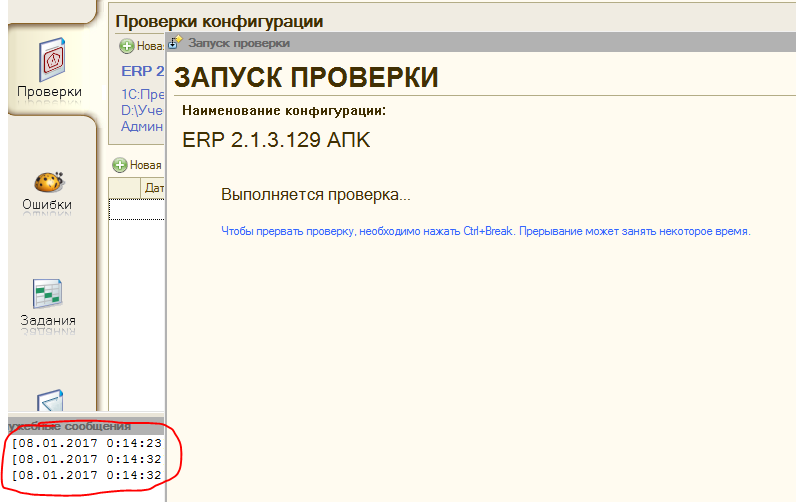
Поэтому если у вас небольшое разрешение экрана, то лучше сразу озаботиться тем, чтобы сдвинуть модальное окно запуска проверки таким образом, чтобы окно сообщений было видно.
На одном из этапов проверки система обновляет содержимое справочника “Структура конфигурации”, содержащего дерево (иерархию) объектов метаданных как в конфигураторе. Данные о конкретном объекте будут обновлены если этот объект изменился или был включен в дополнительную подсистему. Элемент справочника будет помечен на удаление если соответствующий объект конфигурации был удален. Будут созданы новые элементы для новых объектов конфигурации:

Также, при каждой проверке со сбором данных, обновляется содержимое регистров «ЗначенияСвойствОбъектов» и «ЗначенияСоставныхСвойствОбъектов», хранящих свойства объектов, модули, содержимое макетов, элементы форм и т.д. При проверке по ранее собранным данным эти сведения остаются прежними.
Если выбраны какие-либо проверки требующие не только обновления структуры метаданных и платформенной проверки, но и чего-то большего, то система будет производить выгрузку конфигурации в файлы для их последующего анализа:

Выгрузка происходит без иерархии — все файлы в одну папку:
Информация от разработчиков:
Итак, что и когда собирается (при проверке со сбором данных):
- Структура конфигурации — вообще всегда, какие бы требования ни были выбраны.
- Сбор происходит путем запуска внешней обработки из общего макета «ЗагрузчикСтруктурыМетаданных» в предприятии в толстом клиенте. Обработка в предприятии работает с объектом платформы «Метаданные» и пишет данные во внешний файл, который потом передается и разбирается в АПК.
Все дальнейшие этапы, запускающие внешнюю обработку в предприятии, действуют аналогичным образом. Остальные сведения, как уже сказано выше, собираются в зависимости от выбранных требований:
- Сбор сведений о метаданных (повторюсь, это свойства объектов метаданных, а не сама структура) происходит путем запуска внешней обработки из общего макета «ЗагрузчикСведенийОМетаданных».
- Сбор сведений о формах (а точнее, об элементах форм) — с помощью обработки из макета «ЗагрузчикСведенийОФормах».
- Сбор сведений о формах из XML происходит путем анализа XML-файла формы из выгрузки конфигурации в файлы XML. Собирается вся информация, которую не удалось получить из предприятия на предыдущем этапе.
- Сбор сведений о модулях — путем чтения текстов модулей из файлов выгрузки XML.
- Сбор сведений о ролях (а точнее, сбор прав каждой роли для каждого объекта) — из файлов ролей выгрузки XML.
- Сбор сведений о макетах — с помощью обработки из макета «ЗагрузчикСведенийОМакетах».
- Сбор сведений о справке — путем чтения файлов справки из файлов выгрузки XML.
Платформенная проверка конфигурации — пакетный запуск демобазы в режиме конфигуратора с ключами платформенной проверки. Также указывается файл с логом проверки. Затем он разбирается в АПК, из него получаются ошибки платформенной проверки, которые хранятся в отдельном регистре «ОшибкиПроверкиКонфигурации».
Таким образом, если выбрано хотя бы одно требование с флажком сбора сведений о формах из XML, ролях, модулях или справке, то проверяемая база будет выгружена в файлы XML. Если ни одно из этих действий не требуется, что выгрузки не будет.
Ранее все действия производились последовательно. Сначала запускался сбор структуры, затем выгрузка в XML, затем платформенная проверка, затем сбор свойств метаданных, модулей, форм и т.д., что сильно замедляло проверку (сбор данных) крупных конфигураций.
В АПК 1.1.12 было добавлено копирование исходной базы во временный каталог и выявлены самые долговременные этапы сбора данных, что позволило распараллелить сбор данных при проверке. Таким образом на текущий момент сбор структуры конфигурации, платформенная проверка, выгрузка в XML и очистка регистров выполняются параллельно. Остальные этапы занимают незначительное время, даже для ERP. В результате введения параллельности сбора информации удалось ускорить проверку ERP как минимум на пару часов.
В директории временных файлов генерируются и открываются в проверяемой базе обработки, осуществляющие создание экземпляров объектов метаданных и создание форм и макетов объектов. Изначально этот механизм предназначался для сбора сведений о формах, макетах и свойствах метаданных. Но также благодаря ему ищутся ошибки, которые не позволяют даже создать объект или форму программно. Это конечно далеко не юнит-тестирование, но уже что-то:

Если в модуле объекта или формы будет попытка обратиться к необъявленной переменной или недоступному из контекста модуля объекту, то система либо остановится в процессе проверки с ошибкой (будет висеть окно в открывшейся проверяемой базе) , либо АПК отловит эту ошибку и покажет ее в отчетах. Если АПК остановится в процессе проверки из-за такой ошибки, то это конечно не очень удобно. Но с другой стороны наличие ошибок компиляции модулей — это критическая ошибка программистов и лучше если она будет обнаружена с помощью АПК таким образом, чем попадет в продуктив и сообщение о ней поступит от пользователей!
В процессе полной проверки (или ее аналога по количеству правил и объектов) система застревает на проверке объекта №1 никак не сообщая о прогрессе:

Такой статус с сообщением о том, что проверяется объект №1 из 77 тысяч висит на протяжении 5-10 часов и кажется что АПК зависла. На самом деле процесс идет, убедиться в этом можно посмотрев на загрузку процессора в диспетчере задач или вызвав остановку из конфигуратора (если запуск АПК производился из него). Причины долгой проверки Объекта №1 , а именно самой конфигурации, следующие:
1) В рамках этого шага собирается и кэшируется информация, используемая далее при проведении проверок отдельных объектов. Благодаря этому проверка остальных объектов выполняется быстрее.
2) Большинство проверок, затрагивающих все объекты конфигурации сразу, выполняется именно в рамках этого шага. Таких проверок много, около 90. Но наиболее длительных, занимающих большую часть времени, всего пара. Это например «Поиск неиспользуемых служебных экспортных методов». Очевидно, что нельзя сделать вывод о том, используется или не используется метод отдельного объекта, проверив только один этот объект или какую-то отдельную подсистему. Такой вывод можно сделать только проанализировав вызовы методов в рамках всей конфигурации. И очевидно, что обход всей конфигурации оптимально делать один раз, при проверке «Объекта №1», а не множество раз, при проверке отдельных документов и справочников. Другим примером длительной проверки является «Контроль наличия общего модуля, подсистемы, метода и контроль состава параметров».
Если отключить две указанные проверки и платформенную проверку конфигурации, то проверка даже такой конфигурации как ERP может занять не более получаса. Но наверное не стоит экономить время и жертвовать качеством. Лучше решить этот вопрос организационно и делать проверки заблаговременно.
Привожу пример — начало и окончание лога выполнения проверки, который показывает что полностью процесс на ERP 2.1 и АПК 1.1.11.16 занимает порядка 15 часов (естественно цифра сильно зависит от производительности компьютера, также скорость проверки на АПК 1.1.12 значительно выше и при тех же условиях занимает около 10 часов):
[08.01.2023 13:57:12]: Выполняется проверка подключения к информационной базе через COM-соединение
[08.01.2023 13:58:22]: Начало сбора сведений о структуре метаданных конфигурации
[08.01.2023 14:12:04]: Начало выгрузки конфигурации в файлы XML
[08.01.2023 14:25:24]: Начало очистки сведений о метаданных
[08.01.2023 14:27:56]: Начало сбора сведений о ролях конфигурации
[08.01.2023 16:25:49]: Собраны и записаны сведения о ролях конфигурации
[08.01.2023 16:51:39]: Собраны сведения о метаданных конфигурации
[08.01.2023 18:26:05]: Платформенная проверка конфигурации завершена
[08.01.2023 18:26:05]: Начало тестирования объектов конфигурации
[08.01.2023 19:15:55]: Начало сбора сведений о формах конфигурации из файлов XML
[08.01.2023 19:47:20]: Стартовала проверка конфигурации
………ЗДЕСЬ СООБЩЕНИЯ НАЧИНАЮТ ВЫВОДИТЬСЯ В СТРОКУ СОСТОЯНИЯ…..
[09.01.2023 5:19:37]: Выполнена проверка конфигурации
Результат проверки
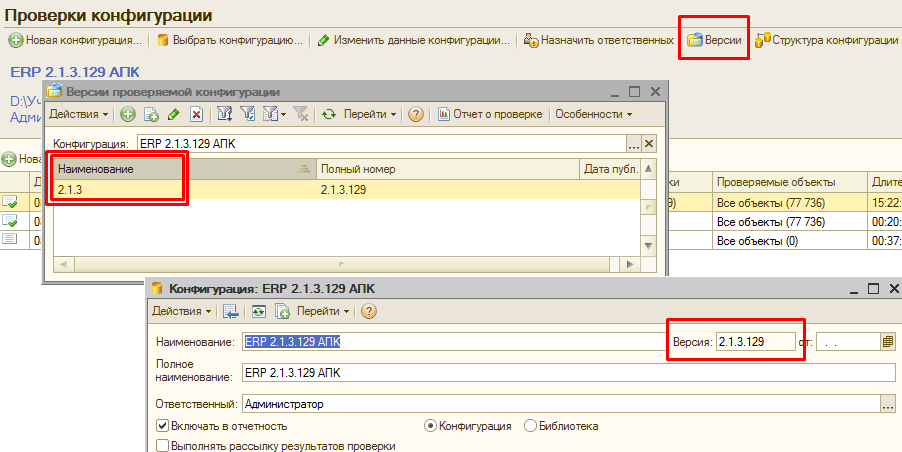
Что получаем в результате выполнения первой проверки? Во первых, заполняется справочник версий конфигурации (справочник “Версии” подчинен справочнику “Конфигурации”). В нем появляется элемент, соответствующий версии проверяемой конфигурации. Также обновляется информация о версии в форме элемента справочника «Конфигурации»:
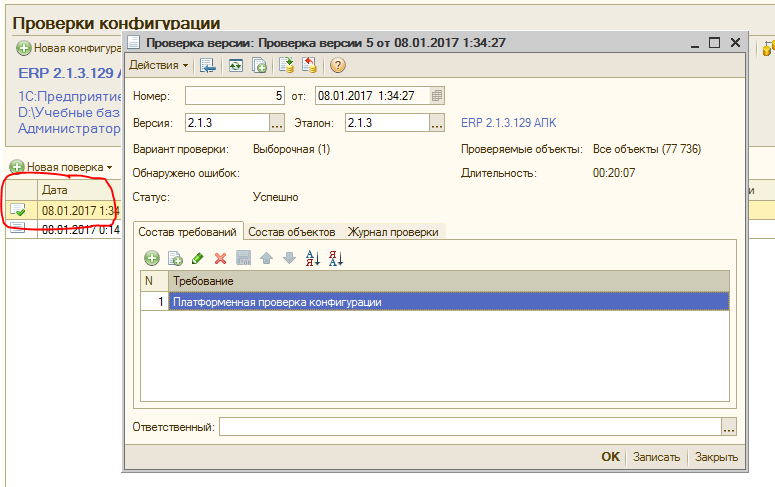
Во вторых, создается документ типа “Проверка конфигурации” , в котором указывается этот элемент справочника “Версии” и другие параметры проверок — состав проверяемых требований, состав проверяемых объектов и “Журнал проверки” в который дублируется лог, выводимый ранее в окно сообщений:
В третьих, обновляются данные о структуре конфигурации:
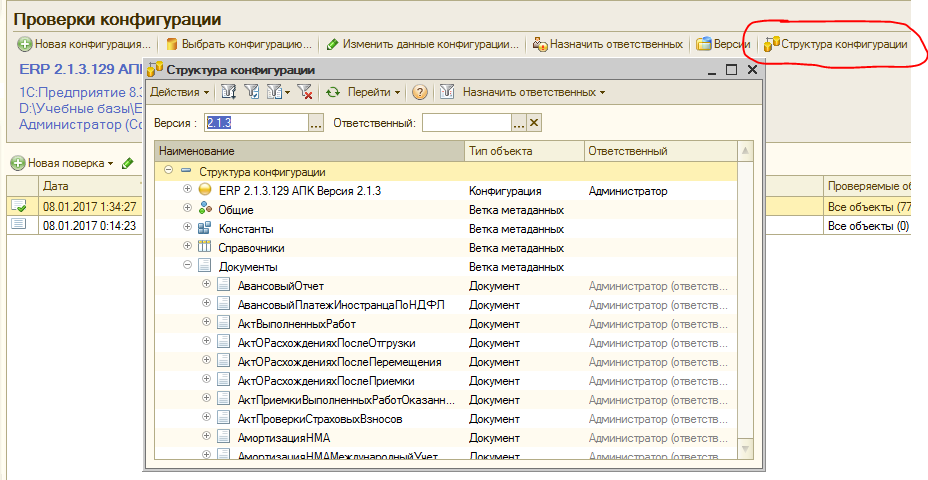
Структура конфигурации — это иерархический справочник с иерархией элементов, подчиненный справочнику “Версии”, то есть при проверке конфигурации новой версии произойдет создание нового элемента справочника “Версии” и загрузка новой структуры метаданных уже в привязке к этой версии.
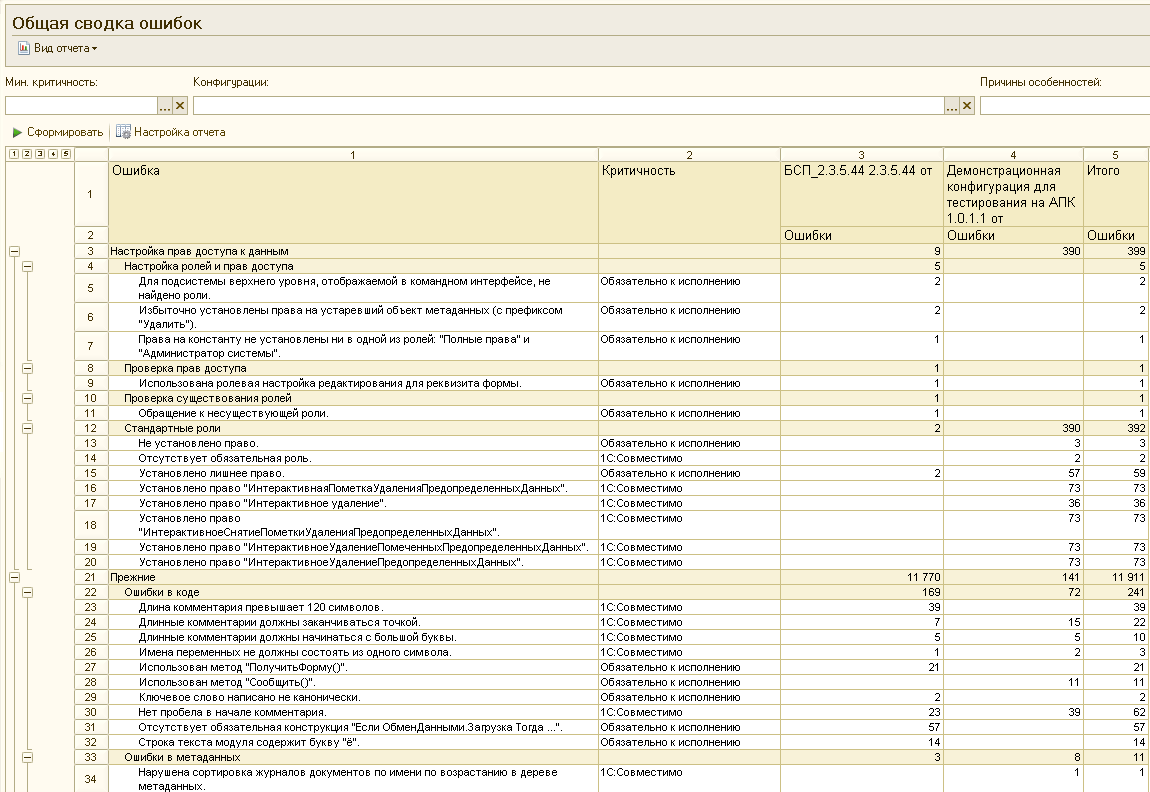
И в четвертых, заполняется регистр “Найденные ошибки”, который собственно и содержит информацию о том, какие ошибки были обнаружены в процессе проверки и является основой для отчетов АПК:
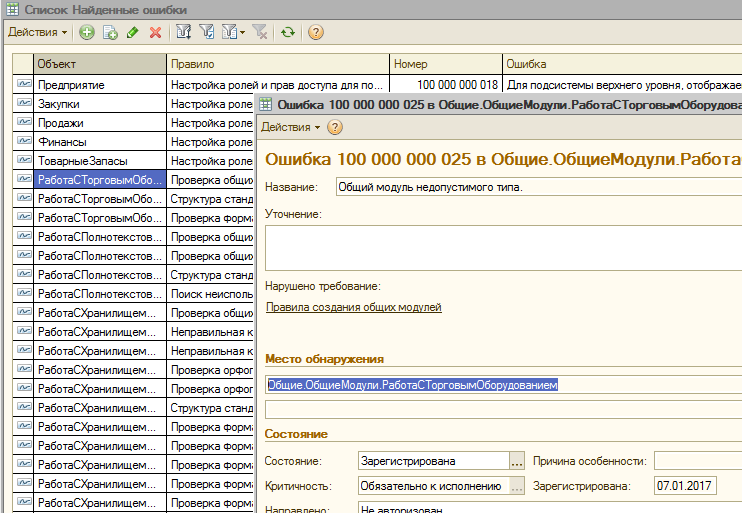
Для этого регистра не создана форма списка. Свалку в этом общем котле регистра можно буквально за несколько минут привести в порядок. Например добавить управляемую форму, в пользовательском режиме или сразу в конфигураторе вывести владельца объектов (элементов справочника «СтруктураКонфигурации»), к которым привязаны ошибки. Этими владельцами будут версии конфигураций.
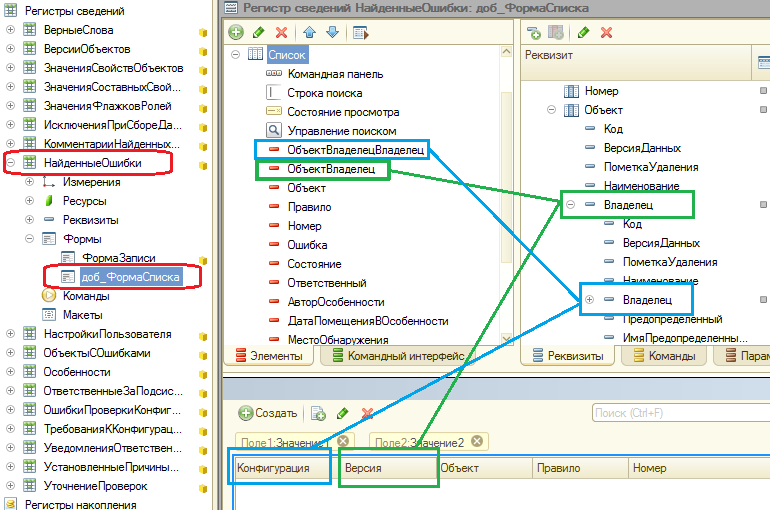
Если вывести владельцев и от них, то получим в форме списка возможность фильтровать ошибки и по конфигурациям и по их версиям. Можно делать по ним группировки. В этом случае с ошибками можно будет работать не только с помощью отчетов, но и непосредственно через регистр, что иногда гораздо удобнее:
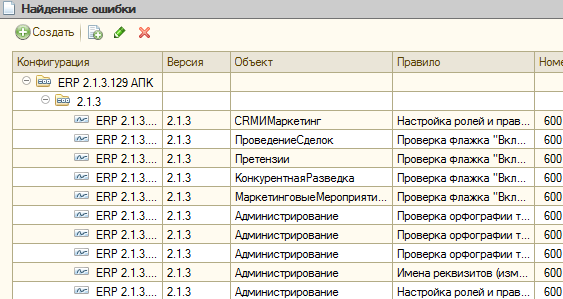
Каждая запись этого регистра — это найденное несоответствие стандартам, орфографическая или другая ошибка. Открыв какую либо из них можно убедиться, что даже такие надежные и проверенные годами системы, как ERP 2.1 ;)) содержат опечатки и ошибки. Причем довольно большое их количество:
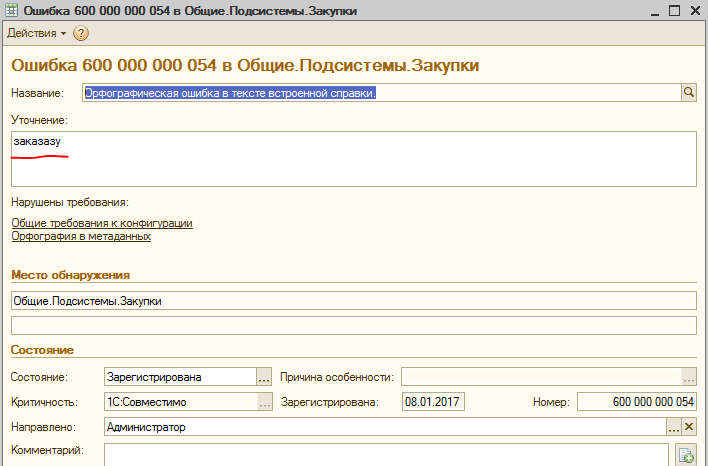
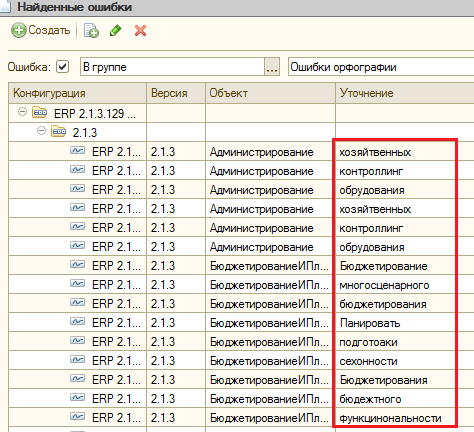
Хотелось бы чтобы мы воспринимали факт наличия таких ошибок в ERP не как индульгенцию на их наличие в наших разработках, а как лишнее доказательство того, что их можно и нужно выявлять и устранять. Особенно при наличии подходящих инструментов. Потому что выглядят они некрасиво и это как раз то, что видят наши пользователи. В блоге 1С на Хабре отмечается, что разработчики ERP 2 используют АПК для проверки конфигурации, но видимо ограничивают список проверок наиболее важными с их точки зрения правилами, обеспечивающими приемлемое соотношение скорости разработки и качества продукта. Мы же можем при разработке своих продуктов повышать планку качества и захватывать в том числе это направление.
Также будет полезно знать, что собранные данные о текстах модулей, блоках модулей и других свойствах объектов конфигурации помещается в регистры “Значения составных свойств объектов” и «Значения свойств объектов». Записи хранятся в привязке все к тем же объектам, подчиненным версиям и конфигурациям:
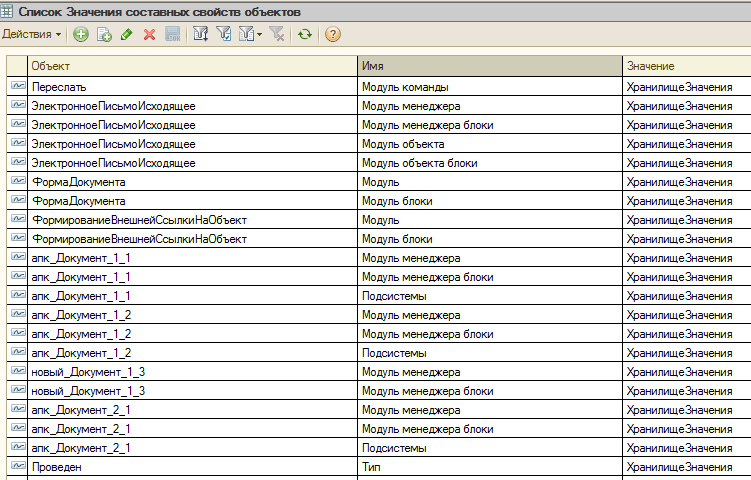
Тексты модулей увидеть прямо из форм регистра не получится, они все упакованы в хранилища значений.
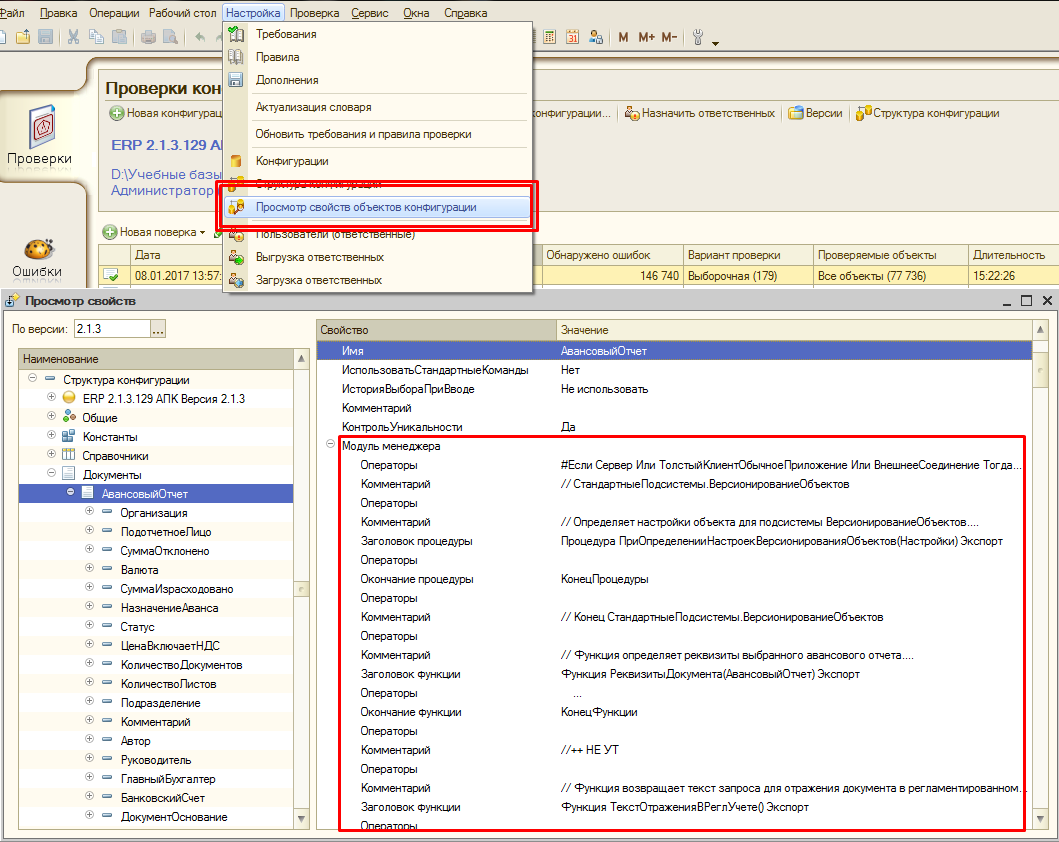
Но для просмотра текстов модулей, уже разбитых на составляющие части, и других свойств объектов конфигурации в АПК есть замечательный инструмент! Это обработка «Просмотр свойств объектов конфигурации», открываемая через меню «Настройка»:
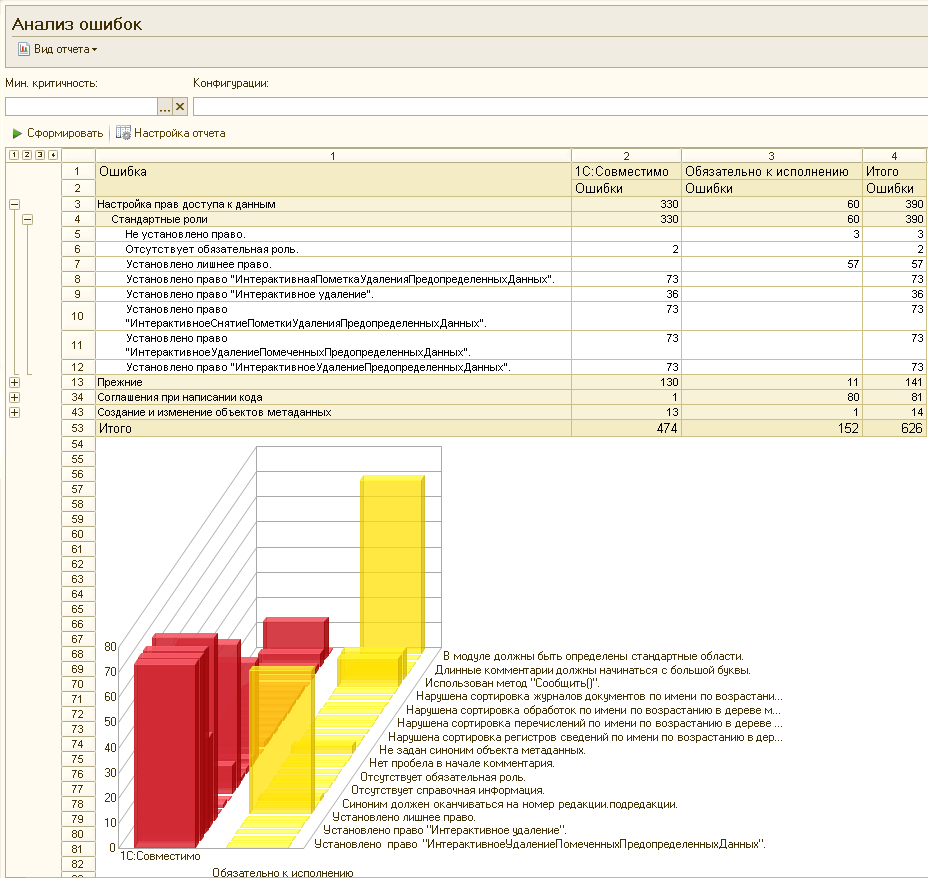
Отчеты АПК
Информацию о найденных ошибках в виде отчетов позволяют получить сразу два раздела системы. Раздел «Ошибки»:
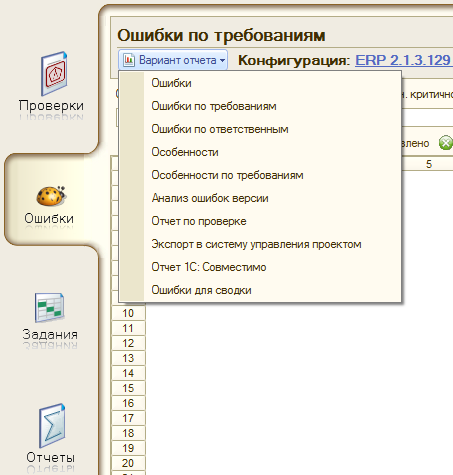
Он строится на базе отчета НайденныеОшибки:
И раздел “Отчеты”
Он строится на базе отчета “Результаты работы”:
На самом деле в конфигурации АПК всего два основных объекта “Отчет”. Но у них довольно много различных макетов СКД:

Все они базируются на анализе регистра сведений «НайденныеОшибки». Раздел “Отчеты” предназначен для получения сводной информации по ошибкам, у него статистическая направленность, в то время как раздел “Ошибки” — для получения детальной информации по ошибкам и управления ими. В разделе “Ошибки” управление возможно как с помощью специальной командной панели, так и через контекстное меню:
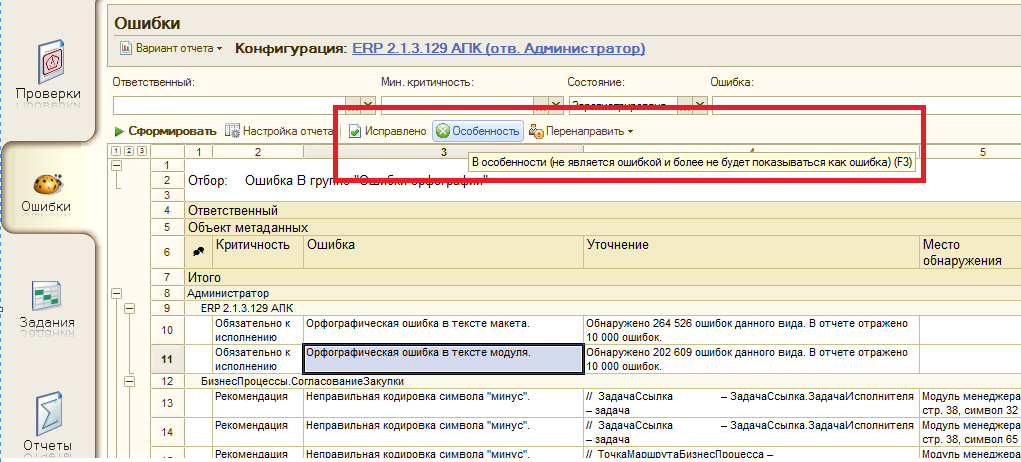
При использовании файловой базы АПК и 32-разрядной платформы 1С наблюдается проблема. Если не установить достаточное количество фильтров, то при анализе ошибок большой конфигурации можно получить сообщение о нехватке памяти. В случае ERP 2.x такое сообщение будет появляться постоянно. Происходит эта ошибка обычно уже на этапе вывода данных в табличный документ. В общем стоит ставить фильтры. В быстрые отборы вынесены всего несколько из них. Остальные можно установить по команде “Настройка отчета”.
Здесь мешает то, что отчеты начинают формироваться сразу после выбора варианта. Это сильно мешает работе и наводит на мысль о необходимости доработки конфигурации АПК вплоть до написания собственных отчетов: хочется и отборы накладывать до их формирования, и чтобы настройки отчетов сохранялись, и чтобы на управляемой форме они были. Благо на основе всего одного регистра сведений это сделать не сложно.
Замечу, что при использовании 64-разрядной версии 1С или sql-ной базы АПК ошибка с нехваткой памяти не наблюдается.
После первого взгляда на отчеты, кажется, что АПК слишком придирчива к проверяемой конфигурации. Например требует задания правильных синонимов даже для макетов печатных форм, воспринимает как ошибку слова “логистических”, “допоставить”, “подотчетниками” и т.д. Но во первых, большая часть найденных ошибок действительно требует исправления! Во вторых, выбор проверяемых правил предоставлен пользователю, его можно сделать как при настройке проверяемой конфигурации, так и при выполнении проверки. В третьих, каждое из правил можно при желании доработать, заменить своим, либо настроить фильтрацию в отчетах таким образом, чтобы видеть только интересующую информацию.
И наконец, в системе имеются и другие возможности настройки. Например регистр сведений “ВерныеСлова” (изначально пустой). Он участвует в проверке правописания, в частности методе Проверка.ПроверитьПравописание(). Слова, которые мы считаем верными в него можно внести вручную или загрузить из текстового файла, в котором каждое слово находится в отдельной строке. Образец такого txt-файла можно выгрузить из общего макета “СловарьВерныхСлов”. Но загружать этот файл в регистр не нужно. По умолчанию система итак берет верные слова из этого макета и дополняет его данными из регистра. Также в системе существует обработка «Актуализация словаря«. Очень подробно и понятно ее применение описано в руководстве пользователя (см. главу 4.6).
В общем, если покажется, что система слишком строга к нашим конфигурациям, то можно ее подкрутить в нужных местах и “задобрить” ))
Наиболее интересными отчетами являются “Ошибки по требованиям” в разделе “Ошибки”, который выводит данные в группировке , соответствующей структуре справочника “Требования”:
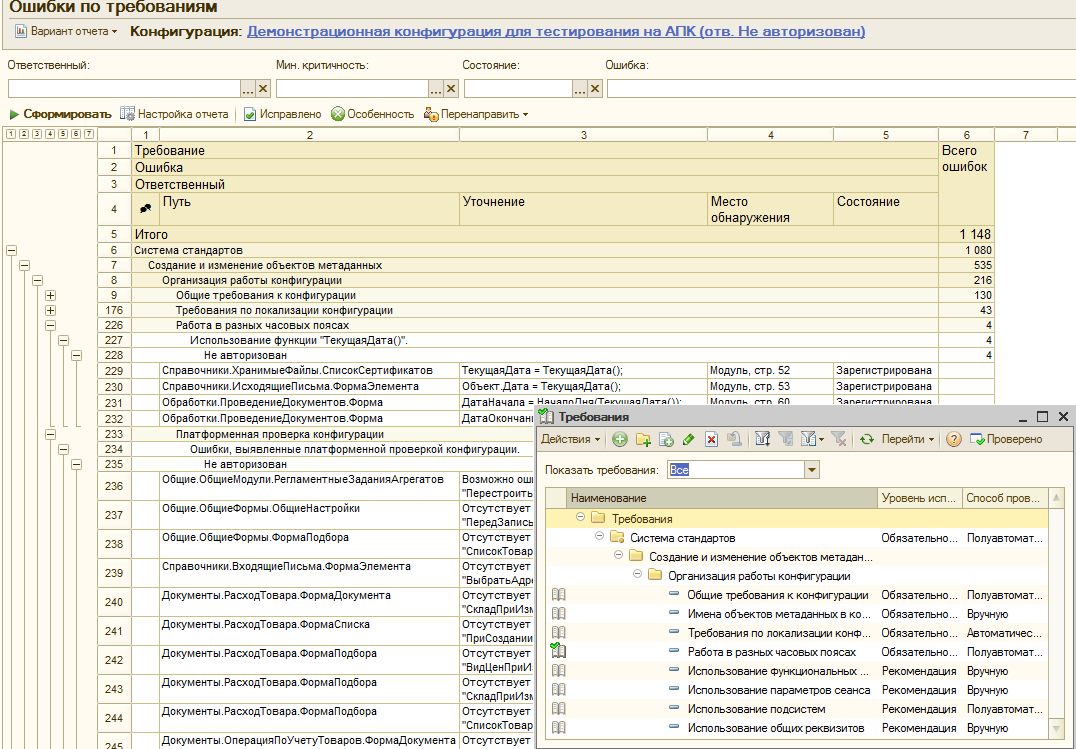
и “Анализ ошибок” в разделе “Отчеты”, который выводит сводные данные на основе классификации “1С:Совместимо” , “Обязательно к исполнению” и “Рекомендация”:
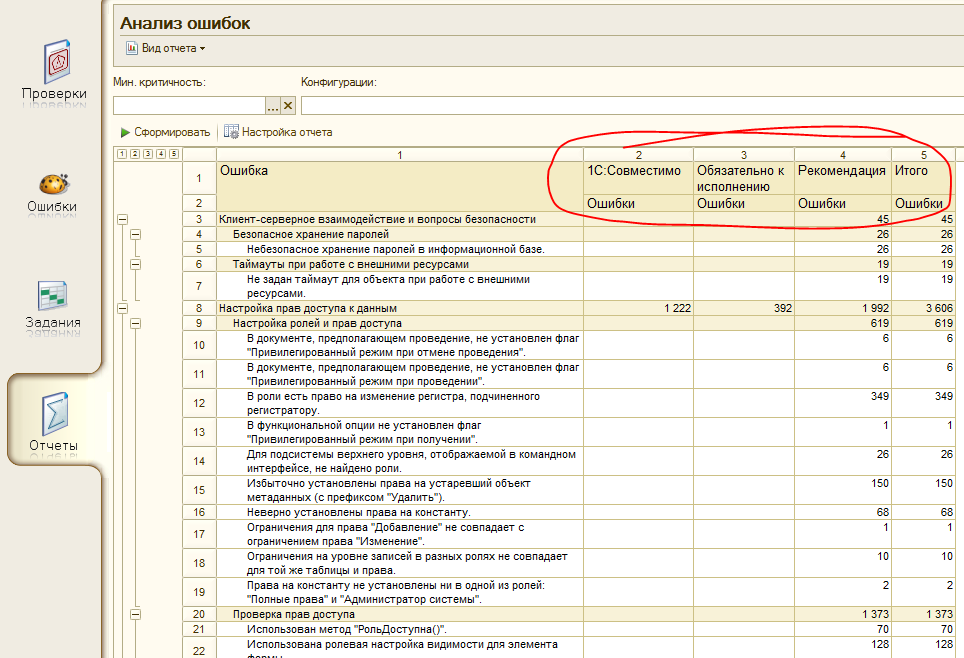
Правила проверки конфигураций
Создание собственных правил на конкретных примерах здесь рассмотрено не будет. Сначала нужно самому лучше разобраться в этом вопросе. В руководстве пользователя из поставки АПК созданию новых правил посвящена достаточно объемная Глава 5 — это сквозной пример в виде целых 30-ти страниц увлекательного текста и иллюстраций ))
Пройдемся по правилам обзорно. Находятся они в одноименном справочнике системы:
Навигация по левому дереву неудобная — выбор элемента для отображения его состава в правой части осуществляется двойным кликом. Поэтому выделенный элемент вовсе не всегда совпадает с тем, чей состав отображается справа.
Каждое правило можно открыть. Форма элемента справочника дает доступ к списку типов объектов, которые должны проверяться этим правилом, параметрам алгоритма (пронумерованный список ошибок, на которые можно ссылаться из алгоритма), самому алгоритму и его описанию, описанию требования, а также настройкам использования:
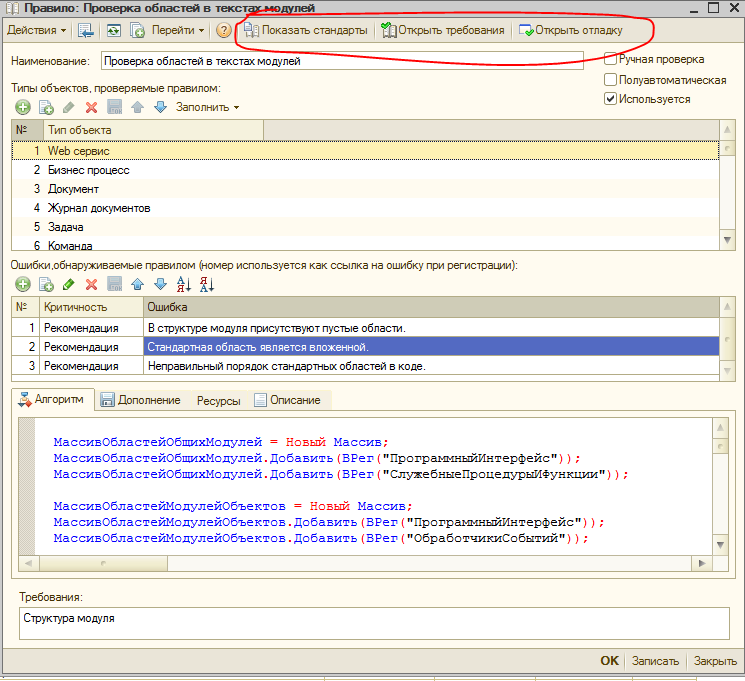
Вверху расположены три полезные кнопки. “Показать стандарты” ведет в соответствующий раздел сайта 1С с описанием стандарта, ссылка открывается в браузере. “Открыть требования” открывает соответствующий правилу элемент справочника “Требования”, и команда “Открыть отладку” запускает обработку “ОтладчикПравилПроверки”. Как она работает в руководстве пользователя умалчивается, но очевидно, что инструменты отладки либо имеются, либо есть наработки для них, которые можно развивать.
Алгоритм правила можно менять, как и создавать новые правила и группы правил. При необходимости писать свои алгоритмы придется изучать встроенные методы и программные объекты. Этому посвящен соответствующий раздел “Синтаксис правил проверки” 6-ой главы PDF-руководства пользователя. Также можно использовать алгоритмы существующих правил в качестве примеров и образцов для копирования.
Встроенная справка по программе катастрофически скудна. Вернее сказать она отсутствует, поэтому описание встроенных методов получить из нее не удастся.
Фильтрация объектов при проведении проверок
В завершение посмотрим как ведет себя АПК 1.1 при проведении проверки с наложенными фильтрами. Действительно ли они помогают сократить время проверки и уменьшить объемы информации в отчетах. Проверим как фильтрацию по префиксу, так и по подсистеме.
В этом разделе будет больше “зарывания в код”, чем рассказа о возможностях АПК. Если на данном этапе это не является вашей целью — этот раздел можно пропустить.
Возьмем все ту же подопытную конфигурацию, создадим для нее новый элемент в справочнике конфигурации (только создавать элемент нужно не копированием, так как при копировании конфигураций копируется также и их версии и структура данных, процесс это долгий и нарушает чистоту эксперимента) . Отнесем документы к двум новым подсистемам:
апк_Документ_1_1 , апк_Документ_1_2 и новый_Документ_1_3 отнесем к подсистеме апк_Подсистема_1
апк_Документ_2_1 , апк_Документ_2_2 и новый_Документ_2_3 отнесем к подсистеме апк_Подсистема_2
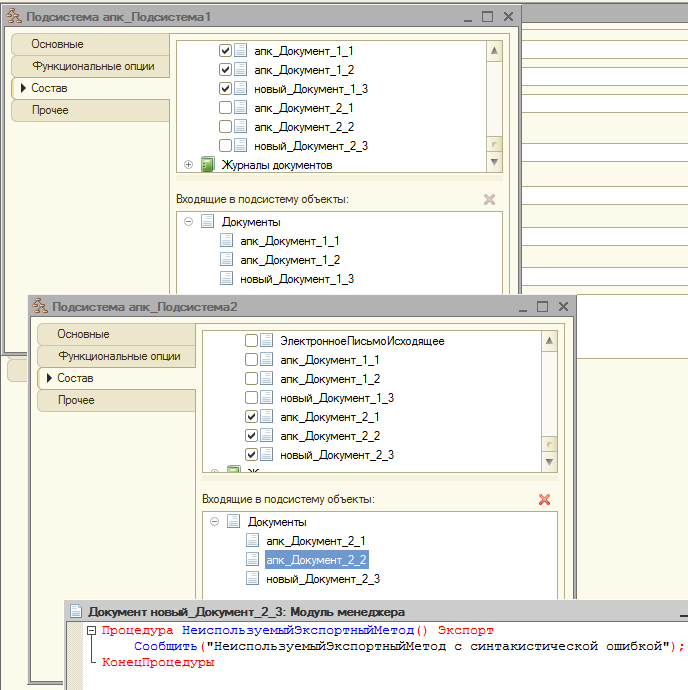
В документах допустим орфографические ошибки и добавим неиспользуемый экспортный метод в модуль менеджера. Будем создавать документы методом копирования.
Добавим два фильтра сбора сведений — на префикс апк_ и на подсистему апк_Подсистема_2 (скриншот сделан на версии АПК 1.1.11.16):
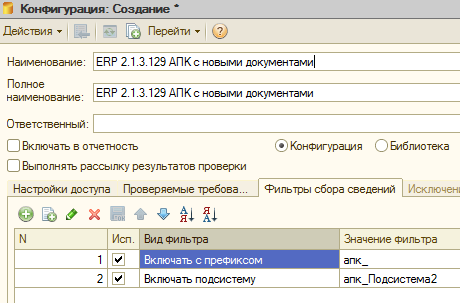
В результате проверки ожидаем увидеть появление ошибок и отчетов по ошибкам, касающихся только документов, подходящих под фильтры (как будет показано ниже, фильтры применяются по «ИЛИ»). Также хотелось бы получить ускорение процесса проверки, со скидкой на то, что часть операций и проверок выполняется независимо от количества проверяемых объектов.
Запустим проверку. Спустя пару часов базовых проверок (включая платформенную) увидим, что количество объектов для дальнейших проверок — это уже не пугающие 77 736 , а всего 65:
В результате проведения проверок отчеты действительно перестают выдавать информацию о “лишних” объектах и сообщают только об объектах, подходящих под фильтры. При этом были найдены как специально допущенные ошибки, так и сделаны другие замечания:

Однако выигрыша во времени проверки от фильтров почти не получим. В данном примере полная проверка вместо 15 часов заняла 10 , то есть ускорилась всего на 30%. В разделе «Проведение проверок» уже дано объяснение причинам такого поведения. Теперь разберемся почему так происходит на уровне кода и заодно глубже поймем как работают алгоритмы фильтрации и обхода элементов структуры конфигурации при проверках.
В отчетах видно что помимо информации о документах также собирается информация о корневом элементе конфигурации в рамках проведения общих проверок. И при проведении проверок сложно не заметить, что именно сообщение о проверке этого объекта №1 висит в строке состояния почти все 10 часов (на версии 1.1.11.16). При этом система сообщает о предстоящей проверки 65 объектов, хотя нам нужны максимум 6-8 из них. Остановим процесс в отладчике в то время, когда в строке состояния висит сообщения “Проверяется объект №1” и посмотрим, какие модули подвергаются проверкам. Можно увидеть, что на первом этапе проверки система все также анализирует все объекты, включая например зарплатные общие модули, которые точно не включены в нашу новую подсистему:
Но ведь мы не требовали от системы собирать данные об общих модулях. Что же представляют из себя те самые 65 объектов, которые будет проверять система?
Получить их список можно поднявшись по стеку вызовов к методу ПроверитьОбъекты() в модуле объекта документа “ПроверкаВерсии”. Из него также можно получить информацию, что для проверки выбираются ВСЕ объекты из справочника СтруктураКонфигурации по которым были собраны данные, или система считает, что данные были собраны:
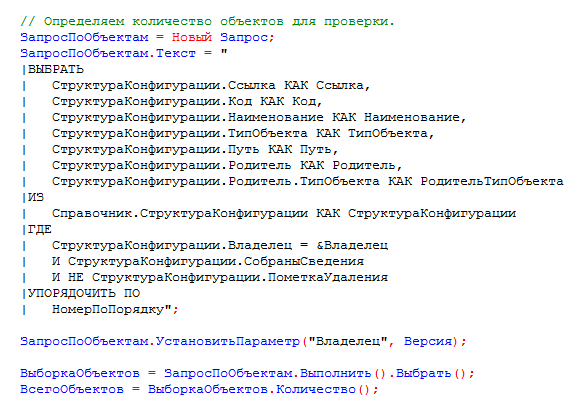
Вот эти объекты:

Самих объектов меньше чем 65, система просто посчитала не только наши документы, но и их реквизиты. Но можно заметить, что корневой элемент иерархии справочника СтруктураКонфигурации попал в этот список самым первым. И мы видели, что именно процесс его проверки занимает так много времени.
Имея список этих объектов можно сделать выводы о том, как работает механизм фильтрации и как работают проверки с учетом фильтров:
-
Фильтрация работает только на этапе сбора данных. В процессе самой проверки фильтры уже не играют никакой роли. И это логично, ведь алгоритмы задаются в пользовательском режиме. АПК лишь передает им на проверку элементы справочника СтруктураКонфигурации, если считает, что по ним собраны данные.
-
Несмотря на фильтры, наложенные нами для проверок, АПК собирает информацию о модулях ВСЕХ объектов конфигурации. Данные о модулях применяются АПК при проведении общих для всей конфигурации проверок. Ниже будет продемонстрировано, что произойдет если отключить такие проверки.
-
Часть общих объектов будет присутствовать в списке на проверку в любом случае, независимо от наших фильтров. В том числе и верхний корневой объект — сама конфигурация. Опять же, это необходимо для проведения «общих» проверок. Поскольку конфигурация, попавшая в список, по прежнему проверяется по тем же правилам что и раньше, и общие модули, их тексты и некоторые другие данные не подвергались фильтрации при сборе данных, то самая длительная многочасовая проверка объекта №1 по прежнему будет выполняться. Радикального ускорения процесса от применения фильтров получить не удастся.
-
Система решила проверять не только документы удовлетворяющие обоим нашим фильтрам, а удовлетворяющие любому из них. На проверку будут отправлены и те объекты, которые начинаются с префикса апк_ и те объекты, которые входят в подсистему апк_Подсистема2, включая документ новый_Документ_2_3. Из перечня проверяемых объектов пропал только документ новый_Документ_1_3, не подходящий ни под один фильтр. Результат станет понятен, если заглянуть в функцию фильтрации. Разрешающие фильтры работают по “ИЛИ” , а не по “И”. Если это необходимо изменить, то опять же придется внести небольшие изменения в этот метод:
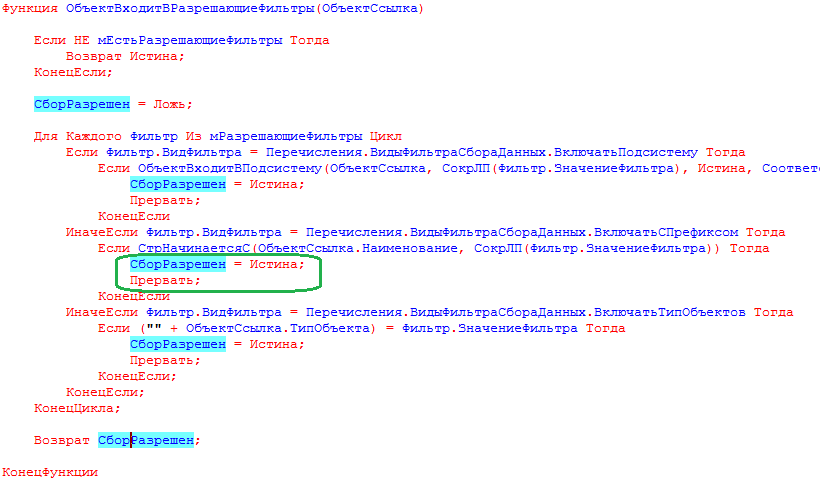
Теперь попробуем “поиграть” с кодом и посмотреть, что было бы, если бы фильтрация работала не только на этапе сбора данных, но и на этапе проверки. Создадим для этого еще один элемент справочника Конфигурации с теми же фильтрами:
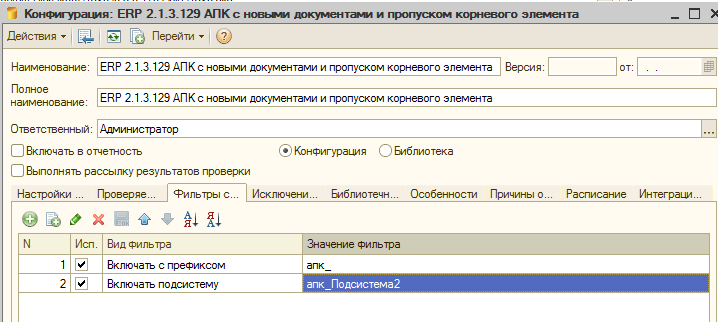
Искусственно в коде метода ПроверитьОбъекты() документа ПроверкаВерсии пропустим первый элемент выборки при обходе результата запроса. То есть пропустим корневой элемент справочника СтруктураКонфигурации:
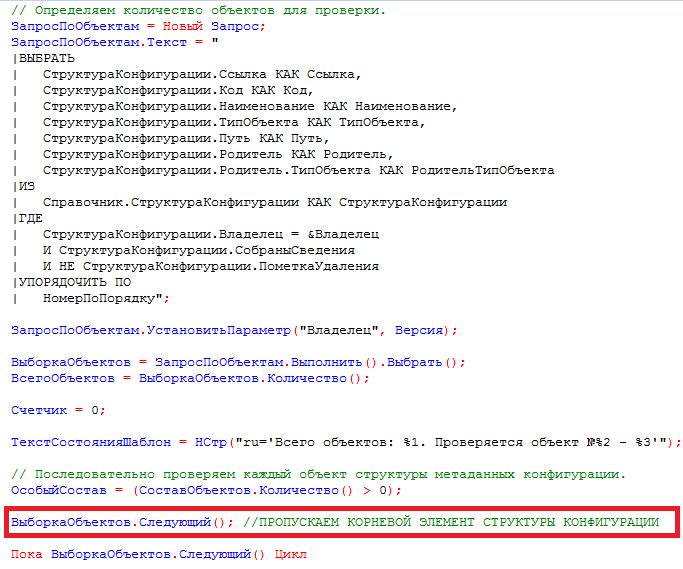
Выполним ту же самую проверку и посмотрим на время, которое уйдет на весь процесс и на то, не будут ли отличаться результаты отчетов от тех, что получаются без пропуска корня конфигураци.
В этом случае от старта процесса до его завершения проходит всего 50 минут вместо 10 часов:
[11.01.2023 20:51:37]: Создан документ Проверка версии 8 от 11.01.2023 20:51:37
………………..
[11.01.2023 21:10:21]: Начало выгрузки конфигурации в файлы XML
[11.01.2023 21:19:48]: Выгрузка конфигурации в файлы XML завершена
………………..
[11.01.2023 21:34:10]: Стартовала проверка конфигурации
[11.01.2023 21:39:16]: Выполнена проверка конфигурации
Теперь отчет:
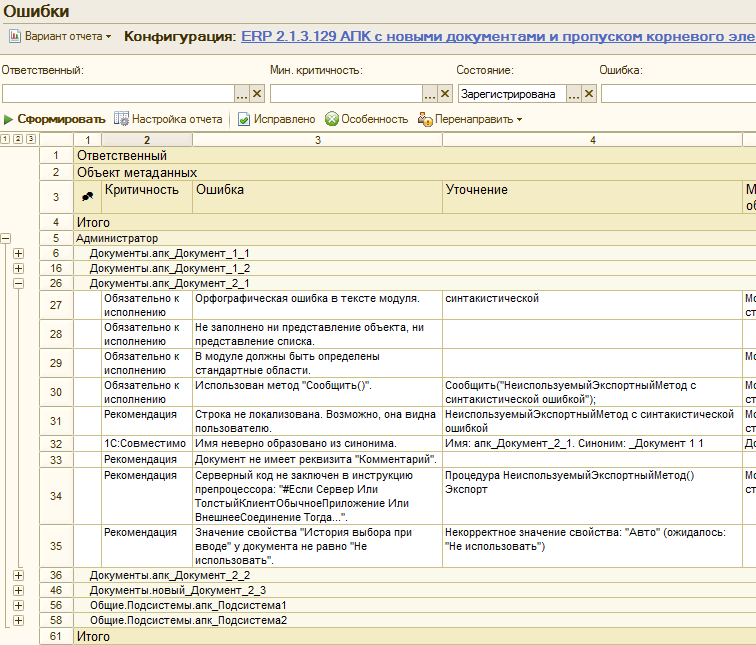
Видно что больше не выводится корневой элемент. Но кроме того в отчете отображается 9 строк вместо 10, касающиеся каждого документа. Пропали строки, сообщающие о неиспользуемых экспортных методах в модулях менеджеров документов. То есть часть ошибок действительно выявляется только если в процессе проверки задействован корневой элемент справочника СтруктураКонфигурации. Иначе соответствующие правила проверки просто не отрабатывают. Это ошибки, при выявлении которых по логике должна проверяться взаимосвязь объекта со всеми остальными объектами конфигурации.
Таким образом, если мы хотим радикально ускорить проверки при применении фильтров, то это нужно делать либо путем отключения наиболее длительных общих проверок, требующих обхода всех модулей (это можно сделать в настройках), либо путем разработки собственных альтернативных правил проверки.
Итог:
-
Инструмент “Автоматическое тестирование конфигураций” действительно позволяет будучи однажды настроенным находить ошибки в конфигурациях в автоматическом режиме. АПК дает возможность найти грубые ошибки в конфигурации, исправить орфографию, привести в соответствие ко вполне разумным и обоснованным стандартам разработки от фирмы 1С.
-
АПК не может стать полной заменой другим инструментам повышения качества кода, таким как код-ревью. Она не позволяет отследить наличие излишней копи-пасты (дублирования кода), нескольких серверных вызовов там, где их можно упаковать в один, или проверить наличие простейших признаков неоптимальности запроса. Но позволяет значительно уменьшить необходимость в визуальном контроле и стать хорошей отправной точкой для применения других инструментов и практик. А при необходимости написать свои проверки, которые решают больше задач чем те, что есть “из коробки”.
-
Несмотря на нехватку информации по нему, освоение этого инструмента для начала использования на практике не сложное. Наличие руководства пользователя, а теперь и этой статьи, могут дать хороший старт для пошагового освоения. Сама конфигурация АПК достаточно простая и легко дорабатывается, по крайней мере в плане интерфейса. Дорабатывать действительно есть что. Для комфортного и эффективного использования нашим “танкам” всегда нужен напильник ))
-
Разработка своих правил проверки требует освоения “встроенного языка” АПК, точнее встроенных процедур и функций, сделать это можно воспользовавшись руководством пользователя и существующими правилами.
-
Даже простейшие операции, требующие сбора данных из таких конфигураций как ERP, занимают у АПК более 20 минут. Поэтому, для разработки и отладки своих правил проверки следует либо создавать свои небольшие демо-конфигурации и демо-базы, в которых некоторые модули будут это правило нарушать, либо проводить проверки по ранее собранным данным. Оба приема помогут ускорить процесс отладки новых правил.
- В конфигурации есть инструменты для отладки новых и существующих правил. Для работы с ними необходимо разбираться с кодом конфигурации АПК , смотреть как создаются объекты и в каком контексте выполняются заданные в пользовательском режиме алгоритмы. Но при желании это кажется вполне возможным, подходы должны быть аналогичны тем, что мы применяем в “Конвертации данных”.