Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 15 июля 2021 года; проверки требуют 10 правок.
Advanced Vector Extensions (AVX) — расширение системы команд x86 для микропроцессоров Intel и AMD, предложенное Intel в марте 2008.[1]
AVX предоставляет различные улучшения, новые инструкции и новую схему кодирования машинных кодов.
Улучшения[править | править код]
- Новая схема кодирования инструкций VEX
- Ширина векторных регистров SIMD увеличивается с 128 (XMM) до 256 бит (регистры YMM0 — YMM15). Существующие 128-битные SSE-инструкции будут использовать младшую половину новых YMM-регистров, не изменяя старшую часть. Для работы с YMM-регистрами добавлены новые 256-битные AVX-инструкции. В будущем возможно расширение векторных регистров SIMD до 512 или 1024 бит. Например, процессоры с архитектурой Xeon Phi уже в 2012 году имели векторные регистры (ZMM) шириной в 512 бит[2], и используют для работы с ними SIMD-команды с MVEX- и VEX-префиксами, но при этом они не поддерживают AVX. [источник не указан 2798 дней]
- Неразрушающие операции. Набор AVX-инструкций использует трёхоперандный синтаксис. Например, вместо
можно использовать
, при этом регистр
остаётся неизменённым. В случаях, когда значение
- Для большинства новых инструкций отсутствуют требования к выравниванию операндов в памяти. Однако рекомендуется следить за выравниванием на размер операнда во избежание значительного снижения производительности.[3]
- Набор инструкций AVX содержит в себе аналоги 128-битных SSE-инструкций для вещественных чисел. При этом, в отличие от оригиналов, сохранение 128-битного результата будет обнулять старшую половину YMM-регистра. 128-битные AVX-инструкции сохраняют прочие преимущества AVX, такие как новая схема кодирования, трехоперандный синтаксис и невыровненный доступ к памяти.
- Intel рекомендует отказаться от старых SSE-инструкций в пользу новых 128-битных AVX-инструкций, даже если достаточно двух операндов.[4].
Новая схема кодирования[править | править код]
Новая схема кодирования инструкций VEX использует VEX-префикс. В настоящий момент существуют два VEX-префикса, длиной 2 и 3 байта. Для 2-байтного VEX-префикса первый байт равен 0xC5, для 3-байтного — 0xC4.
В 64-битном режиме первый байт VEX-префикса уникален. В 32-битном режиме возникает конфликт с инструкциями LES и LDS, который разрешается старшим битом второго байта, он имеет значение только в 64-битном режиме, через неподдерживаемые формы инструкций LES и LDS.[3]
Длина существующих AVX-инструкций, вместе с VEX-префиксом, не превышает 11 байт. В следующих версиях ожидается появление более длинных инструкций.
Новые инструкции[править | править код]
| Инструкция | Описание |
|---|---|
| VBROADCASTSS, VBROADCASTSD, VBROADCASTF128 | Копирует 32-, 64- или 128-битный операнд из памяти во все элементы векторного регистра XMM или YMM. |
| VINSERTF128 | Замещает младшую или старшую половину 256-битного регистра YMM значением 128-битного операнда. Другая часть регистра-получателя не изменяется. |
| VEXTRACTF128 | Извлекает младшую или старшую половину 256-битного регистра YMM и копирует в 128-битный операнд-назначение. |
| VMASKMOVPS, VMASKMOVPD | Условно считывает любое количество элементов из векторного операнда из памяти в регистр-получатель, оставляя остальные элементы несчитанными и обнуляя соответствующие им элементы регистра-получателя. Также может условно записывать любое количество элементов из векторного регистра в векторный операнд в памяти, оставляя остальные элементы операнда памяти неизменёнными. |
| VPERMILPS, VPERMILPD | Переставляет 32- или 64-битные элементы вектора согласно операнду-селектору (из памяти или из регистра). |
| VPERM2F128 | Переставляет 4 128-битных элемента двух 256-битных регистров в 256-битный операнд-назначение с использованием непосредственной константы (imm) в качестве селектора. |
| VZEROALL | Обнуляет все YMM-регистры и помечает их как неиспользуемые. Используется при переключении между 128-битным режимом и 256-битным. |
| VZEROUPPER | Обнуляет старшие половины всех регистров YMM. Используется при переключении между 128-битным режимом и 256-битным. |
Также в спецификации AVX описана группа инструкций PCLMUL (Parallel Carry-Less Multiplication, Parallel CLMUL)
- PCLMULLQLQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 00]
- PCLMULHQLQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 01]
- PCLMULLQHQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 02]
- PCLMULHQHQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 03]
- PCLMULQDQ xmmreg, xmmrm, imm [rmi: 66 0f 3a 44 /r ib]
Применение[править | править код]
Подходит для интенсивных вычислений с плавающей точкой в мультимедиа-программах и научных задачах.
Там, где возможна более высокая степень параллелизма, увеличивает производительность с вещественными числами.
Поддержка[править | править код]
- Math Kernel Library[5]
Поддержка в операционных системах[править | править код]
Использование YMM-регистров требует поддержки со стороны операционной системы. Следующие системы поддерживают регистры YMM:
- Linux: с версии ядра 2.6.30,[6] released on June 9, 2009.[7]
- Windows 7: поддержка добавлена в Service Pack 1[8]
- Windows Server 2008 R2: поддержка добавлена в Service Pack 1[8]
Микропроцессоры с AVX[править | править код]
- Intel:
- Процессоры с микроархитектурой Sandy Bridge, 2011.[9]
- Процессоры с микроархитектурой Ivy Bridge, 2012.
- Процессоры с микроархитектурой Haswell, 2013.
- Процессоры с микроархитектурой Broadwell, 2015.
- Процессоры с микроархитектурой Skylake, 2015.
- Процессоры с микроархитектурой Kaby Lake, 2017.
- Процессоры с микроархитектурой Coffee Lake, 2017.
- AMD:
- Процессоры с микроархитектурой Bulldozer, 2011.[10]
- Процессоры с микроархитектурой Piledriver, 2012.
- Процессоры с микроархитектурой Steamroller, 2014.
- Процессоры с микроархитектурой Excavator, 2015.
- Процессоры с микроархитектурой Zen, 2017.
- Процессоры с микроархитектурой Zen 2, 2019.
- Процессоры с микроархитектурой Zen 3, 2020.
Совместимость между реализациями Intel и AMD обсуждается в этой статье.
Микропроцессоры с AVX2[править | править код]
- Intel Haswell[11]
- Intel Broadwell
- Intel Skylake
- Intel Kaby Lake
- Intel Coffee Lake
- Intel Comet Lake
- Intel Rocket Lake
- Intel Alder Lake
- AMD Excavator
- AMD Zen (AMD Ryzen)
- AMD Zen 2 (AMD Ryzen)
- AMD Zen 3 (AMD Ryzen)
AVX-512[править | править код]
AVX-512 расширяет систему команд AVX до векторов длиной 512 бит при помощи кодировки с префиксом EVEX. Расширение AVX-512 вводит 32 векторных регистра (ZMM), каждый по 512 бит, 8 регистров масок, 512-разрядные упакованные форматы для целых и дробных чисел и операции над ними, тонкое управление режимами округления (позволяет переопределить глобальные настройки), операции broadcast (рассылка информации из одного элемента регистра в другие), подавление ошибок в операциях с дробными числами, операции gather/scatter (сборка и рассылка элементов векторного регистра в/из нескольких адресов памяти), быстрые математические операции, компактное кодирование больших смещений. AVX-512 предлагает совместимость с AVX, в том смысле, что программа может использовать инструкции как AVX, так и AVX-512 без снижения производительности. Регистры AVX (YMM0-YMM15) отображаются на младшие части регистров AVX-512 (ZMM0-ZMM15), по аналогии с SSE и AVX регистрами.[12]
Используeтся в Intel Xeon Phi (ранее Intel MIC) Knights Landing (версия AVX3.1), Intel Skylake-X,[12] Intel Ice Lake, Intel Tiger Lake, Intel Rocket Lake. Также поддержка AVX-512 имеется в производительных ядрах Golden Cove[13] процессоров Intel Alder Lake, однако энергоэффективные ядра Gracemont её лишены. По состоянию на декабрь 2021 г. поддержка AVX-512 для потребительских процессоров Alder Lake официально не заявляется.[14]
Будущие расширения[править | править код]
Схема кодирования инструкций VEX легко допускает дальнейшее расширение набора инструкций AVX. В следующей версии, AVX2, добавлены инструкции для работы с целыми числами, FMA3 (увеличил производительность при обработке чисел с плавающей запятой в 2 раза[11]), загрузку распределенного в памяти вектора (gather) и прочее.
Различные планируемые дополнения системы команд x86:
- AES
- CLMUL
- Intel/AMD FMA3
- AMD FMA4
- AMD XOP
- AMD CVT16
В серверных процессорах поколения Broadwell добавлены расширения AVX 3.1, а в серверных процессорах поколения Skylake — AVX 3.2.
Примечания[править | править код]
- ↑ ISA Extensions | Intel® Software. Дата обращения: 24 июня 2016. Архивировано 6 мая 2019 года.
- ↑ Intel® Xeon Phi™ Coprocessor Instruction Set Architecture Reference Manual (недоступная ссылка — история). Архивировано 11 мая 2013 года.
- ↑ 1 2 Introduction to Intel® Advanced Vector Extensions — Intel® Software Network. Дата обращения: 19 июля 2012. Архивировано 16 июня 2012 года.
- ↑ Questions about AVX — Intel® Software Network. Дата обращения: 24 июня 2016. Архивировано 7 августа 2016 года.
- ↑ Intel® AVX optimization in Intel® MKL. Дата обращения: 7 января 2014. Архивировано 7 января 2014 года.
- ↑ x86: add linux kernel support for YMM state (недоступная ссылка — история). Дата обращения: 13 июля 2009. Архивировано 5 апреля 2012 года.
- ↑ Linux 2.6.30 — Linux Kernel Newbies (недоступная ссылка — история). Дата обращения: 13 июля 2009. Архивировано 5 апреля 2012 года.
- ↑ 1 2 Enable Windows 7 Support for Intel AVX (недоступная ссылка — история). Microsoft. Дата обращения: 29 января 2011. Архивировано 5 апреля 2012 года.
- ↑ Intel Offers Peek at Nehalem and Larrabee. ExtremeTech (17 марта 2008). Архивировано 7 июня 2011 года.
- ↑ Striking a balance (недоступная ссылка — история). Dave Christie, AMD Developer blogs (7 мая 2009). Дата обращения: 8 мая 2009. Архивировано 5 апреля 2012 года.
- ↑ 1 2 More details on the future AVX instruction set 2.0 | Tech News Pedia. Дата обращения: 14 ноября 2012. Архивировано из оригинала 31 октября 2012 года.
- ↑ 1 2 James Reinders (23 July 2013), AVX-512 Instructions, Intel, <http://software.intel.com/en-us/blogs/2013/avx-512-instructions>. Проверено 20 августа 2013. Источник. Дата обращения: 18 ноября 2013. Архивировано 31 марта 2015 года.
- ↑ Dr Ian Cutress, Andrei Frumusanu. Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed. www.anandtech.com. Дата обращения: 23 декабря 2021. Архивировано 4 января 2022 года.
- ↑ Product Specifications (англ.). www.intel.com. Дата обращения: 23 декабря 2021.
Ссылки[править | править код]
- Intel Advanced Vector Extensions Programming Reference (319433-011)(pdf) (англ.)
- Использование Intel AVX: пишем программы завтрашнего дня (рус.)
- Приемы использования масочных регистров в AVX512 коде (рус.)
Время на прочтение
19 мин
Количество просмотров 69K
Введение
Новый набор SIMD инструкций для x86-процессоров Intel AVX был представлен публике ещё в марте 2008 года. И хотя реализации этих инструкций в железе ждать ещё полгода, спецификацию AVX уже можно считать устоявшейся, а поддержка набора инструкций AVX добавлена в новые версии компиляторов и ассемблеров. В данной статье рассмотрены практические вопросы оптимизации для Intel AVX подпрограмм на языках C/C++ и ассемблер.
Набор команд AVX
Все команды AVX, а также некоторые другие команды, описаны в справочнике, который можно найти на сайте Intel, посвященному AVX. В некотором смысле, набор команд AVX представляет собой расширение наборов команд SSE, которые уже поддерживаются всеми современными процессорами. В частности, AVX расширяет изначально 128-битные регистры SSE до 256 бит. Новые 256-битные регистры обозначаются как ymm0-ymm15 (для 32-битной программы доступны только ymm0-ymm7); при этом 128-битные SSE регистры xmm0-xmm15 ссылаются на младшие 128 бит соответствующего AVX регистра.
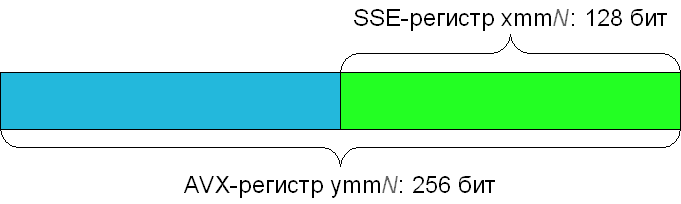
Чтобы эффективно работать с новыми 256-битными регистрами, в AVX было добавлено несметное количество инструкций. Однако, большинство из них представляет собой лишь немного изменённые версии уже знакомых нам инструкций SSE.
Так, каждая инструкция из SSE (а также SSE2, SSE3, SSSE3, SSE4.1, SSE4.2 и AES-NI) имеет в AVX свой аналог с префиксом v. Кроме префикса, такие AVX-инстукции отличаются от своих SSE-собратьев тем, что могут иметь три операнда: первый операнд указывает, куда писать результат, а остальные два — откуда брать данные. Трёхоперандные инструкции хороши тем, что во-первых позволяют избавиться от лишних операций копирования регистров в коде, а во-вторых упрощают написание хороших оптимизирующих компиляторов. SSE2-код
movdqa xmm2, xmm0
punpcklbw xmm0, xmm1
punpckhbw xmm2, xmm1
может быть переписан с AVX как
vpunpckhbw xmm2, xmm0, xmm1.
vpunpcklbw xmm0, xmm0, xmm1
При этом команды с префиксом v зануляют старшие 128 бит того AVX регистра, в который они пишут. Например, инструкция vpaddw xmm0, xmm1, xmm2 занулит старшие 128-бит регистра ymm0.
Кроме того, некоторые SSE-инструкции были расширены в AVX для работы с 256-битными регистрами. К таким инструкциям относятся все команды, работающие с числами с плавающей точкой (как одинарной, так и двойной точности). Например следующий AVX код
vmovapd ymm0, [esi]
vmulpd ymm0, ymm0, [edx]
vmovapd [edi], ymm0
обрабатывает сразу 4 double.
Вдобавок, AVX включает в себя некоторые новые инструкции
- vbroadcastss/vbroadcastsd/vbroadcastf128 — заполнение всего AVX регистра одним и тем же загруженным значением
- vmaskmovps/vmaskmovpd — условная загрузка/сохранение float/double чисел в AVX регистр в зависимости от знака чисел в другом AVX регистре
- vzeroupper — обнуление старших 128 бит всех AVX регистров
- vzeroall — полное обнуление всех AVX регистров
- vinsertf128/vextractf128 — вставка/получение любой 128-битной части 256-битного AVX регистра
- vperm2f128 — перестановка 128-битных частей 256-битного AVX регистра. Параметр перестановки задаётся статически.
- vpermilps/vpermilpd — перестановка float/double чисел внутри 128-битных частей 256-битного AVX регистра. При этом параметры перестановки берутся из другого AVX регистра.
- vldmxcsr/vstmxcsr — загрузка/сохранение управляющих параметров AVX (куда ж без этого!)
- xsaveopt — получение подсказки о том, какие AVX-регистры содержат данные. Эта команда сделана для разработчиков ОС и помогает им ускорить переключение контекста.
Использование AVX в ассемблерном коде
На сегодня AVX поддерживается всеми популярными ассемблерами для x86:
- GAS (GNU Assembler) — начиная с версии binutils 2.19.50.0.1, но лучше использовать 2.19.51.0.1, которая поддерживает более позднюю спецификацию AVX
- MASM — начиная с версии 10 (входит в Visual Studio 2010)
- NASM — начиная с версии 2.03, но лучше использовать последнюю версию
- YASM — начиная с версии 0.70, но лучше использовать последнюю версию
Определение поддержки AVX системой
Первое, что нужно сделать перед использованием AVX — убедиться, что система его поддерживает. В отличие от разных версий SSE, для использования AVX требуется его поддержка не только процессором, но и операционной системой (ведь она должна теперь сохранять верхние 128-бит AVX регистров при переключении контекста). К счастью, разработчики AVX предусмотрели способ узнать о поддержке этого набора инструкций операционной системой. ОС сохраняет/восстанавливает контекст AVX с помощью специальных инструкций XSAVE/XRSTOR, а конфигурируются эти команды с помощью расширенных контрольных регистров (extended control register). На сегодня есть только один такой регистр — XCR0, он же XFEATURE_ENABLED_MASK. Получить его значение можно, записав в ecx номер регистра (для XCR0 это, естественно, 0) и вызвав команду XGETBV. 64-битное значение регистра будет сохранено в паре регистров edx:eax. Выставленный нулевой бит регистра XFEATURE_ENABLED_MASK означает, что команда XSAVE сохраняет состояние FPU-регистров (впрочем, этот бит всегда выставлен), выставленный первый бит — сохранение SSE-регистров (младшие 128 бит AVX регистра), а выставленный второй бит — сохранение старших 128 бит AVX регистра. Т.о. чтобы быть уверенным, что система сохраняет состояние AVX регистров при переключении контекстов, нужно убедиться, что в регистре XFEATURE_ENABLED_MASK выставлены биты 1 и 2. Однако, это ещё не всё: прежде, чем вызывать команду XGETBV, нужно убедиться, что ОС действительно использует инструкции XSAVE/XRSTOR для управления контекстами. Делается это с помощью вызова инструкции CPUID с параметром eax = 1: если ОС включила управление сохранением/восстановлением контекста с помощью инструкций XSAVE/XRSTOR, то после выполениния CPUID в 27-ом бите регистра ecx будет единица. Вдобавок, неплохо бы проверить, что сам процессор поддерживает набор инструкций AVX. Делается это аналогично: вызвать CPUID с eax = 1 и убедиться, что после этого в 28-ом бите регистра ecx находится единица. Всё вышесказанное можно выразить следующим кодом (скопированном, с небольшими изменениями, из Intel AVX Reference):
; extern "C" int isAvxSupported()
_isAvxSupported:
xor eax, eax
cpuid
cmp eax, 1 ; Поддерживает ли CPUID параметр eax = 1?
jb not_supported
mov eax, 1
cpuid
and ecx, 018000000h ; Проверяем, что установлены биты 27 (ОС использует XSAVE/XRSTOR)
cmp ecx, 018000000h ; и 28 (поддержка AVX процессором)
jne not_supported
xor ecx, ecx ; Номер регистра XFEATURE_ENABLED_MASK/XCR0 есть 0
xgetbv ; Регистр XFEATURE_ENABLED_MASK теперь в edx:eax
and eax, 110b
cmp eax, 110b ; Убеждаемся, что ОС сохраняет AVX регистры при переключении контекста
jne not_supported
mov eax, 1
ret
not_supported:
xor eax, eax
ret
Использование AVX-инструкций
Теперь, когда вы знаете, когда можно использовать AVX-инструкции, самое время перейти к их использованию. Программирование под AVX мало отличается от программирования под другие наборы инструкций, но нужно учесть следующие особенности:
- Крайне нежелательно смешивать SSE- и AVX-инструкции (в том числе AVX-аналоги SSE-инструкций). Чтобы перейти от выполнения AVX-инструкций к SSE-инструкциям процессор сохраняет в специальном кэше верхние 128 бит AVX регистров, на что может уйти полсотни тактов. Когда после SSE-инструкций процессор снова вернётся к выполнению AVX-инструкций, он восстановит верхние 128 бит AVX регистров, на что уйдёт ещё полсотни тактов. Поэтому смешивание SSE и AVX инструкций приведёт к заметному снижению производительности. Если вам нужна какая-то команда из SSE в AVX-коде, воспользуйтесь её AVX-аналогом с префиксом v.
- Сохранения верхней части AVX регистров при переходе к SSE-коду можно избежать, если занулить верхние 128 бит AVX регистров с помощью команды vzeroupper или vzeroall. Несмотря на то, что эти команды зануляют все AVX регистры, они работают очень быстро. Правилом хорошего тона будет использовать одну из этих команд перед выходом из подпрограммы, использующей AVX.
- Команды загрузки/сохранения выровненных данных vmovaps/vmovapd/vmovdqa требуют, чтобы данные были выровнены на 16 байт, даже если сама команда загружает 32 байта.
- На Windows x64 подпрограмма не должна изменять регистры xmm6-xmm15. Т.о., если вы используете эти регистры (или соответствующие им регистры ymm6-ymm15), вы должны сохранить их в стеке в начале подпрограммы и восстановить из стека перед выходом из подпрограммы.
- Ядро Sandy Bridge будет способно запускать на выполнение две 256-битные AVX-команды с плавающей точкой каждый такт (одно умножение и одно сложение) благодаря расширению исполнительных устройств до 256 бит. Ядро Bulldozer будет иметь два универсальных 128-битных исполнительных устройства для команд с плавающей точкой, что позволит ему выполнять одну 256-битную AVX-команду за такт (умножение, сложение либо совмещённое умножение и сложение (fused multiply-add); при использовании последней операции можно надеяться на такую же производительность, как и у Sandy Bridge).
Теперь вы знаете всё, чтобы писать код с использованием AVX. Например, такой:
; extern "C" double _vec4_dot_avx( double a[4], double b[4] )
_vec4_dot_avx:
%ifdef X86
mov eax, [esp + 8 + 0] ; eax = a
mov edx, [esp + 8 + 8] ; edx = b
vmovupd ymm0, [eax] ; ymm0 = *a
vmovupd ymm1, [edx] ; ymm1 = *b
%else
vmovupd ymm0, [rcx] ; ymm0 = *a
vmovupd ymm1, [rdx] ; ymm1 = *b
%endif
vmulpd ymm0, ymm0, ymm1 ; ymm0 = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
vperm2f128 ymm1, ymm0, ymm0, 010000001b ; ymm1 = ( +0.0, +0.0, a3 * b3, a2 * b2 )
vaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
vxorpd xmm1, xmm1, xmm1 ; ymm1 = ( +0.0, +0.0, +0.0, +0.0 )
vhaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
%ifdef X86 ; На 32-битной архитектуре возвращаемые числа с плавающей точкой должны быть в st(0)
sub esp, 8
vmovsd [esp], xmm0
vzeroall ; Содержимое SSE-регистров не важно: зануляем полностью
fld qword [esp]
add esp, 8
%else
vzeroupper ; В xmm0 содержится возвращаемое значение, поэтому зануляем только верхние 128 бит
%endif
ret
Тестирование AVX кода
Чтобы убедиться в работоспособности AVX кода лучше написать к нему Unit-тесты. Однако встаёт вопрос: как запустить эти Unit-тесты, если ни один ныне продаваемый процессор не поддерживает AVX? В этом вам поможет специальная утилита от Intel — Software Development Emulator (SDE). Всё, что умеет SDE — это запускать программы, на лету эмулируя новые наборы инструкций. Разумеется, производительность при этом будет далека от таковой на реальном железе, но проверить корректность работы программы таким образом можно. Использовать SDE проще простого: если у вас есть unit-тест для AVX кода в файле avx-unit-test.exe и его нужно запускать с параметром «Hello, AVX!», то вам просто нужно запустить SDE с параметрами
sde -- avx-unit-test.exe "Hello, AVX!"
При запуске программы SDE сэмулирует не только AVX инструкции, но также и инструкции XGETBV и CPUID, так что если вы используете предложенный ранее метод для детектирования поддержки AVX, запущенная под SDE программа решит, что AVX действительно поддерживается. Кроме AVX, SDE (вернее, JIT-компилятор pin, на котором SDE построен) умеет эмулировать SSE3, SSSE3, SSE4.1, SSE4.2, SSE4a, AES-NI, XSAVE, POPCNT и PCLMULQDQ инструкции, так что даже очень старый процессор не помешает вам разрабатывать софт под новые наборы инструкций.
Оценка производительности AVX кода
Некоторое представление о производительности AVX кода можно получить с помощью другой утилиты от Intel — Intel Architecture Code Analyzer (IACA). IACA позволяет оценить время выполнения линейного участка кода (если встречаются команды условных переходов, IACA считает, что переход не происходит). Чтобы использовать IACA, нужно сначала пометить специальными маркерами участки кода, которые вы хотите проанализировать. Маркеры выглядят следующим образом:
; Начало участка кода, который надо проанализировать
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
; Конец участка кода, который надо проанализировать
%macro IACA_END 0
mov ebx, 222
db 0x64, 0x67, 0x90
%endmacro
Теперь следует окружить этими макросами тот участок кода, который вы хотите проанализировать
IACA_START
vmovups ymm0, [ecx]
vbroadcastss ymm1, [edx]
vmulps ymm0, ymm0, ymm1
vmovups [ecx], ymm0
vzeroupper
IACA_END
Скомпилированный с этими макросами объектный файл нужно скормить IACA:
iaca -32 -arch AVX -cp DATA_DEPENDENCY -mark 0 -o avx-sample.txt avx-sample.obj
Параметры для IACA нужно понимать так
- -32 — означает, что входной объектный файл (MS COFF) содержит 32-битный код. Для 64-битного кода нужно указывать -64. Если на вход IACA подаётся не объектный файл (.obj), а исполняемый модуль (.exe или .dll), то этот аргумент можно не указывать.
- -arch AVX — показывает IACA, что нужно анализировать производительность этого кода на будущем процессоре Intel с поддержкой AVX (т.е. Sandy Bridge). Другие возможные значения: -arch nehalem и -arch westmere.
- -cp DATA_DEPENDENCY просит IACA показать, какие инструкции находятся на критическом путе для данных (т.е. какие инструкции нужно соптимизировать, чтобы результат работы этого кода вычислялся быстрее). Другое возможное значение: -cp PERFORMANCE просит IACA показать, какие инструкции «затыкают» конвеер процессора.
- -mark 0 говорит IACA проанализировать все помеченные маркерами участки кода. Если задать -mark n, IACA будет анализировать только n-ый размеченный участок кода.
- -o avx-sample задаёт имя файла, в который будут записаны результаты анализа. Можно опустить этот параметр, тогда результаты анализа будут выведены в консоль.
Результат запуска IACA приведён ниже:
Intel(R) Architecture Code Analyzer Version - 1.1.3
Analyzed File - avx-sample.obj
Binary Format - 32Bit
Architecture - Intel(R) AVX
*******************************************************************
Intel(R) Architecture Code Analyzer Mark Number 1
*******************************************************************
Analysis Report
---------------
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
Port Binding in cycles:
-------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |
-------------------------------------------------------
| Cycles | 1 | 0 | 0 | 2 | 2 | 1 | 1 | 2 | 1 |
-------------------------------------------------------
N - port number, DV - Divider pipe (on port 0), D - Data fetch pipe (on ports 2 and 3)
CP - on a critical Data Dependency Path
N - number of cycles port was bound
X - other ports that can be used by this instructions
F - Macro Fusion with the previous instruction occurred
^ - Micro Fusion happened
* - instruction micro-ops not bound to a port
@ - Intel(R) AVX to Intel(R) SSE code switch, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
------------------------------------------------------------
| 1 | | | | 1 | 2 | X | X | | | CP | vmovups ymm0, ymmword ptr [ecx]
| 2^ | | | | X | X | 1 | 1 | | 1 | | vbroadcastss ymm1, dword ptr [edx]
| 1 | 1 | | | | | | | | | CP | vmulps ymm0, ymm0, ymm1
| 2^ | | | | 1 | | X | | 2 | | CP | vmovups ymmword ptr [ecx], ymm0
| 0* | | | | | | | | | | | vzeroupper
Самыми важными метриками здесь являются Total Throughput и Data Dependency Latency. Если код, который вы оптимизируете, это небольшая подпрограмма, и в программе есть зависимость по данным от её результата, то вам нужно стараться сделать Data Dependency Latency как можно меньше. В качестве примера может служить приведённый выше листинг подпрограммы vec4_dot_avx. Если же оптимизируемый код — это часть цикла, обрабатывающего большой массив элементов, то ваша задача — уменьшать Total Throughput (вообще-то эта метрика должна была бы называться Reciprocal Throughput, ну да ладно).
Использование AVX в коде на C/C++
Поддержка AVX реализована в следующих популярных компиляторах:
- Microsoft C/C++ Compiler начиная с версии 16 (входит в Visual Studio 2010)
- Intel C++ Compiler начиная с версии 11.1
- GCC начиная с версии 4.4
Для использования 256-битных инструкций AVX в дистрибутив этих компиляторов включен новый заголовочный файл immintrin.h с описанием соответствующих intrinsic-функций. Включение этого заголовочного файла автоматически влечёт за собой включение заголовочных файлов всех SSE-intrinsic’ов. Что касается 128-битных инструкций AVX, то для них нет ни только отдельных хидеров, но и отдельных intrinsics-функций. Вместо этого для них используются intrinsic-функции для SSEx-инструкций, а тип инструкций (SSE или AVX), в которые будут компилироваться вызовы этих intrinsic-функций задаётся в параметрах компилятора. Это означает, что смешать SSE и AVX формы 128-битных инструкций в одном компилируемом файле не получится, и если вы хотите иметь и SSE, и AVX версии функций, то вам придётся писать их в разных компилируемых файлах (и компилировать эти файлы с разными параметрами). Параметры компиляции, которые включают компиляцию SSEx intrinsic-функций в AVX инструкции следующие:
- /arch:AVX — для Microsoft C/C++ Compiler и Intel C++ Compiler под Windows
- -mavx — для GCC и Intel C++ Compiler под Linux
- /QxAVX — для Intel C++ Compiler
- /QaxAVX — для Intel C++ Compiler
Следует иметь в виду, что данные команды не только изменяют поведение SSEx intrinsic-функций, но и разрешают компилятору генерировать AVX инструкции при компиляции обычного C/C++ кода (/QaxAVX говорит Интеловскому компилятору сгенерировать две версии кода — с AVX инструкциями и с базовыми x86 инструкциями).
Чтобы со всеми этими intrinsic’ами было проще разобраться, Intel сделал интерактивный справочник — Intel Intrinsic Guide, который включает в себя описание всех intrinsic-функций, которые поддерживаются интеловскими процессорами. Для тех инструкций, которые уже реализованы в железе, указаны также latency и throughput. Скачать этот справочник можно с сайта Intel AVX (есть версии для Windows, Linux и Mac OS X).
Определение поддержки AVX системой
В принципе, для распознавания поддержки AVX системой можно использовать приведённый ранее ассемблерный код, переписав его на inline-ассемблере, либо просто прилинковав собранный ассемблером объектный файл. Однако, если использование inline-ассемблера невозможно (например, из-за coding guidelines, либо потому, что компилятор его не поддерживает, как в случае Microsoft C/C++ Compiler’а для Windows x64), то you are in deep shit. Проблема в том, что intrinsic-функции для инструкции xgetbv не существует! Таким образом, задача разбивается на две части: проверить, что процессор поддерживает AVX (это можно сделать кроссплатформенно) и проверить, что ОС поддерживает AVX (тут уж придётся писать свой код для каждой ОС).
Проверить, что процессор поддерживает AVX можно используя всё ту же инструкцию CPUID, для которой есть intrinsic-функция void __cpuid( int cpuInfo[4], int infoType ). Параметр infoType задаёт значение регистра eax перед вызовом CPUID, а cpuInfo после выполнения функции будет содежать регистры eax, ebx, ecx, edx (именно в таком порядке). Т.о. получаем следующий код:
int isAvxSupportedByCpu() {
int cpuInfo[4];
__cpuid( cpuInfo, 0 );
if( cpuInfo[0] != 0 ) {
__cpuid( cpuInfo, 1 );
return cpuInfo[3] & 0x10000000; // Возвращаем ноль, если 28-ой бит в ecx сброшен
} else {
return 0; // Процессор не поддерживает получение информации о поддерживаемых наборах инструкций
}
}
С поддержкой со стороны ОС сложнее. AVX на сегодня поддерживается следующими ОС:
- Windows 7
- Windows Server 2008 R2
- Linux с ядром 2.6.30 и выше
В Windows была добавлена возможность узнать о поддержке операционкой новых наборов инструкций в виде функции GetEnabledExtendedFeatures из kernel32.dll. К сожалению, эта функция документирована чуть менее, чем никак. Но кое-какую информацию о ней раздобыть всё же можно. Эта функция описана в файле WinBase.h из Platform SDK:
WINBASEAPI
DWORD64
WINAPI
GetEnabledExtendedFeatures(
__in DWORD64 FeatureMask
);
Значения для параметра FeatureMask можно найти в хидере WinNT.h:
//
// Known extended CPU state feature IDs
//
#define XSTATE_LEGACY_FLOATING_POINT 0
#define XSTATE_LEGACY_SSE 1
#define XSTATE_GSSE 2
#define XSTATE_MASK_LEGACY_FLOATING_POINT (1i64 << (XSTATE_LEGACY_FLOATING_POINT))
#define XSTATE_MASK_LEGACY_SSE (1i64 << (XSTATE_LEGACY_SSE))
#define XSTATE_MASK_LEGACY (XSTATE_MASK_LEGACY_FLOATING_POINT | XSTATE_MASK_LEGACY_SSE)
#define XSTATE_MASK_GSSE (1i64 << (XSTATE_GSSE))
#define MAXIMUM_XSTATE_FEATURES 64
Нетрудно заметить, что маски XSTATE_MASK_* соответствуют аналогичным битам регистра XFEATURE_ENABLED_MASK.
В дополнение к этому, в Windows DDK есть описание функции RtlGetEnabledExtendedFeatures и констант XSTATE_MASK_XXX, как две капли воды похожих на GetEnabledExtendedFeatures и XSTATE_MASK_* из WinNT.h. Т.о. для определения поддержки AVX со стороны Windows можно воспользоваться следующим кодом:
int isAvxSupportedByWindows() {
const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
}
Если ваша программа должна работать не только в Windows 7 и Windows 2008 R2, то функцию GetEnabledExtendedFeatures нужно подгружать динамически из kernel32.dll, т.к. в других версиях Windows этой функции нет.
В Linux, насколько мне известно, нет отдельной функции, чтобы узнать о поддержке AVX со стороны ОС. Но вы можете воспользоваться тем фактом, что поддержка AVX было добавлена в ядро 2.6.30. Тогда остаётся только проверить, что версия ядра не меньше этого значения. Узнать версию ядра можно с помощью функции uname.
Использование AVX-инструкций
Написание AVX-кода с использованием intrinsic-функций не вызовет у вас затруднений, если вы когда-либо использовали MMX или SSE посредством intrinsic’ов. Единственное, о чём нужно позаботиться дополнительно, это вызвать функцию _mm256_zeroupper() в конце подпрограммы (как нетрудно догадаться, эта intrinsic-функция генерирует инструкцию vzeroupper). Например, приведённая выше ассемблерная подпрограмма vec4_dot_avx может быть переписана на intrinsic’ах так:
double vec4_dot_avx( double a[4], double b[4] ) {
// mmA = a
const __m256d mmA = _mm256_loadu_pd( a );
// mmB = b
const __m256d mmB = _mm256_loadu_pd( b );
// mmAB = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
const __m256d mmAB = _mm256_mul_pd( mmA, mmB );
// mmABHigh = ( +0.0, +0.0, a3 * b3, a2 * b2 )
const __m256d mmABHigh = _mm256_permute2f128_pd( mmAB, mmAB, 0x81 );
// mmSubSum = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
const __m128d mmSubSum = _mm_add_pd(
_mm256_castpd256_pd128( mmAB ),
_mm256_castpd256_pd128( mmABHigh )
);
// mmSum = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
const __m128d mmSum = _mm_hadd_pd( mmSubSum, _mm_setzero_pd() );
const double result = _mm_cvtsd_f64( mmSum );
_mm256_zeroupper();
return result;
}
Тестирование AVX кода
Если вы используете набор инструкций AVX посредством intrinsic-функций, то, кроме запуска этого кода под эмулятором SDE, у вас есть ещё одна возможность — использовать специальный заголовочный файл, эмулирующий 256-битные AVX intrinsic-функции через intrinsic-функции SSE1-SSE4.2. В этом случае у вас получится исполняемый файл, который можно запустить на процессорах Nehalem и Westmere, что, конечно, быстрее эмулятора. Однако учтите, что таким методом не получиться обнаружить ошибки генерации AVX-кода компилятором (а они вполне могут быть).
Оценка производительности AVX кода
Использование IACA для анализа производительности AVX кода, созданного C/C++ компилятором из intrinsic-функций почти ничем не отличается от анализа ассемблерного кода. В дистрибутиве IACA можно найти заголовочный файл iacaMarks.h, в котором описаны макросы-маркеры IACA_START и IACA_END. Ими нужно пометить анализируемые участки кода. В коде подпрограммы маркер IACA_END должен находиться до оператора return, иначе компилятор «соптимизирует», выкинув код маркера. Макросы IACA_START/IACA_END используют inline-ассемблер, который не поддерживается Microsoft C/C++ Compiler для Windows x64, поэтому если для него нужно использовать специальные варианты макросов — IACA_VC64_START и IACA_VC64_END.
Заключение
В этой статье было продемонстрировано, как разрабатывать программы с использованием набора инструкций AVX. Надеюсь, что это знание поможет вам радовать своих пользователей программами, которые используют возможности компьютера на все сто процентов!
Упражнение
Приведённый код подпрограммы vec4_dot_avx не является оптимальным с точки зрения производительности. Попробуйте переписать её более оптимально. Какая у вас получалась Data Dependency Latency?
From Wikipedia, the free encyclopedia
Advanced Vector Extensions (AVX) are extensions to the x86 instruction set architecture for microprocessors from Intel and Advanced Micro Devices (AMD). They were proposed by Intel in March 2008 and first supported by Intel with the Sandy Bridge[1] processor shipping in Q1 2011 and later by AMD with the Bulldozer[2] processor shipping in Q3 2011. AVX provides new features, new instructions, and a new coding scheme.
AVX2 (also known as Haswell New Instructions) expands most integer commands to 256 bits and introduces new instructions. They were first supported by Intel with the Haswell processor, which shipped in 2013.
AVX-512 expands AVX to 512-bit support using a new EVEX prefix encoding proposed by Intel in July 2013 and first supported by Intel with the Knights Landing co-processor, which shipped in 2016.[3][4] In conventional processors, AVX-512 was introduced with Skylake server and HEDT processors in 2017.
Advanced Vector Extensions[edit]
AVX uses sixteen YMM registers to perform a single instruction on multiple pieces of data (see SIMD). Each YMM register can hold and do simultaneous operations (math) on:
- eight 32-bit single-precision floating point numbers or
- four 64-bit double-precision floating point numbers.
The width of the SIMD registers is increased from 128 bits to 256 bits, and renamed from XMM0–XMM7 to YMM0–YMM7 (in x86-64 mode, from XMM0–XMM15 to YMM0–YMM15). The legacy SSE instructions can be still utilized via the VEX prefix to operate on the lower 128 bits of the YMM registers.
| 511 256 | 255 128 | 127 0 |
| ZMM0 | YMM0 | XMM0 |
| ZMM1 | YMM1 | XMM1 |
| ZMM2 | YMM2 | XMM2 |
| ZMM3 | YMM3 | XMM3 |
| ZMM4 | YMM4 | XMM4 |
| ZMM5 | YMM5 | XMM5 |
| ZMM6 | YMM6 | XMM6 |
| ZMM7 | YMM7 | XMM7 |
| ZMM8 | YMM8 | XMM8 |
| ZMM9 | YMM9 | XMM9 |
| ZMM10 | YMM10 | XMM10 |
| ZMM11 | YMM11 | XMM11 |
| ZMM12 | YMM12 | XMM12 |
| ZMM13 | YMM13 | XMM13 |
| ZMM14 | YMM14 | XMM14 |
| ZMM15 | YMM15 | XMM15 |
| ZMM16 | YMM16 | XMM16 |
| ZMM17 | YMM17 | XMM17 |
| ZMM18 | YMM18 | XMM18 |
| ZMM19 | YMM19 | XMM19 |
| ZMM20 | YMM20 | XMM20 |
| ZMM21 | YMM21 | XMM21 |
| ZMM22 | YMM22 | XMM22 |
| ZMM23 | YMM23 | XMM23 |
| ZMM24 | YMM24 | XMM24 |
| ZMM25 | YMM25 | XMM25 |
| ZMM26 | YMM26 | XMM26 |
| ZMM27 | YMM27 | XMM27 |
| ZMM28 | YMM28 | XMM28 |
| ZMM29 | YMM29 | XMM29 |
| ZMM30 | YMM30 | XMM30 |
| ZMM31 | YMM31 | XMM31 |
AVX introduces a three-operand SIMD instruction format called VEX coding scheme, where the destination register is distinct from the two source operands. For example, an SSE instruction using the conventional two-operand form a ← a + b can now use a non-destructive three-operand form c ← a + b, preserving both source operands. Originally, AVX’s three-operand format was limited to the instructions with SIMD operands (YMM), and did not include instructions with general purpose registers (e.g. EAX). It was later used for coding new instructions on general purpose registers in later extensions, such as BMI. VEX coding is also used for instructions operating on the k0-k7 mask registers that were introduced with AVX-512.
The alignment requirement of SIMD memory operands is relaxed.[5] Unlike their non-VEX coded counterparts, most VEX coded vector instructions no longer require their memory operands to be aligned to the vector size. Notably, the VMOVDQA instruction still requires its memory operand to be aligned.
The new VEX coding scheme introduces a new set of code prefixes that extends the opcode space, allows instructions to have more than two operands, and allows SIMD vector registers to be longer than 128 bits. The VEX prefix can also be used on the legacy SSE instructions giving them a three-operand form, and making them interact more efficiently with AVX instructions without the need for VZEROUPPER and VZEROALL.
The AVX instructions support both 128-bit and 256-bit SIMD. The 128-bit versions can be useful to improve old code without needing to widen the vectorization, and avoid the penalty of going from SSE to AVX, they are also faster on some early AMD implementations of AVX. This mode is sometimes known as AVX-128.[6]
New instructions[edit]
These AVX instructions are in addition to the ones that are 256-bit extensions of the legacy 128-bit SSE instructions; most are usable on both 128-bit and 256-bit operands.
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD, VBROADCASTF128
|
Copy a 32-bit, 64-bit or 128-bit memory operand to all elements of a XMM or YMM vector register. |
VINSERTF128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTF128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VMASKMOVPS, VMASKMOVPD
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. On the AMD Jaguar processor architecture, this instruction with a memory source operand takes more than 300 clock cycles when the mask is zero, in which case the instruction should do nothing. This appears to be a design flaw.[7] |
VPERMILPS, VPERMILPD
|
Permute In-Lane. Shuffle the 32-bit or 64-bit vector elements of one input operand. These are in-lane 256-bit instructions, meaning that they operate on all 256 bits with two separate 128-bit shuffles, so they can not shuffle across the 128-bit lanes.[8] |
VPERM2F128
|
Shuffle the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VTESTPS, VTESTPD
|
Packed bit test of the packed single-precision or double-precision floating-point sign bits, setting or clearing the ZF flag based on AND and CF flag based on ANDN. |
VZEROALL
|
Set all YMM registers to zero and tag them as unused. Used when switching between 128-bit use and 256-bit use. |
VZEROUPPER
|
Set the upper half of all YMM registers to zero. Used when switching between 128-bit use and 256-bit use. |
CPUs with AVX[edit]
- Intel
- Sandy Bridge processors, Q1 2011[9]
- Sandy Bridge E processors, Q4 2011[10]
- Ivy Bridge processors, Q1 2012
- Ivy Bridge E processors, Q3 2013
- Haswell processors, Q2 2013
- Haswell E processors, Q3 2014
- Broadwell processors, Q4 2014
- Skylake processors, Q3 2015
- Broadwell E processors, Q2 2016
- Kaby Lake processors, Q3 2016 (ULV mobile)/Q1 2017 (desktop/mobile)
- Skylake-X processors, Q2 2017
- Coffee Lake processors, Q4 2017
- Cannon Lake processors, Q2 2018
- Whiskey Lake processors, Q3 2018
- Cascade Lake processors, Q4 2018
- Ice Lake processors, Q3 2019
- Comet Lake processors (only Core and Xeon branded), Q3 2019
- Tiger Lake (Core, Pentium and Celeron branded[11]) processors, Q3 2020
- Rocket Lake processors, Q1 2021
- Alder Lake (Xeon, Core, Pentium and Celeron branded) processors, Q4 2021. Supported both in Golden Cove P-cores and Gracemont E-cores.
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Arrow Lake processors
- Lunar Lake processors
Not all CPUs from the listed families support AVX. Generally, CPUs with the commercial denomination Core i3/i5/i7/i9 support them, whereas Pentium and Celeron CPUs before Tiger Lake[12] do not.
- AMD:
- Jaguar-based processors and newer
- Puma-based processors and newer
- «Heavy Equipment» processors
- Bulldozer-based processors, Q4 2011[13]
- Piledriver-based processors, Q4 2012[14]
- Steamroller-based processors, Q1 2014
- Excavator-based processors and newer, 2015
- Zen-based processors, Q1 2017
- Zen+-based processors, Q2 2018
- Zen 2-based processors, Q3 2019
- Zen 3 processors, Q4 2020
- Zen 4 processors, Q4 2022
Issues regarding compatibility between future Intel and AMD processors are discussed under XOP instruction set.
- VIA:
- Nano QuadCore
- Eden X4
- Zhaoxin:
- WuDaoKou-based processors (KX-5000 and KH-20000)
Compiler and assembler support[edit]
- Absoft supports with -mavx flag.
- The Free Pascal compiler supports AVX and AVX2 with the -CfAVX and -CfAVX2 switches from version 2.7.1.
- RAD studio (v11.0 Alexandria) supports AVX2 and AVX512.[15]
- The GNU Assembler (GAS) inline assembly functions support these instructions (accessible via GCC), as do Intel primitives and the Intel inline assembler (closely compatible to GAS, although more general in its handling of local references within inline code).
- GCC starting with version 4.6 (although there was a 4.3 branch with certain support) and the Intel Compiler Suite starting with version 11.1 support AVX.
- The Open64 compiler version 4.5.1 supports AVX with -mavx flag.
- PathScale supports via the -mavx flag.
- The Vector Pascal compiler supports AVX via the -cpuAVX32 flag.
- The Visual Studio 2010/2012 compiler supports AVX via intrinsic and /arch:AVX switch.
- Other assemblers such as MASM VS2010 version, YASM,[16] FASM, NASM and JWASM.
Operating system support[edit]
AVX adds new register-state through the 256-bit wide YMM register file, so explicit operating system support is required to properly save and restore AVX’s expanded registers between context switches. The following operating system versions support AVX:
- DragonFly BSD: support added in early 2013.
- FreeBSD: support added in a patch submitted on January 21, 2012,[17] which was included in the 9.1 stable release[18]
- Linux: supported since kernel version 2.6.30,[19] released on June 9, 2009.[20]
- macOS: support added in 10.6.8 (Snow Leopard) update[21][unreliable source?] released on June 23, 2011. In fact, macOS Ventura does not support processors without the AVX2 instruction set. [22]
- OpenBSD: support added on March 21, 2015.[23]
- Solaris: supported in Solaris 10 Update 10 and Solaris 11
- Windows: supported in Windows 7 SP1, Windows Server 2008 R2 SP1,[24] Windows 8, Windows 10
- Windows Server 2008 R2 SP1 with Hyper-V requires a hotfix to support AMD AVX (Opteron 6200 and 4200 series) processors, KB2568088
Advanced Vector Extensions 2[edit]
Advanced Vector Extensions 2 (AVX2), also known as Haswell New Instructions,[25] is an expansion of the AVX instruction set introduced in Intel’s Haswell microarchitecture. AVX2 makes the following additions:
- expansion of most vector integer SSE and AVX instructions to 256 bits
- Gather support, enabling vector elements to be loaded from non-contiguous memory locations
- DWORD- and QWORD-granularity any-to-any permutes
- vector shifts.
Sometimes three-operand fused multiply-accumulate (FMA3) extension is considered part of AVX2, as it was introduced by Intel in the same processor microarchitecture. This is a separate extension using its own CPUID flag and is described on its own page and not below.
New instructions[edit]
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD
|
Copy a 32-bit or 64-bit register operand to all elements of a XMM or YMM vector register. These are register versions of the same instructions in AVX1. There is no 128-bit version however, but the same effect can be simply achieved using VINSERTF128. |
VPBROADCASTB, VPBROADCASTW, VPBROADCASTD, VPBROADCASTQ
|
Copy an 8, 16, 32 or 64-bit integer register or memory operand to all elements of a XMM or YMM vector register. |
VBROADCASTI128
|
Copy a 128-bit memory operand to all elements of a YMM vector register. |
VINSERTI128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTI128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VGATHERDPD, VGATHERQPD, VGATHERDPS, VGATHERQPS
|
Gathers single or double precision floating point values using either 32 or 64-bit indices and scale. |
VPGATHERDD, VPGATHERDQ, VPGATHERQD, VPGATHERQQ
|
Gathers 32 or 64-bit integer values using either 32 or 64-bit indices and scale. |
VPMASKMOVD, VPMASKMOVQ
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. |
VPERMPS, VPERMD
|
Shuffle the eight 32-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERMPD, VPERMQ
|
Shuffle the four 64-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERM2I128
|
Shuffle (two of) the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VPBLENDD
|
Doubleword immediate version of the PBLEND instructions from SSE4. |
VPSLLVD, VPSLLVQ
|
Shift left logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRLVD, VPSRLVQ
|
Shift right logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRAVD
|
Shift right arithmetically. Allows variable shifts where each element is shifted according to the packed input. |
CPUs with AVX2[edit]
- Intel
- Haswell processors (only Core and Xeon branded), Q2 2013
- Haswell E processors, Q3 2014
- Broadwell processors, Q4 2014
- Broadwell E processors, Q3 2016
- Skylake processors, Q3 2015
- Kaby Lake processors, Q3 2016 (ULV mobile)/Q1 2017 (desktop/mobile)
- Skylake-X processors, Q2 2017
- Coffee Lake processors, Q4 2017
- Cannon Lake processors, Q2 2018
- Cascade Lake processors, Q2 2019
- Ice Lake processors, Q3 2019
- Comet Lake processors, Q3 2019
- Tiger Lake (Core, Pentium and Celeron branded[11]) processors, Q3 2020
- Rocket Lake processors, Q1 2021
- Alder Lake (Xeon, Core, Pentium and Celeron branded[11]) processors, Q4 2021. Supported both in Golden Cove P-cores and Gracemont E-cores.
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Arrow Lake processors
- Lunar Lake processors
- AMD
- Excavator processor and newer, Q2 2015
- Zen processors, Q1 2017
- Zen+ processors, Q2 2018
- Zen 2 processors, Q3 2019
- Zen 3 processors, Q4 2020
- Zen 4 processors, Q4 2022
- VIA:
- Nano QuadCore
- Eden X4
AVX-512[edit]
AVX-512 are 512-bit extensions to the 256-bit Advanced Vector Extensions SIMD instructions for x86 instruction set architecture proposed by Intel in July 2013, and are supported with Intel’s Knights Landing processor.[3]
AVX-512 instructions are encoded with the new EVEX prefix. It allows 4 operands, 8 new 64-bit opmask registers, scalar memory mode with automatic broadcast, explicit rounding control, and compressed displacement memory addressing mode. The width of the register file is increased to 512 bits and total register count increased to 32 (registers ZMM0-ZMM31) in x86-64 mode.
AVX-512 consists of multiple instruction subsets, not all of which are meant to be supported by all processors implementing them. The instruction set consists of the following:
- AVX-512 Foundation (F) – adds several new instructions and expands most 32-bit and 64-bit floating point SSE-SSE4.1 and AVX/AVX2 instructions with EVEX coding scheme to support the 512-bit registers, operation masks, parameter broadcasting, and embedded rounding and exception control
- AVX-512 Conflict Detection Instructions (CD) – efficient conflict detection to allow more loops to be vectorized, supported by Knights Landing[3]
- AVX-512 Exponential and Reciprocal Instructions (ER) – exponential and reciprocal operations designed to help implement transcendental operations, supported by Knights Landing[3]
- AVX-512 Prefetch Instructions (PF) – new prefetch capabilities, supported by Knights Landing[3]
- AVX-512 Vector Length Extensions (VL) – extends most AVX-512 operations to also operate on XMM (128-bit) and YMM (256-bit) registers (including XMM16-XMM31 and YMM16-YMM31 in x86-64 mode)[26]
- AVX-512 Byte and Word Instructions (BW) – extends AVX-512 to cover 8-bit and 16-bit integer operations[26]
- AVX-512 Doubleword and Quadword Instructions (DQ) – enhanced 32-bit and 64-bit integer operations[26]
- AVX-512 Integer Fused Multiply Add (IFMA) – fused multiply add for 512-bit integers.[27]: 746
- AVX-512 Vector Byte Manipulation Instructions (VBMI) adds vector byte permutation instructions which are not present in AVX-512BW.
- AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW) – vector instructions for deep learning.
- AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS) – vector instructions for deep learning.
- VPOPCNTDQ – count of bits set to 1.[28]
- VPCLMULQDQ – carry-less multiplication of quadwords.[28]
- AVX-512 Vector Neural Network Instructions (VNNI) – vector instructions for deep learning.[28]
- AVX-512 Galois Field New Instructions (GFNI) – vector instructions for calculating Galois field.[28]
- AVX-512 Vector AES instructions (VAES) – vector instructions for AES coding.[28]
- AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2) – byte/word load, store and concatenation with shift.[28]
- AVX-512 Bit Algorithms (BITALG) – byte/word bit manipulation instructions expanding VPOPCNTDQ.[28]
- AVX-512 Bfloat16 Floating-Point Instructions (BF16) – vector instructions for AI acceleration.
- AVX-512 Half-Precision Floating-Point Instructions (FP16) – vector instructions for operating on floating-point and complex numbers with reduced precision.
Only the core extension AVX-512F (AVX-512 Foundation) is required by all implementations, though all current processors also support CD (conflict detection); computing coprocessors will additionally support ER, PF, 4VNNIW, 4FMAPS, and VPOPCNTDQ, while central processors will support VL, DQ, BW, IFMA, VBMI, VPOPCNTDQ, VPCLMULQDQ etc.
The updated SSE/AVX instructions in AVX-512F use the same mnemonics as AVX versions; they can operate on 512-bit ZMM registers, and will also support 128/256 bit XMM/YMM registers (with AVX-512VL) and byte, word, doubleword and quadword integer operands (with AVX-512BW/DQ and VBMI).[27]: 23
CPUs with AVX-512[edit]
| AVX-512 Subset | F | CD | ER | PF | 4FMAPS | 4VNNIW | VPOPCNTDQ | VL | DQ | BW | IFMA | VBMI | VBMI2 | BITALG | VNNI | BF16 | VPCLMULQDQ | GFNI | VAES | VP2INTERSECT | FP16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intel Knights Landing (2016) | Yes | Yes | No | ||||||||||||||||||
| Intel Knights Mill (2017) | Yes | No | |||||||||||||||||||
| Intel Skylake-SP, Skylake-X (2017) | No | No | Yes | No | |||||||||||||||||
| Intel Cannon Lake (2018) | Yes | No | |||||||||||||||||||
| Intel Cascade Lake-SP (2019) | No | Yes | No | ||||||||||||||||||
| Intel Cooper Lake (2020) | No | Yes | No | ||||||||||||||||||
| Intel Ice Lake (2019) | Yes | No | Yes | No | |||||||||||||||||
| Intel Tiger Lake (2020) | Yes | No | |||||||||||||||||||
| Intel Rocket Lake (2021) | No | ||||||||||||||||||||
| Intel Alder Lake (2021) | Not officially supported, but can be enabled on some motherboards with some BIOS versionsNote 1 | ||||||||||||||||||||
| AMD Zen 4 (2022) | Yes | Yes | No | ||||||||||||||||||
| Intel Sapphire Rapids (2023) | No | Yes |
[29]
^Note 1 : AVX-512 is disabled by default in Alder Lake processors. On some motherboards with some BIOS versions, AVX-512 can be enabled in the BIOS, but this requires disabling E-cores.[30] However, Intel has begun fusing AVX-512 off of new Alder Lake processors.[31]
Compilers supporting AVX-512[edit]
- GCC 4.9 and newer[32]
- Clang 3.9 and newer[33]
- ICC 15.0.1 and newer[34]
- Microsoft Visual Studio 2017 C++ Compiler[35]
AVX-VNNI, AVX-IFMA[edit]
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. Similarly, AVX-IFMA is a VEX-coded variant of AVX512-IFMA. These extensions provide the same sets of operations as their AVX-512 counterparts, but are limited to 256-bit vectors and do not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. These extensions allow to support VNNI and IFMA operations even when full AVX-512 support is not implemented in the processor.
CPUs with AVX-VNNI[edit]
- Intel
- Alder Lake processors, Q4 2021
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Emerald Rapids processors
- Arrow Lake processors
- Lunar Lake processors
CPUs with AVX-IFMA[edit]
- Intel
- Sierra Forest processors
- Grand Ridge processors
- Meteor Lake processors
AVX10[edit]
AVX10, announced in August 2023, is a new, «converged» AVX instruction set. It addresses several issues of AVX-512, such as it being split into too many parts[36] (20 feature flags) and making 512-bit vectors mandatory to support. AVX10 presents a simplified CPUID interface to test for instruction support, consisting of the AVX10 version number (indicating the set of instructions supported, with later versions always being a superset of an earlier one) and the available maximum vector length (256 or 512 bits).[37] A combined notation is used to indicate the version and vector length: for example, AVX10.2/256 indicates that a CPU is capable of the second version of AVX10 with a maximum vector width of 256 bits.[38]
The first and «early» version of AVX10, notated AVX10.1, will not introduce any instructions or encoding features beyond what is already in AVX-512 (F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, BITALG, VNNI, GFNI, VPOPCNTDQ, VPCLMULQDQ, VAES, BF16, FP16). The second and «fully-featured» version, AVX10.2, introduces new features such as YMM embedded rounding and Suppress All Exception. For CPUs supporting AVX10 and 512-bit vectors, all legacy AVX-512 feature flags will remain set to facilitate applications supporting AVX-512 to continue using AVX-512 instructions.[38]
AVX10.1/512 will be available on Granite Rapids.[38]
APX[edit]
APX is a new extension. It is not focused on vector computation, but provides RISC-like extensions to the x86-64 architecture by doubling the number of general purpose registers to 32 and introducing three-operand instruction formats. AVX is only tangentially affected as APX introduces extended operands.[39][40]
Applications[edit]
- Suitable for floating point-intensive calculations in multimedia, scientific and financial applications (AVX2 adds support for integer operations).
- Increases parallelism and throughput in floating point SIMD calculations.
- Reduces register load due to the non-destructive instructions.
- Improves Linux RAID software performance (required AVX2, AVX is not sufficient)[41]
Software[edit]
- Blender uses AVX, AVX2 and AVX-512 in the Cycles render engine.[42]
- Bloombase uses AVX, AVX2 and AVX-512 in their Bloombase Cryptographic Module (BCM).
- Botan uses both AVX and AVX2 when available to accelerate some algorithms, like ChaCha.
- BSAFE C toolkits uses AVX and AVX2 where appropriate to accelerate various cryptographic algorithms.[43]
- Crypto++ uses both AVX and AVX2 when available to accelerate some algorithms, like Salsa and ChaCha.
- OpenSSL uses AVX- and AVX2-optimized cryptographic functions since version 1.0.2.[44] Support for AVX-512 was added in version 3.0.0.[45] Some of this support is also present in various clones and forks, like LibreSSL.
- Prime95/MPrime, the software used for GIMPS, started using the AVX instructions since version 27.1, AVX2 since 28.6 and AVX-512 since 29.1.[46]
- dav1d AV1 decoder can use AVX2 and AVX-512 on supported CPUs.[47][48]
- SVT-AV1 AV1 encoder can use AVX2 and AVX-512 to accelerate video encoding.[49]
- dnetc, the software used by distributed.net, has an AVX2 core available for its RC5 project and will soon release one for its OGR-28 project.
- Einstein@Home uses AVX in some of their distributed applications that search for gravitational waves.[50]
- Folding@home uses AVX on calculation cores implemented with GROMACS library.
- Helios uses AVX and AVX2 hardware acceleration on 64-bit x86 hardware.[51]
- Horizon: Zero Dawn uses AVX in its Decima game engine.
- RPCS3, an open source PlayStation 3 emulator, uses AVX2 and AVX-512 instructions to emulate PS3 games.
- Network Device Interface, an IP video/audio protocol developed by NewTek for live broadcast production, uses AVX and AVX2 for increased performance.
- TensorFlow since version 1.6 and tensorflow above versions requires CPU supporting at least AVX.[52]
- x264, x265 and VTM video encoders can use AVX2 or AVX-512 to speed up encoding.
- Various CPU-based cryptocurrency miners (like pooler’s cpuminer for Bitcoin and Litecoin) use AVX and AVX2 for various cryptography-related routines, including SHA-256 and scrypt.
- libsodium uses AVX in the implementation of scalar multiplication for Curve25519 and Ed25519 algorithms, AVX2 for BLAKE2b, Salsa20, ChaCha20, and AVX2 and AVX-512 in implementation of Argon2 algorithm.
- libvpx open source reference implementation of VP8/VP9 encoder/decoder, uses AVX2 or AVX-512 when available.
- FFTW can utilize AVX, AVX2 and AVX-512 when available.
- LLVMpipe, a software OpenGL renderer in Mesa using Gallium and LLVM infrastructure, uses AVX2 when available.
- glibc uses AVX2 (with FMA) and AVX-512 for optimized implementation of various mathematical (i.e.
expf,sinf,powf,atanf,atan2f) and string (memmove,memcpy, etc.) functions in libc. - Linux kernel can use AVX or AVX2, together with AES-NI as optimized implementation of AES-GCM cryptographic algorithm.
- Linux kernel uses AVX or AVX2 when available, in optimized implementation of multiple other cryptographic ciphers: Camellia, CAST5, CAST6, Serpent, Twofish, MORUS-1280, and other primitives: Poly1305, SHA-1, SHA-256, SHA-512, ChaCha20.
- POCL, a portable Computing Language, that provides implementation of OpenCL, makes use of AVX, AVX2 and AVX-512 when possible.
- .NET and .NET Framework can utilize AVX, AVX2 through the generic
System.Numerics.Vectorsnamespace. - .NET Core, starting from version 2.1 and more extensively after version 3.0 can directly use all AVX, AVX2 intrinsics through the
System.Runtime.Intrinsics.X86namespace. - EmEditor 19.0 and above uses AVX2 to speed up processing.[53]
- Native Instruments’ Massive X softsynth requires AVX.[54]
- Microsoft Teams uses AVX2 instructions to create a blurred or custom background behind video chat participants,[55] and for background noise suppression.[56]
- Pale Moon custom Windows builds greatly increase browsing speed due to the use of AVX2.
- simdjson, a JSON parsing library, uses AVX2 and AVX-512 to achieve improved decoding speed.[57][58]
- Tesseract OCR engine uses AVX, AVX2 and AVX-512 to accelerate character recognition.[59]
Downclocking[edit]
Since AVX instructions are wider and generate more heat, some Intel processors have provisions to reduce the Turbo Boost frequency limit when such instructions are being executed. On Skylake and its derivatives, the throttling is divided into three levels:[60][61]
- L0 (100%): The normal turbo boost limit.
- L1 (~85%): The «AVX boost» limit. Soft-triggered by 256-bit «heavy» (floating-point unit: FP math and integer multiplication) instructions. Hard-triggered by «light» (all other) 512-bit instructions.
- L2 (~60%):[dubious – discuss] The «AVX-512 boost» limit. Soft-triggered by 512-bit heavy instructions.
The frequency transition can be soft or hard. Hard transition means the frequency is reduced as soon as such an instruction is spotted; soft transition means that the frequency is reduced only after reaching a threshold number of matching instructions. The limit is per-thread.[60]
In Ice Lake, only two levels persist:[62]
- L0 (100%): The normal turbo boost limit.
- L1 (~97%): Triggered by any 512-bit instructions, but only when single-core boost is active; not triggered when multiple cores are loaded.
Rocket Lake processors do not trigger frequency reduction upon executing any kind of vector instructions regardless of the vector size.[62] However, downclocking can still happen due to other reasons, such as reaching thermal and power limits.
Downclocking means that using AVX in a mixed workload with an Intel processor can incur a frequency penalty. Avoiding the use of wide and heavy instructions help minimize the impact in these cases. AVX-512VL allows for using 256-bit or 128-bit operands in AVX-512, making it a sensible default for mixed loads.[63]
On supported and unlocked variants of processors that down-clock, the ratios are adjustable and may be turned off (set to 0x) entirely via Intel’s Overclocking / Tuning utility or in BIOS if supported there.[64]
See also[edit]
- Memory Protection Extensions
- Scalable Vector Extension for ARM — a new vector instruction set (supplementing VFP and NEON) similar to AVX-512, with some additional features.
References[edit]
- ^ Kanter, David (September 25, 2010). «Intel’s Sandy Bridge Microarchitecture». www.realworldtech.com. Retrieved February 17, 2018.
- ^ Hruska, Joel (October 24, 2011). «Analyzing Bulldozer: Why AMD’s chip is so disappointing — Page 4 of 5 — ExtremeTech». ExtremeTech. Retrieved February 17, 2018.
- ^ a b c d e James Reinders (July 23, 2013), AVX-512 Instructions, Intel, retrieved August 20, 2013
- ^ «Intel Xeon Phi Processor 7210 (16GB, 1.30 GHz, 64 core) Product Specifications». Intel ARK (Product Specs). Retrieved March 16, 2018.
- ^ «14.9». Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture (PDF) (-051US ed.). Intel Corporation. p. 349. Retrieved August 23, 2014.
Memory arguments for most instructions with VEX prefix operate normally without causing #GP(0) on any byte-granularity alignment (unlike Legacy SSE instructions).
- ^ «i386 and x86-64 Options — Using the GNU Compiler Collection (GCC)». Retrieved February 9, 2014.
- ^ «The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers» (PDF). Retrieved October 17, 2016.
- ^ «Chess programming AVX2». Archived from the original on July 10, 2017. Retrieved October 17, 2016.
- ^ «Intel Offers Peek at Nehalem and Larrabee». ExtremeTech. March 17, 2008.
- ^ «Intel Core i7-3960X Processor Extreme Edition». Retrieved January 17, 2012.
- ^ a b c «Intel® Celeron® 6305 Processor (4M Cache, 1.80 GHz, with IPU) Product Specifications». ark.intel.com. Retrieved November 10, 2020.
- ^ «Does a Processor with AVX2 or AVX-512 Support AVX Instructions?». ark.intel.com. Retrieved April 27, 2022.
- ^ Dave Christie (May 7, 2009), Striking a balance, AMD Developer blogs, archived from the original on November 9, 2013, retrieved January 17, 2012
- ^ New «Bulldozer» and «Piledriver» Instructions (PDF), AMD, October 2012
- ^ «What’s New — RAD Studio». docwiki.embarcadero.com. Retrieved September 17, 2021.
- ^ «YASM 0.7.0 Release Notes». yasm.tortall.net.
- ^ Add support for the extended FPU states on amd64, both for native 64bit and 32bit ABIs, svnweb.freebsd.org, January 21, 2012, retrieved January 22, 2012
- ^ «FreeBSD 9.1-RELEASE Announcement». Retrieved May 20, 2013.
- ^ x86: add linux kernel support for YMM state, retrieved July 13, 2009
- ^ Linux 2.6.30 — Linux Kernel Newbies, retrieved July 13, 2009
- ^ Twitter, retrieved June 23, 2010
- ^ «Devs are making progress getting macOS Ventura to run on unsupported, decade-old Macs». August 23, 2022.
- ^ Add support for saving/restoring FPU state using the XSAVE/XRSTOR., retrieved March 25, 2015
- ^ Floating-Point Support for 64-Bit Drivers, retrieved December 6, 2009
- ^ Haswell New Instruction Descriptions Now Available, Software.intel.com, retrieved January 17, 2012
- ^ a b c James Reinders (July 17, 2014). «Additional AVX-512 instructions». Intel. Retrieved August 3, 2014.
- ^ a b «Intel Architecture Instruction Set Extensions Programming Reference» (PDF). Intel. Retrieved January 29, 2014.
- ^ a b c d e f g «Intel® Architecture Instruction Set Extensions and Future Features Programming Reference». Intel. Retrieved October 16, 2017.
- ^ «Intel® Software Development Emulator | Intel® Software». software.intel.com. Retrieved June 11, 2016.
- ^ Cutress, Ian; Frumusanu, Andrei. «The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity». AnandTech. Retrieved November 5, 2021.
- ^ Alcorn, Paul (March 2, 2022). «Intel Nukes Alder Lake’s AVX-512 Support, Now Fuses It Off in Silicon». Tom’s Hardware. Retrieved October 3, 2022.
- ^ «GCC 4.9 Release Series — Changes, New Features, and Fixes – GNU Project — Free Software Foundation (FSF)». gcc.gnu.org. Retrieved April 3, 2017.
- ^ «LLVM 3.9 Release Notes — LLVM 3.9 documentation». releases.llvm.org. Retrieved April 3, 2017.
- ^ «Intel® Parallel Studio XE 2015 Composer Edition C++ Release Notes | Intel® Software». software.intel.com. Retrieved April 3, 2017.
- ^ «Microsoft Visual Studio 2017 Supports Intel® AVX-512». July 11, 2017.
- ^ Mann, Tobias (August 15, 2023). «Intel’s AVX10 promises benefits of AVX-512 without baggage». www.theregister.com. Retrieved August 20, 2023.
- ^ «The Converged Vector ISA: Intel® Advanced Vector Extensions 10 Technical Paper». Intel.
- ^ a b c «Intel® Advanced Vector Extensions 10 (Intel® AVX10) Architecture Specification». Intel.
- ^ «Intel® Advanced Performance Extensions (Intel® APX) Architecture Specification». Intel.
- ^ Robinson, Dan (July 26, 2023). «Intel discloses x86 and vector instructions for future chips». www.theregister.com. Retrieved August 20, 2023.
- ^ «Linux RAID». LWN. February 17, 2013. Archived from the original on April 15, 2013.
- ^ Jaroš, Milan; Strakoš, Petr; Říha, Lubomír (May 28, 2022). «Rendering in Blender using AVX-512 Vectorization» (PDF). Intel eXtreme Performance Users Group. Technical University of Ostrava. Retrieved October 28, 2022.
{{cite web}}: CS1 maint: url-status (link) - ^ «Comparison of BSAFE cryptographic library implementations». July 25, 2023.
- ^ «Improving OpenSSL Performance». May 26, 2015. Retrieved February 28, 2017.
- ^ «OpenSSL 3.0.0 release notes». GitHub. September 7, 2021.
- ^ «Prime95 release notes». Retrieved July 10, 2022.
- ^ «dav1d: performance and completion of the first release». November 21, 2018. Retrieved November 22, 2018.
- ^ «dav1d 0.6.0 release notes». March 6, 2020.
- ^ «SVT-AV1 0.7.0 release notes». September 26, 2019.
- ^ «Einstein@Home Applications».
- ^ «FAQ, Helios». Helios. Retrieved July 5, 2021.
- ^ «Tensorflow 1.6». GitHub.
- ^ New in Version 19.0 – EmEditor (Text Editor)
- ^ «MASSIVE X Requires AVX Compatible Processor». Native Instruments. Retrieved November 29, 2019.
- ^ «Hardware requirements for Microsoft Teams». Microsoft. Retrieved April 17, 2020.
- ^ «Reduce background noise in Teams meetings». Microsoft Support. Retrieved January 5, 2021.
- ^ Langdale, Geoff; Lemire, Daniel (2019). «Parsing Gigabytes of JSON per Second». The VLDB Journal. 28 (6): 941–960. arXiv:1902.08318. doi:10.1007/s00778-019-00578-5. S2CID 67856679.
- ^ «simdjson 2.1.0 release notes». GitHub. June 30, 2022.
- ^ Larabel, Michael (July 7, 2022). «Tesseract OCR 5.2 Engine Finds Success With AVX-512F». Phoronix.
- ^ a b Lemire, Daniel (September 7, 2018). «AVX-512: when and how to use these new instructions». Daniel Lemire’s blog.
- ^ BeeOnRope. «SIMD instructions lowering CPU frequency». Stack Overflow.
- ^ a b Downs, Travis (August 19, 2020). «Ice Lake AVX-512 Downclocking». Performance Matters blog.
- ^ «x86 — AVX 512 vs AVX2 performance for simple array processing loops». Stack Overflow.
- ^ «Intel® Extreme Tuning Utility (Intel® XTU) Guide to Overclocking : Advanced Tuning». Intel. Retrieved July 18, 2021.
See image in linked section, where AVX2 ratio has been set to 0.
External links[edit]
- Intel Intrinsics Guide
- x86 Assembly Language Reference Manual
Аббревиатура AVX расшифровывается как Advanced Vector Extensions. Это наборы инструкций для процессоров Intel и AMD, идея создания которых появилась в марте 2008 года. Впервые такой набор был встроен в процессоры линейки Intel Haswell в 2013 году. Поддержка команд в Pentium и Celeron появилась лишь в 2020 году.
Прочитав эту статью, вы более подробно узнаете, что такое инструкции AVX и AVX2 для процессоров, а также — как узнать поддерживает ли процессор AVX.
AVX и AVX2 – что это такое
AVX/AVX2 — это улучшенные версии старых наборов команд SSE. Advanced Vector Extensions расширяют операционные пакеты со 128 до 512 бит, а также добавляют новые инструкции. Например, за один такт процессора без инструкций AVX будет сложена 1 пара чисел, а с ними — 10. Эти наборы расширяют спектр используемых чисел для оптимизации подсчёта данных.
Наличие у процессоров поддержки AVX весьма желательно. Эти инструкции предназначены, прежде всего, для выполнения сложных профессиональных операций. Без поддержки AVX всё-таки можно запускать большинство игр, редактировать фото, смотреть видео, общаться в интернете и др., хотя и не так комфортно.
Как узнать, поддерживает ли процессор AVX
Далее будут показаны несколько простых способов узнать это. Некоторые из методов потребуют установки специального ПО.
1. Таблица сравнения процессоров на сайте Chaynikam.info.
Для того чтобы узнать, поддерживает ли ваш процессор инструкции AVX, можно воспользоваться предлагаемым способом. Перейдите на этот сайт. В правом верхнем углу страницы расположена зелёная кнопка Добавить процессор. Нажмите её.
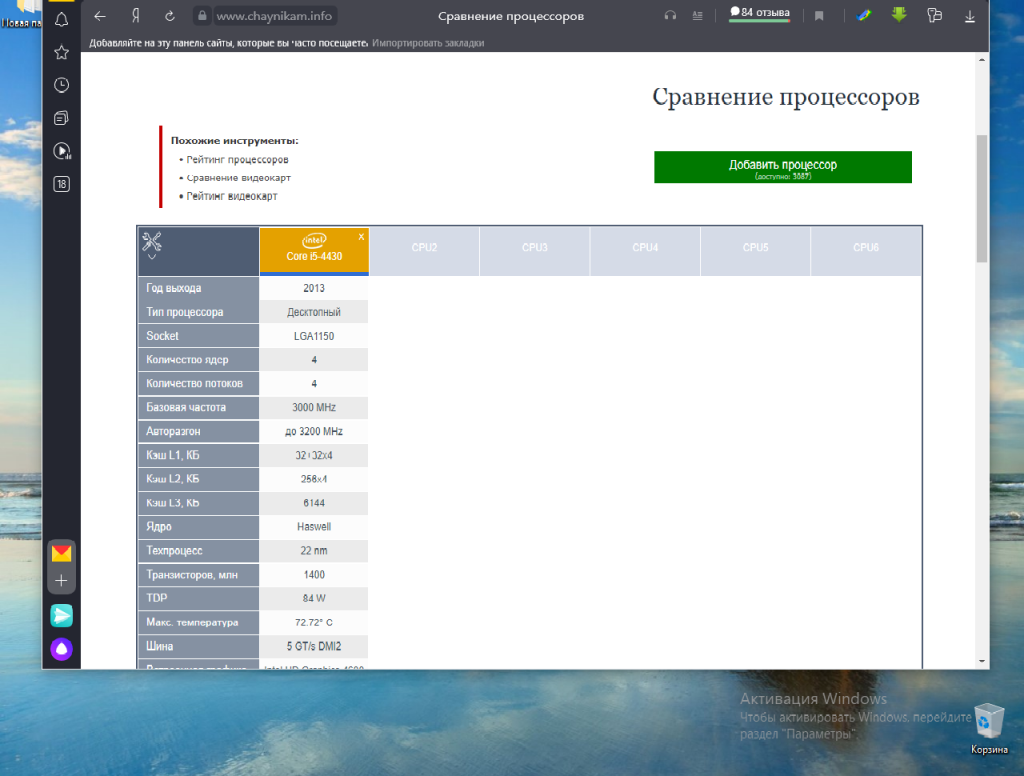
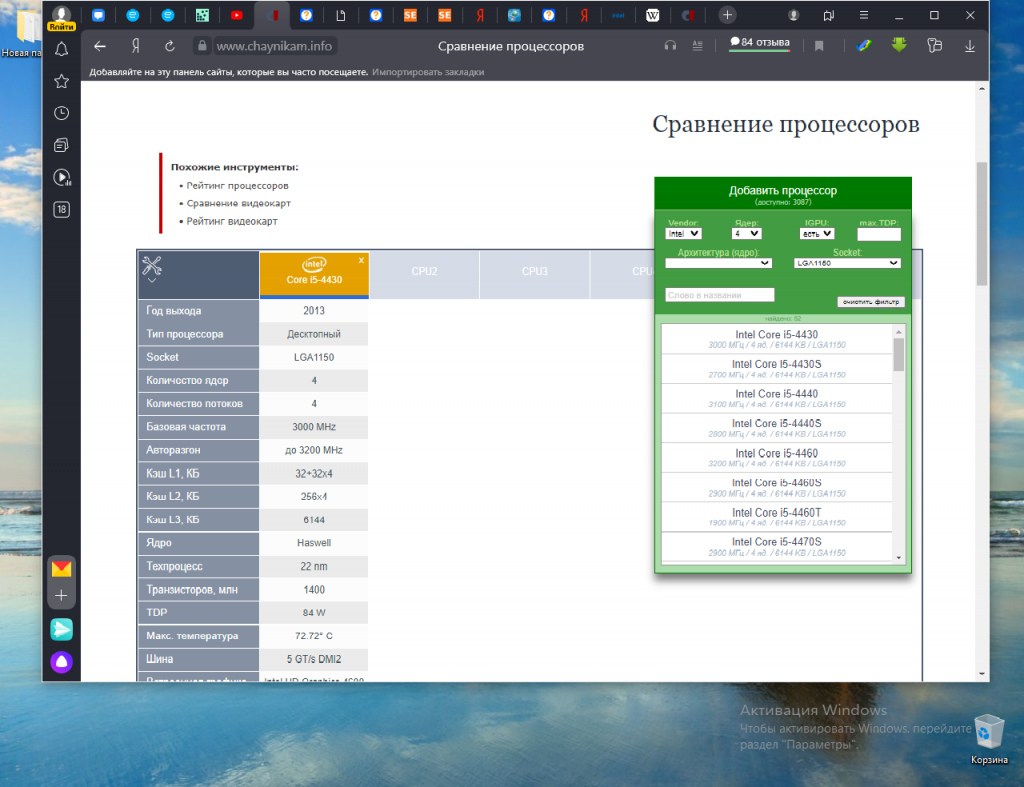
В открывшемся окне вам будет предложено указать параметры выбора нужного процессора. Все указывать не обязательно.
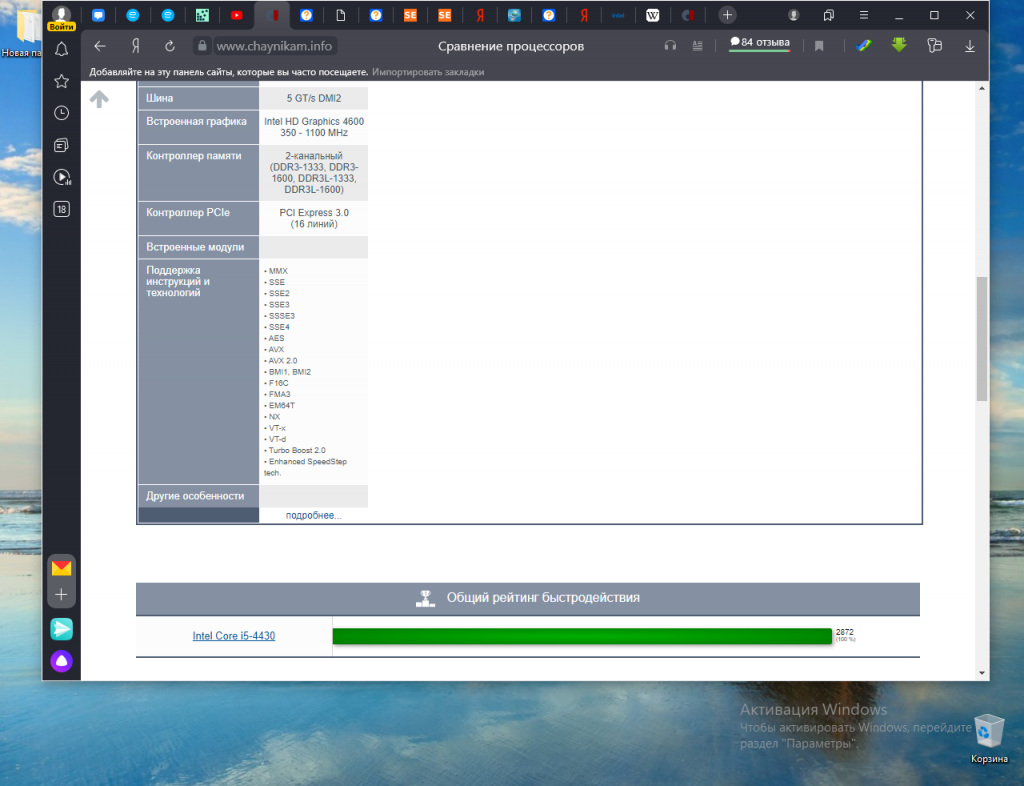
В результате выполнения поиска будет сформирована таблица с параметрами выбранного из списка процессора. Прокрутите таблицу вниз. В строке Поддержка инструкций и технологий будет показана подробная информация.
2. Утилита CPU-Z.
Один из самых простых и надёжных способов узнать поддерживает ли процессор AVX инструкции, использовать утилиту для просмотра информации о процессоре — CPU-Z. Скачать утилиту можно на официальном сайте. После завершения установки ярлык для запуска утилиты появится на рабочем столе. Запустите её.
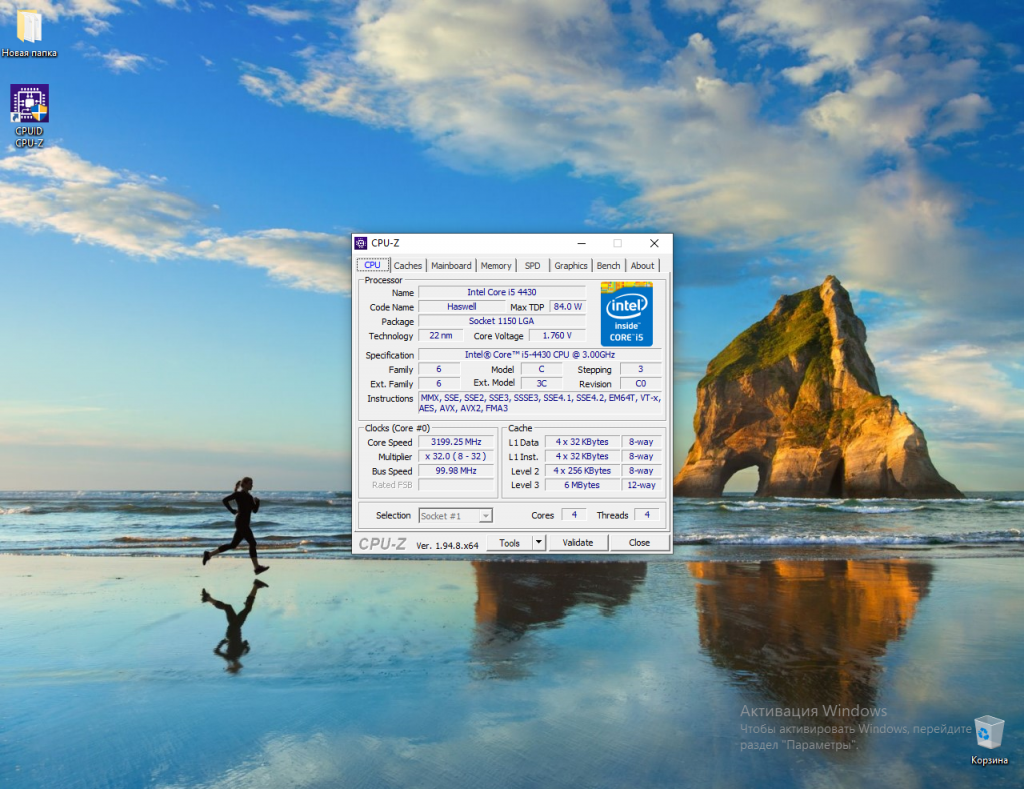
В строке Instructions показаны все инструкции и другие технологии, поддерживаемые вашим процессором.
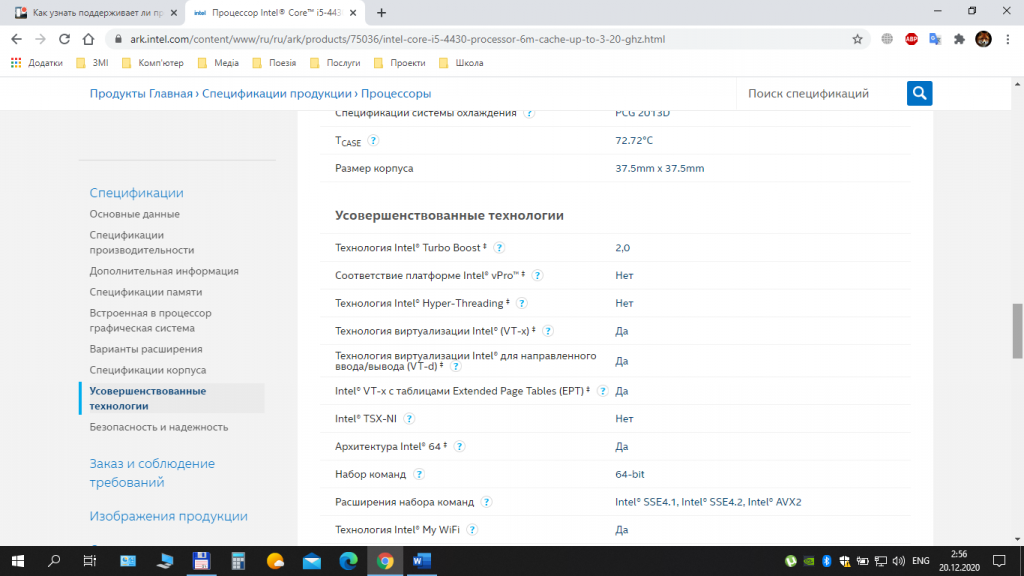
3. Поиск на сайте производителя.
Ещё один способ узнать, есть ли AVX на процессоре, воспользоваться официальным сайтом производителя процессоров. В строке поиска браузера наберите название процессора и выполните поиск. Если у вас процессор Intel, выберите соответствующую страницу в списке и перейдите на неё. На этой странице вам будет предоставлена подробная информация о процессоре.
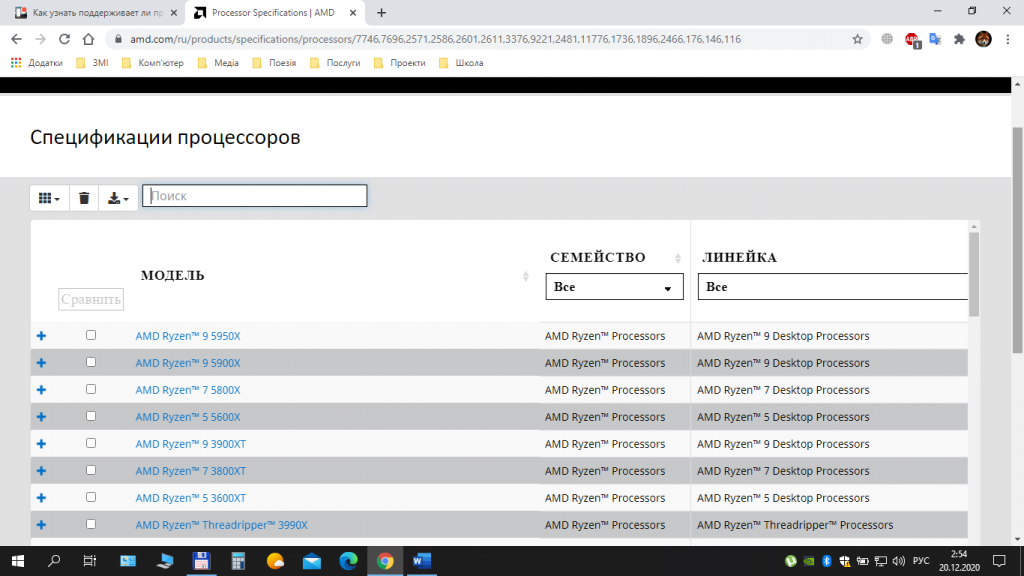
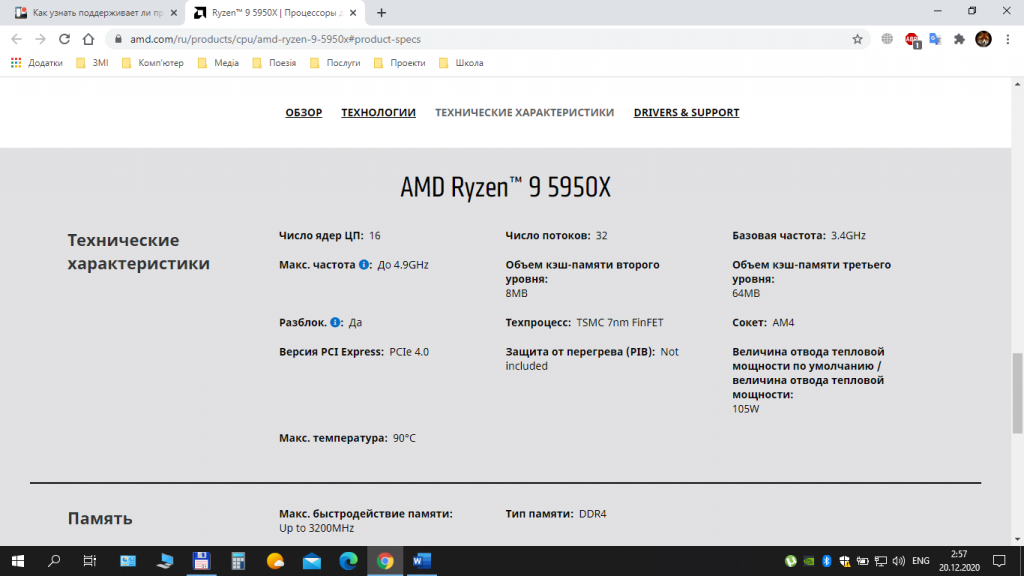
Если у вас процессор от компании AMD, то лучше всего будет воспользоваться сайтом AMD. Выберите пункт меню Процессоры, далее — пункт Характеристики изделия и затем, выбрав тип (например, Потребительские процессоры), выполните переход на страницу Спецификации процессоров. На этой странице выполните поиск вашего процессора по названию и посмотрите подробную информацию о нём.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.
Была ли эта статья полезной?
ДаНет
Оцените статью:
 (8 оценок, среднее: 5,00 из 5)
(8 оценок, среднее: 5,00 из 5)
![]() Загрузка…
Загрузка…
Об авторе

Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.
Оглавление:
- Инструкция по нашему процессору
- Что такое расширенные векторные расширения
- Характеристики AVX
- Для чего использовался AVX
- Несколько заключительных слов
Мы поговорим о том, что такое AVX и как он влияет на ваш процессор, а также о некоторых его реализациях. И это из множества компонентов, которые составляют команду, мало кто будет утверждать, что процессор является одним из тех, которые оказывают наибольшее влияние на команду.
Внутри процессора одним из элементов, который оказывает наибольшее влияние на работу компонента, являются наборы команд и их реализация. Сегодня мы хотим провести время с одной из самых влиятельных среди существующих моделей. Давай сделаем это!
Указатель содержания
Инструкция по нашему процессору
Прежде чем продолжить, мы думаем, что будет полезно определить, какие инструкции (или все они) находятся в процессоре. Инструкции — это самая основная операция, которую наш процессор может выполнять с данными, необходимыми для действия программы или приложения.

Их набор и их реализация определяют, как наш процессор управляет информацией, и какие программы или приложения могут работать. Существует несколько типов инструкций, но основными являются арифметика и логика.
Что такое расширенные векторные расширения
AVX является аббревиатурой от Advanced Vector Extension , имя, под которым набор команд известен как расширение к уже исчерпывающему набору команд IA-32 (x86). Набор, который Intel и AMD начнут кормить в конце девяностых, увидев свет других, таких как MMX или AMD64.
AVX гораздо более развит, чем его предки, а также набор инструкций SSE4, который он заменяет. Он сфокусирован на повышении эффективности при выполнении векторных вычислений (в основном, вычислений с плавающей запятой), но благодаря реализации улучшенной схемы кодирования и новых инструкций он может выполнять код до его реализации, что Это произошло в 2011 году с процессорами Sandy Bridge и FX-Jaguar.

Расширение регистра битовой длины. Изображение: colfaxresearch
В AVX инструкции собираются через регистры в векторах размером от 128 до 256 бит (YMM и XMM) в зависимости от их режима. Это обеспечивает совместимость с набором команд SSE, и вы можете использовать собственную схему кодирования трех операндов (VEX), которая более эффективна на многопоточных процессорах. Есть два замечательных дополнения к набору инструкций AVX: AVX2 и AVX-512.
- AVX2 является самым продолжительным с момента его применения с 2013 года. Он вносит важные новшества в то, как процессор управляет элементами, найденными в векторах, и расширяет набор команд до 256-битных в тех, которые основаны на AVX и SSE. AVX-512 также выпущен в 2013 году, но его реализация в домашних процессорах (за пределами Xeon и Threadripper) несколько новее. Он состоит из серии расширений для операндов AVX2 и может работать с регистрами до 512 бит (ZMM).
МЫ РЕКОМЕНДУЕМ ВАМ Intel Burn Test: как проверить стабильность вашего процессора
Для чего использовался AVX
AVX — это эволюция, которая сопровождала наборы инструкций процессоров Intel в течение первого десятилетия 2000-х годов. Будучи естественными преемниками набора SSE, его приложения также вращаются вокруг мультимедиа (главным образом звука и видео) и поэтому являются Обязательное требование во многих программах, использующих рендеринг изображений, 3D-рисование или работу со звуком.

Дорожная карта AVX в Intel. Изображение: Wikimedia Commons; Lambtron
Хорошим примером этого может служить Blender, который в настоящее время поддерживает только AVX-совместимые процессоры. У нас такой же случай с такими программами, как Massive для звука, или в интерактивных развлечениях с некоторыми видеоиграми. AVX присутствует во всей среде современных мультимедийных программ и приложений.
Несколько заключительных слов
Хотя существует больше вариаций и наборов инструкций, связанных с AVX, перечисленные здесь сегодня являются наиболее распространенными среди процессоров бытовой электроники, и поэтому мы сосредоточились на них на других предложениях.
Мы рекомендуем читать лучшие процессоры на рынке
Если вам было интересно узнать больше о том, что такое AVX и как он влияет на ваш процессор в вашей команде, мы приглашаем вас прочитать нашу статью о работе наших процессоров. Настоятельно рекомендуется прочитать для любого любопытного, заинтересованного в теме.
Шрифт Colfaxresearch