In computer science, an instruction set architecture (ISA), also called computer architecture, is an abstract model of a computer. A device that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation.
In general, an ISA defines the supported instructions, data types, registers, the hardware support for managing main memory, fundamental features (such as the memory consistency, addressing modes, virtual memory), and the input/output model of a family of implementations of the ISA.
An ISA specifies the behavior of machine code running on implementations of that ISA in a fashion that does not depend on the characteristics of that implementation, providing binary compatibility between implementations. This enables multiple implementations of an ISA that differ in characteristics such as performance, physical size, and monetary cost (among other things), but that are capable of running the same machine code, so that a lower-performance, lower-cost machine can be replaced with a higher-cost, higher-performance machine without having to replace software. It also enables the evolution of the microarchitectures of the implementations of that ISA, so that a newer, higher-performance implementation of an ISA can run software that runs on previous generations of implementations.
If an operating system maintains a standard and compatible application binary interface (ABI) for a particular ISA, machine code will run on future implementations of that ISA and operating system. However, if an ISA supports running multiple operating systems, it does not guarantee that machine code for one operating system will run on another operating system, unless the first operating system supports running machine code built for the other operating system.
An ISA can be extended by adding instructions or other capabilities, or adding support for larger addresses and data values; an implementation of the extended ISA will still be able to execute machine code for versions of the ISA without those extensions. Machine code using those extensions will only run on implementations that support those extensions.
The binary compatibility that they provide makes ISAs one of the most fundamental abstractions in computing.
Overview[edit]
An instruction set architecture is distinguished from a microarchitecture, which is the set of processor design techniques used, in a particular processor, to implement the instruction set. Processors with different microarchitectures can share a common instruction set. For example, the Intel Pentium and the AMD Athlon implement nearly identical versions of the x86 instruction set, but they have radically different internal designs.
The concept of an architecture, distinct from the design of a specific machine, was developed by Fred Brooks at IBM during the design phase of System/360.
Prior to NPL [System/360], the company’s computer designers had been free to honor cost objectives not only by selecting technologies but also by fashioning functional and architectural refinements. The SPREAD compatibility objective, in contrast, postulated a single architecture for a series of five processors spanning a wide range of cost and performance. None of the five engineering design teams could count on being able to bring about adjustments in architectural specifications as a way of easing difficulties in achieving cost and performance objectives.[1]: p.137
Some virtual machines that support bytecode as their ISA such as Smalltalk, the Java virtual machine, and Microsoft’s Common Language Runtime, implement this by translating the bytecode for commonly used code paths into native machine code. In addition, these virtual machines execute less frequently used code paths by interpretation (see: Just-in-time compilation). Transmeta implemented the x86 instruction set atop VLIW processors in this fashion.
Classification of ISAs[edit]
An ISA may be classified in a number of different ways. A common classification is by architectural complexity. A complex instruction set computer (CISC) has many specialized instructions, some of which may only be rarely used in practical programs. A reduced instruction set computer (RISC) simplifies the processor by efficiently implementing only the instructions that are frequently used in programs, while the less common operations are implemented as subroutines, having their resulting additional processor execution time offset by infrequent use.[2]
Other types include very long instruction word (VLIW) architectures, and the closely related long instruction word (LIW) and[citation needed] explicitly parallel instruction computing (EPIC) architectures. These architectures seek to exploit instruction-level parallelism with less hardware than RISC and CISC by making the compiler responsible for instruction issue and scheduling.[3]
Architectures with even less complexity have been studied, such as the minimal instruction set computer (MISC) and one-instruction set computer (OISC). These are theoretically important types, but have not been commercialized.[4][5]
Instructions[edit]
Machine language is built up from discrete statements or instructions. On the processing architecture, a given instruction may specify:
- opcode (the instruction to be performed) e.g. add, copy, test
- any explicit operands:
-
- registers
- literal/constant values
- addressing modes used to access memory
More complex operations are built up by combining these simple instructions, which are executed sequentially, or as otherwise directed by control flow instructions.
Instruction types[edit]
Examples of operations common to many instruction sets include:
Data handling and memory operations[edit]
- Set a register to a fixed constant value.
- Copy data from a memory location or a register to a memory location or a register (a machine instruction is often called move; however, the term is misleading). They are used to store the contents of a register, the contents of another memory location or the result of a computation, or to retrieve stored data to perform a computation on it later. They are often called load and store operations.
- Read and write data from hardware devices.
Arithmetic and logic operations[edit]
- Add, subtract, multiply, or divide the values of two registers, placing the result in a register, possibly setting one or more condition codes in a status register.[6]
- increment, decrement in some ISAs, saving operand fetch in trivial cases.
- Perform bitwise operations, e.g., taking the conjunction and disjunction of corresponding bits in a pair of registers, taking the negation of each bit in a register.
- Compare two values in registers (for example, to see if one is less, or if they are equal).
- Floating-point instructions for arithmetic on floating-point numbers.[6]
Control flow operations[edit]
- Branch to another location in the program and execute instructions there.
- Conditionally branch to another location if a certain condition holds.
- Indirectly branch to another location.
- Call another block of code, while saving the location of the next instruction as a point to return to.
Coprocessor instructions[edit]
- Load/store data to and from a coprocessor or exchanging with CPU registers.
- Perform coprocessor operations.
Complex instructions[edit]
Processors may include «complex» instructions in their instruction set. A single «complex» instruction does something that may take many instructions on other computers. Such instructions are typified by instructions that take multiple steps, control multiple functional units, or otherwise appear on a larger scale than the bulk of simple instructions implemented by the given processor. Some examples of «complex» instructions include:
- transferring multiple registers to or from memory (especially the stack) at once
- moving large blocks of memory (e.g. string copy or DMA transfer)
- complicated integer and floating-point arithmetic (e.g. square root, or transcendental functions such as logarithm, sine, cosine, etc.)
- SIMD instructions, a single instruction performing an operation on many homogeneous values in parallel, possibly in dedicated SIMD registers
- performing an atomic test-and-set instruction or other read-modify-write atomic instruction
- instructions that perform ALU operations with an operand from memory rather than a register
Complex instructions are more common in CISC instruction sets than in RISC instruction sets, but RISC instruction sets may include them as well. RISC instruction sets generally do not include ALU operations with memory operands, or instructions to move large blocks of memory, but most RISC instruction sets include SIMD or vector instructions that perform the same arithmetic operation on multiple pieces of data at the same time. SIMD instructions have the ability of manipulating large vectors and matrices in minimal time. SIMD instructions allow easy parallelization of algorithms commonly involved in sound, image, and video processing. Various SIMD implementations have been brought to market under trade names such as MMX, 3DNow!, and AltiVec.
Instruction encoding[edit]

On traditional architectures, an instruction includes an opcode that specifies the operation to perform, such as add contents of memory to register—and zero or more operand specifiers, which may specify registers, memory locations, or literal data. The operand specifiers may have addressing modes determining their meaning or may be in fixed fields. In very long instruction word (VLIW) architectures, which include many microcode architectures, multiple simultaneous opcodes and operands are specified in a single instruction.
Some exotic instruction sets do not have an opcode field, such as transport triggered architectures (TTA), only operand(s).
Most stack machines have «0-operand» instruction sets in which arithmetic and logical operations lack any operand specifier fields; only instructions that push operands onto the evaluation stack or that pop operands from the stack into variables have operand specifiers. The instruction set carries out most ALU actions with postfix (reverse Polish notation) operations that work only on the expression stack, not on data registers or arbitrary main memory cells. This can be very convenient for compiling high-level languages, because most arithmetic expressions can be easily translated into postfix notation.[7]
Conditional instructions often have a predicate field—a few bits that encode the specific condition to cause an operation to be performed rather than not performed. For example, a conditional branch instruction will transfer control if the condition is true, so that execution proceeds to a different part of the program, and not transfer control if the condition is false, so that execution continues sequentially. Some instruction sets also have conditional moves, so that the move will be executed, and the data stored in the target location, if the condition is true, and not executed, and the target location not modified, if the condition is false. Similarly, IBM z/Architecture has a conditional store instruction. A few instruction sets include a predicate field in every instruction; this is called branch predication.
Number of operands[edit]
Instruction sets may be categorized by the maximum number of operands explicitly specified in instructions.
(In the examples that follow, a, b, and c are (direct or calculated) addresses referring to memory cells, while reg1 and so on refer to machine registers.)
C = A+B
- 0-operand (zero-address machines), so called stack machines: All arithmetic operations take place using the top one or two positions on the stack:[8]
push a,push b,add,pop c.C = A+Bneeds four instructions.[9] For stack machines, the terms «0-operand» and «zero-address» apply to arithmetic instructions, but not to all instructions, as 1-operand push and pop instructions are used to access memory.
- 1-operand (one-address machines), so called accumulator machines, include early computers and many small microcontrollers: most instructions specify a single right operand (that is, constant, a register, or a memory location), with the implicit accumulator as the left operand (and the destination if there is one):
load a,add b,store c.C = A+Bneeds three instructions.[9]
- 2-operand — many CISC and RISC machines fall under this category:
- CISC —
move Ato C; thenadd Bto C.C = A+Bneeds two instructions. This effectively ‘stores’ the result without an explicit store instruction.
- CISC — Often machines are limited to one memory operand per instruction:
load a,reg1;add b,reg1;store reg1,c; This requires a load/store pair for any memory movement regardless of whether theaddresult is an augmentation stored to a different place, as inC = A+B, or the same memory location:A = A+B.C = A+Bneeds three instructions.
- RISC — Requiring explicit memory loads, the instructions would be:
load a,reg1;load b,reg2;add reg1,reg2;store reg2,c.C = A+Bneeds four instructions.
- CISC —
- 3-operand, allowing better reuse of data:[10]
- CISC — It becomes either a single instruction:
add a,b,cC = A+Bneeds one instruction.
- CISC — Or, on machines limited to two memory operands per instruction,
move a,reg1;add reg1,b,c;C = A+Bneeds two instructions.
- RISC — arithmetic instructions use registers only, so explicit 2-operand load/store instructions are needed:
load a,reg1;load b,reg2;add reg1+reg2->reg3;store reg3,c;C = A+Bneeds four instructions.- Unlike 2-operand or 1-operand, this leaves all three values a, b, and c in registers available for further reuse.[10]
- CISC — It becomes either a single instruction:
- more operands—some CISC machines permit a variety of addressing modes that allow more than 3 operands (registers or memory accesses), such as the VAX «POLY» polynomial evaluation instruction.
Due to the large number of bits needed to encode the three registers of a 3-operand instruction, RISC architectures that have 16-bit instructions are invariably 2-operand designs, such as the Atmel AVR, TI MSP430, and some versions of ARM Thumb. RISC architectures that have 32-bit instructions are usually 3-operand designs, such as the ARM, AVR32, MIPS, Power ISA, and SPARC architectures.
Each instruction specifies some number of operands (registers, memory locations, or immediate values) explicitly. Some instructions give one or both operands implicitly, such as by being stored on top of the stack or in an implicit register. If some of the operands are given implicitly, fewer operands need be specified in the instruction. When a «destination operand» explicitly specifies the destination, an additional operand must be supplied. Consequently, the number of operands encoded in an instruction may differ from the mathematically necessary number of arguments for a logical or arithmetic operation (the arity). Operands are either encoded in the «opcode» representation of the instruction, or else are given as values or addresses following the opcode.
Register pressure[edit]
Register pressure measures the availability of free registers at any point in time during the program execution. Register pressure is high when a large number of the available registers are in use; thus, the higher the register pressure, the more often the register contents must be spilled into memory. Increasing the number of registers in an architecture decreases register pressure but increases the cost.[11]
While embedded instruction sets such as Thumb suffer from extremely high register pressure because they have small register sets, general-purpose RISC ISAs like MIPS and Alpha enjoy low register pressure. CISC ISAs like x86-64 offer low register pressure despite having smaller register sets. This is due to the many addressing modes and optimizations (such as sub-register addressing, memory operands in ALU instructions, absolute addressing, PC-relative addressing, and register-to-register spills) that CISC ISAs offer.[12]
Instruction length[edit]
The size or length of an instruction varies widely, from as little as four bits in some microcontrollers to many hundreds of bits in some VLIW systems. Processors used in personal computers, mainframes, and supercomputers have minimum instruction sizes between 8 and 64 bits. The longest possible instruction on x86 is 15 bytes (120 bits).[13] Within an instruction set, different instructions may have different lengths. In some architectures, notably most reduced instruction set computers (RISC), instructions are a fixed length, typically corresponding with that architecture’s word size. In other architectures, instructions have variable length, typically integral multiples of a byte or a halfword. Some, such as the ARM with Thumb-extension have mixed variable encoding, that is two fixed, usually 32-bit and 16-bit encodings, where instructions cannot be mixed freely but must be switched between on a branch (or exception boundary in ARMv8).
Fixed-length instructions are less complicated to handle than variable-length instructions for several reasons (not having to check whether an instruction straddles a cache line or virtual memory page boundary,[10] for instance), and are therefore somewhat easier to optimize for speed.
Code density[edit]
In early 1960s computers, main memory was expensive and very limited, even on mainframes. Minimizing the size of a program to make sure it would fit in the limited memory was often central. Thus the size of the instructions needed to perform a particular task, the code density, was an important characteristic of any instruction set. It remained important on the initially-tiny memories of minicomputers and then microprocessors. Density remains important today, for smartphone applications, applications downloaded into browsers over slow Internet connections, and in ROMs for embedded applications. A more general advantage of increased density is improved effectiveness of caches and instruction prefetch.
Computers with high code density often have complex instructions for procedure entry, parameterized returns, loops, etc. (therefore retroactively named Complex Instruction Set Computers, CISC). However, more typical, or frequent, «CISC» instructions merely combine a basic ALU operation, such as «add», with the access of one or more operands in memory (using addressing modes such as direct, indirect, indexed, etc.). Certain architectures may allow two or three operands (including the result) directly in memory or may be able to perform functions such as automatic pointer increment, etc. Software-implemented instruction sets may have even more complex and powerful instructions.
Reduced instruction-set computers, RISC, were first widely implemented during a period of rapidly growing memory subsystems. They sacrifice code density to simplify implementation circuitry, and try to increase performance via higher clock frequencies and more registers. A single RISC instruction typically performs only a single operation, such as an «add» of registers or a «load» from a memory location into a register. A RISC instruction set normally has a fixed instruction length, whereas a typical CISC instruction set has instructions of widely varying length. However, as RISC computers normally require more and often longer instructions to implement a given task, they inherently make less optimal use of bus bandwidth and cache memories.
Certain embedded RISC ISAs like Thumb and AVR32 typically exhibit very high density owing to a technique called code compression. This technique packs two 16-bit instructions into one 32-bit word, which is then unpacked at the decode stage and executed as two instructions.[14]
Minimal instruction set computers (MISC) are commonly a form of stack machine, where there are few separate instructions (8–32), so that multiple instructions can be fit into a single machine word. These types of cores often take little silicon to implement, so they can be easily realized in an FPGA or in a multi-core form. The code density of MISC is similar to the code density of RISC; the increased instruction density is offset by requiring more of the primitive instructions to do a task.[15][failed verification]
There has been research into executable compression as a mechanism for improving code density. The mathematics of Kolmogorov complexity describes the challenges and limits of this.
In practice, code density is also dependent on the compiler. Most optimizing compilers have options that control whether to optimize code generation for execution speed or for code density. For instance GCC has the option -Os to optimize for small machine code size, and -O3 to optimize for execution speed at the cost of larger machine code.
Representation[edit]
The instructions constituting a program are rarely specified using their internal, numeric form (machine code); they may be specified by programmers using an assembly language or, more commonly, may be generated from high-level programming languages by compilers.[16]
Design[edit]
The design of instruction sets is a complex issue. There were two stages in history for the microprocessor. The first was the CISC (Complex Instruction Set Computer), which had many different instructions. In the 1970s, however, places like IBM did research and found that many instructions in the set could be eliminated. The result was the RISC (Reduced Instruction Set Computer), an architecture that uses a smaller set of instructions. A simpler instruction set may offer the potential for higher speeds, reduced processor size, and reduced power consumption. However, a more complex set may optimize common operations, improve memory and cache efficiency, or simplify programming.
Some instruction set designers reserve one or more opcodes for some kind of system call or software interrupt. For example, MOS Technology 6502 uses 00H, Zilog Z80 uses the eight codes C7,CF,D7,DF,E7,EF,F7,FFH[17] while Motorola 68000 use codes in the range A000..AFFFH.
Fast virtual machines are much easier to implement if an instruction set meets the Popek and Goldberg virtualization requirements.[clarification needed]
The NOP slide used in immunity-aware programming is much easier to implement if the «unprogrammed» state of the memory is interpreted as a NOP.[dubious – discuss]
On systems with multiple processors, non-blocking synchronization algorithms are much easier to implement[citation needed] if the instruction set includes support for something such as «fetch-and-add», «load-link/store-conditional» (LL/SC), or «atomic compare-and-swap».
Instruction set implementation[edit]
A given instruction set can be implemented in a variety of ways. All ways of implementing a particular instruction set provide the same programming model, and all implementations of that instruction set are able to run the same executables. The various ways of implementing an instruction set give different tradeoffs between cost, performance, power consumption, size, etc.
When designing the microarchitecture of a processor, engineers use blocks of «hard-wired» electronic circuitry (often designed separately) such as adders, multiplexers, counters, registers, ALUs, etc. Some kind of register transfer language is then often used to describe the decoding and sequencing of each instruction of an ISA using this physical microarchitecture.
There are two basic ways to build a control unit to implement this description (although many designs use middle ways or compromises):
- Some computer designs «hardwire» the complete instruction set decoding and sequencing (just like the rest of the microarchitecture).
- Other designs employ microcode routines or tables (or both) to do this, using ROMs or writable RAMs (writable control store), PLAs, or both.
Some microcoded CPU designs with a writable control store use it to allow the instruction set to be changed (for example, the Rekursiv processor and the Imsys Cjip).[18]
CPUs designed for reconfigurable computing may use field-programmable gate arrays (FPGAs).
An ISA can also be emulated in software by an interpreter. Naturally, due to the interpretation overhead, this is slower than directly running programs on the emulated hardware, unless the hardware running the emulator is an order of magnitude faster. Today, it is common practice for vendors of new ISAs or microarchitectures to make software emulators available to software developers before the hardware implementation is ready.
Often the details of the implementation have a strong influence on the particular instructions selected for the instruction set. For example, many implementations of the instruction pipeline only allow a single memory load or memory store per instruction, leading to a load–store architecture (RISC). For another example, some early ways of implementing the instruction pipeline led to a delay slot.
The demands of high-speed digital signal processing have pushed in the opposite direction—forcing instructions to be implemented in a particular way. For example, to perform digital filters fast enough, the MAC instruction in a typical digital signal processor (DSP) must use a kind of Harvard architecture that can fetch an instruction and two data words simultaneously, and it requires a single-cycle multiply–accumulate multiplier.
See also[edit]
- Comparison of instruction set architectures
- Computer architecture
- Processor design
- Compressed instruction set
- Emulator
- Simulation
- Instruction set simulator
- OVPsim full systems simulator providing ability to create/model/emulate any instruction set using C and standard APIs
- Register transfer language (RTL)
- Micro-operation
References[edit]
- ^ Pugh, Emerson W.; Johnson, Lyle R.; Palmer, John H. (1991). IBM’s 360 and Early 370 Systems. MIT Press. ISBN 0-262-16123-0.
- ^ Crystal Chen; Greg Novick; Kirk Shimano (December 16, 2006). «RISC Architecture: RISC vs. CISC». cs.stanford.edu. Retrieved February 21, 2015.
- ^ Schlansker, Michael S.; Rau, B. Ramakrishna (February 2000). «EPIC: Explicitly Parallel Instruction Computing». Computer. 33 (2). doi:10.1109/2.820037.
- ^ Shaout, Adnan; Eldos, Taisir (Summer 2003). «On the Classification of Computer Architecture». International Journal of Science and Technology. 14: 3. Retrieved March 2, 2023.
- ^ Gilreath, William F.; Laplante, Phillip A. (December 6, 2012). Computer Architecture: A Minimalist Perspective. Springer Science+Business Media. ISBN 978-1-4615-0237-1.
- ^ a b Hennessy & Patterson 2003, p. 108.
- ^ Durand, Paul. «Instruction Set Architecture (ISA)». Introduction to Computer Science CS 0.
- ^ Hennessy & Patterson 2003, p. 92.
- ^ a b Hennessy & Patterson 2003, p. 93.
- ^ a b c
Cocke, John; Markstein, Victoria (January 1990). «The evolution of RISC technology at IBM» (PDF). IBM Journal of Research and Development. 34 (1): 4–11. doi:10.1147/rd.341.0004. Retrieved 2022-10-05. - ^ Page, Daniel (2009). «11. Compilers». A Practical Introduction to Computer Architecture. Springer. p. 464. Bibcode:2009pica.book…..P. ISBN 978-1-84882-255-9.
- ^ Venkat, Ashish; Tullsen, Dean M. (2014). Harnessing ISA Diversity: Design of a Heterogeneous-ISA Chip Multiprocessor. 41st Annual International Symposium on Computer Architecture.
- ^ «Intel® 64 and IA-32 Architectures Software Developer’s Manual». Intel Corporation. Retrieved 5 October 2022.
- ^ Weaver, Vincent M.; McKee, Sally A. (2009). Code density concerns for new architectures. IEEE International Conference on Computer Design. CiteSeerX 10.1.1.398.1967. doi:10.1109/ICCD.2009.5413117.
- ^ «RISC vs. CISC». cs.stanford.edu. Retrieved 2021-12-18.
- ^ Hennessy & Patterson 2003, p. 120.
- ^ Ganssle, Jack (February 26, 2001). «Proactive Debugging». embedded.com.
- ^ «Great Microprocessors of the Past and Present (V 13.4.0)». cpushack.net. Retrieved 2014-07-25.
Further reading[edit]
- Bowen, Jonathan P. (July–August 1985). «Standard Microprocessor Programming Cards». Microprocessors and Microsystems. 9 (6): 274–290. doi:10.1016/0141-9331(85)90116-4.
- Hennessy, John L.; Patterson, David A. (2003). Computer Architecture: A Quantitative Approach (Third ed.). Morgan Kaufmann Publishers. ISBN 1-55860-724-2. Retrieved 2023-03-04.
External links[edit]
![]()
 Media related to Instruction set architectures at Wikimedia Commons
Media related to Instruction set architectures at Wikimedia Commons- Programming Textfiles: Bowen’s Instruction Summary Cards
- Mark Smotherman’s Historical Computer Designs Page
Процессор – это главное устройство компьютера, отвечающее за выполнение всех операций. Давайте рассмотрим, что такое инструкции процессора, какие наборы поддерживаются и откуда они берутся.
Инструкции процессора – это набор команд, которые выполняются процессором. Каждая инструкция содержит определенный код, который процессор распознает и выполняет соответствующую операцию. У каждого процессора есть свой набор инструкций, который определяет, какие команды он может выполнить. Но есть некоторые стандартные наборы инструкций, которые поддерживаются большинством процессоров на рынке.
.webp")
Инструкции процессора определяют базовый набор операций, которые может выполнять процессор, такие как:
-
Арифметические операции (сложение, вычитание, умножение, деление)
-
Логические операции (AND, OR, XOR, NOT)
-
Операции сравнения (равно, больше, меньше)
-
Операции загрузки и сохранения данных в память
-
Операции передачи данных между регистрами процессора и внешними устройствами
-
Управления переходом и выполнением инструкций (ветвление, вызовы функций)
При разработке программного обеспечения необходимо учитывать возможности и ограничения аппаратной платформы, включая набор инструкций процессора. Некоторые инструкции могут выполняться быстрее, чем другие, поэтому разработчики могут использовать определенные оптимизации кода, чтобы оптимизировать производительность программы. Кроме того, некоторые инструкции могут быть недоступны на определенных процессорах, поэтому программист должен учитывать совместимость со всеми целевыми аппаратными платформами при разработке программного обеспечения.
Одним из наиболее распространенных наборов инструкций является x86. Он используется в процессорах Intel и AMD, которые являются самыми распространенными компьютерными процессорами в мире. x86 поддерживает широкий диапазон операций, включая арифметические, логические, условные операции, операции ввода-вывода и многое другое. Этот набор инструкций является довольно старым и имеет множество дополнительных инструкций, добавленных за десятилетия исследований и разработок.
Другим набором инструкций, который становится все более популярным, является ARM. Он используется в большинстве смартфонов, планшетов и других мобильных устройств. ARM является более современным набором инструкций, который разработан с учетом энергоэффективности и меньшего размера процессора. Он также поддерживает широкий диапазон операций, которые аналогичны x86.

ARM
Это сокращение от Advanced RISC Machine (расшифровка по-русски звучит как «Усовершенствованный комплекс управления сокращенной командой»). Он используется в большинстве мобильных устройств, таких как смартфоны, планшеты, ноутбуки и электронные книги, а также в некоторых встраиваемых системах и серверной аппаратуре.
ARM является RISC-процессором, что означает, что он использует набор инструкций сокращенной команды (CISC — набор инструкций со сложными командами). Это делает его более энергоэффективным, чем CISC-процессоры, такие как x86, потому что он выполняет больше операций с меньшим количеством команд. ARM-процессоры также имеют более маленький размер, что позволяет их использовать в устройствах с ограниченным местом.
ARM также поддерживает широкий диапазон операций, которые аналогичны x86, что делает его более гибким для разработки программного обеспечения. Он также имеет возможность использования многопоточности, что позволяет ему быстро обрабатывать несколько задач одновременно.
Инструкции процессора не появляются из ниоткуда. Они обычно разрабатываются производителями процессоров в течение многих лет, исследуя и улучшая наборы инструкций, которые использовались ранее. Кроме того, существует ряд отраслевых организаций, таких как ARM Holdings, которые занимаются разработкой стандартных наборов инструкций.
.jpg")
Набор инструкций
Это только один из факторов, который влияет на производительность процессора. Он также зависит от количества ядер и частоты процессора. Однако, набор инструкций наиболее существенен при работе с операционными системами, сложными алгоритмическими задачами, графикой или мультимедиа.
Теперь, когда вы знаете, что такое инструкции процессора, какие наборы поддерживаются и откуда они берутся, вы можете лучше понимать, как работает процессор и какие задачи он выполняет. Наборы инструкций являются основными элементами архитектуры процессора, которые позволяют ему выполнять задачи намного быстрее и эффективнее.
Приветствую! Далеко не все пользователи задумываются, как конкретно работает процессор и как ему удаётся работать с программами. И это, впрочем, и не нужно знать, так как видеть результат этой работы вполне достаточно. Но иногда возникает проблема, когда ЦП просто не может справиться с каким-нибудь ПО или что бывает даже чаще, игрой.
Причиной этого могут являться неподходящие характеристики ПК, а среди них иногда упоминается и недостаток инструкций процессора, само существование которых может вызывать озадаченность. А ведь инструкции процессора это именно то, что и позволяет ему работать с разными программами. Поэтому о них и поговорим далее.
Для чего нужны инструкции в процессорах
У термина «инструкция» здесь нет никакого особого значения, это всё так же некоторая последовательность действий, которую нужно выполнить для получения результата.
А так как обработка данных — это основная задача ЦП, они все используют наборы заложенных команд для выполнения различных операций с информацией. Здесь нужно учитывать, что любая программа, от ОС до игры — это тоже совокупность команд, и когда ЦП выполняет инструкции, которые нужны программе для работы, всё складывается, и вы получаете результаты.
Если команд нет или их набор в неподходящей версии, с выполнением программы будут трудности. Звучит просто, но на самом деле система сложнее, просто я делаю допущения для вашего удобства.
Пакет инструкций, поддерживаемых процессором, закладываются в него изначально, поэтому поменять вы его не сможете. Разве что купив новый, более мощный ЦП.
Какие наборы инструкций существуют и чем отличаются
Условно команды можно разделить на две большие группы — базовые и дополнительные. Базовые нужны для выполнения основных операций, которые и заставляют CPU работать, дополнительные — для особых задач и оптимизации работы ЦП.
Команды общего назначения выполняют универсальные арифметические, логические, информационные задачи, а также те, что связаны с переносом данных и т. д. То, какие инструкции может выполнять ваш ЦП, зависит от его архитектуры, чем она лучше, тем команд больше. А вот разрядность CPU, например, влияет на то, как много команд одновременно получится выполнить.
Базовые команды общие для всех процессоров, так что вам достаточно знать только архитектуру. А дополнительные различаются в зависимости от производителя CPU и версии, так как меняются чаще, чем фундаментальные.
Например, вы можете увидеть, что ваш ЦП поддерживает MMX. Это набор, который пригодится для ускоренной обработки фото, аудио и видео. Он был разработан Intel ещё в конце 90-х.
SSE обеспечивает устройствам от Intel быстродействие, когда одни и те же данные нужно использовать в разных вычислениях.
SSE2 необходима всему современному ПО, без этих команд у вас не будут работать ни версии Windows, начиная с 8, ни большинство программ. Например, даже браузеры от Яндекса и Google не получится запустить.
SSE3 пригодится для обработки графической, аудио и видеоинформации. Есть и другие версии SSE, каждая из которых имеет больше команд, чем предыдущая.
AES, которую также можно встретить в Intel, представляет собой расширение команд ЦП для ускорения работы программ и их большей защищённости. Название связано с алгоритмом шифрования Advanced Encryption Standard.
AVX, разработанный Intel в 2008, влияет как на вычислительные, так и мультимедийные возможности ЦП. А вот следующая версия, AVX 2, даёт прирост производительности при работе с фото, видео, аудио, программами распознавания голоса и т. д.
FMA ускоряет операции умножения и сложения с плавающей запятой, которые выполняются командами общего назначения.
А VT-x расширяет возможности работы ПК с виртуальными машинами.
Как вы могли заметить, инструкции, описанные выше, актуальны для Intel. А вот, например, для AMD есть свои:
- SenseMI — в первый раз использовался в Ryzen, прогнозирует программный код для лучшей производительности ЦП.
- AMD CoolCore — реализует временное отключение блоков процессора для снижения энергопотребления.
- AMD CoolSpeed — защищает ЦП от перегрева.
- AMD Enduro — ещё одна технология для энергосбережения.
Есть и универсальные технологии, вроде BMI или F16C.
Те наборы команд, которые я описал, лишь малая часть того, что вы можете встретить. Но я думаю и их достаточно, чтобы понять суть. Обращайте на них внимание в характеристиках программ, а в особенности игр, перед покупкой.
Как узнать какие инструкции поддерживает процессор
Вы наверняка уже задались вопросом, как узнать какие инструкции поддерживает процессор компьютера, и я могу на него ответить.
Для начала, вы можете найти список команд ЦП, просто сделав поисковый запрос. Зачастую нужная информация найдётся на официальных сайтах производителей ЦП. Если не получится, то на сайтах, посвящённых компьютерам, нередко есть целый раздел, где можно ввести название устройства в поиск и прочесть расширенные данные о нём. О наборах команд обязательно что-то будет.
Если не хотите искать, есть и другой способ, как посмотреть количество инструкций ЦП. Например, вы можете воспользоваться CPU-Z или другими подобными программами. В CPU-Z нужная информация будет в блоке «Instructions» прямо в первом окне. Скопируйте список и просто сравните его с требованиями для игр или ПО. Всё равно если вы не увидите подходящих версий, поможет только замена устройства.
На самом деле, инструкции процессора — не такая простая тема. Но описанного выше, думаю, вполне достаточно, чтобы иметь общее представление о том, что такое инструкции процессора и откуда их взять. Подробнее о других особенностях ЦП и остальных компонентах компьютеров поговорим в другой раз, и чтобы не пропустить новые публикации, нужно лишь подписаться на мои социальные сети, где новости всегда самые свежие. Увидимся!
С уважением, автор блога Андрей Андреев.
В мире компьютерных технологий нет ничего странного в обилии всевозможных аббревиатур: CPU, GPU, RAM, SSD, BIOS, CD-ROM, и многих других. И почти каждый день появляются всё новые и новые сокращения названий каких-то технологий, что является неизбежным следствием бесконечного стремления инженеров улучшить функции и возможности наших вычислительных устройств.
Сегодня речь пойдёт о таких расширениях набора команд процессоров, как MMX, SSE и AVX. Многим знакомы эти сокращения, и мы выясним, действительно ли это какие-то интересные разработки, или же это не более чем бессмысленные маркетинговые уловки.
Ну о-о-очень первые дни
Середина 80-х прошлого столетия. Рынок процессоров был очень похож на сегодняшний. Intel бесспорно преобладала, но столкнулась с жесткой конкуренцией со стороны AMD. Домашние компьютеры, такие как Commodore 64, использовали базовые 8-битные процессоры, тогда как настольные ПК начинали переходить с 16-битных на 32-битные чипы.
Эти числа означают размер значений данных, которые могут быть обработаны математически, при этом чем выше эти значения, тем выше точность и возможности. Они также определяет размер основных регистров в микросхеме: небольших участков памяти, используемых для хранения рабочих данных.
Такие процессоры являются также скалярными и целочисленными. Что это означает? Скаляр – это когда над одним элементом данных выполняется только одна любая математическая операция. Обычно это обозначается как SISD (single instruction, single data, «одиночный поток команд – одиночный поток данных»).
Таким образом, инструкция по сложению двух значений данных просто обрабатывается для этих двух чисел. А если вам, например, нужно прибавить одно и то же значение к группе из 16 чисел, то для этого потребуется выполнить все 16 наборов инструкций – для каждого числа из этой группы по отдельности. По-другому процессоры тех лет складывать ещё не умели.

Intel 80386DX с частотой 16МГц (1985).
Целое (Integer) – в математике, это такое число, которое не имеет дробной части. Например, 8 или -12. Процессоры типа интеловского 80386SX не имели врожденной способности сложить, скажем, 3.80 и 7.26 – такие дробные числа называются числами с плавающей точкой (или запятой, в русском языке это без разницы) – по-английски FP, floating point или просто floats. Чтобы справиться с ними, нужен был другой процессор, например 80387SX, и отдельный набор инструкций – список команд, который сообщает процессору, что делать.
В те времена под инструкциями x86 понимали наборы команд для целочисленных (integer) операций, а под инструкциями x87 – для чисел с плавающей точкой (float). В наши дни все операции умеет выполнять один процессор, поэтому мы используем термин x86 для обозначения набора инструкций обоих типов данных.
Использование отдельных сопроцессоров для обработки разных типов данных было нормой, пока Intel не представила 80486: их первый CPU для персоналок со встроенным математическим сопроцессором для обработки вещественных данных (FPU, Floating Point Unit).

Intel 80486: Жёлтым цветом выделен блок FPU для обработки чисел с плавающей точкой.
Как вы можете видеть, этот блок совсем немного занимает места в процессоре, но рывок в производительности, благодаря этому решению, был огромен.
Но в целом принцип работы оставался скалярным, и таким он перешел и к преемнику 486-го: оригинальному Intel Pentium.
И пройдёт ещё три года после релиза этого первого Пентиума, прежде чем Intel представит миру Pentium MMX. Это произошло в октябре 1996 года.
V – значит «векторный». А MMX что значит?
В мире математики числа можно группировать в наборы различных видов и размеров – одна такая упорядоченная совокупность называется арифметическим вектором. Проще всего представить его себе в виде списка значений, расположенных горизонтально или вертикально. Технология MMX привнесла в мир процессоров возможность выполнять векторные математические вычисления.
Однако она была изначально довольно ограниченной, поскольку оперировала только целыми числами и фактически эксплуатировала для своих целей регистры FPU. Поэтому программисты, желающие использовать какие-то инструкции MMX, вынуждены иметь в виду, что при выполнении таких инструкций любые вычисления с плавающей запятой не могут выполняться одновременно с ними.
Знаменитая реклама технологии Intel MMX (1997).
FPU Pentium имел 64-битные регистры, и в операциях MMX каждый из них мог вместить два 32-битных, четыре 16-битных или восемь 8-битных целых числа. Именно эти группы чисел и являются векторами, и каждая инструкция, предназначенная для них, будет выполняться сразу над всеми значениями в группе.
Такой принцип получил название SIMD (single instruction, multiple data, «одиночный поток команд, множественный поток данных») и знаменует собой большой шаг вперед в развитии возможностей процессоров для персональных компьютеров.
Ну а какие приложения выигрывают от использования такого принципа? Практически все, которым приходится выполнять одинаковые вычисления над группой однородных данных, и в первую очередь это некоторые функции в 3D-моделировании и мультимедийных технологиях, а также в системах обработки стандартных сигналов.
Например, MMX можно применить для ускорения умножения матриц при обработке вершин в 3D, или для смешивания видеопотоков при работе с хромакеем или альфа-композитингом.

Процессор AMD K6-2 – где-то там есть 3DNow!
К сожалению, внедрение MMX продвигалось довольно медленными темпами из-за негативного влияния этой технологии на производительность операций с плавающей точкой. AMD частично решила эту проблему, создав свою собственную версию под названием 3DNow! примерно через два года после появления MMX. Технология от AMD предлагала больше инструкций SIMD и умела обрабатывать числа с плавающей точкой, но также страдала от недостатка понимания программистами.
Ах, да! Как же официально расшифровывается аббревиатура MMX? Согласно Intel – никак!
Проще пареной SSE
Ситуация переломилась в лучшую сторону с приходом в 1999 году процессора Intel Pentium III. Он принёс с собой блестящую реализацию векторной функции под названием SSE (Streaming SIMD Extensions, «потоковые расширения SIMD»). На этот раз это был дополнительный набор из восьми 128-битных регистров, отдельных от регистров в FPU, и стек дополнительных инструкций для обработки чисел с плавающей точкой.
Использование независимых регистров означает, что больше нет такой сильной зависимости от FPU, хотя Pentium III не мог выполнять инструкции SSE одновременно с инструкциями FP. А также, новая функция поддерживает только один тип данных в регистрах: четыре 32-битных FP-числа.
Но переход к использованию FP-инструкций SIMD позволил значительно увеличить производительность в таких приложениях, как кодирование/декодирование видео, обработка изображений и звука, сжатие файлов и многих других.

Pentium IV: желтым цветом выделен блок регистров SSE2.
Усовершенствованная версия SSE2 появилась в 2001 году вместе с Pentium 4, и на этот раз поддержка типов данных была намного лучше: четыре 32-битных или два 64-битных FP-числа, а также шестнадцать 8-битных, восемь 16-битных, четыре 32-битных или два 64-битных целых числа. Регистры MMX остались в процессоре, но все операции MMX и SSE могли выполняться с использованием независимых 128-битных регистров SSE.
Модификация SSE3 появилась на свет в 2003 году, имея больше инструкций и возможность выполнять некоторые математические вычисления между значениями внутри одного регистра.
Ещё через 3 года мы познакомились с архитектурой Intel Core, принёсшей ещё одну ревизию технологии SIMD (SSSE3 – Supplemental SSE, «расширенные SSE»), и чуть позже в том же году – финальную версию, SSE4.

В 2007 году AMD применила собственную версию расширений CPU-инструкций SSE4 в своей архитектуре Barcelona. С названием в AMD париться не стали, и назвали свою версию просто SSE4a.
С линейкой Nehalem Core в 2008 году было выпущено незначительное обновление этой версии, которую Intel обозначила как SSE4.2 (а под SSE4.1 стали понимать исходную версию этого обновления). Обновления не затронули регистры, а лишь добавили больше инструкций в таблицу, расширив диапазон возможных математических и логических операций.
AMD, со своей стороны, сперва предложила новую версию SSE5, но позже решила разделить ее на три отдельных расширения, одно из которых довольно проблемное – подробнее об этом чуть позже.
К концу 2008 года и Intel, и AMD поставляли процессоры, которые уже могли обрабатывать все версии наборов инструкций от MMX до SSE4.2, и многие приложения (в основном игры) начали требовать этих функций для работы.
Время для новых букв
2008 год также был годом, когда Intel объявила о том, что они работают над значительным апгрейдом своей системы SIMD, и в 2011 году выкатила линейку процессоров Sandy Bridge с поддержкой набора инструкций AVX (Advanced Vector Extensions, «продвинутые векторные расширения»).
Всё удвоилось: вдвое больше векторных регистров и вдвое больше их размер.
Шестнадцать 256-битных регистров вмещают только восемь 32-битных или четыре 64-битных вещественных числа, поэтому в плане форматов данных, этот набор инструкций более ограничен в сравнении с SSE, но ведь и SSE никто не отменял. К тому времени программная поддержка векторных операций для CPU была уже хорошо отлажена, начиная с фундаментального мира компиляторов, заканчивая сложными приложениями.

Intel 80386DX с частотой 16МГц (1985).
Целое (Integer) – в математике, это такое число, которое не имеет дробной части. Например, 8 или -12. Процессоры типа интеловского 80386SX не имели врожденной способности сложить, скажем, 3.80 и 7.26 – такие дробные числа называются числами с плавающей точкой (или запятой, в русском языке это без разницы) – по-английски FP, floating point или просто floats. Чтобы справиться с ними, нужен был другой процессор, например 80387SX, и отдельный набор инструкций – список команд, который сообщает процессору, что делать.
В те времена под инструкциями x86 понимали наборы команд для целочисленных (integer) операций, а под инструкциями x87 – для чисел с плавающей точкой (float). В наши дни все операции умеет выполнять один процессор, поэтому мы используем термин x86 для обозначения набора инструкций обоих типов данных.
Использование отдельных сопроцессоров для обработки разных типов данных было нормой, пока Intel не представила 80486: их первый CPU для персоналок со встроенным математическим сопроцессором для обработки вещественных данных (FPU, Floating Point Unit).
Intel 80486: Жёлтым цветом выделен блок FPU для обработки чисел с плавающей точкой.
Как вы можете видеть, этот блок совсем немного занимает места в процессоре, но рывок в производительности, благодаря этому решению, был огромен.
Но в целом принцип работы оставался скалярным, и таким он перешел и к преемнику 486-го: оригинальному Intel Pentium.
И пройдёт ещё три года после релиза этого первого Пентиума, прежде чем Intel представит миру Pentium MMX. Это произошло в октябре 1996 года.
V – значит «векторный». А MMX что значит?
В мире математики числа можно группировать в наборы различных видов и размеров – одна такая упорядоченная совокупность называется арифметическим вектором. Проще всего представить его себе в виде списка значений, расположенных горизонтально или вертикально. Технология MMX привнесла в мир процессоров возможность выполнять векторные математические вычисления.
Однако она была изначально довольно ограниченной, поскольку оперировала только целыми числами и фактически эксплуатировала для своих целей регистры FPU. Поэтому программисты, желающие использовать какие-то инструкции MMX, вынуждены иметь в виду, что при выполнении таких инструкций любые вычисления с плавающей запятой не могут выполняться одновременно с ними.
Знаменитая реклама технологии Intel MMX (1997).
FPU Pentium имел 64-битные регистры, и в операциях MMX каждый из них мог вместить два 32-битных, четыре 16-битных или восемь 8-битных целых числа. Именно эти группы чисел и являются векторами, и каждая инструкция, предназначенная для них, будет выполняться сразу над всеми значениями в группе.
Такой принцип получил название SIMD (single instruction, multiple data, «одиночный поток команд, множественный поток данных») и знаменует собой большой шаг вперед в развитии возможностей процессоров для персональных компьютеров.
Ну а какие приложения выигрывают от использования такого принципа? Практически все, которым приходится выполнять одинаковые вычисления над группой однородных данных, и в первую очередь это некоторые функции в 3D-моделировании и мультимедийных технологиях, а также в системах обработки стандартных сигналов.
Например, MMX можно применить для ускорения умножения матриц при обработке вершин в 3D, или для смешивания видеопотоков при работе с хромакеем или альфа-композитингом.
Процессор AMD K6-2 – где-то там есть 3DNow!
К сожалению, внедрение MMX продвигалось довольно медленными темпами из-за негативного влияния этой технологии на производительность операций с плавающей точкой. AMD частично решила эту проблему, создав свою собственную версию под названием 3DNow! примерно через два года после появления MMX. Технология от AMD предлагала больше инструкций SIMD и умела обрабатывать числа с плавающей точкой, но также страдала от недостатка понимания программистами.
Ах, да! Как же официально расшифровывается аббревиатура MMX? Согласно Intel – никак!
Проще пареной SSE
Ситуация переломилась в лучшую сторону с приходом в 1999 году процессора Intel Pentium III. Он принёс с собой блестящую реализацию векторной функции под названием SSE (Streaming SIMD Extensions, «потоковые расширения SIMD»). На этот раз это был дополнительный набор из восьми 128-битных регистров, отдельных от регистров в FPU, и стек дополнительных инструкций для обработки чисел с плавающей точкой.
Использование независимых регистров означает, что больше нет такой сильной зависимости от FPU, хотя Pentium III не мог выполнять инструкции SSE одновременно с инструкциями FP. А также, новая функция поддерживает только один тип данных в регистрах: четыре 32-битных FP-числа.
Но переход к использованию FP-инструкций SIMD позволил значительно увеличить производительность в таких приложениях, как кодирование/декодирование видео, обработка изображений и звука, сжатие файлов и многих других.
Pentium IV: желтым цветом выделен блок регистров SSE2.
Усовершенствованная версия SSE2 появилась в 2001 году вместе с Pentium 4, и на этот раз поддержка типов данных была намного лучше: четыре 32-битных или два 64-битных FP-числа, а также шестнадцать 8-битных, восемь 16-битных, четыре 32-битных или два 64-битных целых числа. Регистры MMX остались в процессоре, но все операции MMX и SSE могли выполняться с использованием независимых 128-битных регистров SSE.
Модификация SSE3 появилась на свет в 2003 году, имея больше инструкций и возможность выполнять некоторые математические вычисления между значениями внутри одного регистра.
Ещё через 3 года мы познакомились с архитектурой Intel Core, принёсшей ещё одну ревизию технологии SIMD (SSSE3 – Supplemental SSE, «расширенные SSE»), и чуть позже в том же году – финальную версию, SSE4.
В 2007 году AMD применила собственную версию расширений CPU-инструкций SSE4 в своей архитектуре Barcelona. С названием в AMD париться не стали, и назвали свою версию просто SSE4a.
С линейкой Nehalem Core в 2008 году было выпущено незначительное обновление этой версии, которую Intel обозначила как SSE4.2 (а под SSE4.1 стали понимать исходную версию этого обновления). Обновления не затронули регистры, а лишь добавили больше инструкций в таблицу, расширив диапазон возможных математических и логических операций.
AMD, со своей стороны, сперва предложила новую версию SSE5, но позже решила разделить ее на три отдельных расширения, одно из которых довольно проблемное – подробнее об этом чуть позже.
К концу 2008 года и Intel, и AMD поставляли процессоры, которые уже могли обрабатывать все версии наборов инструкций от MMX до SSE4.2, и многие приложения (в основном игры) начали требовать этих функций для работы.
Время для новых букв
2008 год также был годом, когда Intel объявила о том, что они работают над значительным апгрейдом своей системы SIMD, и в 2011 году выкатила линейку процессоров Sandy Bridge с поддержкой набора инструкций AVX (Advanced Vector Extensions, «продвинутые векторные расширения»).
Всё удвоилось: вдвое больше векторных регистров и вдвое больше их размер.
Шестнадцать 256-битных регистров вмещают только восемь 32-битных или четыре 64-битных вещественных числа, поэтому в плане форматов данных, этот набор инструкций более ограничен в сравнении с SSE, но ведь и SSE никто не отменял. К тому времени программная поддержка векторных операций для CPU была уже хорошо отлажена, начиная с фундаментального мира компиляторов, заканчивая сложными приложениями.
И не даром: Core i7-2600K (или подобный ему), работающий на частоте 3,8ГГц, потенциально может выдавать более 230 GFLOPS (миллиардов операций с плавающей точкой в секунду) при выполнении инструкций AVX – неплохо для дополнения, относительно немного места занимающего на кристалле процессора.
Или могло бы быть неплохо, если бы он действительно работал на частоте 3,8ГГц. Частично проблема AVX заключалась в том, что нагрузка на чип получалась настолько высокой, что Intel пришлось заставить процессор автоматически снижать тактовую частоту в этом режиме примерно на 20%, чтобы уменьшить энергопотребление и не допустить перегрева. К сожалению, такова цена за выполнение любой работы SIMD в современном процессоре.
Еще одно усовершенствование, предлагаемое в AVX – это возможность работать одновременно с тремя значениями. Во всех версиях SSE операции выполнялись между двумя значениями, после чего результат заменял одно из них в регистре. При выполнении инструкций SIMD AVX не трогает исходные значения, сохраняя результирующее значение в отдельный регистр.

AVX2 был выпущен вместе с архитектурой Haswell для процессоров Core 4-го поколения в 2013 году, и представлял собой довольно значительный апгрейд, благодаря добавлению нового расширения: FMA (Fused Multiply-Add, «умножение-сложение с однократным округлением»).
Эта независимая функция в составе AVX2 была крайне востребована для приложений, работающих с векторной и матричной математикой, поскольку давала возможность выполнять две операции с помощью одной инструкции. Функция поддерживала и скалярные операции также.
Проблема оказалась в том, что FMA от Intel отличался от аналогичного расширения AMD настолько, что они были совершенно несовместимы. Причина в том, что Intel FMA представляет собой систему с тремя операндами, то есть работает с тремя отдельными значениями: два слагаемых и сумма, либо три слагаемых и сумма, замещающая одно из слагаемых.
У версии от AMD четыре операнда, поэтому она может вычислить 3 числа и записать ответ в отдельный регистр, не трогая исходные значения. Математически FMA4 лучше, чем FMA3, но его реализация немного сложнее, как с точки зрения программирования, так и с точки зрения интеграции функции в процессор.
AVX-512: а не многовато-ли?
AVX2 ещё только начал появляться на рынке процессоров, а Intel уже плела маниакальные планы относительно его преемника, AVX-512, и общий настрой среди разработчиков был такой: «больше регистров богу регистров!». Мало того, что этих самых регистров снова вдвое больше, и они снова вдвое увеличились в размере, так ещё и появился стек новых инструкций и поддержка устаревших.
Первой партией чипов, на которых поднялся в воздух набор функций AVX-512, стала серия Xeon Phi 7200 – второе поколение громоздких и очень многоядерных процессоров Intel, ориентированных на рынок суперкомпьютеров.

72-ядерный 288-потоковый Knights Landing Xeon Phi.
В отличие от всех предыдущих реализаций, новый набор векторных инструкций состоял из 19-и компонентов: базового – AVX-512F, – необходимого для обеспечения совместимости, и множества весьма специфических. Эти дополнительные наборы охватывают такие области операций, как обратная математика, целочисленные FMA и алгоритмы свёрточной (конволюционной) нейронной сети (CNN-алгоритмы).
Первоначально AVX-512 был только прерогативой крупнейших чипов Intel, предназначенных для рабочих станций и серверов, но теперь их недавние архитектуры Ice Lake и Tiger Lake также поддерживают его. Да, не удивляйтесь: вы можете купить легкий ноутбук с процессором, имеющим 512-битные векторные блоки.
Это может показаться круто. А может и не показаться – в зависимости от вашей точки зрения. Регистры на кристалле CPU обычно группируются в так называемом регистровом файле, как видно на макрофото ниже.
 2-ядерный Intel Skylake
2-ядерный Intel Skylake
Желтым прямоугольником выделен файл векторных регистров, красный прямоугольник – это наиболее вероятное расположение файла целочисленного регистра. Обратите внимание, насколько файл векторного регистра больше integer-регистра. В Skylake используются 256-битные регистры AVX2, следовательно аналогичный векторный регистровый файл AVX-512 занял бы на таком же кристалле в четыре раза больше места: вдвое больше, потому что вдвое больше их размер, и ещё вдвое – потому что самих регистров вдвое больше.
А очень-ли нужно такое количество векторных регистров маленькому чипу, который должен быть максимально мобильным? Хоть речь и не о лишних килограммах в ноутбуке, а лишь о небольшой части площади ядра процессора, каждый квадратный миллиметр имеет значение, когда речь идет о миниатюризации мобильных устройств и наиболее эффективном использовании доступного пространства в них.
И учитывая, что использование AVX в любом виде приводит к автоматическому уменьшению тактовой частоты, использование AVX-512 на таких платформах скорее всего приведет к ещё более сомнительным издержкам по сравнению с любым из своих предшественников, поскольку при работе он потребляет еще больше энергии.

AVX2 был выпущен вместе с архитектурой Haswell для процессоров Core 4-го поколения в 2013 году, и представлял собой довольно значительный апгрейд, благодаря добавлению нового расширения: FMA (Fused Multiply-Add, «умножение-сложение с однократным округлением»).
Эта независимая функция в составе AVX2 была крайне востребована для приложений, работающих с векторной и матричной математикой, поскольку давала возможность выполнять две операции с помощью одной инструкции. Функция поддерживала и скалярные операции также.
Проблема оказалась в том, что FMA от Intel отличался от аналогичного расширения AMD настолько, что они были совершенно несовместимы. Причина в том, что Intel FMA представляет собой систему с тремя операндами, то есть работает с тремя отдельными значениями: два слагаемых и сумма, либо три слагаемых и сумма, замещающая одно из слагаемых.
У версии от AMD четыре операнда, поэтому она может вычислить 3 числа и записать ответ в отдельный регистр, не трогая исходные значения. Математически FMA4 лучше, чем FMA3, но его реализация немного сложнее, как с точки зрения программирования, так и с точки зрения интеграции функции в процессор.
AVX-512: а не многовато-ли?
AVX2 ещё только начал появляться на рынке процессоров, а Intel уже плела маниакальные планы относительно его преемника, AVX-512, и общий настрой среди разработчиков был такой: «больше регистров богу регистров!». Мало того, что этих самых регистров снова вдвое больше, и они снова вдвое увеличились в размере, так ещё и появился стек новых инструкций и поддержка устаревших.
Первой партией чипов, на которых поднялся в воздух набор функций AVX-512, стала серия Xeon Phi 7200 – второе поколение громоздких и очень многоядерных процессоров Intel, ориентированных на рынок суперкомпьютеров.
72-ядерный 288-потоковый Knights Landing Xeon Phi.
В отличие от всех предыдущих реализаций, новый набор векторных инструкций состоял из 19-и компонентов: базового – AVX-512F, – необходимого для обеспечения совместимости, и множества весьма специфических. Эти дополнительные наборы охватывают такие области операций, как обратная математика, целочисленные FMA и алгоритмы свёрточной (конволюционной) нейронной сети (CNN-алгоритмы).
Первоначально AVX-512 был только прерогативой крупнейших чипов Intel, предназначенных для рабочих станций и серверов, но теперь их недавние архитектуры Ice Lake и Tiger Lake также поддерживают его. Да, не удивляйтесь: вы можете купить легкий ноутбук с процессором, имеющим 512-битные векторные блоки.
Это может показаться круто. А может и не показаться – в зависимости от вашей точки зрения. Регистры на кристалле CPU обычно группируются в так называемом регистровом файле, как видно на макрофото ниже.
2-ядерный Intel Skylake
Желтым прямоугольником выделен файл векторных регистров, красный прямоугольник – это наиболее вероятное расположение файла целочисленного регистра. Обратите внимание, насколько файл векторного регистра больше integer-регистра. В Skylake используются 256-битные регистры AVX2, следовательно аналогичный векторный регистровый файл AVX-512 занял бы на таком же кристалле в четыре раза больше места: вдвое больше, потому что вдвое больше их размер, и ещё вдвое – потому что самих регистров вдвое больше.
А очень-ли нужно такое количество векторных регистров маленькому чипу, который должен быть максимально мобильным? Хоть речь и не о лишних килограммах в ноутбуке, а лишь о небольшой части площади ядра процессора, каждый квадратный миллиметр имеет значение, когда речь идет о миниатюризации мобильных устройств и наиболее эффективном использовании доступного пространства в них.
И учитывая, что использование AVX в любом виде приводит к автоматическому уменьшению тактовой частоты, использование AVX-512 на таких платформах скорее всего приведет к ещё более сомнительным издержкам по сравнению с любым из своих предшественников, поскольку при работе он потребляет еще больше энергии.
И проблема AVX-512 не только в применении к небольшим мобильным процессорам. Разработчикам, пишущим код для работы на рабочих станциях и серверах, и для которых увеличение возможностей векторных расширений действительно важный вопрос, потребуется создавать несколько версий кода. Это связано с тем, что не все процессоры с AVX-512 работают с одинаковым набором команд.
Например, набор IFMA (Integer Fused Multiply Add, «целочисленное умножение-сложение с однократным округлением») доступен только на процессорах Cannon, Ice и Tiger Lake. В то время как процессоры на архитектуре Cooper и Cascade Lake его не поддерживают, несмотря на то, что они относятся к сегменту процессоров для серверов и рабочих станций.
Стоит отметить, что AMD не предлагает поддержку AVX-512, и не собирается. По их мнению, обработка массивных векторных вычислений – это прерогатива GPU. С AMD полностью солидарна Nvidia, и обе компании уже выпустили продукты специально для таких нужд.
И дальше что?
Много лет назад процессор с возможностью обработки векторной математики ознаменовал собой эпохальный прорыв. Современные процессоры обладают огромными возможностями, предлагая множество наборов инструкций для обработки целочисленных операций и операций с плавающей запятой для скалярных, векторных и матричных данных.
Что касается последних двух типов данных, то CPU теперь напрямую конкурируют с GPU: ведь мир 3D-графики – это как раз всё, что связано с SIMD, векторами, плавающими точками и т.д. И производители GPU не спали – разработка графических ускорителей велась стремительными темпами. В начале 2010-х годов купить видеокарту, процессор которой способен выполнять почти 800 миллиардов инструкций SIMD в секунду, вы уже могли менее чем за 500 долларов.
Это больше, чем то, на что сейчас способны лучшие из десктопных CPU. Но они и не предназначены для рекордов в какой-то конкретной области – их задача обрабатывать очень обобщенный код, который зачастую не повторяется или легко распараллеливается. Поэтому, не стоит думать, что возможности SIMD столь жизненно-важны для CPU, скорее это полезное дополнение к его арсеналу.
 Вас интересует производительность SIMD в чистом виде? Ваш выбор – видеокарта, а не материнка!
Вас интересует производительность SIMD в чистом виде? Ваш выбор – видеокарта, а не материнка!
Стремительное развитие графических процессоров недвусмысленно намекает, что для CPU нет нужды иметь чересчур большие векторные блоки, и почти наверняка именно поэтому AMD даже не пыталась разрабатывать своего собственного преемника для AVX2 (расширение, которое они используют в своих чипах с 2015 года). Давайте также не будем забывать, что процессоры следующего поколения могут больше походить на мобильные однокристальные (SoC, System-on-a-Chip), где под каждый тип задач выделена площадь на кристалле. Intel, в свою очередь, похоже, стремится внедрить AVX-512 в как можно большее количество продуктов.
Ждёт ли нас ещё и AVX-1024? Вряд ли, либо очень нескоро. Скорее всего, Intel займётся расширением AVX-512 с помощью дополнительных компонентов с инструкциями, чтобы повысить гибкость, а чистую SIMD-производительность переложит на плечи своей недавно разработанной линейки графических процессоров Xe.

Библиотеки SSE и AVX теперь являются неотъемлемой частью программного обеспечения: Adobe Photoshop требует, чтобы процессоры поддерживали как минимум SSE4.2; API машинного обучения TensorFlow требует поддержки AVX; Microsoft Teams может выполнять фоновые видеоэффекты, только если доступен AVX2.
Это говорит только об одном: несмотря на то, что в плане обработки SIMD графическим процессорам нет равных, этот функционал ещё долго будет в арсенале CPU. Так что будем ждать нового поколения векторных расширений и надеюсь, реклама нас впечатлит.
Путешествие через вычислительный конвейер процессора
Время на прочтение
16 мин
Количество просмотров 130K
 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Что происходит внутри процессора? Сколько времени уходит на исполнение одной инструкции? Что значит, когда новый процессор имеет 12, или 18, или даже 31-уровневый конвейер?
Программы обычно работают с процессором, как с чёрным ящиком. Инструкции входят и выходят из него по порядку, а внутри совершается некая вычислительная магия.
Программисту полезно знать, что происходит внутри этого ящика, особенно, если он будет заниматься оптимизацией программ. Если вы не знаете какие процессы протекают внутри процессора, как вы сможете оптимизировать под него?
Эта статья рассказывает, как устроен вычислительный конвейер x86 процессора.
Вещи, которые вы уже должны знать
Во-первых, предполагается, что вы немного разбираетесь в программировании или может даже немного знаете ассемблер. Если вы не понимаете, что я имею ввиду, когда использую термин «указатель на инструкцию» (instruction pointer), тогда, возможно, эта статья не для вас. Когда я пишу о регистрах, инструкциях и кэшах, я предполагаю, что вы уже знаете, что это значит, можете понять или нагуглить.
Во-вторых, эта статья – упрощение сложной темы. Если вам кажется, что я пропустил какие-то важные моменты, добро пожаловать в комментарии.
В-третьих, я акцентирую внимание только на процессорах Intel x86 семейства. Я знаю о существовании других семейств процессоров, кроме x86. Я знаю, что AMD внесло много полезных нововведений в x86 семейство, и Intel их приняло. Но архитектура и набор инструкций принадлежит Intel, также Intel представило реализацию самых главных особенностей семейства, так что для простоты и логичности, речь пойдет именно об их процессорах.
В-четвертых, эта статья уже устарела. В разработке более новые процессоры, и некоторые из них уже скоро ожидаются в продаже. Я очень рад, что технологии развиваются такими быстрыми темпами и надеюсь, что когда-нибудь все стадии, описанные ниже, полностью устареют и будут заменены еще более удивительными достижениями в процессоростроении.
Основы вычислительного конвейера
Если посмотреть на x86 семейство в целом, то можно заметить, что оно не сильно изменилось за 35 лет. Было много дополнений, но оригинальный дизайн, как и почти весь набор команд, в основном остались нетронутыми и до сих пор прослеживаются в современных процессорах.
Первоначальный 8086 процессор имеет 14 регистров, которые используются до сих пор. Четыре регистра общего назначения – AX, BX, CX и DX. Четыре сегментных регистра, которые используют для облегчения работы с указателями – CS (Code Segment), DS (Data Segment), ES (Extra Segment) и SS (Stack Segment). Четыре индексных регистра, которые указывают на различные адреса в памяти – SI (Source Index), DI (Destination Index), BP (Base Pointer) и SP (Stack Pointer). Один регистр содержит битовые флаги. И, наконец, самый главный регистр в этой статье – IP (Instruction Pointer).
IP регистр – это указатель с особой функцией, его задача указывать на следующую инструкцию, которая подлежит исполнению.
Все процессоры в x86 семействе следуют одному и тому же принципу. Сначала они следуют указателю на инструкцию и декодируют следующую команду по этому адресу. После декодирования следует этап выполнения этой инструкции. Некоторые инструкции читают из памяти или пишут в нее, другие производят вычисления, сравнения или другую работу. Когда работа окончена, команда проходит через этап отставки (retire stage) и IP начинает указывать на следующую инструкцию.
Этот принцип декодирования, выполнения и отставки одинаково применяется как в первом 8086 процессоре, так и в самом последнем Core i7. С течением времени были добавлены новые этапы конвейера, но принцип работы остался прежним.
Что изменилось за 35 лет
Первые процессоры были просты по сегодняшним меркам. 8086 процессор начинал с проверки команды на текущем указателе на инструкцию, декодировал ее, выполнял, отставлял и продолжал работу со следующей инструкцией на которую указывал IP.
Каждый новый чип в семействе добавлял новую функциональность. Большинство добавляло новые инструкции, некоторые добавляли новые регистры. Чтобы оставаться в рамках этой статьи, я буду уделять внимание изменениям, которые непосредственно касаются прохождения команд через ЦП. Другие изменения, такие как добавление виртуальной памяти или параллельной обработки, конечно же интересны, но выходят за рамки данной статьи.
В 1982 был введён кэш инструкций. Вместо обращения к памяти на каждой команде, процессор читал на несколько байт дальше текущего IP. Кэш инструкций был всего несколько байт в размере, достаточным для хранения лишь нескольких команд, но ощутимо увеличивал производительность, исключая постоянные обращения к памяти каждые несколько тактов.
В 1985 в 386 процессор был добавлен кэш данных и увеличен размер кэша инструкций. Этот шаг позволил увеличить производительность за счет чтения на несколько байт дальше запроса на данные. На тот момент кэши данных и инструкций измерялись в килобайтах, нежели в байтах.
В 1989 i486 процессор перешел на 5-уровневый конвейер. Вместо наличия одной инструкции во всем процессоре, теперь каждый уровень конвейера мог иметь по инструкции. Это нововведение позволило увеличить производительность более чем в два раза по сравнению с 386 процессором на той частоте. Этап загрузки (fetch stage) извлекал команду из кэша инструкций (размер кэша в то время был обычно 8кб). Второй этап декодировал инструкцию. Третий этап транслировал адреса памяти и смещения, необходимые для команды. Четвёртый этап выполнял инструкцию. Пятый этап отправлял команду в отставку и записывал результаты обратно в регистры и память по мере необходимости. Появление возможности держать в процессоре множество инструкций одновременно позволило программам выполняться гораздо быстрее.
1993 год был годом появления процессора Pentium. Название семейства процессоров сменилось с номеров на имена из-за судебного процесса, поэтому оно было названо Pentium вместо 586. Конвейер чипа изменился еще больше по сравнению с i486. Архитектура Pentium добавила второй отдельный суперскалярный конвейер. Основной конвейер работал также, как и на i486, в то время как второй выполнял более простые инструкции, такие как целочисленная арифметика, параллельно и намного быстрее.
В 1995 Intel выпустило процессор Pentium Pro, который имел кардинальные изменения в дизайне. У чипа появилось несколько особенностей, включая ядро с внеочерёдным (Out-of-Order, OOO) и упреждающим (Speculative) исполнением команд. Конвейер был расширен до 12 этапов, и в него вошло нечто, называемое суперконвейером (superpipeline), где большое количество инструкций могло исполняться одновременно. OOO ядро будет более подробно освещено ниже в статье.
Между 1995 годом, когда OOO ядро было представлено, и 2002 было сделано много важных изменений. Были добавлены дополнительные регистры и представлены инструкции, которые могли обрабатывать множество данных за раз (Single Instruction Multiple Data, SIMD). Появились новые кэши, старые увеличились в размере. Этапы конвейера делились и объединялись, адаптируясь к требованиям реального мира. Эти и многие другие изменения были важны для общей производительности, но мало что значили, когда речь шла о потоке данных через процессор.
В 2002 Pentium 4 представил новую технологию — Hyper-Threading. OOO ядро было настолько успешным в обработке команд, что способно было обрабатывать инструкции быстрее, чем они могли быть посланы ядру. Для большинства пользователей OOO ядро процессора практически бездействовало большую часть времени даже под нагрузкой. Для обеспечения постоянного потока инструкций к OOO ядру добавили второй фронт-энд. Операционная система видела два процессора вместо одного. Процессор содержал два набора x86 регистров, два декодера инструкций, которые следили за двумя наборами IP и обрабатывали два набора инструкций. Далее команды обрабатывались одним общим OOO ядром, но это было незаметно для программ. Потом инструкции проходили этап отставки, как и ранее, и посылались назад к виртуальным процессорам, на которые они поступали.
В 2006 Intel выпустило микроархитектуру Core. В маркетинговых целях она была названа Core 2 (потому что каждый знает, что два лучше, чем один). Неожиданным ходом было снижение частоты процессоров и отказ от Hyper-Threading. Снижение частот способствовало расширению всех этапов вычислительного конвейера. OOO ядро было расширено, кэши и буферы были увеличены. Архитектура процессоров была переработана с уклоном на двух- и четырёхъядерные чипы с общими кэшами.
В 2008 Intel ввело схему именования процессоров Core i3, Core i5 и Core i7. В этих процессорах вновь появился Hyper-Threading с общим OOO ядром, и отличались они, в основном, лишь размерами кэшей.
Будущие процессоры: Следующее обновление микроархитектуры, названной Haswell, по слухам, будет выпущено во второй половине 2013. Опубликованные на данный момент документы говорят о том, что это будет 14-уровневый конвейер, и, скорей всего, принцип обработки информации будет все также следовать дизайну Pentium Pro.
Так что же такое этот вычислительный конвейер, что такое OOO ядро и как это все увеличивает скорость обработки?
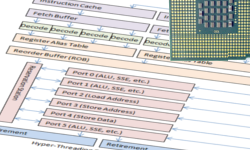
Вычислительный конвейер процессора
В самом простой форме, описанной выше, одиночная инструкция входит в процессор, обрабатывается и выходит с другой стороны. Это довольно интуитивно для большинства программистов.
Процессор i486 имел 5-уровневый конвейер – загрузка (Fetch), основное декодирование (D1), вторичное декодирование или трансляция (D2), выполнение (EX), запись результата в регистры и память (WB). Каждый этап конвейера мог содержать по инструкции.

Конвейер i486 и пять инструкций, проходящие через него одновременно.
Однако такая схема имела серьезный недостаток. Представьте себе код ниже. До прихода конвейера следующие три строки кода были распространенным способом поменять значения двух переменных без использования третьей.
XOR a, b
XOR b, a
XOR a, b
Чипы, начиная с 8086 и до 386 не имели внутреннего конвейера. Они обрабатывали только одну инструкцию в каждый момент времени, независимо и полностью. Три последовательных XOR инструкции в такой архитектуре вовсе не проблема.
Теперь подумаем, что происходит с i486, так как это был первый x86 чип с конвейером. Наблюдать за многими вещами в движении одновременно может быть затруднительно, поэтому, возможно, вы сочтёте полезным обратиться к диаграмме выше.
Первая инструкция входит в этап загрузки, на этом первый шаг закончен. Следующий шаг – первая инструкция входит в D1 этап, вторая инструкция помещается в этап загрузки. Третий шаг – первая инструкция двигается в D2 этап, вторая в D1 и третья загружается в Fetch. На следующем шагу что-то идет не так – первая инструкция переходит в EX…, но остальные остаются на месте. Декодер останавливается, потому что вторая XOR команда требует результат первой. Переменная «a» должна быть использована во второй инструкции, но в неё не будет произведена запись, пока не выполнилась первая инструкция. Поэтому команды в конвейере ждут, пока первая команда не пройдет EX и WB этапы. Только после этого вторая инструкция может продолжить свой путь по конвейеру. Третья команда аналогично застрянет в ожидании выполнения второй команды.
Такое явление называется ступор конвейера (pipeline stall) или конвейерный пузырь (pipeline bubble).
Другой проблемой конвейеров является возможность одних инструкций выполняться очень быстро, а других очень медленно, что было более заметно с двойным конвейером Pentium.
Pentium Pro представил с собой 12-уровневый конвейер. Когда это число было впервые озвучено, то понимавшие как работал суперскалярный конвейер программисты затаили дыхание. Если бы Intel последовало такому же принципу с 12-уровневым конвейером, то любой ступор конвейера или медленная инструкция серьезно бы сказывались на производительности. Но в то же время Intel анонсировало кардинально отличающийся конвейер, названный ядром с внеочерёдным исполнением (OOO core). Несмотря на то, что это трудно было понять из документации, Intel заверило разработчиков, что они будут потрясены результатами.
Давайте разберем OOO ядро более детально.
OOO конвейер
В случае с OOO ядром, иллюстрация стоит тысячи слов. Так что давайте посмотрим несколько картинок.
Диаграмы конвейеров процессора
5-уровневый конвейер i486 работал замечательно. Эта идея была довольно распространена среди других семейств процессоров в то время и работала отлично в реальных условиях.
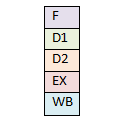
Суперскалярный конвейер i486.
Конвейер Pentium был даже еще лучше i486. Он имел два вычислительных конвейера, которые могли работать параллельно, и каждый из них мог содержать множество инструкций на различных этапах, позволяя вам обрабатывать почти в двое больше инструкций за то же время.
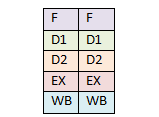
Два параллельных суперскалярных конвейера Pentium.
Однако наличие быстрых команд, ожидающих выполнение медленных, было все также проблемой в параллельных конвейерах, как и наличие последовательных команд (привет ступор). Конвейеры были все так же линейными и могли сталкиваться с непреодолимыми ограничениями производительности.
Дизайн OOO ядра сильно отличался от предыдущих чипов с линейными путями. Сложность конвейера возросла, и были введены нелинейные пути.
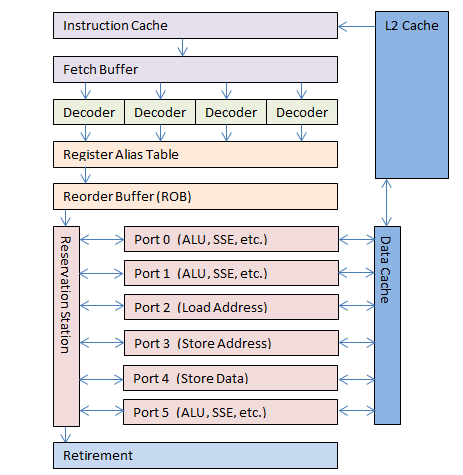
OOO ядро, используемое с 1995 года. Цветовое обозначение соответствует пяти этапам, используемых в предыдущих процессорах. Некоторые этапы и буферы не показаны, так как варьируются от процессора к процессору.
Сначала инструкции загружаются из памяти и помещаются в кэш инструкций процессора. Декодер современного процессора может предсказать появление скорого ветвления (например вызов функции) и начать загрузку инструкций заранее.
Этап декодирования был немного изменен по сравнению с более ранними чипами. Вместо обработки лишь одной инструкции на IP, Pentium Pro мог декодировать до трех инструкций за такт. Сегодняшние процессоры (2008-2013) могут декодировать до четырёх инструкций за такт. Результатом декодирования являются микрооперации (micro-ops / µ-ops).
Следующий этап (или группа этапов) состоит из трансляции микроопераций (micro-op transaltion) и последующего присвоения псевдонимов регистрам (register aliasing). Множество операций выполняются одновременно, возможно внеочерёдно, поэтому одна инструкция может читать из регистра, пока другая в него пишет. Запись в регистр может подавить значение, нужное другой инструкции. Оригинальные регистры внутри процессора (AX, BX, CX, DX итд.) транслируются (или создаются псевдонимы) во внутренние, скрытые от программиста регистры. Значение регистров и адресов памяти затем должны быть привязаны к временным значениям для обработки. На данный момент 4 микрооперации могут проходить через этап трансляции за такт.
После трансляции все микрооперации входят в буфер переупорядочивания (reorder buffer, ROB). На данный момент этот буфер может вмещать до 128 микроопераций. На процессорах с HT ROB также может выступать в роли координатора входных команд с виртуальных процессоров, распределяя два потока команд на одно OOO ядро.
Теперь микрооперации готовы для обработки и помещаются в резервацию (reservation station, RS). RS на данный момент может вмещать 36 микроопераций в любой момент времени.
Теперь настало время для магии OOO ядра. Микрооперации обрабатываются одновременно на множестве исполнительных блоков (execution unit), причем каждый блок работает максимально быстро. Микрооперации могут обрабатываться внеочерёдно, если все нужные данные для этого уже доступны. Если данные недоступны, выполнение откладывается до их готовности, пока выполняются другие готовые микрооперации. Таким образом долгие операции не блокируют быстрые и последствия ступора конвейера уже не так печальны.
OOO ядро Pentium Pro имело шесть исполнительных блоков: два для работы с целыми числами, один для чисел с плавающей точкой, загрузочный блок, блок сохранения адресов и блок сохранения данных. Два целочисленных блока были специализированы, один мог работать со сложными операциями, другой мог обрабатывать две простые операции за раз. В идеальных условиях исполнительные блоки Pentium Pro могли обрабатывать семь микроопераций за такт.
Сегодняшнее OOO ядро также содержит шесть исполнительных блоков. Оно до сих пор содержит блоки загрузки адреса, сохранения адреса и сохранения данных. Однако остальные три немного изменились. Каждый из трех блоков теперь может выполнять простые математические операции или более сложную микрооперацию. Каждый из трех блоков специализирован для конкретных микроопераций, позволяя выполнять работу быстрее, по сравнению с блоками общего назначения. В идеальных условиях нынешнее OOO ядро может обрабатывать 11 микроопераций за такт.
Наконец микрооперация начинает выполняться. Она проходит через более мелкие этапы (отличающиеся между процессорами) и проходит этап отставки. В этот момент микрооперация возвращается во внешний мир и IP начинает указывать на следующую инструкцию. С точки зрения программы, инструкция просто входит в процессор и выходит с другой стороны, точно так же, как это было со старым 8086.
Если вы внимательно читали статью, вы возможно могли заметить очень важную проблему в описании выше. Что произойдет в случае смены места исполнения? Например, что произойдет, если код доходит до if или switch конструкции? В более старых процессорах это значило сброс всей работы в суперскалярном конвейере и ожидание начала обработки новой ветки исполнения.
Ступор конвейера, когда в процессоре находится сотня или более инструкций очень серьезно сказывается на производительности. Каждая инструкция вынуждена ждать, пока инструкции с нового адреса будут загружены и конвейер будет перезапущен. В этой ситуации OOO ядро должно отменить всю текущую работу, откатиться до предыдущего состояния, подождать, пока все микрооперации пройдут отставку, отбросить их вместе с результатами и затем продолжить работу по новому адресу. Эта проблема была очень серьёзной и часто случалась при проектировании. Показатели производительности в такой ситуации были неприемлемы для инженеров. Именно здесь приходит на помощь еще одна важная особенность OOO ядра.
Их ответ был – упреждающее выполнение. Упреждающее выполнение означает, что когда OOO ядро встречает в коде условные конструкции (например if блок), оно просто загрузит и выполнит две ветки кода. Как только ядро понимает, какая ветка верная, результаты второй будут сброшены. Это предотвращает ступор конвейера ценой незначительных издержек на запуск кода в неверной ветке. Также был добавлен кэш для предсказания ветвления (branch prediction cache), который намного улучшил результаты в ситуациях, когда ядро было вынуждено прогнозировать среди множества условных переходов. Ступоры конвейера до сих пор встречаются из-за ветвления, однако это решение позволило сделать их редким исключением, нежели обычным явлением.
Ну и наконец, процессор с HT предоставляет два виртуальных процессора для одного общего OOO ядра. Они разделяют общий ROB и OOO ядро и будут видны для операционной системы как два отдельных процессора. Это выглядит примерно так:
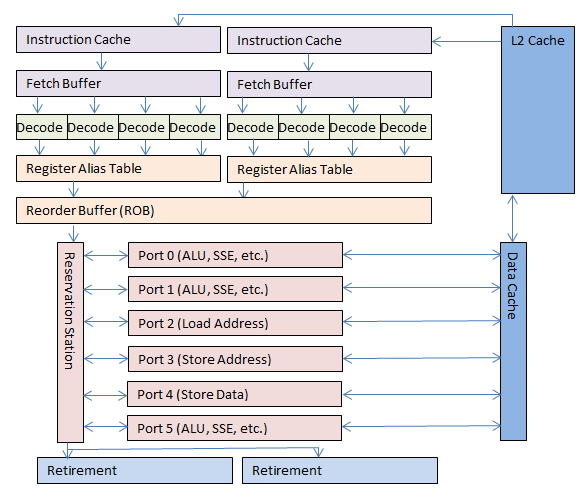
OOO ядро с Hyper-Threading, см. примечание.
Процессор с HT получает два виртуальных процессора, которые взамен поставляют больше данных OOO ядру, что дает увеличение производительности при обычном пользовании. Лишь некоторые тяжелые вычислительные нагрузки, оптимизированные под многопроцессорные системы, могут полностью загрузить OOO ядро. В этом случае HT может несколько понизить производительность. Однако такие нагрузки относительно редки. Для потребителя HT обычно позволяет увеличивать скорость работы примерно вдвое при обычном ежедневном пользовании компьютером.
Пример
Всё это может показаться немного запутанным. Надеюсь, пример расставит всё на свои места.
С точки зрения приложения, мы все ещё работаем на вычислительном конвейере старого 8086. Это чёрный ящик. Инструкция, на которую указывает IP, обрабатывается этим ящиком, и, когда инструкция выходит из него, результаты уже отображены в памяти.
Хотя с точки зрения инструкции, этот чёрный ящик то ещё приключение.
Ниже приводится путь, который совершает инструкция в современном процессоре (2008-2013).
Поехали, вы – инструкция в программе, и эта программа запускается.
Вы терпеливо ждете, пока IP начнет указывать на вас для последующей обработки. Когда IP указывает примерно за 4кб до вашего расположения, или за 1500 инструкций, вы перемещаетесь в кэш инструкций. Загрузка в кэш занимает некоторое время, но это не страшно, так как вы ещё нескоро будете запущены. Эта предзагрузка (prefetch) является частью первого этапа конвейера.
Тем временем IP указывает всё ближе и ближе к вам, и, когда он начинает указывать за 24 инструкции до вас, вы и пять соседних команд отправляетесь в очередь инструкций (instruction queue).
Этот процессор имеет четыре декодера, которые могут вмещать одну сложную команду и до трёх простых. Так случилось, что вы сложная инструкция и были декодированы в четыре микрооперации.
Декодирование – это многоуровневый процесс. Часть декодирования включает в себя анализ на предмет требуемых вами данных и вероятность перехода в какое-то новое место. Декодер зафиксировал потребность в дополнительных данных. Без вашего участия, где-то на другом конце компьютера, нужные вам данные начинают загрузку в кэш данных.
Ваши четыре микрооперации подходят к таблице псевдонимов регистров. Вы объявляете с какого адреса памяти вы читаете (это оказывается fs:[eax+18h]), и чип транслирует его во временный адрес для ваших микроопераций. Ваши микрооперации входят в ROB, откуда, при первой же возможности, двигаются в резервацию.
Резервация содержит инструкции, готовые к исполнению. Ваша третья микрооперация немедленно подхватывается пятым портом исполнения. Вам не известно, почему она была выбрана первой, но её уже нет. Через несколько тактов ваша первая микрооперация устремляется во второй порт, блок загрузки адресов. Оставшиеся микрооперации ждут, пока различные порты подхватывают другие микрооперации. Они ждут, пока второй порт загружает данные из кэша данных во временные слоты памяти.
Долго ждут…
Очень долго ждут…
Другие инструкции приходят и уходят, в то время как ваши микрооперации ждут своего друга, пока тот загружает нужные данные. Хорошо, что этот процессор знает как обрабатывать их внеочерёдно.
Внезапно, обе оставшиеся микрооперации подхватываются нулевым и первым портом, должно быть загрузка данных завершена. Все микрооперации запущены и со временем они вновь встречаются в резервации.
По пути обратно через ворота, микрооперации передают свои билеты с временными адресами. Микрооперации собираются и объединяются, и вы вновь, как инструкция, чувствуете себя единым целым. Процессор вручает вам ваш результат и вежливо направляет к выходу.
Через дверь с пометкой “Отставка” стоит короткая очередь. вы встаете в очередь и обнаруживаете, что вы стоите за той же инструкцией, за которой и заходили. Вы даже стоите в том же порядке. Получается, что OOO ядро действительно знает своё дело.
Со стороны выглядит так, что каждая выходящая из процессора команда выходит по одной, точно в таком же порядке, в каком IP указывал на них.
Заключение
Надеюсь, что эта маленькая лекция пролила немного света на то, что происходит внутри процессора. Как видите, здесь нет магии, дыма и зеркал.
Теперь мы можем ответить на вопросы, заданные в начале статьи.
Так что же происходит внутри процессора? Это сложный мир, где инструкции разбиваются на микрооперации, обрабатываются при первой же возможности и в любом порядке, и вновь собираются воедино, сохраняя свой порядок и расположение. Для внешнего мира выглядит так, будто они обрабатываются последовательно и независимо друг от друга. Но мы теперь знаем, что на самом деле, они обрабатываются внеочерёдно, иногда даже предсказывая и запуская вероятные ветки кода.
Сколько времени уходит на исполнение одной инструкции? Тогда как в бесконвейерном мире для этого имелся хороший ответ, в современном же процессоре всё зависит от того какие инструкции находятся рядом, какой размер соседних кэшей и что в них находится. Есть минимальное время прохождения команды через процессор, но эта величина практически постоянна. Хороший программист или оптимизирующий компилятор может заставить множество инструкций исполняться за среднее время близкое к нулю. Среднее время близкое к нулю – это не время исполнения самой медленной инструкции, а время, требуемое для прохождения инструкции через OOO ядро и время, требуемое кэшу для загрузки и выгрузки данных.
Что значит, когда новый процессор имеет 12, или 18, или даже 31-уровневый конвейер? Это значит, что больше инструкций за раз могут быть приглашены на вечеринку. Очень длинный конвейер может значить, что несколько сотен инструкций могут быть помечены как “обрабатываются” за раз. Когда все идет по плану, OOO ядро постоянно загружено и пропускная способность процессора просто впечатляет. К сожалению, это так же значит, что ступор конвейера перерастает из мелкой неприятности, как это было раньше, в кошмар, так как сотни команд будут вынуждены ожидать очистки конвейера.
Как вы можете применить эти знания в своих программах? Хорошие новости – процессор может предугадать большинство распространённых шаблонов кода, и компиляторы оптимизируют код для OOO ядра уже почти два десятилетия. Процессор лучше всего работает с упорядоченными инструкциями и данными. Всегда пишите простой код. Простой и не извилистый код поможет оптимизатору компилятора найти и ускорить результаты. Если возможно, не создавайте переходы по коду. Если вам необходимо совершать переходы, пытайтесь делать это, следуя определенному шаблону. Сложные дизайны, наподобие динамических таблиц переходов, выглядят классно и многое могут, но ни компилятор, ни процессор, не смогут спрогнозировать какой кусок кода будет выполняться в следующий момент времени. Поэтому сложный код с большой вероятностью будет провоцировать ступоры и неверные предсказания ветвления. Напротив, поддерживайте ваши данные простыми. Организуйте данные упорядоченно, связанно и последовательно для предотвращения ступоров. Правильный выбор структуры и разметки данных может заметно сказаться на повышении производительности. До тех пор, пока ваши данные и код остаются простыми, вы обычно можете положиться на работу оптимизирующего компилятора.
Спасибо, что были частью этого путешествия.
Оригинал — www.gamedev.net/page/resources/_/technical/general-programming/a-journey-through-the-cpu-pipeline-r3115