Один из этапов создания рекламной кампании — сбор семантического ядра. Оно включает в себя ключевые фразы пользователей, по которым будут показываться рекламные объявления. Релевантные ключевые слова и правильно написанный оффер — отличная возможность показать объявления целевой аудитории, привлечь клиентов и сэкономить бюджет. Как составить семантическое ядро, читайте в инструкции от eLama.
Этот текст был написан в 2019 году. В 2023-ем мы его обновили. Приятного чтения!
Семантическое ядро, или семантика — это список ключевых слов и фраз и минус-слов, соответствующих поисковым запросам целевых посетителей, которые используются в продвижении и рекламе. Семантическое ядро структурирует запросы и выделяет самые приоритетные. Это позволяет понять, как распределяется спрос, помогает создать наиболее релевантные рекламные объявления, выстроить структуру сайта, которая будет способствовать продвижению и т. д.
Кстати, важно различать ключевые фразы и поисковые запросы — несмотря на то, что часто они совпадают, это разные вещи. Ключевые фразы рекламодатель использует, чтобы таргетироваться на поисковые запросы — те фразы, которые пользователи вводят в поисковой системе Яндекс или Google. Запрос может содержать не только ключевую фразу, но и дополнительные слова. Кроме того, примерно 15% поисковых запросов поисковики видят впервые.
Какие бывают ключевые слова
Ключевые слова и фразы в семантике обычно сегментируют по нескольким параметрам.
- По количеству включающих их запросов в месяц:
- Высокочастотные (ВЧ) определяют тематику поиска. Пример: беспроводная зарядка.
- Среднечастотные (СЧ) намечают задачу поиска. Пример: купить беспроводную зарядку.
- Низкочастотные (НЧ) уточняют потребность. Пример: купить беспроводную зарядку Apple в СПб.
Конкретные цифры частотности зависят от тематики и определяются сравнительно. Например, у двух высокочастотных в своих тематиках фраз «беспроводная зарядка» и «кожаный диван» частотность составляет соответственно 318 898 и 40 151.
- По направленности:
- информационные — помогают пользователю найти информацию — смартфон Apple;
- коммерческие — содержат интент к покупке — купить смартфон Apple;
- гео-ориентированные — содержат указание города, района, страны, области и т.п. — смартфон Apple в Москве.
- По наличию упоминания бренда:
- витальные (или навигационные), то есть состоящие только из названия — eLama, елама;
- брендовые, название плюс запрос — маркировка рекламы eLama.
У них разные цели и принцип действия. Высокочастотники дают большой охват и подразумевают большую конкуренцию, низкочастотники более редки, но увеличивают вероятность контакта с целевым пользователем. Информационные чаще привлекают холодный трафик, коммерческие — теплый и даже горячий, гео-ориентированные повышают вероятность контакта. По витальным запросам легко занять первые строчки, а посетителей конвертировать в покупателей. В грамотно составленном семантическом ядре запросы разных характеристик учтены и сбалансированы.
После того как сбор семантического ядра сделан, фразы кластеризуют — объединяют похожие в группы по тому или иному принципу: например, в зависимости от типа товара (смартфоны, умные часы и т. д.), от модели, от содержания запроса (со словами цена / купить / заказ, как / почему и т. д.).
В рекламе это позволяет лучше структурировать кампанию, готовить релевантные объявления, распределять трафик на подходящие посадочные страницы — и в итоге повышать эффективность продвижения.
Такая разбивка важна для выстраивания структуры сайта, если семантическое ядро нужно в том числе для SEO-продвижения. Тогда тексты, оптимизированные по ключевикам с вхождениями словами цена / купить / заказ будут размещены на страницы каталога, а как / почему — в FAQ и т. д.
Бесплатные сервисы для сбора семантики
Вот несколько сервисов и инструментов, которые точно пригодятся вам, если нужно составить семантическое ядро. Мы начали с главных источников данных — статистических сервисов поисковых систем — и расположили их в порядке возрастания функциональности.
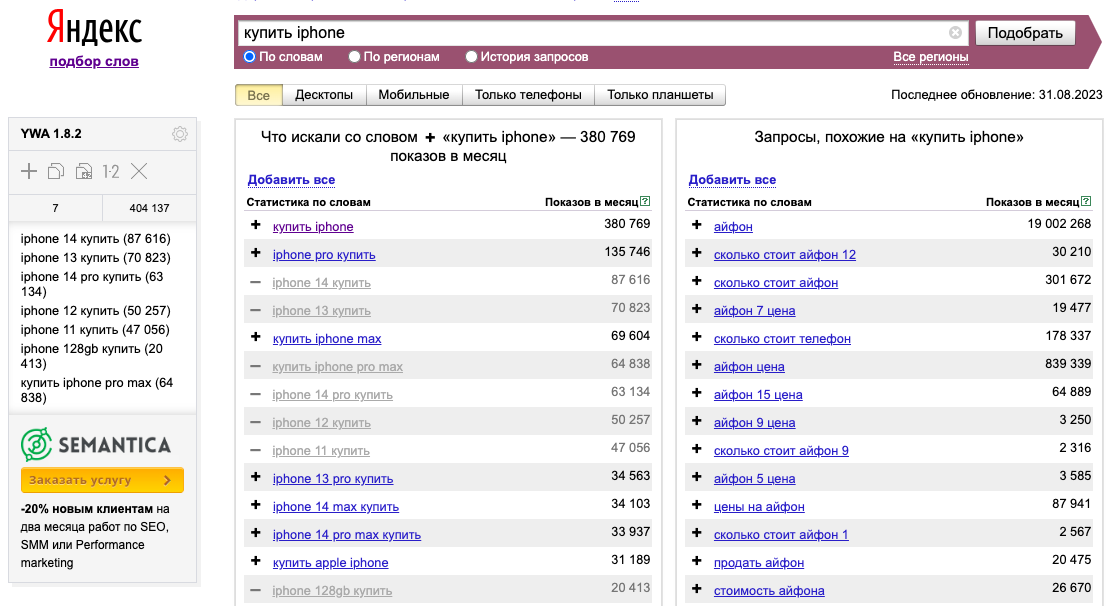
Яндекс Wordstat, подбор слов Яндекса — сервис, который позволяет оценить интерес пользователя к разным тематикам и конкретным фразам. Он показывает исторические данные по количеству запросов в поиске Яндекса — по словам и по регионам, а также по типу устройств. А еще выдает похожие запросы, которыми можно дополнить семантику.
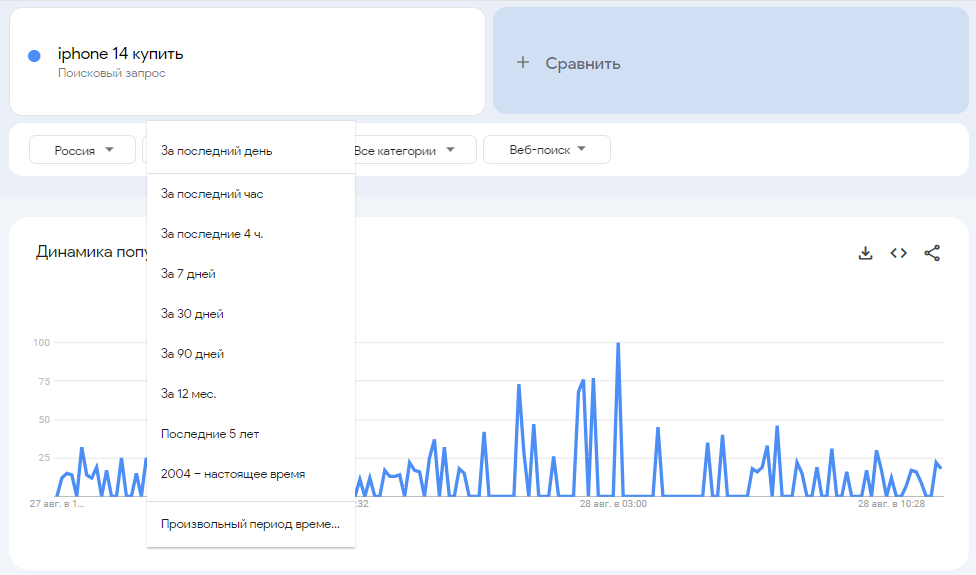
Подробнее: Как подбирать ключевые фразы с помощью Wordstat Яндекса — инструкция для начинающих Google Trends — сервис Google, который позволяет анализировать тренды и сезонность запросов, а также прогнозировать спрос. Алгоритм анализирует запросы в поиске Google, новостях и YouTube и выводит на главной странице темы, наиболее популярные в разных странах. Для интересующих вас запросов можно посмотреть динамику популярности за разные периоды и в разных регионах. Подробнее: Как подбирать ключевые фразы с помощью Wordstat Яндекса — инструкция для начинающих Google Trends — сервис Google, который позволяет анализировать тренды и сезонность запросов, а также прогнозировать спрос. Алгоритм анализирует запросы в поиске Google, новостях и YouTube и выводит на главной странице темы, наиболее популярные в разных странах. Для интересующих вас запросов можно посмотреть динамику популярности за разные периоды и в разных регионах.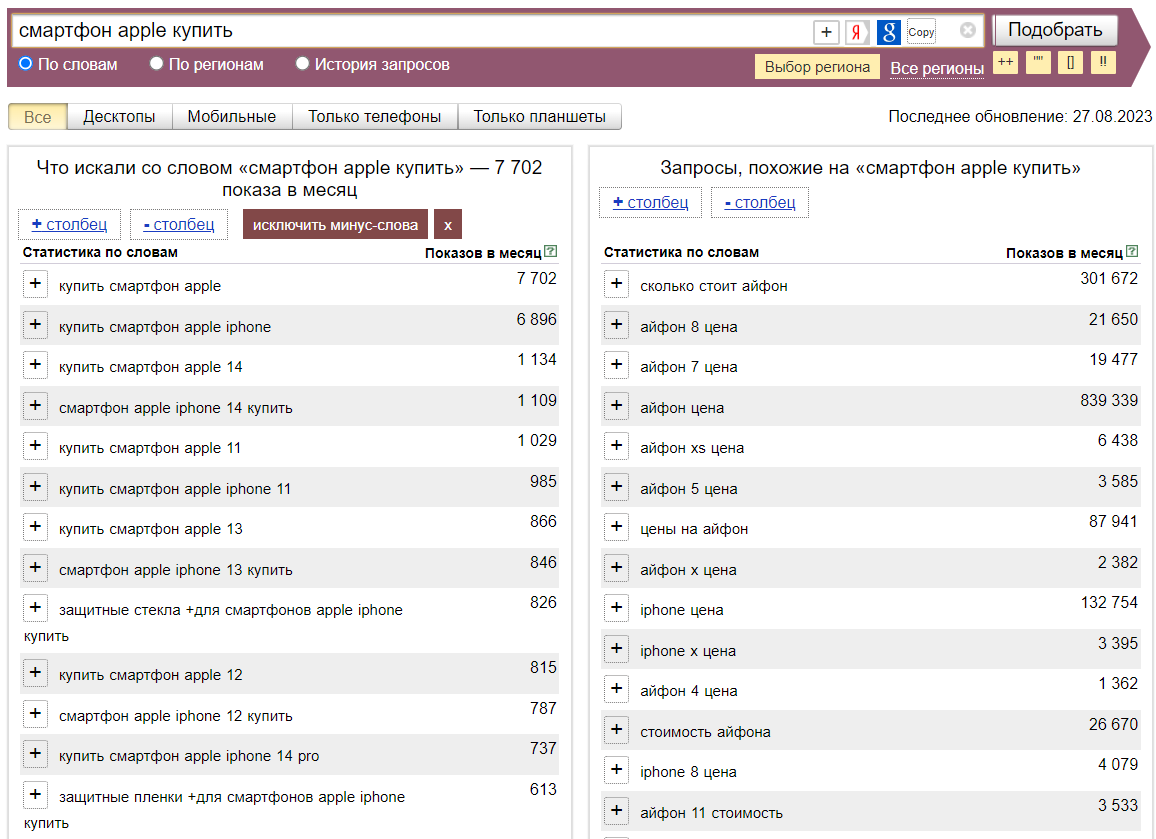
А также похожие запросы и связанные тренды.
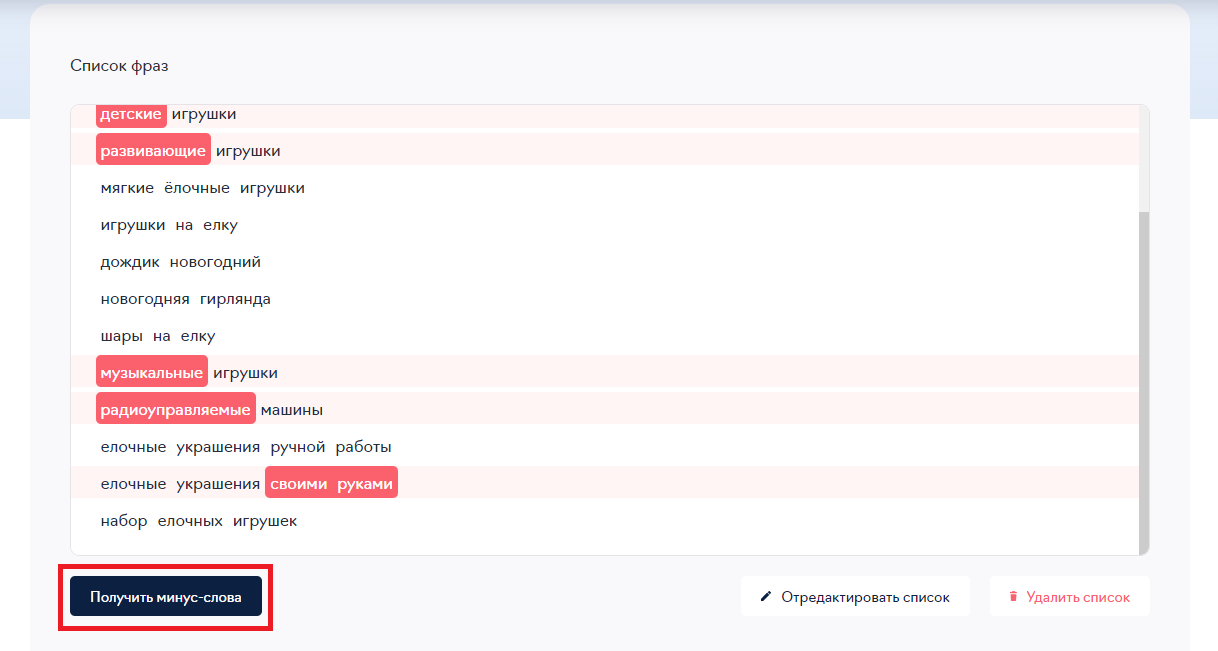
Минусатор — инструмент eLama для очистки семантики от ненужных фраз и составления списков минус-слов. Минусатор — инструмент eLama для очистки семантики от ненужных фраз и составления списков минус-слов.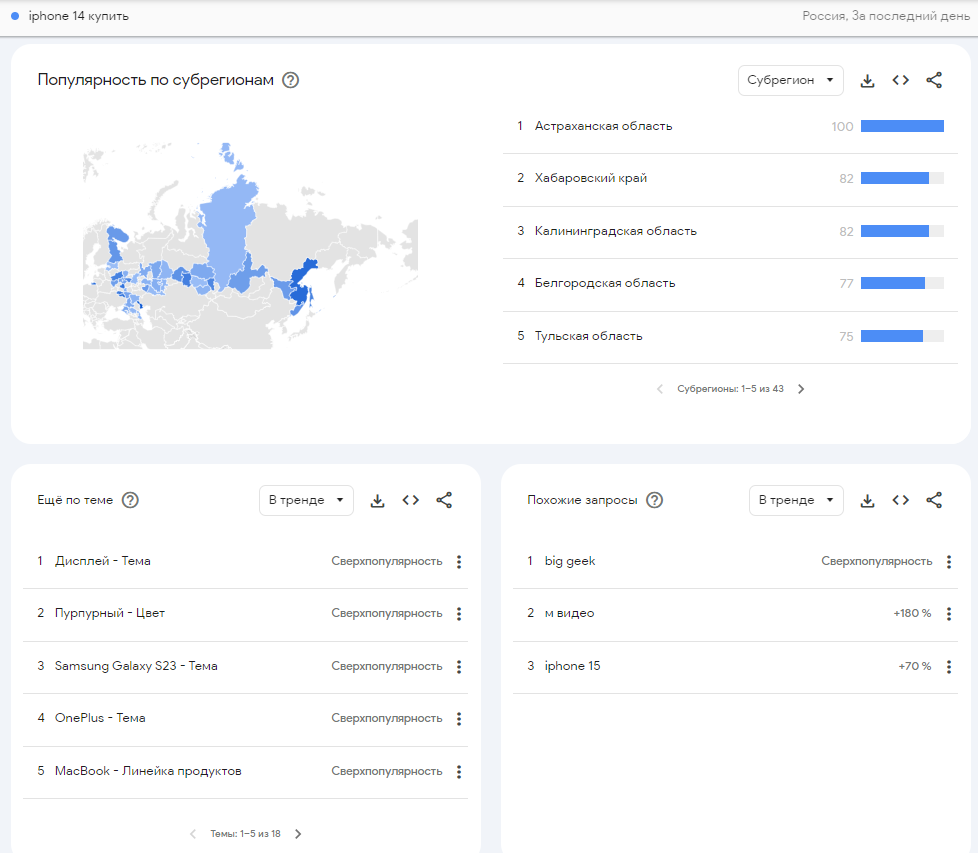
Вот текст о том, как с ним работать.
Комбинатор — еще один инструмент eLama, который в пару кликов создает готовые ключевые фразы для рекламной кампании на основе ваших списков. К каждому списку и к готовым комбинациям можно добавить операторы соответствия, а то, что получится, скопировать или скачать.
Yandex Wordstat Assistant — расширение для браузера, которое упрощает и ускоряет сбор фраз в Wordstat. Вы добавляете нужные фразы в список кликом по иконке «+» или вручную. Список без дублей с указанной частотностью синхронизируется между вкладками и сохраняется при закрытии браузера. Когда работа закончена, список можно скопировать. Сортировать фразы можно по частотности, по очередности добавления или алфавиту. Yandex Wordstat Assistant — расширение для браузера, которое упрощает и ускоряет сбор фраз в Wordstat. Вы добавляете нужные фразы в список кликом по иконке «+» или вручную. Список без дублей с указанной частотностью синхронизируется между вкладками и сохраняется при закрытии браузера. Когда работа закончена, список можно скопировать. Сортировать фразы можно по частотности, по очередности добавления или алфавиту.
WordStater — плагин для сбора ключевых и минус-слов в Wordstat, ориентированный на подбор фраз для рекламных кампаний в Яндекс Директе. Позволяет формировать и выгружать списки с частотностью, с операторами и без, комбинировать запросы и минусовать ненужные, а также генерировать UTM-метки, прогнозировать стоимость клика и бюджет кампании, оптимизировать уже запущенные кампании.
SpyWords — сервис конкурентной разведки. Позволяет анализировать рекламные объявления, которые показываются по тому или иному запросу, ключевые слова, которые приносят вашим конкурентам больше всего трафика, оптимизацию их посадочных страниц и сайтов. С его помощью можно быстро собрать семантическое ядро с опорой на стратегии конкурентов — то есть максимально полное и целесообразное. SpyWords — сервис конкурентной разведки. Позволяет анализировать рекламные объявления, которые показываются по тому или иному запросу, ключевые слова, которые приносят вашим конкурентам больше всего трафика, оптимизацию их посадочных страниц и сайтов. С его помощью можно быстро собрать семантическое ядро с опорой на стратегии конкурентов — то есть максимально полное и целесообразное.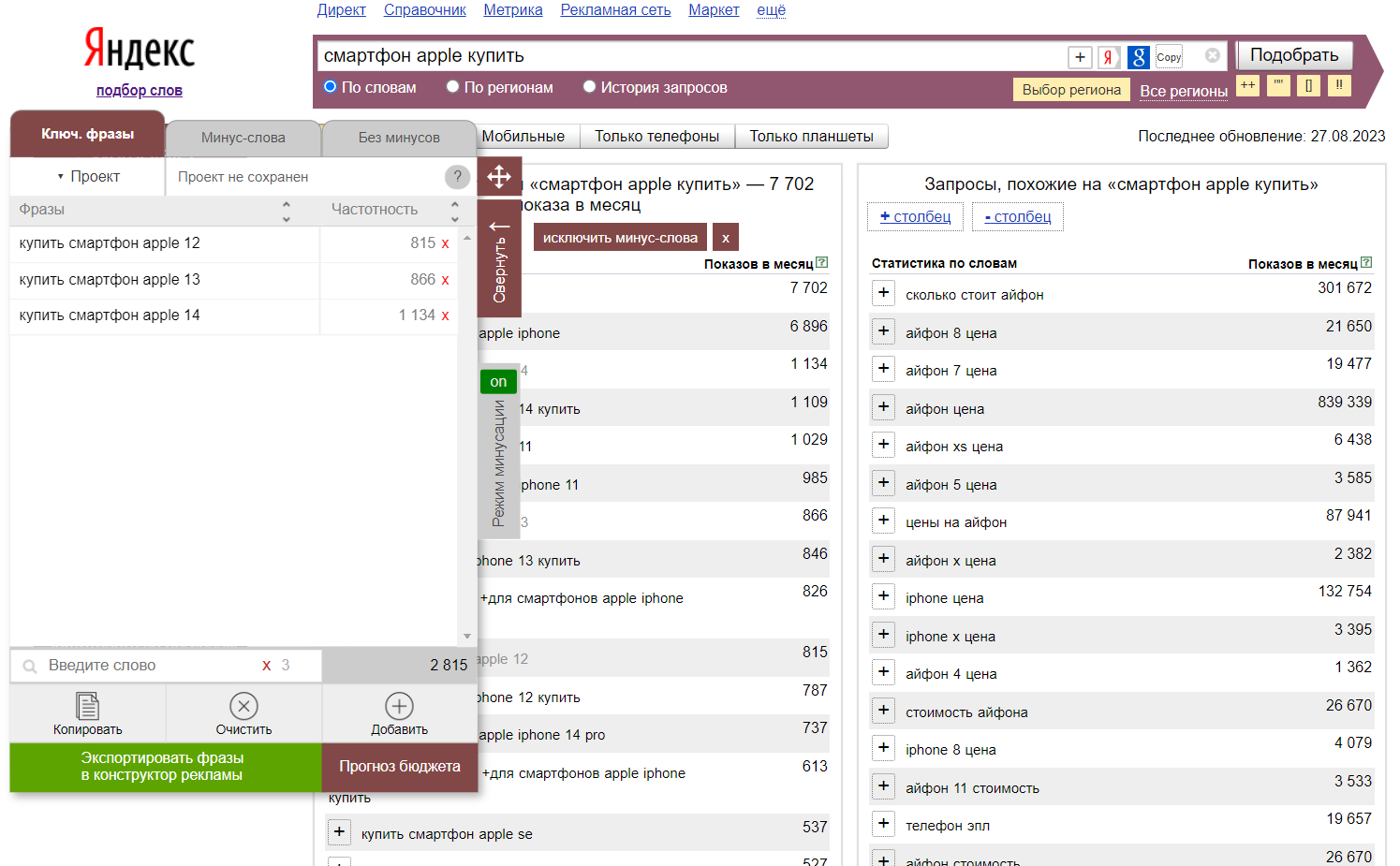
SpyWords — это платный сервис, но клиенты eLama могут пользоваться им совершенно бесплатно, потому что он есть на нашем маркетплейсе. Экономия за год при этом может составить около 70 000 руб. Подробности →
О том, как подсматривать за конкурентами с помощью SpyWords и использовать эти знания в сборе семантического ядра, у нас есть отдельный материал. А здесь мы пройдемся по базе и покажем, как собрать ключевики вручную — чтобы вы лучше понимали процесс.
Семантическое ядро для поисковых кампаний
Этап 1. Сбор базовых ключевых слов
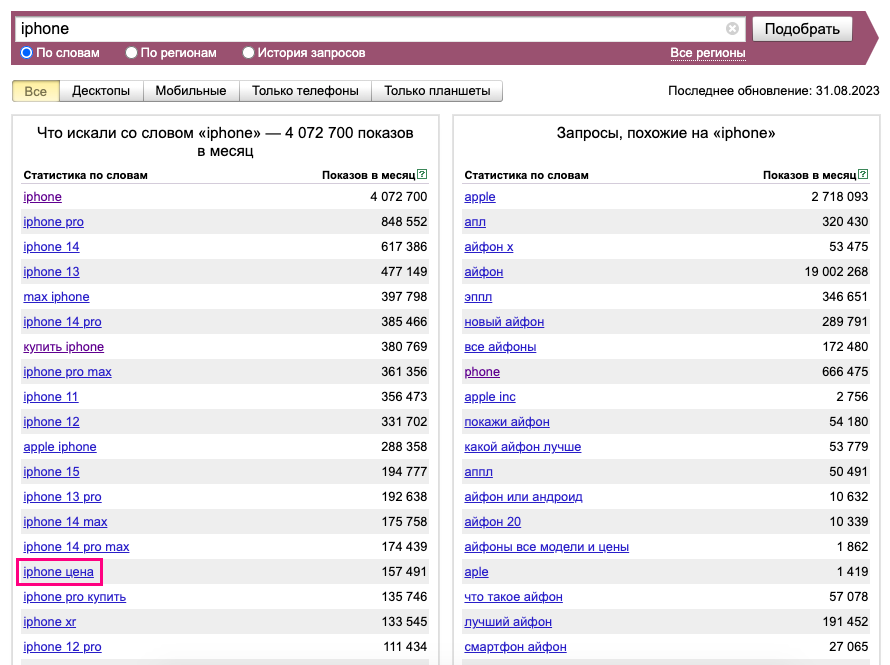
Прежде всего подумайте, какие слова характеризуют вашу нишу. Например, для интернет-магазина по продаже iPhone будут очевидны следующие слова: iPhone, айфон, купить, заказать и т. д. Для удобства записывайте слова в таблицу Excel.
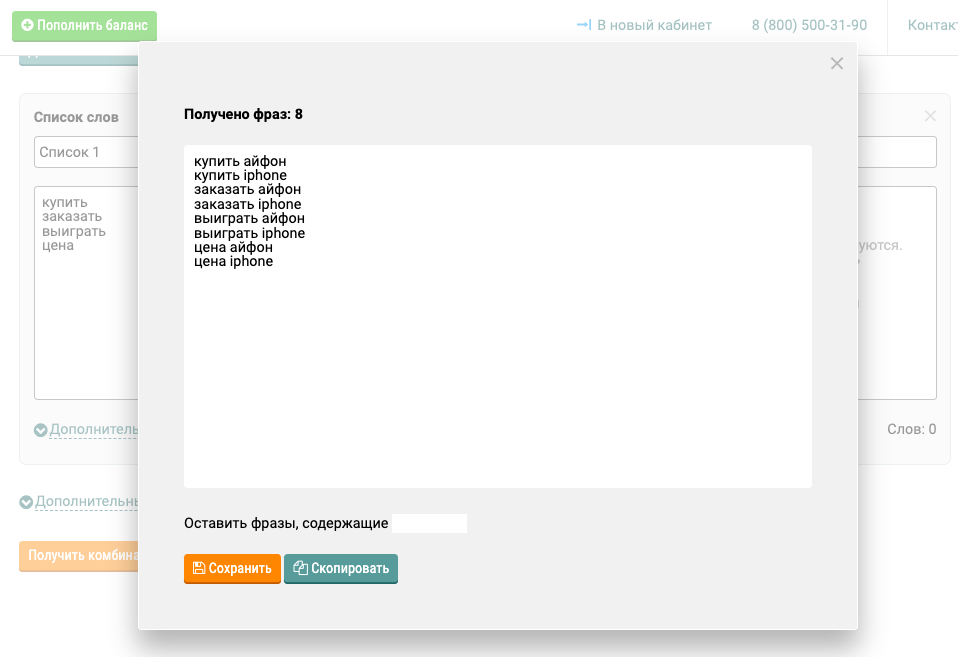
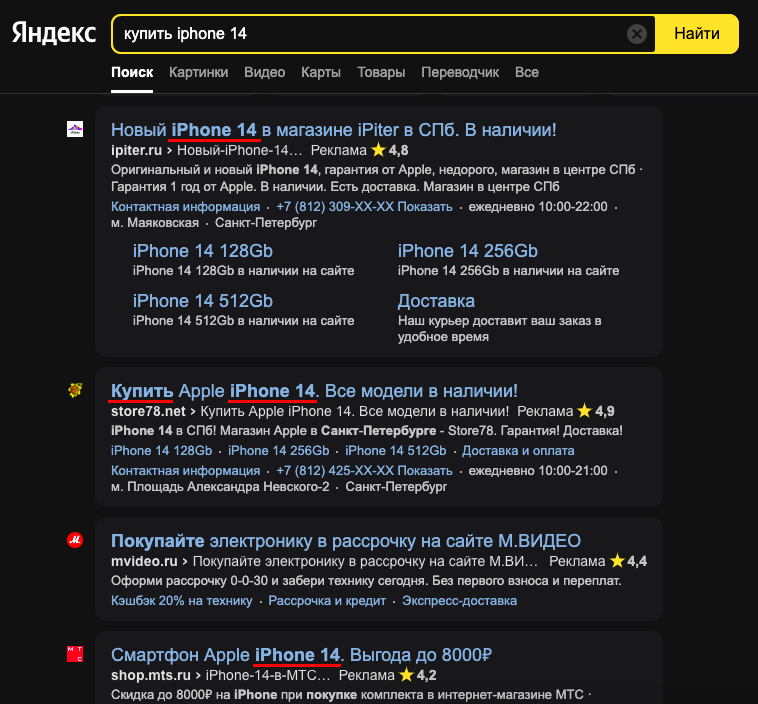
Если у вас закончились идеи, зайдите в Wordstat и посмотрите, что ищут при вводе, например, iPhone. К собранному в Excel списку добавим слово «Цена». Далее найденные слова нужно скомпоновать. Это можно сделать через инструмент Комбинатор от eLama: Полученные фразы мы будем использовать на следующем этапе. Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра. Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее. Выберите все слова в выдаче и перенесите их в Google Таблицу или Excel: Получился список и одна свободная колонка, которая нужна для списка минус-слов. Теперь весь список ключевых слов нужно очистить от нерелевантных запросов, чтобы показывать рекламу только тем пользователям, которые ищут наши товары. Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы. Проще и удобнее это сделать в минусаторе eLama. Скопируйте собранную список семантики и вручную выделите все ненужные слова. В итоге у вас получится два списка: ключей и минус-слов. А еще в минусаторе можно применить готовый список минус-слов к списку ключевых фраз — инструмент найдет нерелевантные фразы и удалит их. Можно продолжить работу в таблице, но так будет посложнее. Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel. Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов». По сравнению с Wordstat он имеет больше функций, благодаря которым можно: Для получения более точного результата попробуйте комбинировать все инструменты. Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость. Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление. Полный список операторов Яндекс Директа есть на странице помощи, а для типов соответствия Google Ads — здесь. Для экономии времени используйте используйте инструмент Комбинатор ключевых фраз, который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор: Если нужны типы соответствия/операторы, которых нет в комбинаторе, используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом. Для рекламы в РСЯ и КМС в семантическое ядро достаточно включить широкие, высокочастотные ключевые фразы, связанные между собой. Уточнять их операторами не нужно. Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ. Сбор семантики — интересный, но сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.

Этап 2. Подбор семантического ядра


Этап 3. Чистка семантического ядра



Этап 4. Заключительный
Операторы и типы соответствия ключевых слов в Яндекс Директе и Google Ads

Подбор ключевых слов для КМС и РСЯ
Заключение
Семантическое ядро – фундамент последующего продвижения сайта. Данная статья будет полезна как новичкам, так и практикующим специалистам, а также клиентам, стремящимся получше разобраться в вопросах поискового продвижения. Сложно и муторно в этой статье точно не будет – обещаем 
Собрали целый массив структурированной информации: что такое семантика, как выглядит семантическое ядро; как собрать ядро для интернет-магазина или маркетплейса; способы кластеризации, а также анализ СЯ конкурента, и все способы сбора ключей.
Кстати, хорошие примеры семантического ядра есть у Rush Analytics.
Содержание:
Что такое семантика и как выглядит семантическое ядро
Для совсем новичков приведем цитату из Википедии: семантическое ядро представляет собой упорядоченный набор слов, их морфологических форм и словосочетаний, характеризующих вид деятельности, товары и услуги, предлагаемые сайтом.
Страшно, сложно и непонятно.
Конкретизируем: семантическое ядро – структурированное описание сайта, учитывающее пользовательский спрос, интересы аудитории, специфику бизнеса и цели проекта. Таким образом, СЯ – это не просто список слов и словосочетаний.
К.О.
Стоит учитывать, что в ядро попадают запросы, вводимые пользователями в поисковую систему. Эти запросы называют ключевыми словами, иначе – ключами, благодаря которым вы можете узнать, что, как и для чего ищет ваша аудитория.
- Что ищут – какая информация, услуга, товар интересны пользователям.
- Как ищут – какими фразами они пользуются для поиска.
- Зачем ищут – цели получения информации. Например, сравнить цены, выбрать, купить и т.д.
Представим, что вы планируете открыть сервисный центр по ремонту телефонов и выйти в онлайн. Вам необходимо определиться, как составить семантическое ядро, какие услуги более всего интересуют ваших потенциальных клиентов.
Вордстат отражает, что вводят в поисковик люди, которым необходимо отремонтировать телефон.
А если кликнуть на запрос, то перейдем на следующий «уровень» с уточненными ключевыми словами.
«Починить телефон», «отремонтировать телефон» говорят нам о целях поиска. Сопутствующие основной фразе «самсунг», «iphone» и прочие отвечают на вопрос о том, что именно хотят починить пользователи.
Задачи семантического ядра не ограничиваются на описании тематики сайта:
- СЯ определяет структуру сайта – страницы, разделы, иерархичность. Это облегчает навигацию как для аудитории, так и для ПС.
- Благодаря семантическому ядру оптимизируем страницы под конкретные запросы — прописываем мета-теги, создаем релевантный контент.
- Создаем матрицу контента. Семантическое ядро дает нам основу для создания контент-плана — релевантные статьи (в том числе описания ассортимента), инфоблог и прочее.
- Оптимизированное ядро несложно использовать и для настройки контекстной рекламы.
- Благодаря СЯ мы грамотно линкуем страницы, чтобы корректно распределить ссылочный вес, а также для пользователей облегчить поиск необходимой информации.
- Актуализация ядра = достоверный анализ покупательского спроса. Отслеживая, чем интересуются пользователи, можно включать новые услуги, расширять ассортимент и прочее.
Таким образом, семантическое ядро – основа успешного продвижения ресурса в поисковых системах. Его составлением стоит заняться до создания сайта. Формирование семантического ядра до того, как создан ресурс, – это семантическое проектирование.
Для начала определяют тематику сайта, ключи должны наиболее полно описывать содержание. Далее запросы кластеризуют по разделам сайта. После – собранную семантику используют для постраничной оптимизации страниц.
Как собрать семантическое ядро для интернет-магазина
Как пользователи ищут товары и услуги в интернете?
- Если речь о технике, косметике, мебели, ищут по наименованию, а порой даже по артикулу.
- Если конкретики нет, то ищут по товарной категории.
- Часто вводят запросы, начинающиеся с «как…», «почему…», и в итоге находят, что им нужно купить, например, для удовлетворения той или иной потребности.
Чтобы собрать семантическое ядро для интернет-магазина, можно воспользоваться wordstat.yandex.ru, KeyCollector. Есть свои плюсы и минусы.
1. Wordstat бесплатен, предоставляет прекрасную возможность сориентироваться, насколько востребован конкретный запрос. Учитывается время, регион, порядок слов, статистика за месяц. Такой вариант подойдет для ручного сбора небольших семантических ядер. Не забудьте установить Yandex Wordstat Assistant, благодаря которому вы сможете сохранять и фразы, и их частотность в таблицах.
2. Парсер, например, Key Collector. Парсер это программа, сервис или скрипт, который собирает данные, анализирует и выдает в нужном формате. Чтобы было еще понятнее, условно определим парсер как сортировщик. Среди платных профессиональных программ можно выделить KeyCollector. Разумеется, требует времени на освоение, и прекрасно подходит для работы с большими семантическими ядрами.
С чего начать?
В первую очередь обозначим, что СЯ для страниц каталога и страниц товаров будут разными, раз мы говорим именно об интернет-магазине.
Рекомендуем начать с работы над страницами каталога, точнее, с его структуры. Почему это важно?
Продуманный каталог поможет не только собрать семантическое ядро, но и улучшать поведенческие факторы. Если структура удобна для пользователя, то и поисковая система «поднимет выше» сайт в выдаче.
Используем готовый шаблон
Чтобы подготовить каталог, воспользуйтесь готовым шаблоном –их можно найти в интернете. На скриншоте один из вариантов:
Таблица для подготовки семантического ядра интернет-магазина
Разумеется, это лишь пример, и ваша таблица может получить гораздо сложнее. Главное – вы поняли принцип.
Заполнение шаблона
Ядро составляем на основе ассортимента интернет-магазина, но в первую очередь следует заняться категориями и подкатегориями. Непосредственно к карточкам товаров можно обратиться позже.
Как создать каталог?
- оценить, каким бы вы хотели видеть перечень, и составить его в соответствии с собственными предпочтениями и видением;
- опереться на прайсы поставщиков;
- позаимствовать у конкурентов из топа.
Так, например, будет выглядеть каталог для магазина растений и семян:
База запросов
Помимо этого, вы можете воспользоваться любой крупной базой ключевых слов. Например, у Keys.so база состоит более 120 млн слов из русскоязычного сегмента интернета и практически отсутствуют нулевые ключевые запросы. Вводите ключевое слово и выбираете регион:
Таким же образом вы можете взять сайт конкурента и проанализировать его, какие запросы он использует и какая видимость в поисковой выдаче:
Подбираем запросы
Категория должна быть релевантна своему запросу – это и есть основа оптимизации, благодаря которой мы привлекаем заинтересованных клиентов.
Как определить релевантность? Обратите внимание на частоту поиска фразы, которую вы проверяете в сервисе или программе. Если необходимо, ограничивайте по регионам.
Далее следует оптимизация страниц категорий и подкатегорий, начинающаяся с проработки Title, Description, H1, но это уже тема другой статьи.
Несколько советов касаемо сбора семантики :
- Сбор СЯ начинается с категорий и подкатегорий, если речь об интернет-магазине. Непосредственно к карточкам переходите после.
- При подборе проверяйте название и на русском, и на английском. Например, «Indesit» и «Индезит».
- Учитывайте, что поставщики формируют прайс так, как им удобно. Чтобы не ошибиться, формируйте категории все же на базе семантического ядра.
- Сбор начинайте с парсеров (в идеальном случае).
На этом пока завершим первую часть нашей статьи про семантическое ядро. В следующей части рассмотрим СЯ для сайта услуг; кластеризацию и детализацию запросов и как проанализировать семантическое ядро конкурентов.
Содержание
Какими бывают поисковые запросы?
Сервисы для сбора и кластеризации
Семантическое ядро — просто список запросов, по которым продвигается сайт. Файл с длинной таблице из сотен или тысяч строк. Каждая строка — слово или словосочетание, например: [купить плед], [купить шерстяной плед], [плед сова купить]. Это ключевые слова, которые пользователи вводят в поисковик, например, Яндекс или Google.
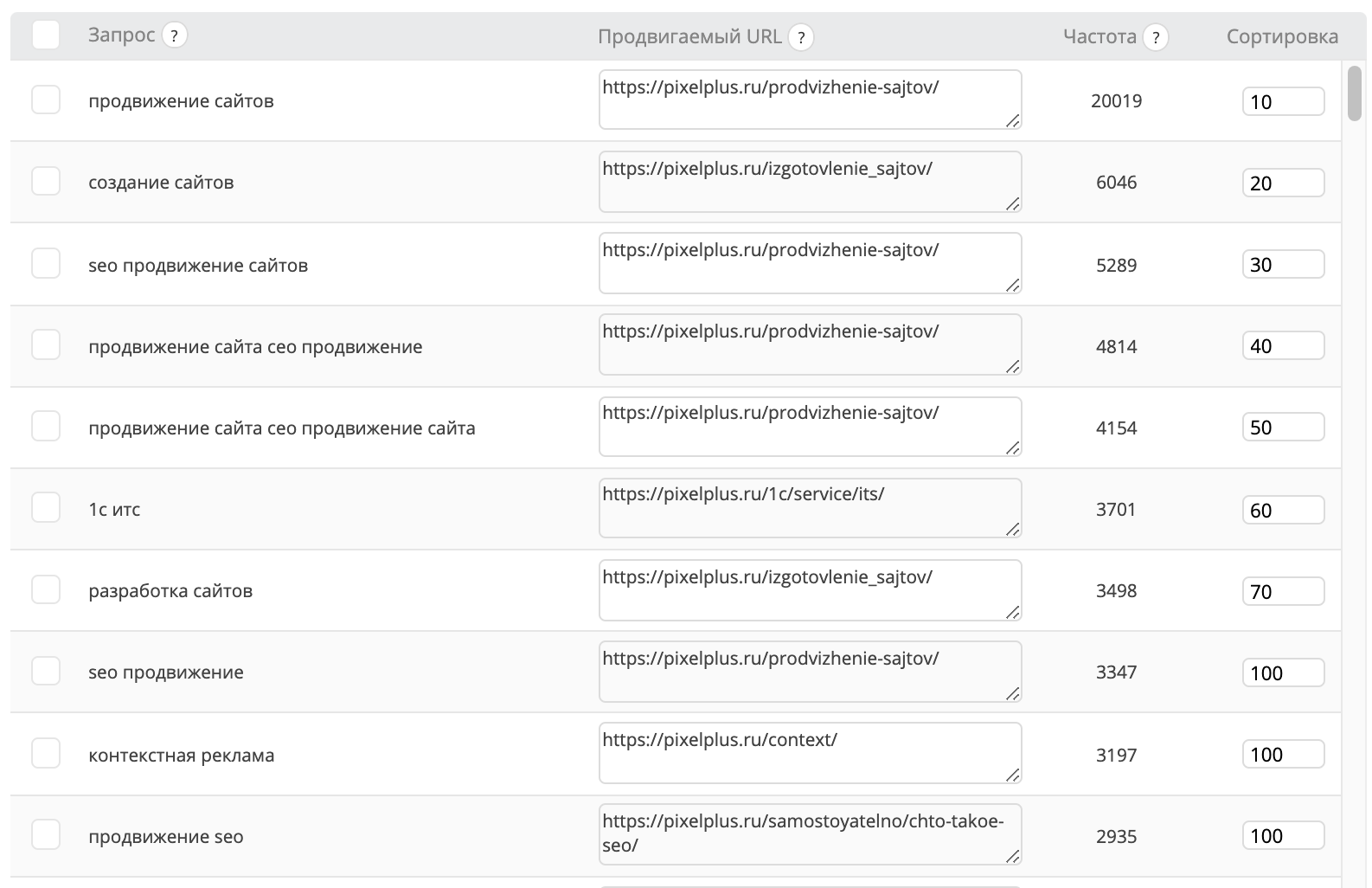
В готовом ядре такие фразы разделены на группы. В случае с пледами в одну группу попадут слова с одинаковым интентом (потребностью): [сова с пледом купить], [плед сова], [сова с пледом внутри], [мягкая сова с пледом].
В ядре указана частотность каждого ключевого слова (количество запросов в месяц) и прочие параметры запросов.
Для SEO-специалиста ядро — основа будущей структуры сайта, его фундамент. Под ключи предстоит «заточить» отдельные страницы, разделы и весь сайт.
Для бизнесмена и маркетолога ядро — это набор подсказок. СЯ поможет оценить спрос и увидеть недостающие позиции в ассортименте. Например, в случае с пледами ядро подсказывает, что спрос на шерстяные пледы выше, чем из хлопка.
Согласно определению:
Семанти́ческое ядро — совокупность целевых поисковых запросов, по которым продвигается или планируется к продвижению проект.
Можно добавить, что ядро описывает интересы аудитории сайта, специфику спроса и бизнеса.
Зачем его собирать?
Ключи показывают, что ищет аудитория и какими фразами формулирует свой запрос.
Если вы думаете, что знаете все о потребностях своих клиентов, то при составлении семантического ядра поймаете инсайт. Представление бизнесмена или маркетолога о том, что ищут люди в интернете, и реальные запросы пользователей чаще всего не совпадают.
Предположим, вы открываете магазин цветов в Москве. Можно предположить, что один из популярных фраз — это [купить чайные розы].
На самом деле, это не популярный запрос.
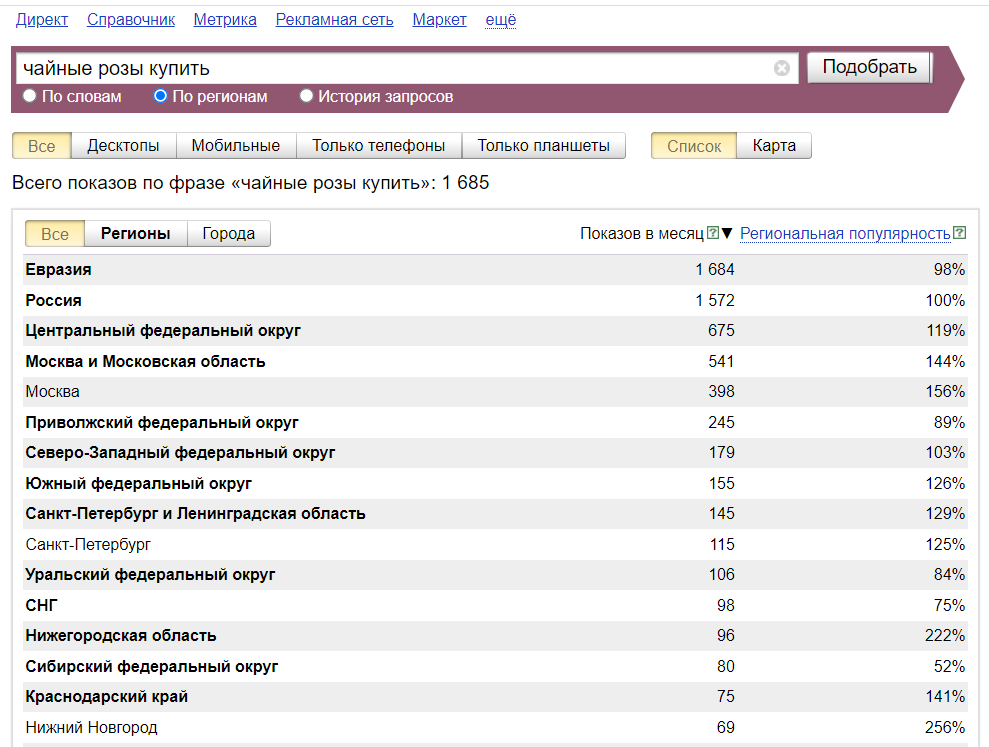
При этом в тематике есть ключевые слова с неожиданно высокой частотностью по Wordstat.
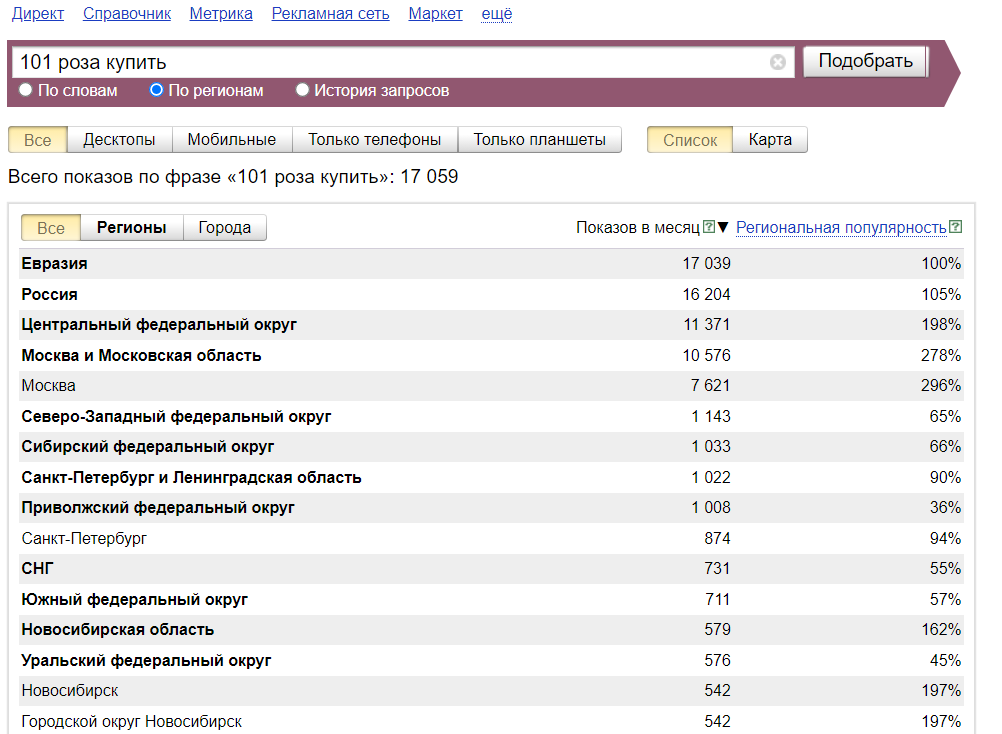
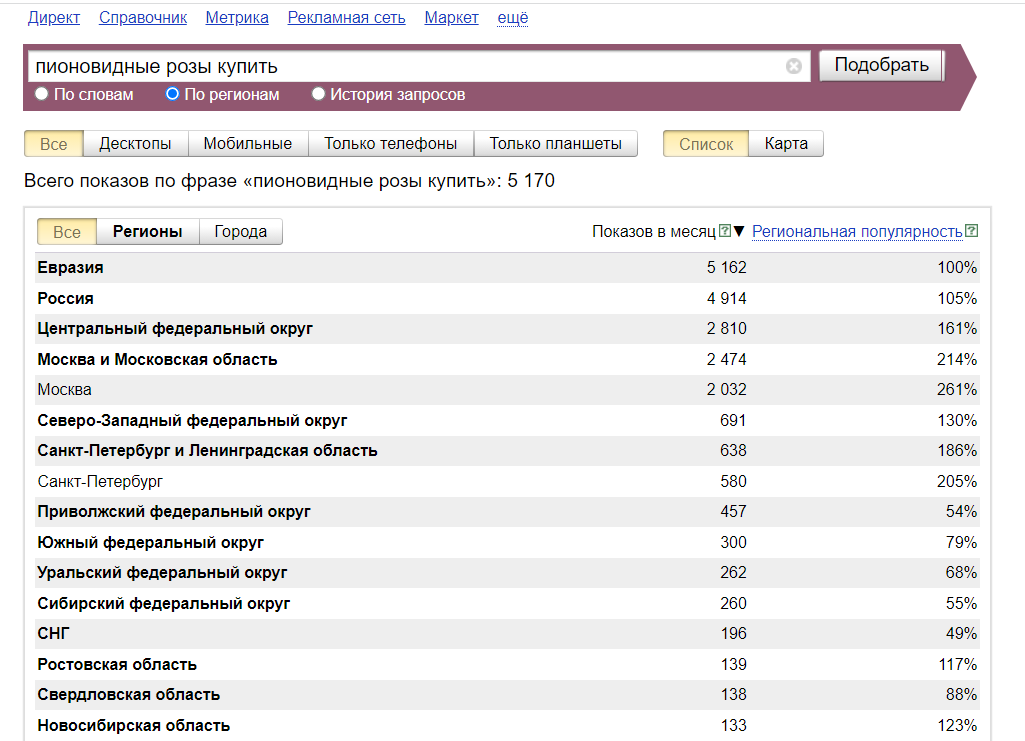
Этот пример показывает, что важно сверяться с реальными запросами потенциальных покупателей и клиентов. Ядро помогает маркетологам анализировать покупательский спрос.
Но оно не только описывает потребности аудитории, а еще и выполняет SEO-задачи:
-
Семантическое ядро сайта ложится в основу структуры. Разделы, подразделы и страницы создаются под группы ключевых фраз. Именно в такой последовательности: сначала ядро, потом — на его основе — структура. Существует альтернативный принцип — подбор ключей под готовые разделы и страницы. Оба подхода считаются рабочими, хотя и вызывают много споров в среде сеошников.
-
Группы ключевых слов — основа контента. На них можно опираться, создавая контент-план, планируя разработку онлайн-сервисов.
-
Ключевые фразы распределятся по страницам. Они нужны для оптимизации текстов, заголовков и мета-тегов.
-
При перелинковке эти слова используются как анкоры.
-
В контекстных объявлениях точно сформулированные фразы помогают «попасть» в интересы аудитории, повысить кликабельность и конверсию.
Какими бывают поисковые запросы?
Классификация ключевых слов основана на нескольких признаках.
По частотности ключи делят на:
-
ВЧ — высокочастотные (больше 1000 запросов в месяц);
-
СЧ — среднечастотные (100-1000);
-
НЧ — низкочастотные (меньше 100).
Распределение поисковых запросов по частоте употребления в Яндексе: 92% из них — встречаются менее 10 раз в день.
Доля уникальных (неповторяющихся) запросов в течение дня — от 40% до 60% в зависимости от региона.
Это условные и очень приблизительные цифры. В каждой нише свои диапазоны НЧ, СЧ и ВЧ. В некоторых узконишевых тематиках даже запрос с частотой «100» можно отнести к высокочастотным.
По типу интента ключевые слова делят на:
-
Информационные. Пользователь ищет какие-то сведения. Примеры: «как постирать плед», «как выбрать свадебный букет».
-
Коммерческие (транзакционные). Пользователь ищет товар или услугу. Он уже готов сделать заказ или купить товар. Примеры: «купить шерстяной плед», «заказать букет на свадьбу», «интернет-магазин кондиционеров Москва», «цены на клининг квартир».
-
Навигационные. Пользователи хотят найти конкретный сайт, компанию. Примеры: «Связной», «Госуслуги», «официальный сайт Кремля».
-
Общие (нечеткие). Пользователь не уточняет свое намерение. Примеры: «планировка кухни», «двери» (непонятно, пользователь хочет разобраться в видах дверей или готов сделать заказ).
Некоторые специалисты выделяют в отдельный класс витальные (брендовые) запросы. Они содержат только название бренда. Примеры: «Мерседес», «Apple», «Шанель».
По географической привязке ключевые фразы делят на:
-
Геозависимые. Поисковые системы привязывают их конкретному региону или городу. В каждом городе по этому запросу формируется своя выдача. Примеры: «доставка продуктов», «расписание кинотеатров».
-
Геонезависимые. Примеры: «как приготовить пиццу», «о чем фильм Остров проклятых». Такие фразы как «снять квартиру в Москве», «лучшие рестораны Санкт-Петербурга» тоже геонезависимые, поскольку выдача по ним одинаковая во всех регионах.
Разобраться в типах ключей нужно, чтобы правильно разгруппировать ядро. Например, при кластеризации нельзя объединять в одну группу информационные и транзакционные фразы. Они должны попасть в разные кластеры и продвигаться на отдельных страницах.
Источники ключей
Ключи хранятся в базах поисковых систем и в сервисах анализа сайтов-конкурентов. Задача семантика — извлечь и систематизировать. Основные источники ключевых слов:
Яндекс.Wordstat. Бесплатный сервис поисковой системы Яндекс. Показывает ключевые фразы, актуальную статистику, распределение частотности по регионам, историю.
Google Keyword Planner. Сервис создан для работы с рекламными объявлениями Google. Чтобы «подсмотреть» ключи, нужно создать рекламную кампанию.
Для сайтов с поисковым трафиком можно использовать системы аналитики Яндекс.Метрика, Яндекс.Вебмастер, Google Analytics. Здесь можно проверить, по каким ключевым словам пользователи заходят на ваш сайт.
Вебмастер Яндекса также формирует пул рекомендованных запросов.
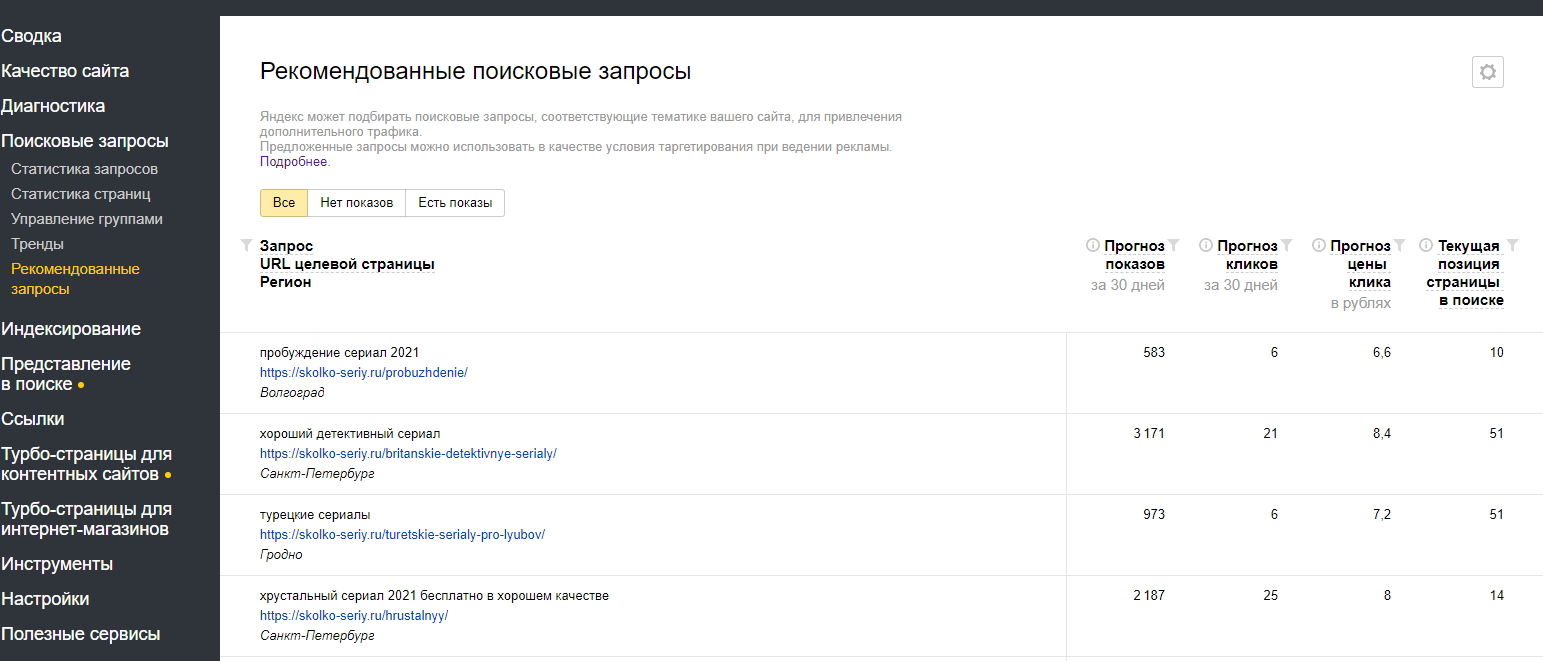
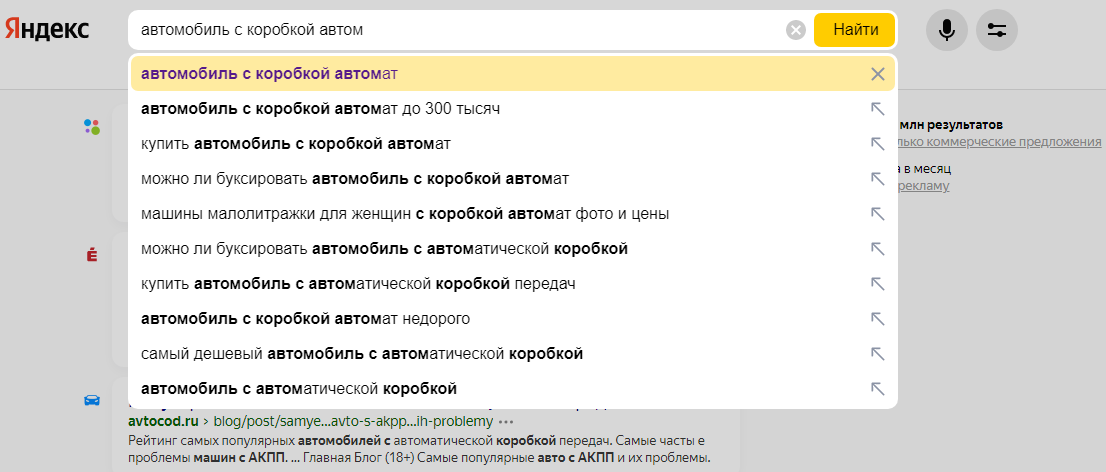
Поисковые подсказки. Когда пользователь набирает фразу в поисковой строке, Яндекс или Google предлагают свои варианты концовки. Эти подсказки — тоже ключевые слова.
Другие источники ключей: базы ключей, сайты конкурентов. Фразы из этих источников не получится скачать напрямую, но их можно спарсить с помощью специальных сервисов.
Сервисы для сбора и кластеризации
Существует много онлайн-сервисов и десктопных программ для сбора и группировки семантики.
-
Key Collector
Основной инструмент при сборе ядра. Платная программа с бессрочной лицензией. Устанавливается на компьютер или ноутбук. Возможности Key Collector:
-
парсит (собирает) ключи из Wordstat, Google.Ads, Liveinternet.ru, «ВКонтакте» и других платформ.
-
собирает поисковые подсказки.
-
определяет актуальную частотность.
-
фильтрует ключи по стоп-словам и частотности.
-
находит релевантные страницы.
-
проводит группировку (кластеризацию) запросов.
-
-
Онлайн-инструменты Пиксель Тулс
Здесь есть сразу несколько инструментов для работы с семантикой.
В модуле «Проекты» сервис автоматически генерирует базовый набор ключей для сайта. Его можно дополнять, загружая слова из других источников.
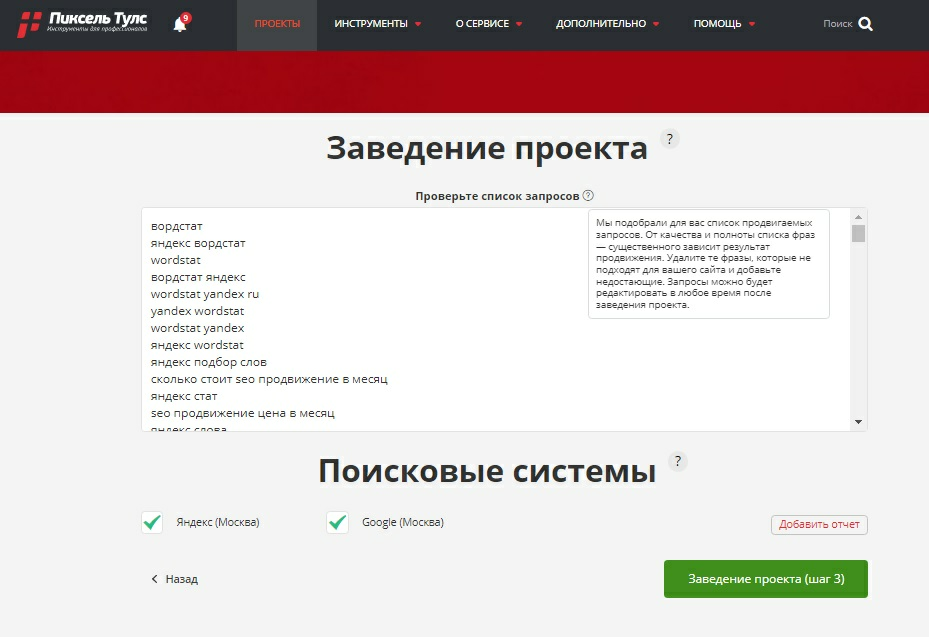
Другие полезные инструменты для работы с ядром от Пиксель Тулс:
-
Определение геозависимости, локализации и коммерциализации запроса.
-
Комплексная оценка запросов. Сервис определяет интент, то есть желание/намерение пользователя.
-
Парсинг поисковых подсказок в выдаче Яндекса.
-
Парсинг поисковых подсказок в выдаче Google.
-
Парсинг подсказок Avito.
-
Группировка запросов по ТОПу. Инструмент определяет позиции сайта, частотность, анализирует ТОП и распределяет запросы, определяя релевантные URL.
-
Детальный анализ запроса. Оценивает важные параметры фразы: геозависимость, слова из подсветки, частотность, число главных страниц в ТОП, средний возраст документов и другие.
-
Вместе с запросом ищут… Инструмент находит похожие ключи.
-
Получение семантики по домену. Сервис парсит фразы сайтов-конкурентов.
-
Получение данных из Яндекс.Вордстат. Инструмент собирает ключевые слова, их историю, анализирует частотность.
-
Список запросов из Яндекс.Вебмастера. Выгружает ТОП-500 запросов по данным сервиса Вебмастер.
-
Лемматизация и удаление дублей фраз. Удаляет условно одинаковые ключи с учётом лемматизации (то есть приводит слова к лемме — нормальной, словарной форме слова).
-
-
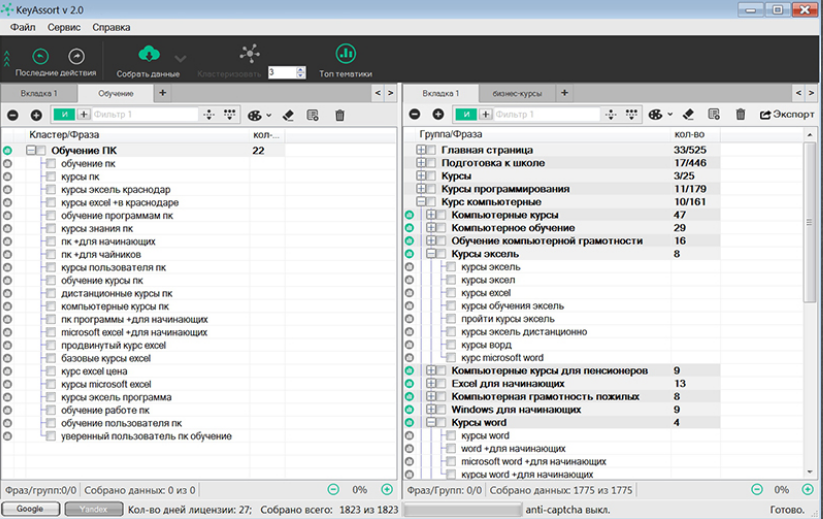
Key Assort
Еще одна платная десктопная программа. Автоматически кластеризует ядро (делит на группы), создает структуру проекта на основе семантики, находит лидеров ниши. Программа не парсит ключи, а работает с уже собранными запросами.
-
Keys.so
Платный онлайн сервис с широким функционалом:
-
Анализирует сайты конкурентов: трафик, позиции, поисковые запросы.
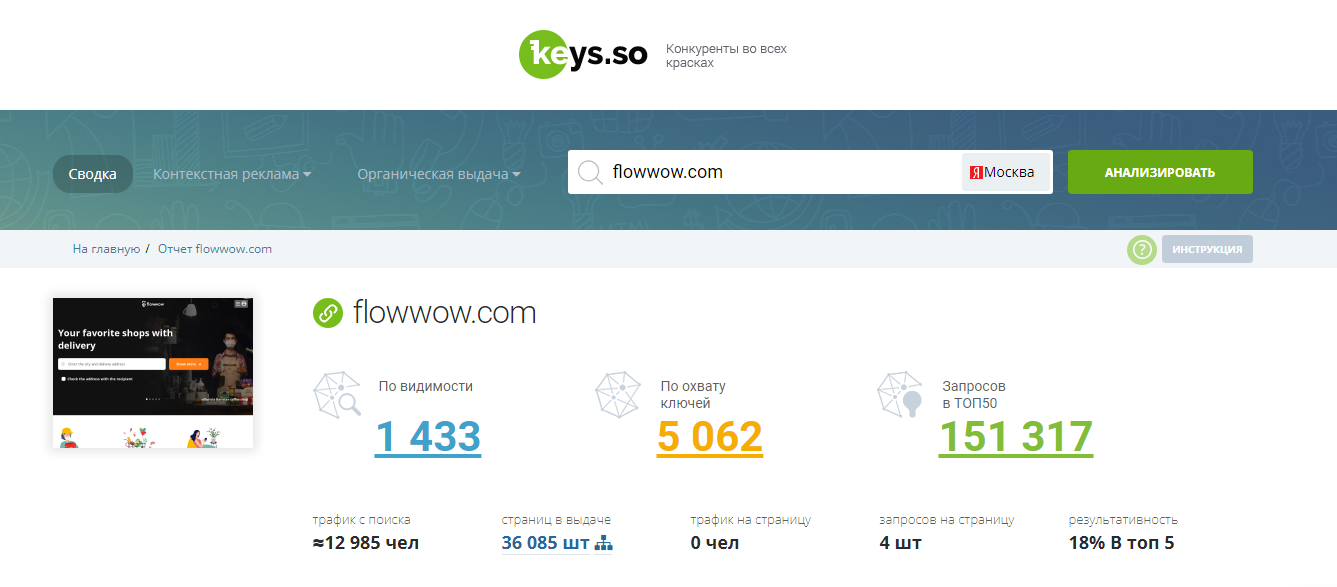
-
Сравнивает конкурентов по позициям, видимости, посещаемости.
-
Позволяет выгрузить активную семантику конкурента или сразу нескольких конкурентов (создает групповой отчет со списком ключей).
-
Парсит рекламные кампании в Яндекс.Директ, Adwords.
-
Модуль «Семантическое ядро» создает СЯ с помощью древовидных структур и автоматической кластеризации. Есть возможность выгружать в сервис дополнительные ключи, группировать их в ручном режиме.
-
-
Serpstat
По функционалу сервис напоминает Keys.so. Есть платная и бесплатная версии. Тоже парсит ключи конкурентов и делает автоматическую кластеризацию, но есть отличия.
-
Собирает все виды запросов: брендовые, информационные, коммерческие, навигационные.
-
При анализе выдачи показывает, есть ли в ТОПе соцсети и колдунщики.
-
В отчете отображается ориентировочный трафик по ключам.
-
-
Мутаген
Платный сервис, который позволяет выгружать ключи конкурентов, их частотность.
-
Оценивает уровень конкуренции по запросу.
-
Собирает СЯ на основе запросов конкурентов. Работает только с геонезависимыми запросами, поэтому подходит не всем коммерческим проектам.
-
Расширяет ядро. Находит ключевые слова, по которым показываются те же страницы, что и по заданным фразам.
-
Оценивает параметры ключа (частотность, позиции, хвосты, LSI фразы).
-
Автоматически кластеризует ключи.
-
Парсит Вордстат.
-
-
SpyWords
Еще один популярный платный сервис, который работает с ключами сайтов-конкурентов. Возможности SpyWords:
-
Анализирует и сравнивает конкурентов.
-
Подбирает эффективные запросы конкурентов для SEO-продвижения и рекламных кампаний.
-
Разбивает ядро на кластеры.
-
Алгоритм сбора ядра
Семантическое ядро можно собрать буквально за час с помощью сервисов анализа конкурентов, о которых мы рассказали (например, Keys.so или Serpstat). Во многих ситуациях этот экспресс-способ будет полезен.
Но у такого ядра есть существенный минус. Оно вторично, поскольку включает только те ключевые фразы, по которым уже продвигаются конкуренты. И не учитывает множество запросов, которые интересуют пользователей, но которых пока нет у ваших прямых конкурентов. А значит, у вас есть хороший шанс опередить их и занять высокое место в выдаче, если соберете полное ядро.
Поэтому мы расскажем о классическом способе сбора семантического ядра. Он довольно трудоемкий, потому что предполагает сбор ключей из максимального количества источников и полуавтоматическую-полуручную кластеризацию.
Алгоритм действий:
-
Нужно составить в текстовом файле список вводных слов. Это базовые ключи — слова и фразы, которые имеют отношение к тематике сайта. Например, для цветочного интернет-магазина это названия цветов: розы, тюльпаны, орхидеи и так далее. Чем длиннее список, тем лучше. Хорошие подсказки по вводным словам может дать модуль ведения проектов Пиксель Тулс.
-
Создайте проект в Key Collector и загрузите в него эти слова. Предварительно нужно разобраться в настройках программы. Учтите, что для парсинга понадобятся прокси, антикапча и дополнительные аккаунты Яндекса.
-
Укажите в настройках, какие источники будете парсить: Вордстат, подсказки, Директ и так далее. Выбор зависит от особенностей ниши. Чем больше источников, тем полнее ядро.
-
Начните сбор ключей, кликнув по соответствующей кнопке. Парсинг занимает несколько часов, иногда дней. Также нужно собрать статистику. В первую очередь нас интересует точная частота «!».
-
Когда сбор будет закончен, вы получите длинный список запросов с указанием частотности.
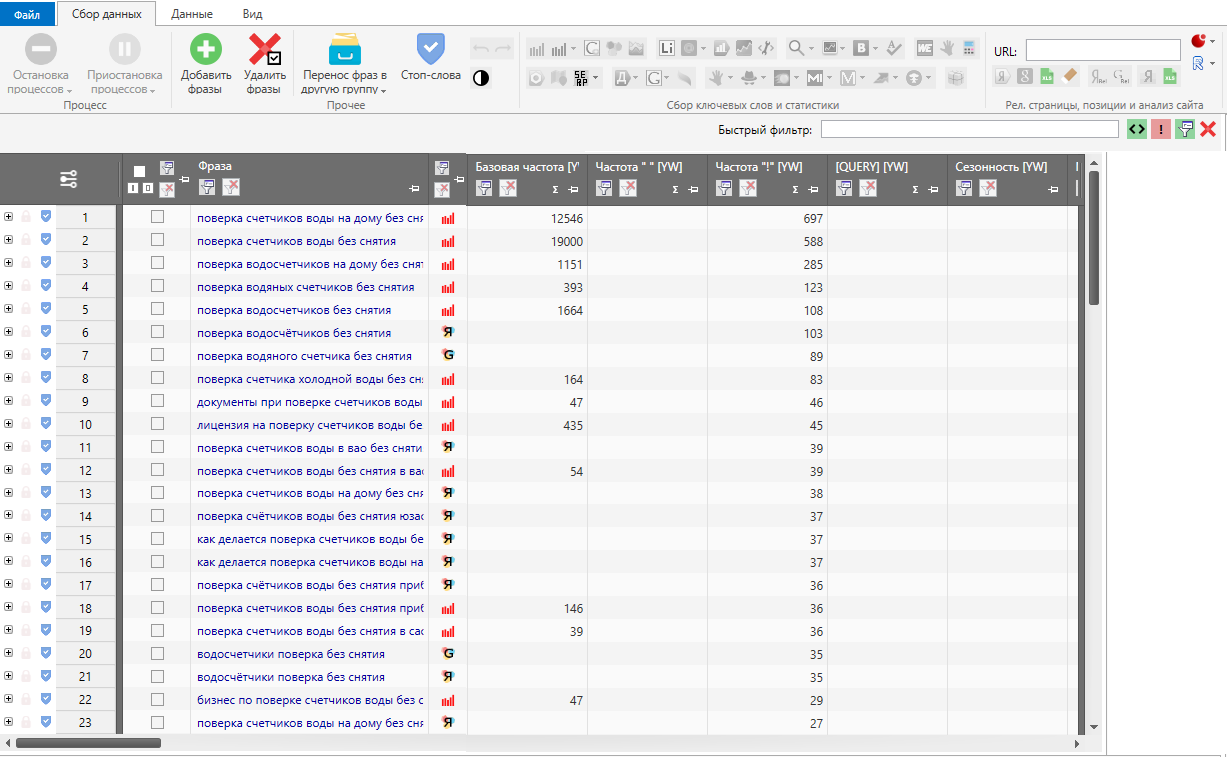
Теперь его нужно очистить от «мусора» — ненужных ключей: нетематичных, неполных. Что считать мусором, зависит от тематики и типа проекта. Например, для информационных сайтов мусорными считаются коммерческие запросы. Можно чистить слова по частотности (например, убрать все слова с частотностью ниже 10). Но есть тематики, где даже два запроса в месяц имеют значение, их не нужно убирать. В чистке поможет автоматический фильтр по стоп-словам.
-
Классический способ сбора ядра предполагает две итерации: парсинг-чистка-парсинг-чистка. Поэтому «чистое» (без мусорных запросов) ядро мы снова отправляем на парсинг. Потом снова чистим от мусора.
-
В ядро загружаются ключи конкурентов (например, выгруженные из сервиса Keys.so или Пиксель Тулс). Парсится актуальная статистика (частотность).
-
Кластеризация — деление ключей на группы (на этом этапе остановимся подробнее).
-
Экспорт готового ядра в таблицу формата .xls.
Кластеризация
Группировка запросов по кластерам — самая ответственная и долгая часть работы. На этом этапе можно пользоваться автоматическими кластеризаторами (Пиксель Тулс, Key Collector, KeyAssort, Keys.so. и другими), они проделают черновую работу и сэкономят время. Но полностью полагаться на них не стоит.
При группировке ядра формируется структура сайта. Это слишком важный этап, чтобы полностью доверить его автоматическим алгоритмам. Машина не знает вашу отрасль, ваши бизнес-цели и особенности конкуренции. Поэтому нужно проверить каждый кластер и, скорее всего, что-то перегруппировывать вручную.
Запросы кластеризуются по принципу матрешки. Сначала делим все ключи на большие группы. Например, для магазина постельного белья это: «Подушки», «Одеяла», «Постельное белье», «Пледы и покрывала». Это и будут основные разделы (категории) сайта.
Важно использовать шаблон, чтобы структура получилась сразу правильная и логичная.
Затем каждую большую группу нужно раздробить на более мелкие. Например, в разделе «Постельное белье» это: «Постельное белье из сатина», «Постельное белье из жаккарда», «Постельное белье из бязи», «Детское постельное белье». Категорию детского постельного белья можно разделить на подкатегории «Для девочек» и «Для мальчиков». Делим ядро до тех пор, пока не получатся «неделимые» группы запросов.
Типичные ошибки при группировке ядра:
-
Руководствоваться только собственной логикой и не обращать внимания на структуру семантического ядра конкурентов. Сайты-лидеры ниши могут стать хорошим источником идей.
-
Помещать в разные группы ключи с разной формулировкой, но общим интентом. Например, ключи «постельное белье для новорожденных» и «постельное белье для младенцев» отражают один интент, поэтому должны оказаться в одном кластере.
-
Объединять в общий кластер фразы разного типа. Например, коммерческий запрос «купить белье из жаккарда» и информационный «как постирать жаккардовое белье».
Актуализация ядра
SEO-ядро не собирают «раз и навсегда». В любой нише, особенно коммерческой, меняются запросы и их частотность. Спрос на отдельные позиции проседает, появляются новые ключи.
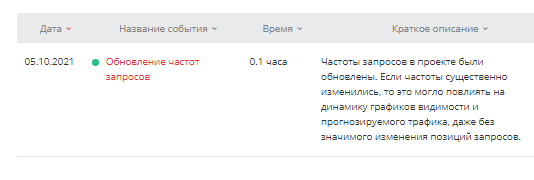
Поэтому ядро нужно регулярно актуализировать. Заново пересобирать его — слишком трудоемкая задача. Удобнее и проще использовать специальные сервисы, которые помогают найти недостающие фразы и актуализировать частотность.
Например, модуль ведения проектов Пиксель Тулс в автоматическом режиме регулярно проверяет и обновляет частоты запросов. Соответствующий отчет появляется в разделе «события».
Подведем итоги
-
Семантическое ядро решает не только SEO, но и маркетинговые задачи. Помогает анализировать спрос, находить точки роста.
-
Существуют автоматические экспресс-способы сбора СЯ. В некоторых ситуациях это оптимальное решение. Но при жесткой конкуренции такой подход не оправдывает себя.
-
Чем больше задействовано источников ключевых слов (Вордстат, Директ, подсказки, соцсети, конкуренты), тем полнее ядро. И тем сложнее процесс.
-
Существует много программ и онлайн-сервисов, которые помогают в сборе и группировке ядра. Для оптимальной схемы работы достаточно выбрать три-четыре сервиса.
-
Кластеризацию СЯ можно частично автоматизировать. Но группировка — это тонкий процесс, не стоит полностью полагаться на автоматические кластеризаторы.
-
Используйте шаблон для формирования правильной структуры.
Если у вас закончились идеи, зайдите в Wordstat и посмотрите, что ищут при вводе, например, iPhone.
К собранному в Excel списку добавим слово «Цена».
Далее найденные слова нужно скомпоновать. Это можно сделать через инструмент Комбинатор от eLama:
Полученные фразы мы будем использовать на следующем этапе.
Этап 2. Подбор семантического ядра
Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра.
Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее. Выберите все слова в выдаче и перенесите их в Google Таблицу или Excel:
Получился список и одна свободная колонка, которая нужна для списка минус-слов.
Этап 3. Чистка семантического ядра
Теперь весь список ключевых слов нужно очистить от нерелевантных запросов, чтобы показывать рекламу только тем пользователям, которые ищут наши товары. Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы.
Проще и удобнее это сделать в минусаторе eLama. Скопируйте собранную список семантики и вручную выделите все ненужные слова. В итоге у вас получится два списка: ключей и минус-слов. А еще в минусаторе можно применить готовый список минус-слов к списку ключевых фраз — инструмент найдет нерелевантные фразы и удалит их.
Можно продолжить работу в таблице, но так будет посложнее.
Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel.
Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов».
По сравнению с Wordstat он имеет больше функций, благодаря которым можно:
- узнать конкурентность ниши и процент показа объявлений;
- минимальные/максимальные ставки для показа объявлений внизу/вверху страницы.
Для получения более точного результата попробуйте комбинировать все инструменты.
Этап 4. Заключительный
Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость.
Операторы и типы соответствия ключевых слов в Яндекс Директе и Google Ads
Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление.
Полный список операторов Яндекс Директа есть на странице помощи, а для типов соответствия Google Ads — здесь.
Для экономии времени используйте используйте инструмент Комбинатор ключевых фраз, который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор:
Если нужны типы соответствия/операторы, которых нет в комбинаторе, используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом.
Подбор ключевых слов для КМС и РСЯ
Для рекламы в РСЯ и КМС в семантическое ядро достаточно включить широкие, высокочастотные ключевые фразы, связанные между собой. Уточнять их операторами не нужно.
Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ.
Заключение
Сбор семантики — интересный, но сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.
Семантическое ядро – фундамент последующего продвижения сайта. Данная статья будет полезна как новичкам, так и практикующим специалистам, а также клиентам, стремящимся получше разобраться в вопросах поискового продвижения. Сложно и муторно в этой статье точно не будет – обещаем
Собрали целый массив структурированной информации: что такое семантика, как выглядит семантическое ядро; как собрать ядро для интернет-магазина или маркетплейса; способы кластеризации, а также анализ СЯ конкурента, и все способы сбора ключей.
Кстати, хорошие примеры семантического ядра есть у Rush Analytics.
Содержание:
Что такое семантика и как выглядит семантическое ядро
Для совсем новичков приведем цитату из Википедии: семантическое ядро представляет собой упорядоченный набор слов, их морфологических форм и словосочетаний, характеризующих вид деятельности, товары и услуги, предлагаемые сайтом.
Страшно, сложно и непонятно.
Конкретизируем: семантическое ядро – структурированное описание сайта, учитывающее пользовательский спрос, интересы аудитории, специфику бизнеса и цели проекта. Таким образом, СЯ – это не просто список слов и словосочетаний.
К.О.
Стоит учитывать, что в ядро попадают запросы, вводимые пользователями в поисковую систему. Эти запросы называют ключевыми словами, иначе – ключами, благодаря которым вы можете узнать, что, как и для чего ищет ваша аудитория.
- Что ищут – какая информация, услуга, товар интересны пользователям.
- Как ищут – какими фразами они пользуются для поиска.
- Зачем ищут – цели получения информации. Например, сравнить цены, выбрать, купить и т.д.
Представим, что вы планируете открыть сервисный центр по ремонту телефонов и выйти в онлайн. Вам необходимо определиться, как составить семантическое ядро, какие услуги более всего интересуют ваших потенциальных клиентов.
Вордстат отражает, что вводят в поисковик люди, которым необходимо отремонтировать телефон.
А если кликнуть на запрос, то перейдем на следующий «уровень» с уточненными ключевыми словами.
«Починить телефон», «отремонтировать телефон» говорят нам о целях поиска. Сопутствующие основной фразе «самсунг», «iphone» и прочие отвечают на вопрос о том, что именно хотят починить пользователи.
Задачи семантического ядра не ограничиваются на описании тематики сайта:
- СЯ определяет структуру сайта – страницы, разделы, иерархичность. Это облегчает навигацию как для аудитории, так и для ПС.
- Благодаря семантическому ядру оптимизируем страницы под конкретные запросы — прописываем мета-теги, создаем релевантный контент.
- Создаем матрицу контента. Семантическое ядро дает нам основу для создания контент-плана — релевантные статьи (в том числе описания ассортимента), инфоблог и прочее.
- Оптимизированное ядро несложно использовать и для настройки контекстной рекламы.
- Благодаря СЯ мы грамотно линкуем страницы, чтобы корректно распределить ссылочный вес, а также для пользователей облегчить поиск необходимой информации.
- Актуализация ядра = достоверный анализ покупательского спроса. Отслеживая, чем интересуются пользователи, можно включать новые услуги, расширять ассортимент и прочее.
Таким образом, семантическое ядро – основа успешного продвижения ресурса в поисковых системах. Его составлением стоит заняться до создания сайта. Формирование семантического ядра до того, как создан ресурс, – это семантическое проектирование.
Для начала определяют тематику сайта, ключи должны наиболее полно описывать содержание. Далее запросы кластеризуют по разделам сайта. После – собранную семантику используют для постраничной оптимизации страниц.
Как собрать семантическое ядро для интернет-магазина
Как пользователи ищут товары и услуги в интернете?
- Если речь о технике, косметике, мебели, ищут по наименованию, а порой даже по артикулу.
- Если конкретики нет, то ищут по товарной категории.
- Часто вводят запросы, начинающиеся с «как…», «почему…», и в итоге находят, что им нужно купить, например, для удовлетворения той или иной потребности.
Чтобы собрать семантическое ядро для интернет-магазина, можно воспользоваться wordstat.yandex.ru, KeyCollector. Есть свои плюсы и минусы.
1. Wordstat бесплатен, предоставляет прекрасную возможность сориентироваться, насколько востребован конкретный запрос. Учитывается время, регион, порядок слов, статистика за месяц. Такой вариант подойдет для ручного сбора небольших семантических ядер. Не забудьте установить Yandex Wordstat Assistant, благодаря которому вы сможете сохранять и фразы, и их частотность в таблицах.
2. Парсер, например, Key Collector. Парсер это программа, сервис или скрипт, который собирает данные, анализирует и выдает в нужном формате. Чтобы было еще понятнее, условно определим парсер как сортировщик. Среди платных профессиональных программ можно выделить KeyCollector. Разумеется, требует времени на освоение, и прекрасно подходит для работы с большими семантическими ядрами.
С чего начать?
В первую очередь обозначим, что СЯ для страниц каталога и страниц товаров будут разными, раз мы говорим именно об интернет-магазине.
Рекомендуем начать с работы над страницами каталога, точнее, с его структуры. Почему это важно?
Продуманный каталог поможет не только собрать семантическое ядро, но и улучшать поведенческие факторы. Если структура удобна для пользователя, то и поисковая система «поднимет выше» сайт в выдаче.
Используем готовый шаблон
Чтобы подготовить каталог, воспользуйтесь готовым шаблоном –их можно найти в интернете. На скриншоте один из вариантов:
Таблица для подготовки семантического ядра интернет-магазина
Разумеется, это лишь пример, и ваша таблица может получить гораздо сложнее. Главное – вы поняли принцип.
Заполнение шаблона
Ядро составляем на основе ассортимента интернет-магазина, но в первую очередь следует заняться категориями и подкатегориями. Непосредственно к карточкам товаров можно обратиться позже.
Как создать каталог?
- оценить, каким бы вы хотели видеть перечень, и составить его в соответствии с собственными предпочтениями и видением;
- опереться на прайсы поставщиков;
- позаимствовать у конкурентов из топа.
Так, например, будет выглядеть каталог для магазина растений и семян:
База запросов
Помимо этого, вы можете воспользоваться любой крупной базой ключевых слов. Например, у Keys.so база состоит более 120 млн слов из русскоязычного сегмента интернета и практически отсутствуют нулевые ключевые запросы. Вводите ключевое слово и выбираете регион:
Таким же образом вы можете взять сайт конкурента и проанализировать его, какие запросы он использует и какая видимость в поисковой выдаче:
Подбираем запросы
Категория должна быть релевантна своему запросу – это и есть основа оптимизации, благодаря которой мы привлекаем заинтересованных клиентов.
Как определить релевантность? Обратите внимание на частоту поиска фразы, которую вы проверяете в сервисе или программе. Если необходимо, ограничивайте по регионам.
Далее следует оптимизация страниц категорий и подкатегорий, начинающаяся с проработки Title, Description, H1, но это уже тема другой статьи.
Несколько советов касаемо сбора семантики :
- Сбор СЯ начинается с категорий и подкатегорий, если речь об интернет-магазине. Непосредственно к карточкам переходите после.
- При подборе проверяйте название и на русском, и на английском. Например, «Indesit» и «Индезит».
- Учитывайте, что поставщики формируют прайс так, как им удобно. Чтобы не ошибиться, формируйте категории все же на базе семантического ядра.
- Сбор начинайте с парсеров (в идеальном случае).
На этом пока завершим первую часть нашей статьи про семантическое ядро. В следующей части рассмотрим СЯ для сайта услуг; кластеризацию и детализацию запросов и как проанализировать семантическое ядро конкурентов.
Содержание
Какими бывают поисковые запросы?
Сервисы для сбора и кластеризации
Семантическое ядро — просто список запросов, по которым продвигается сайт. Файл с длинной таблице из сотен или тысяч строк. Каждая строка — слово или словосочетание, например: [купить плед], [купить шерстяной плед], [плед сова купить]. Это ключевые слова, которые пользователи вводят в поисковик, например, Яндекс или Google.
В готовом ядре такие фразы разделены на группы. В случае с пледами в одну группу попадут слова с одинаковым интентом (потребностью): [сова с пледом купить], [плед сова], [сова с пледом внутри], [мягкая сова с пледом].
В ядре указана частотность каждого ключевого слова (количество запросов в месяц) и прочие параметры запросов.
Для SEO-специалиста ядро — основа будущей структуры сайта, его фундамент. Под ключи предстоит «заточить» отдельные страницы, разделы и весь сайт.
Для бизнесмена и маркетолога ядро — это набор подсказок. СЯ поможет оценить спрос и увидеть недостающие позиции в ассортименте. Например, в случае с пледами ядро подсказывает, что спрос на шерстяные пледы выше, чем из хлопка.
Согласно определению:
Семанти́ческое ядро — совокупность целевых поисковых запросов, по которым продвигается или планируется к продвижению проект.
Можно добавить, что ядро описывает интересы аудитории сайта, специфику спроса и бизнеса.
Зачем его собирать?
Ключи показывают, что ищет аудитория и какими фразами формулирует свой запрос.
Если вы думаете, что знаете все о потребностях своих клиентов, то при составлении семантического ядра поймаете инсайт. Представление бизнесмена или маркетолога о том, что ищут люди в интернете, и реальные запросы пользователей чаще всего не совпадают.
Предположим, вы открываете магазин цветов в Москве. Можно предположить, что один из популярных фраз — это [купить чайные розы].
На самом деле, это не популярный запрос.
При этом в тематике есть ключевые слова с неожиданно высокой частотностью по Wordstat.
Этот пример показывает, что важно сверяться с реальными запросами потенциальных покупателей и клиентов. Ядро помогает маркетологам анализировать покупательский спрос.
Но оно не только описывает потребности аудитории, а еще и выполняет SEO-задачи:
-
Семантическое ядро сайта ложится в основу структуры. Разделы, подразделы и страницы создаются под группы ключевых фраз. Именно в такой последовательности: сначала ядро, потом — на его основе — структура. Существует альтернативный принцип — подбор ключей под готовые разделы и страницы. Оба подхода считаются рабочими, хотя и вызывают много споров в среде сеошников.
-
Группы ключевых слов — основа контента. На них можно опираться, создавая контент-план, планируя разработку онлайн-сервисов.
-
Ключевые фразы распределятся по страницам. Они нужны для оптимизации текстов, заголовков и мета-тегов.
-
При перелинковке эти слова используются как анкоры.
-
В контекстных объявлениях точно сформулированные фразы помогают «попасть» в интересы аудитории, повысить кликабельность и конверсию.
Какими бывают поисковые запросы?
Классификация ключевых слов основана на нескольких признаках.
По частотности ключи делят на:
-
ВЧ — высокочастотные (больше 1000 запросов в месяц);
-
СЧ — среднечастотные (100-1000);
-
НЧ — низкочастотные (меньше 100).
Распределение поисковых запросов по частоте употребления в Яндексе: 92% из них — встречаются менее 10 раз в день.
Доля уникальных (неповторяющихся) запросов в течение дня — от 40% до 60% в зависимости от региона.
Это условные и очень приблизительные цифры. В каждой нише свои диапазоны НЧ, СЧ и ВЧ. В некоторых узконишевых тематиках даже запрос с частотой «100» можно отнести к высокочастотным.
По типу интента ключевые слова делят на:
-
Информационные. Пользователь ищет какие-то сведения. Примеры: «как постирать плед», «как выбрать свадебный букет».
-
Коммерческие (транзакционные). Пользователь ищет товар или услугу. Он уже готов сделать заказ или купить товар. Примеры: «купить шерстяной плед», «заказать букет на свадьбу», «интернет-магазин кондиционеров Москва», «цены на клининг квартир».
-
Навигационные. Пользователи хотят найти конкретный сайт, компанию. Примеры: «Связной», «Госуслуги», «официальный сайт Кремля».
-
Общие (нечеткие). Пользователь не уточняет свое намерение. Примеры: «планировка кухни», «двери» (непонятно, пользователь хочет разобраться в видах дверей или готов сделать заказ).
Некоторые специалисты выделяют в отдельный класс витальные (брендовые) запросы. Они содержат только название бренда. Примеры: «Мерседес», «Apple», «Шанель».
По географической привязке ключевые фразы делят на:
-
Геозависимые. Поисковые системы привязывают их конкретному региону или городу. В каждом городе по этому запросу формируется своя выдача. Примеры: «доставка продуктов», «расписание кинотеатров».
-
Геонезависимые. Примеры: «как приготовить пиццу», «о чем фильм Остров проклятых». Такие фразы как «снять квартиру в Москве», «лучшие рестораны Санкт-Петербурга» тоже геонезависимые, поскольку выдача по ним одинаковая во всех регионах.
Разобраться в типах ключей нужно, чтобы правильно разгруппировать ядро. Например, при кластеризации нельзя объединять в одну группу информационные и транзакционные фразы. Они должны попасть в разные кластеры и продвигаться на отдельных страницах.
Источники ключей
Ключи хранятся в базах поисковых систем и в сервисах анализа сайтов-конкурентов. Задача семантика — извлечь и систематизировать. Основные источники ключевых слов:
Яндекс.Wordstat. Бесплатный сервис поисковой системы Яндекс. Показывает ключевые фразы, актуальную статистику, распределение частотности по регионам, историю.
Google Keyword Planner. Сервис создан для работы с рекламными объявлениями Google. Чтобы «подсмотреть» ключи, нужно создать рекламную кампанию.
Для сайтов с поисковым трафиком можно использовать системы аналитики Яндекс.Метрика, Яндекс.Вебмастер, Google Analytics. Здесь можно проверить, по каким ключевым словам пользователи заходят на ваш сайт.
Вебмастер Яндекса также формирует пул рекомендованных запросов.
Поисковые подсказки. Когда пользователь набирает фразу в поисковой строке, Яндекс или Google предлагают свои варианты концовки. Эти подсказки — тоже ключевые слова.
Другие источники ключей: базы ключей, сайты конкурентов. Фразы из этих источников не получится скачать напрямую, но их можно спарсить с помощью специальных сервисов.
Сервисы для сбора и кластеризации
Существует много онлайн-сервисов и десктопных программ для сбора и группировки семантики.
-
Key Collector
Основной инструмент при сборе ядра. Платная программа с бессрочной лицензией. Устанавливается на компьютер или ноутбук. Возможности Key Collector:
-
парсит (собирает) ключи из Wordstat, Google.Ads, Liveinternet.ru, «ВКонтакте» и других платформ.
-
собирает поисковые подсказки.
-
определяет актуальную частотность.
-
фильтрует ключи по стоп-словам и частотности.
-
находит релевантные страницы.
-
проводит группировку (кластеризацию) запросов.
-
-
Онлайн-инструменты Пиксель Тулс
Здесь есть сразу несколько инструментов для работы с семантикой.
В модуле «Проекты» сервис автоматически генерирует базовый набор ключей для сайта. Его можно дополнять, загружая слова из других источников.
Другие полезные инструменты для работы с ядром от Пиксель Тулс:
-
Определение геозависимости, локализации и коммерциализации запроса.
-
Комплексная оценка запросов. Сервис определяет интент, то есть желание/намерение пользователя.
-
Парсинг поисковых подсказок в выдаче Яндекса.
-
Парсинг поисковых подсказок в выдаче Google.
-
Парсинг подсказок Avito.
-
Группировка запросов по ТОПу. Инструмент определяет позиции сайта, частотность, анализирует ТОП и распределяет запросы, определяя релевантные URL.
-
Детальный анализ запроса. Оценивает важные параметры фразы: геозависимость, слова из подсветки, частотность, число главных страниц в ТОП, средний возраст документов и другие.
-
Вместе с запросом ищут… Инструмент находит похожие ключи.
-
Получение семантики по домену. Сервис парсит фразы сайтов-конкурентов.
-
Получение данных из Яндекс.Вордстат. Инструмент собирает ключевые слова, их историю, анализирует частотность.
-
Список запросов из Яндекс.Вебмастера. Выгружает ТОП-500 запросов по данным сервиса Вебмастер.
-
Лемматизация и удаление дублей фраз. Удаляет условно одинаковые ключи с учётом лемматизации (то есть приводит слова к лемме — нормальной, словарной форме слова).
-
-
Key Assort
Еще одна платная десктопная программа. Автоматически кластеризует ядро (делит на группы), создает структуру проекта на основе семантики, находит лидеров ниши. Программа не парсит ключи, а работает с уже собранными запросами.
-
Keys.so
Платный онлайн сервис с широким функционалом:
-
Анализирует сайты конкурентов: трафик, позиции, поисковые запросы.
-
Сравнивает конкурентов по позициям, видимости, посещаемости.
-
Позволяет выгрузить активную семантику конкурента или сразу нескольких конкурентов (создает групповой отчет со списком ключей).
-
Парсит рекламные кампании в Яндекс.Директ, Adwords.
-
Модуль «Семантическое ядро» создает СЯ с помощью древовидных структур и автоматической кластеризации. Есть возможность выгружать в сервис дополнительные ключи, группировать их в ручном режиме.
-
-
Serpstat
По функционалу сервис напоминает Keys.so. Есть платная и бесплатная версии. Тоже парсит ключи конкурентов и делает автоматическую кластеризацию, но есть отличия.
-
Собирает все виды запросов: брендовые, информационные, коммерческие, навигационные.
-
При анализе выдачи показывает, есть ли в ТОПе соцсети и колдунщики.
-
В отчете отображается ориентировочный трафик по ключам.
-
-
Мутаген
Платный сервис, который позволяет выгружать ключи конкурентов, их частотность.
-
Оценивает уровень конкуренции по запросу.
-
Собирает СЯ на основе запросов конкурентов. Работает только с геонезависимыми запросами, поэтому подходит не всем коммерческим проектам.
-
Расширяет ядро. Находит ключевые слова, по которым показываются те же страницы, что и по заданным фразам.
-
Оценивает параметры ключа (частотность, позиции, хвосты, LSI фразы).
-
Автоматически кластеризует ключи.
-
Парсит Вордстат.
-
-
SpyWords
Еще один популярный платный сервис, который работает с ключами сайтов-конкурентов. Возможности SpyWords:
-
Анализирует и сравнивает конкурентов.
-
Подбирает эффективные запросы конкурентов для SEO-продвижения и рекламных кампаний.
-
Разбивает ядро на кластеры.
-
Алгоритм сбора ядра
Семантическое ядро можно собрать буквально за час с помощью сервисов анализа конкурентов, о которых мы рассказали (например, Keys.so или Serpstat). Во многих ситуациях этот экспресс-способ будет полезен.
Но у такого ядра есть существенный минус. Оно вторично, поскольку включает только те ключевые фразы, по которым уже продвигаются конкуренты. И не учитывает множество запросов, которые интересуют пользователей, но которых пока нет у ваших прямых конкурентов. А значит, у вас есть хороший шанс опередить их и занять высокое место в выдаче, если соберете полное ядро.
Поэтому мы расскажем о классическом способе сбора семантического ядра. Он довольно трудоемкий, потому что предполагает сбор ключей из максимального количества источников и полуавтоматическую-полуручную кластеризацию.
Алгоритм действий:
-
Нужно составить в текстовом файле список вводных слов. Это базовые ключи — слова и фразы, которые имеют отношение к тематике сайта. Например, для цветочного интернет-магазина это названия цветов: розы, тюльпаны, орхидеи и так далее. Чем длиннее список, тем лучше. Хорошие подсказки по вводным словам может дать модуль ведения проектов Пиксель Тулс.
-
Создайте проект в Key Collector и загрузите в него эти слова. Предварительно нужно разобраться в настройках программы. Учтите, что для парсинга понадобятся прокси, антикапча и дополнительные аккаунты Яндекса.
-
Укажите в настройках, какие источники будете парсить: Вордстат, подсказки, Директ и так далее. Выбор зависит от особенностей ниши. Чем больше источников, тем полнее ядро.
-
Начните сбор ключей, кликнув по соответствующей кнопке. Парсинг занимает несколько часов, иногда дней. Также нужно собрать статистику. В первую очередь нас интересует точная частота «!».
-
Когда сбор будет закончен, вы получите длинный список запросов с указанием частотности.
Теперь его нужно очистить от «мусора» — ненужных ключей: нетематичных, неполных. Что считать мусором, зависит от тематики и типа проекта. Например, для информационных сайтов мусорными считаются коммерческие запросы. Можно чистить слова по частотности (например, убрать все слова с частотностью ниже 10). Но есть тематики, где даже два запроса в месяц имеют значение, их не нужно убирать. В чистке поможет автоматический фильтр по стоп-словам.
-
Классический способ сбора ядра предполагает две итерации: парсинг-чистка-парсинг-чистка. Поэтому «чистое» (без мусорных запросов) ядро мы снова отправляем на парсинг. Потом снова чистим от мусора.
-
В ядро загружаются ключи конкурентов (например, выгруженные из сервиса Keys.so или Пиксель Тулс). Парсится актуальная статистика (частотность).
-
Кластеризация — деление ключей на группы (на этом этапе остановимся подробнее).
-
Экспорт готового ядра в таблицу формата .xls.
Кластеризация
Группировка запросов по кластерам — самая ответственная и долгая часть работы. На этом этапе можно пользоваться автоматическими кластеризаторами (Пиксель Тулс, Key Collector, KeyAssort, Keys.so. и другими), они проделают черновую работу и сэкономят время. Но полностью полагаться на них не стоит.
При группировке ядра формируется структура сайта. Это слишком важный этап, чтобы полностью доверить его автоматическим алгоритмам. Машина не знает вашу отрасль, ваши бизнес-цели и особенности конкуренции. Поэтому нужно проверить каждый кластер и, скорее всего, что-то перегруппировывать вручную.
Запросы кластеризуются по принципу матрешки. Сначала делим все ключи на большие группы. Например, для магазина постельного белья это: «Подушки», «Одеяла», «Постельное белье», «Пледы и покрывала». Это и будут основные разделы (категории) сайта.
Важно использовать шаблон, чтобы структура получилась сразу правильная и логичная.
Затем каждую большую группу нужно раздробить на более мелкие. Например, в разделе «Постельное белье» это: «Постельное белье из сатина», «Постельное белье из жаккарда», «Постельное белье из бязи», «Детское постельное белье». Категорию детского постельного белья можно разделить на подкатегории «Для девочек» и «Для мальчиков». Делим ядро до тех пор, пока не получатся «неделимые» группы запросов.
Типичные ошибки при группировке ядра:
-
Руководствоваться только собственной логикой и не обращать внимания на структуру семантического ядра конкурентов. Сайты-лидеры ниши могут стать хорошим источником идей.
-
Помещать в разные группы ключи с разной формулировкой, но общим интентом. Например, ключи «постельное белье для новорожденных» и «постельное белье для младенцев» отражают один интент, поэтому должны оказаться в одном кластере.
-
Объединять в общий кластер фразы разного типа. Например, коммерческий запрос «купить белье из жаккарда» и информационный «как постирать жаккардовое белье».
Актуализация ядра
SEO-ядро не собирают «раз и навсегда». В любой нише, особенно коммерческой, меняются запросы и их частотность. Спрос на отдельные позиции проседает, появляются новые ключи.
Поэтому ядро нужно регулярно актуализировать. Заново пересобирать его — слишком трудоемкая задача. Удобнее и проще использовать специальные сервисы, которые помогают найти недостающие фразы и актуализировать частотность.
Например, модуль ведения проектов Пиксель Тулс в автоматическом режиме регулярно проверяет и обновляет частоты запросов. Соответствующий отчет появляется в разделе «события».
Подведем итоги
-
Семантическое ядро решает не только SEO, но и маркетинговые задачи. Помогает анализировать спрос, находить точки роста.
-
Существуют автоматические экспресс-способы сбора СЯ. В некоторых ситуациях это оптимальное решение. Но при жесткой конкуренции такой подход не оправдывает себя.
-
Чем больше задействовано источников ключевых слов (Вордстат, Директ, подсказки, соцсети, конкуренты), тем полнее ядро. И тем сложнее процесс.
-
Существует много программ и онлайн-сервисов, которые помогают в сборе и группировке ядра. Для оптимальной схемы работы достаточно выбрать три-четыре сервиса.
-
Кластеризацию СЯ можно частично автоматизировать. Но группировка — это тонкий процесс, не стоит полностью полагаться на автоматические кластеризаторы.
-
Используйте шаблон для формирования правильной структуры.

Подписывайтесь
на рассылку
Советы
Как составить семантическое ядро сайта
Руководство с комментариями опытного сеошника

Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Статья написана под надзором Lead SEO в Unisender — Сергея Лукашевича. Если после статьи у вас останутся вопросы— задайте их в комментариях Сергею 🙂
Что такое семантическое ядро
Семантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
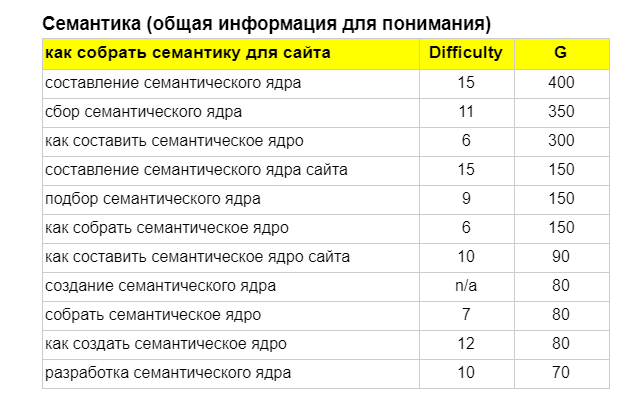
Вот так выглядит семантика для статьи, которую вы читаете. Скорее всего, если вы нашли эту статью в поиске, вы писали что-то подобное. Difficulty означает сложность запроса — чем выше, тем труднее попасть в топ выдачи. G означает частность — сколько таких запросов ищут в месяц
Для чего собирать семантическое ядро
Вот основные причины:
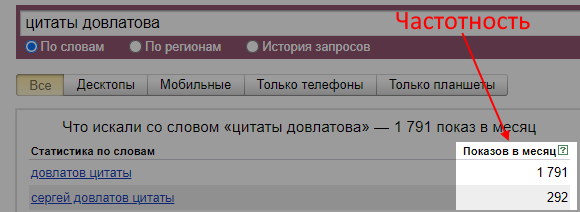
1. Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
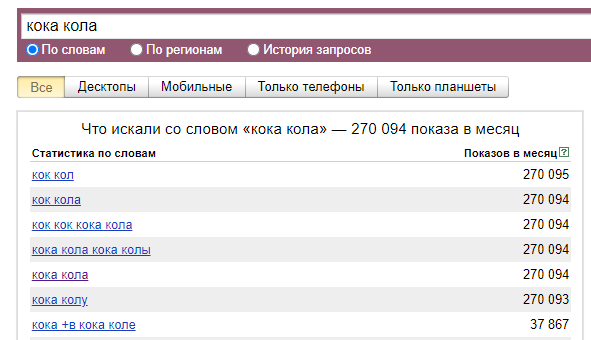
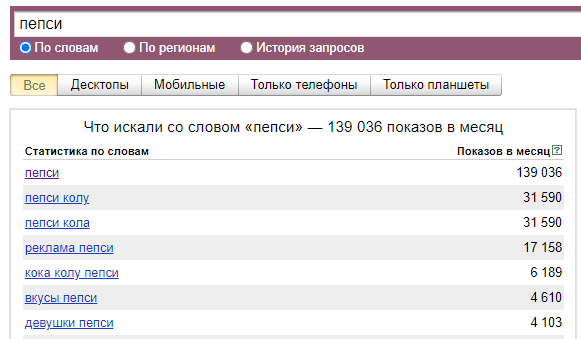
Кока кола популярнее Пепси. По данным Wordstat, запросов, связанных с ней, больше чем в два раза
Анализ семантического ядра дает подсказки в развитии бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.

Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть — никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
2. Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
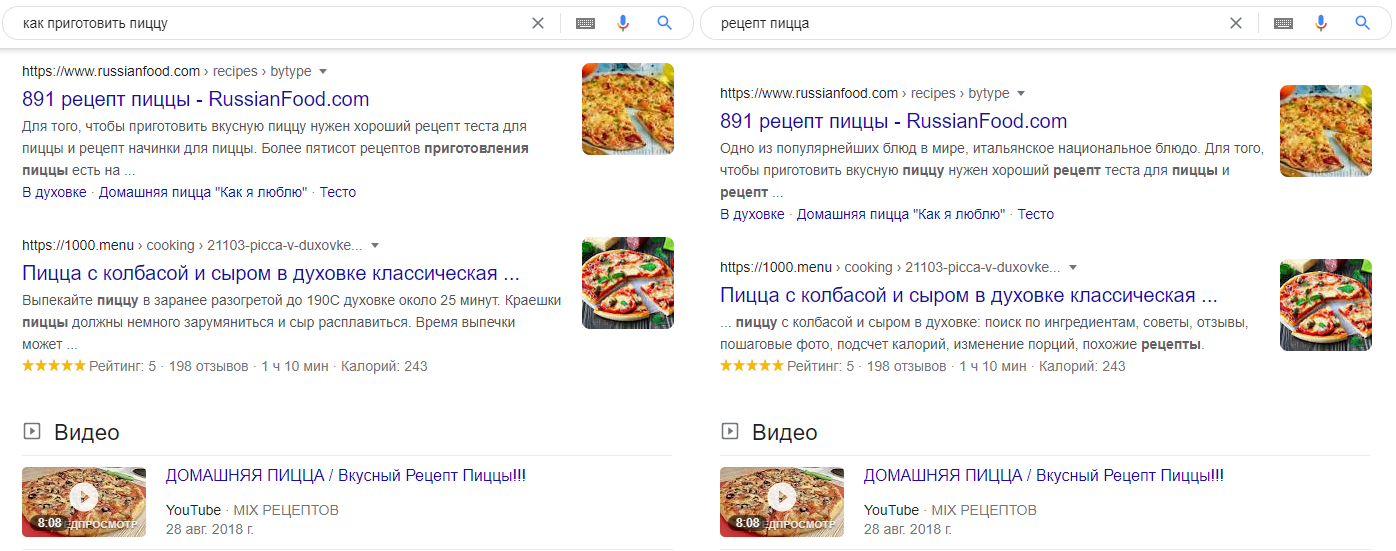
«Как приготовить пиццу» и «Рецепт пицца» — один кластер. Google выдает по этим запросам пересекающие результаты. Первые позиции совпадают полностью
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В блоге Unisender больше половины всех статей seo-оптимизированные. Эта статья тоже оптимизирована.
3. Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с H2 и H3 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
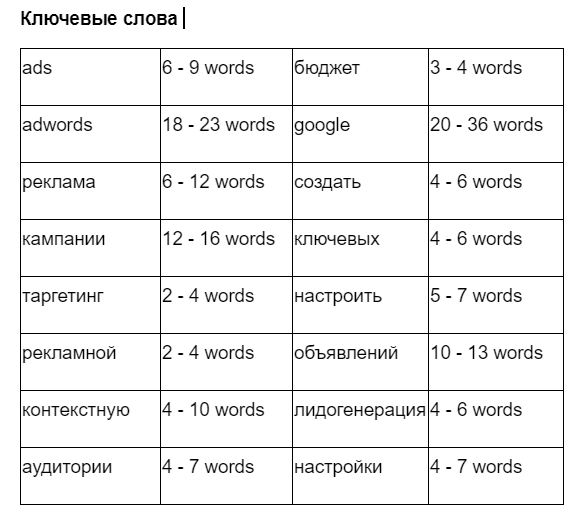
Ключи для статьи про контекстную рекламу. Справа от слова написано его рекомендуемое вхождение — сколько раз за статью оно должно быть использовано
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
4. Отслеживать динамику страниц в поисковике. После того как собрано семантическое ядро мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Семантика — это еще не все
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом, мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучать гид.
Когда семантическое ядро собирать самому, а когда лучше звать сеошника
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
- Собрать много повторяющихся запросов.
- Упустить перспективные низкочастотные запросы.
- Неправильно отсеять нерелевантные запросы.
- Еще выше вероятность ошибиться на следующих этапах — кластеризации, анализе, формировании страниц в интернете.
Чем больше проект, тем выше вероятность ошибок.
Чем больше проект, тем больше нужд в специальном инструментарии
Я пользуюсь Ahrefs, SEMrush и другими. Они достаточно сложные и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 тысяч запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа и она требует времени. Если вы плохо с этим знакомы, вам придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
На что обратить внимание при подборе ядра
Прежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальными семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкуретность можете почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.

Чем выше значение Difficulty, тем сложнее попасть в топ выдачи по этому запросу
Интент
Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
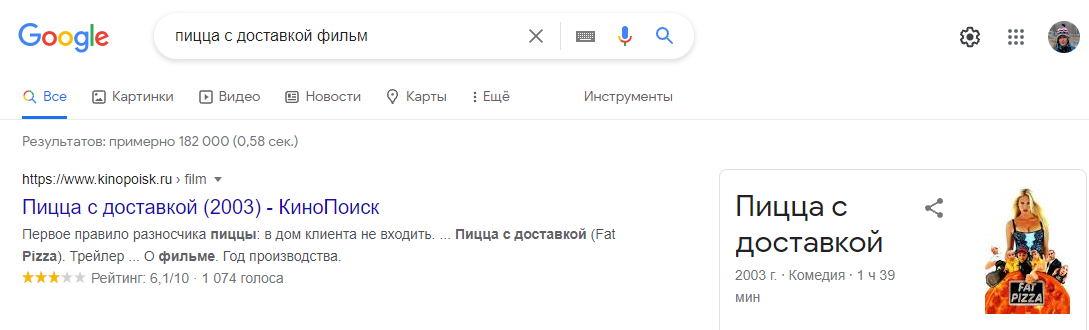
В мою семантику попал запрос «пицца с доставкой фильм». Не знал, что такой есть и поэтому было ощущение что запрос можно оставить. Но потом загуглил и вот — под пиццерию это не подходит
Геозависимость
Геозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если вести «макдональдс адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстат есть настройка по региону — информация будет выводиться только по нему. А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
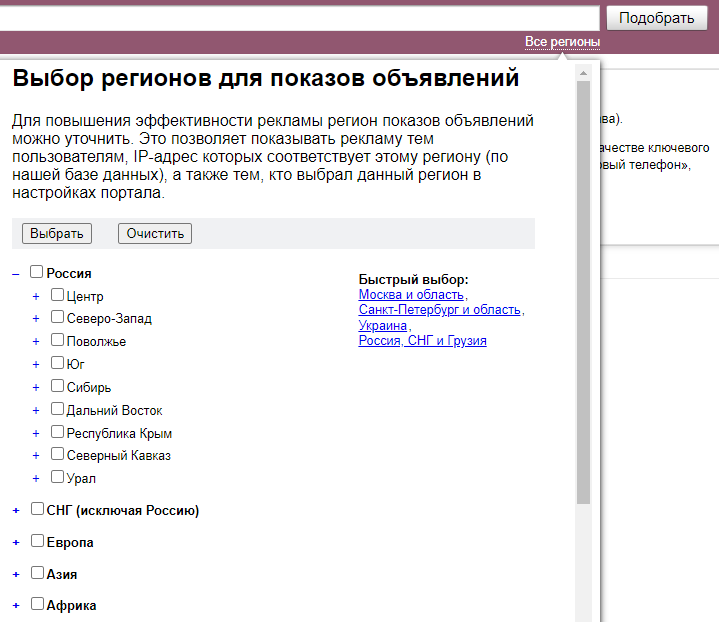
Можно выбрать как всю Россию, так и конкретный город или регион
Пошаговая инструкция как составить семантическое ядро
Подумайте, какие запросы характеризуют ваш сайт
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам? Все идеи, которые придут в голову, записывайте в таблицу или текстовый документ.
Несколько советов, как охватить все интересные запросы:
- Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
- Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна. В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
- Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов и практически всегда эти вопросы популярны в поисковике.
Блог покроет информационные запросы и увеличит трафик на сайт
Даже если ваш сайт предполагается чисто коммерческим, я все равно рекомендую обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена несложно и недорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:

Сбор базовых ключевых слов
Все запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Wordstat или Букварикс. Все сервисы интуитивно понятны.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это и есть, однако он раздражает вводом капчи после каждого запроса.
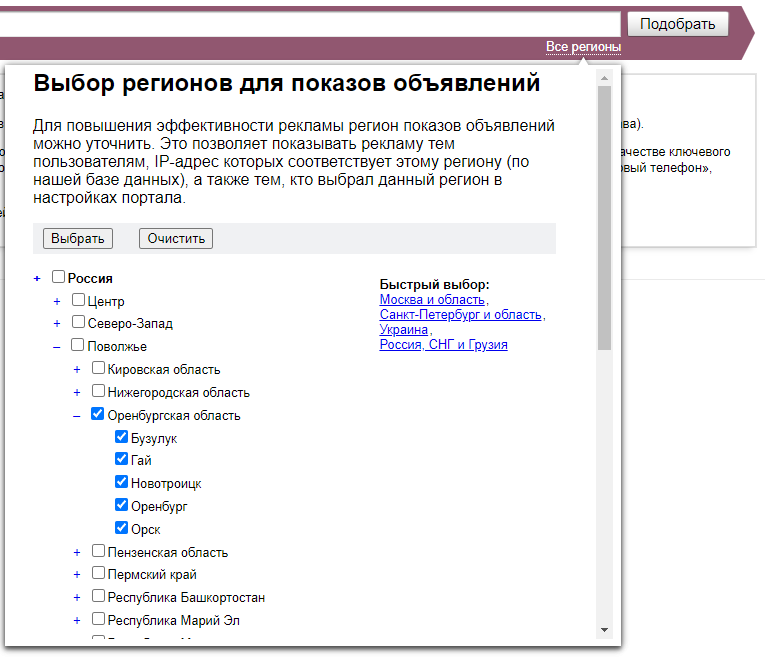
Выбор региона в Яндекс Вордстат
Поглядите, какая мне смешная капча попалась 🙂
Показываю на примере, как работаю с Яндекс Вордстат. Беру первый запрос из своего документа и ввожу его. Всю статистику из обоих столбцов копирую в Google Таблицы.
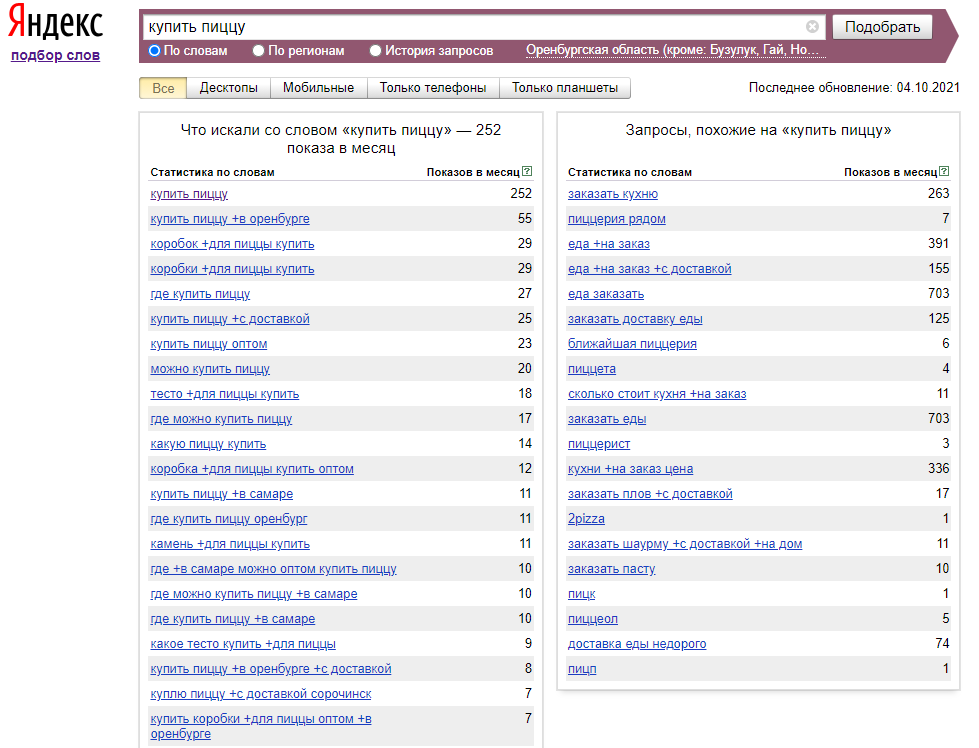
Статистика Яндекс Вордстат по запросу «купить пиццу» для Оренбурга
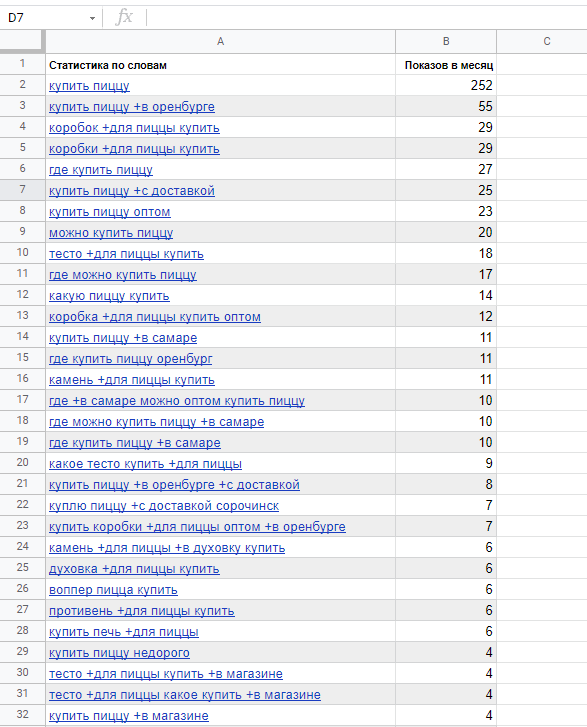
А вот так это выглядит в Google Таблицах
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
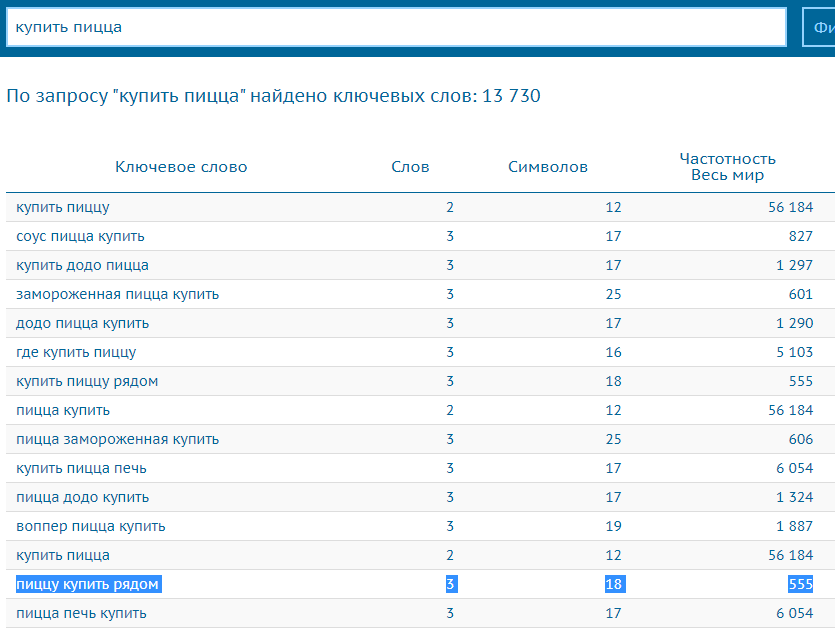
Я вбил общий запрос «купить пицца» и мне приглянулись фразы «пиццу купить рядом» и «воппер пицца купить» — последнюю часто ищут, видимо, какой-то тренд. В этот раз меня интуиция подвела: в Оренбурге «воппер пиццу» ищут 6 раз в месяц, что очень мало, а «купить пиццу рядом» не ищут вообще. Но тем не менее используйте Букварикс — это поможет вам отыскать другие перспективные запросы
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро — вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же — это сигнал, что вы финишировали.
Когда я только начал заниматься SEO, то любил собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
Если сомневаетесь, можете собирать много запросов — мы все равно их удалим при чистке: просто это лишняя работа.
Анализ конкурентов
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные и разбирать в статье их функционал мы не будем. Если вам интересно, присмотритесь к следующим сервисам и изучите их самостоятельно:
- SEMRush
- Ahrefs
- Serpstat.
Почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
На одном сайте пиццерии я увидел раздел с акциями и стал копать в этом направлении. Попробовал запросы «пицца скидки» и «промокоды пицца». По последнему запросу неплохой результат — 169 запросов для Оренбурга, точно нужно взять. А по скидкам частотность меньше, но тоже можно использовать
Шлифуем семантику — сортируем, удаляем дубликаты и лишние символы
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
Выделяем таблицу и нажимаем вкладку «Данные», а в ней «Удалить повторы». Оставляем только столбец A — в котором содержатся сами запросы
Удалить плюсы. Они будут мешать на этапе кластеризации.
Нажмите Ctrl + F или Command + F на MacBook. В выпадающем меню выберите три точки. Либо в разделе «Правки» кликните «Найти и заменить». В поле «Найти» напишите «+», остальное оставьте без изменений. Нажмите на кнопку «Заменить все». Google удалит все плюсы из таблицы
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
Сортировка запросов по убыванию частотности. Выделяем таблицу, нажимаем «Данные» и кликаем по «Сортировать диапазон по столбцу B, Я → А». Если у вас частность не в столбце B, то сортируйте по другому столбцу
Чистка нерелевантных запросов
В семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
- С упоминаниями конкурентов.
- С товарами или услугами, которые не оказываем.
- С упоминанием города, районов и улиц в которых не работаем.
- Запросы с ошибками. Даже если человек сделает ошибку в запросе, поисковик все равно переведет его на верный запрос.
- Фразы, которые вы не понимаете. С большой вероятностью это не имеет отношения к вашей компании.
- Запросы-синонимы, например, «купить смартфон» и «смартфон купить»
- Микрозапросы — их ищут ничтожно мало, такая сеошная погрешность. Зависит от сферы: например, если наша среднечастотка 200 запросов, то все запросы меньше 10 можно удалять. Тем более, если они похожи на уточнение основного запроса.
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, потом оказалось что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можете загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:



Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документ
При сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Не игнорируйте информационные запросы
При чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
В примере про пиццерию я выяснил, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить человеку купить нашу пиццу, по рецепту который он искал. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который я увидел — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Кластеризация
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можете присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
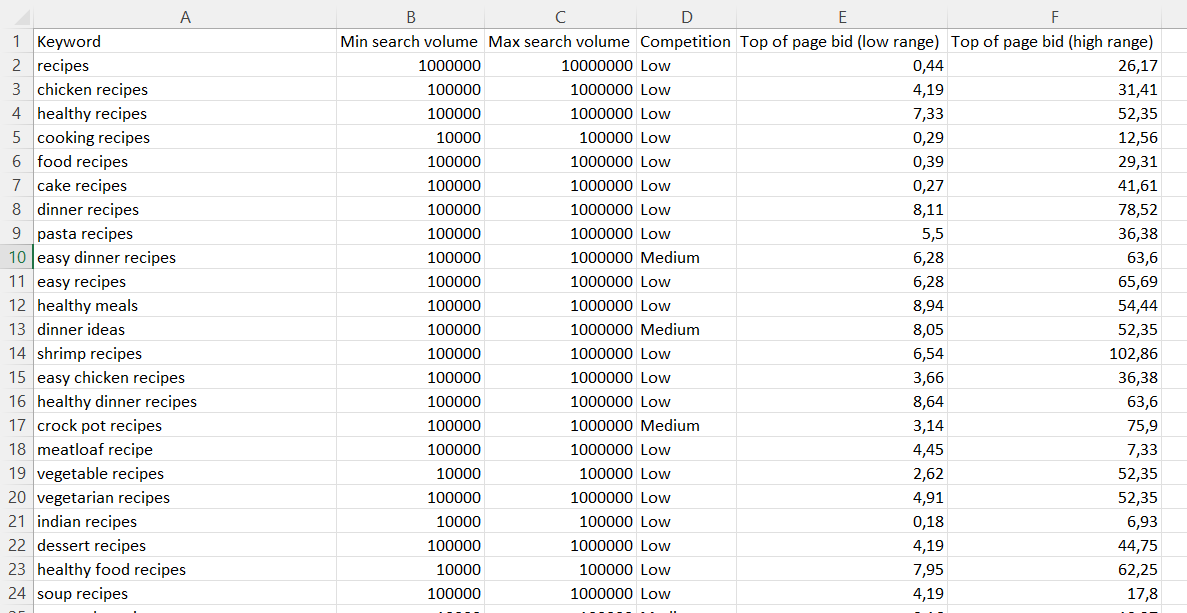
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
В меню нажимаем «Файл» — «Импорт» — «Файл с параметрами»
Следующие окна оставляем без изменений:
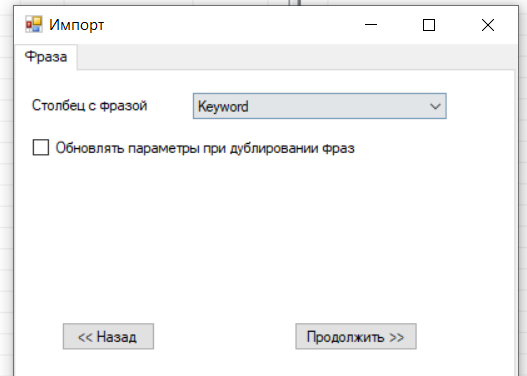
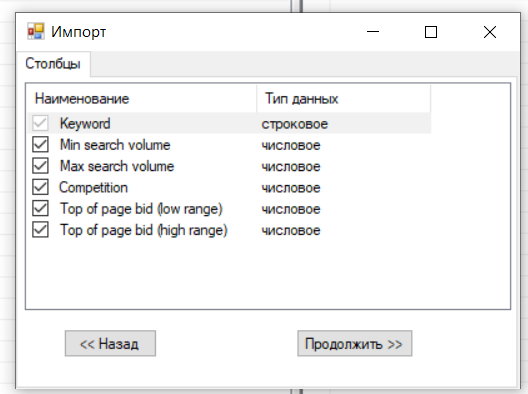
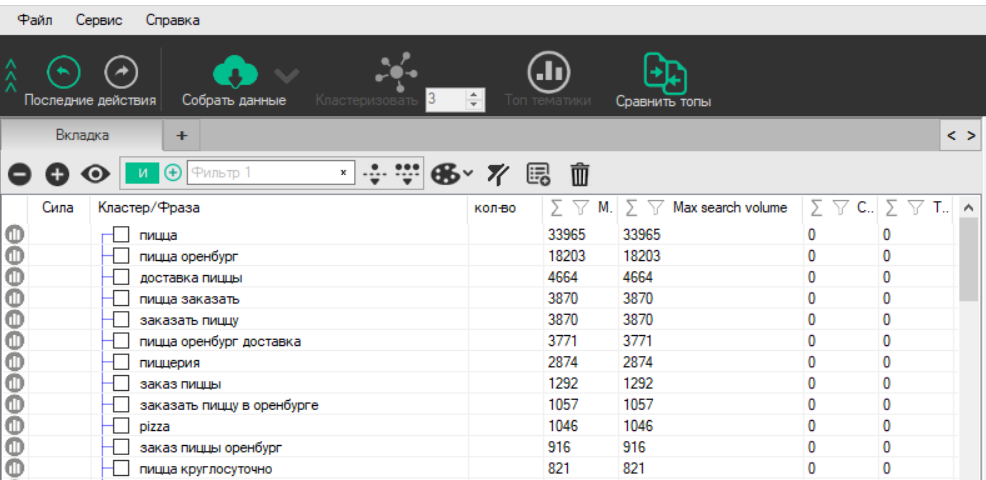
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
Так как мы работали с Яндекс Вордстат, то собираем по Яндексу
У нас около 200 запросов и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров . Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
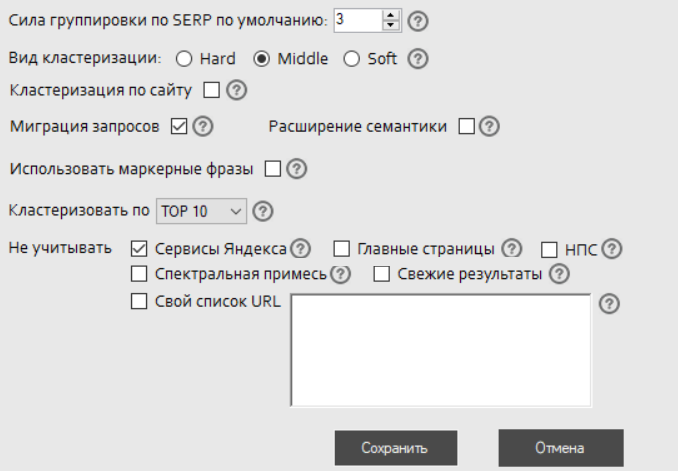
Настройка кластеризации
Меняйте настройки пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
В нашем примере получился такой результат:

В последнем кластере ошибка — это не статья в блоге, а страницы пиццы
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Что дальше
Теперь у вас есть собранная и кластеризованная семантика. Можно:
- Продумать структуру сайта. Под каждый кластер — своя страница.
- Отслеживать движение сайта в выдаче по ключевым запросам.
- Подумать над созданием продуктов, которые близки нашему бизнесу.
- Писать технические задания с ключевыми словами и вставлять их в страницу — но это уже совсем другая тема, в этой статье мы ее касаться не будем.
Заключение
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
- Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.
- Семантика помогает продумать структура сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием сео-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
- Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
- Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики и тут нужные более глубокие знания. Скорее всего, придется звать сеошника и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
- Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт. Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
- Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
- Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
- Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из Яндекс Вордстат.
- Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
- Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах. Подробности про всё SEO читайте в нашем гиде.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Семантическое ядро (СЯ) ― список запросов пользователей, который нужен для продвижения вашего сайта в поисковых сетях. В этой статье подробно разбираем, как составить СЯ, чтобы получить максимум органического трафика.
- Что такое семантическое ядро
- Шесть шагов для определения семантического ядра
- Как собрать семантическое ядро
- Ошибки при составлении семантического ядра
Что такое семантическое ядро
Семантическое ядро ― это набор слов, их форм, словосочетаний, которые относятся к деятельности (товарам, услугам) продвигаемого сайта. Семантика покажет, какой товар или услугу ищут ваши потребители и что хотят сделать ― купить, продать, отремонтировать, сравнить цены, узнать больше.
Предположим, вы продаёте товары для сада и собираете семантическое ядро для товара «Саженцы яблонь». Тогда сервис «Яндекс.Wordstat» покажет вам, какие слова вводят ваши потенциальные клиенты в поисковике, чтобы купить такие саженцы.
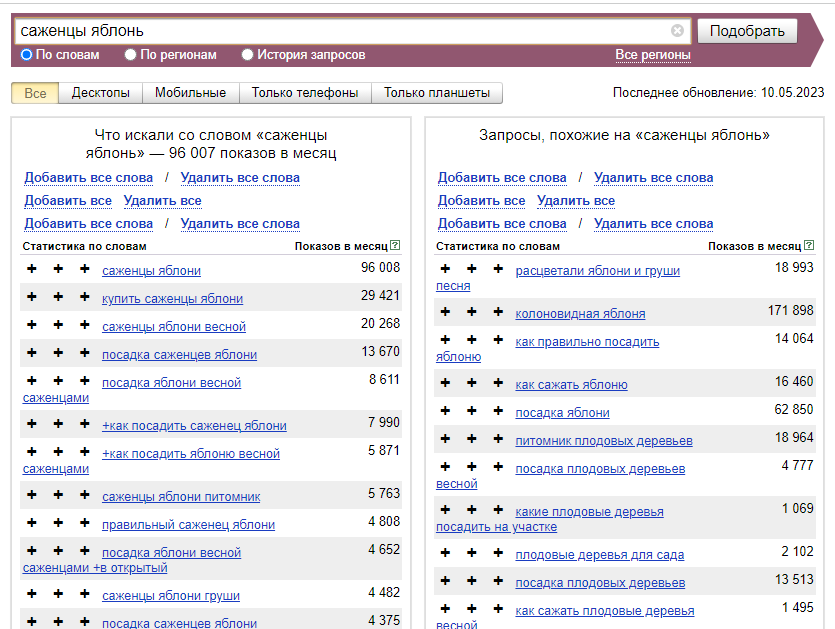
Чтобы уточнить запрос, можно кликнуть на него ― получаем расширенный перечень всех связанных запросов.
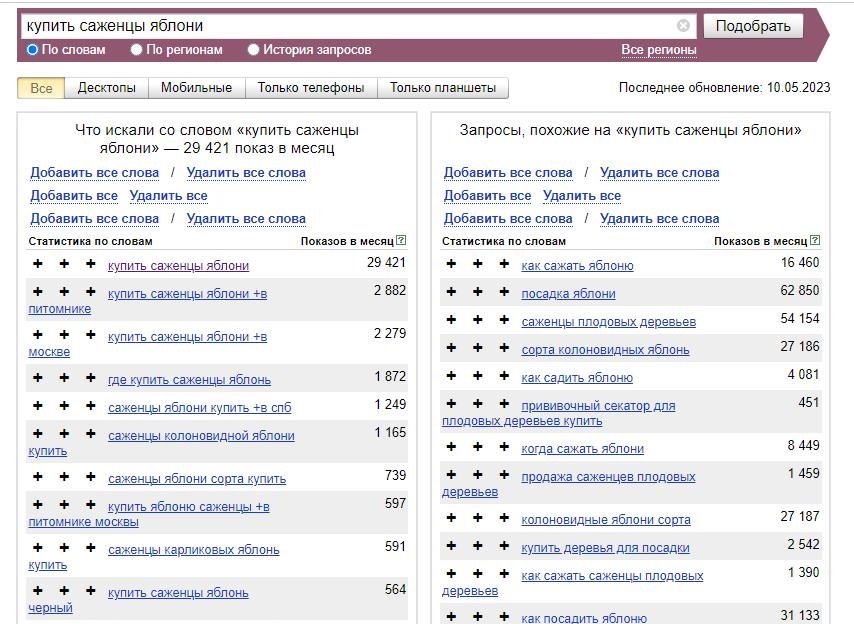
Слово «купить» говорит о цели поиска, а сопутствующие слова «колоновидной», «карликовой», «в СПб», «в питомнике Москвы» дают уточнение, где и какие именно саженцы яблонь приобретают пользователи.
Шесть шагов для определения семантического ядра
Чтобы составить семантическое ядро, надо пройти шесть этапов:
- Создать правильную структуру сайта ― разделы, страницы, удобную навигацию и для посетителей, и для самого поисковика.
- Оптимизировать страницы под определённые запросы. Например, создать релевантный текст, прописать метатеги — фрагменты текста, описывающие структуру страницы. Они важны как для поисковых систем, так и для пользователей.
- Улучшить ранжирование страниц и получить максимум целевого органического трафика, посещений потенциальных клиентов.
- Использовать полученные ключевые слова для контекстной рекламы.
- Создать матрицу контента: по запросам легко составить темы статей для блога, описания для товаров и категорий.
- Определять потребности целевой аудитории, отслеживать спрос. На основе этого корректировать продукт и ассортимент, добавлять новые услуги и вовремя реагировать на изменения.
Семантическое ядро позволяет правильно перелинковать страницы ― связать их между собой с помощью гиперссылок. Это сделает поиск информации и товаров проще для покупателя.
Как собрать семантическое ядро
Работа состоит из нескольких этапов. На основе тематики сайта собираются релевантные ключевые слова. Затем эти запросы разделяют на кластеры — о них расскажем ниже. На последнем этапе прорабатывают по кластерам каждую страницу.
Шаг 1. Собираем базу ключевых слов
Создаём таблицу, куда записываем все собранные ключевые слова с уточнениями, во всех формах. Список должен быть максимально широким.
Из каких источников можно сделать сбор запросов:
- Отчётность. Если сайт уже есть и работает, то подойдёт «Яндекс.Метрика»: в отчёте будут все слова, по которым посетители находят сайт.
- Сайты конкурентов. СЯ можно позаимствовать у 3–4 конкурентов, которые хорошо ранжируются в выдаче. Их семантику можно собрать через сервисы, затем сегментировать и очистить от нерелевантных ключей. Способ экономит время, но без вдумчивой проработки можно скопировать и ошибки конкурентов, пропустить перспективные запросы.
- Поисковая строка сайта. Собрать перспективные запросы в поисковой строке сайта (Search bar) будет актуально для сайтов с большим количеством информации, страниц, товаров.
- Собрать своими руками. Вы анализируете свой сайт, услуги и товары, цены поставщиков и ассортимент, а также запросы по тематике в «Яндекс.Wordstat». Метод небыстрый, зато надёжный, и даёт достоверную информацию для маркетинговой стратегии.
Чтобы получить точный результат, лучше собирать запросы как вручную, так и с учётом анализа конкурентов.
Для сбора фраз можно использовать такие инструменты, как «Яндекс.Wordstat» совместно с расширением Yandex Wordstat Assistant, SEMrush, Key Collector или «Мутаген».
Шаг 2. Классифицируем собранные запросы
Собранные ключи разделяются на следующие типы.
- По частотности
Высокочастотные ключи ищут чаще всего, но такие фразы не конкретизированы. Среднечастотные ― более точные, у них есть 1–2 уточняющих слова, из которых понятна потребность пользователя. Низкочастотные состоят более чем из 3 слов с конкретным запросом.

Пример: среднечастотный запрос с уточнением «в питомнике» и низкочастотные с уточнением «в питомнике Тимирязевской академии», «в питомнике Екатеринбург» Здесь вы можете отделить их по местонахождению.
Частотность для разных отраслей отличается. К примеру, ноутбуки ищут гораздо чаще, чем узкоотраслевые продукты, например, билеты на спектакли городского театра. Поэтому запросы «купить ноутбук» частотностью в 25 тысяч и «спектакли театр Новосибирск» частотой 794 ― оба среднечастотные.
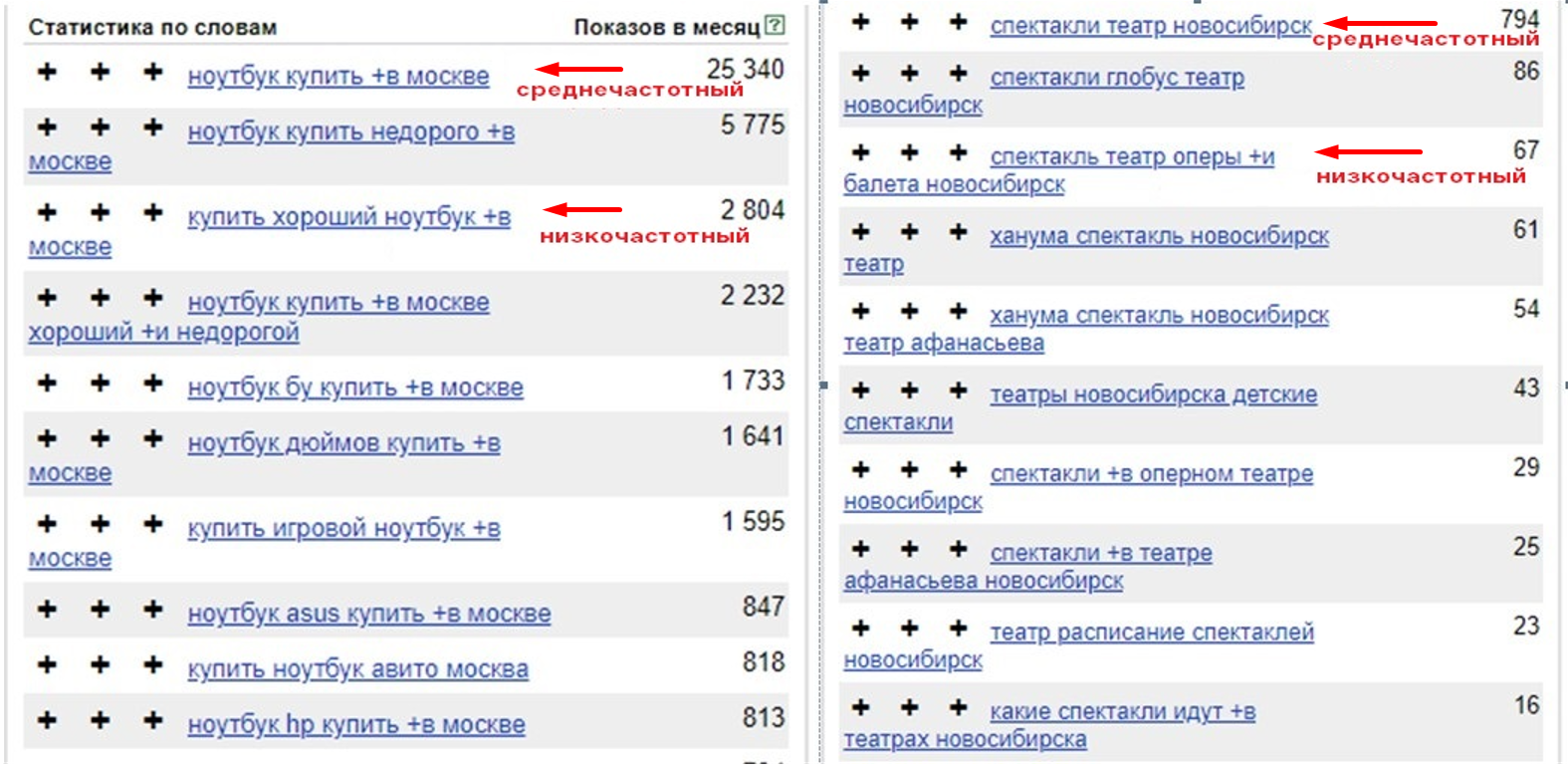
Продвигать сайт лучше по средне- и низкочастотным запросам, а высокочастотные применять для создания контента в блоге.
Чтобы использовать высокочастотные запросы, по которым продвигаются крупные компании, ваш сайт и ассортимент должны быть на одном уровне с ними. Если по запросу «саженцы яблонь» у конкурентов 500 товаров, а у вас 20, то соперничать невозможно.
- По цели ― коммерческие и информационные
Коммерческие означают, что пользователь заинтересован в сделке. Об этом говорят слова «купить», «заказать», «прайс», «цены», «недорого», указание города, места покупки. Информационные запросы говорят о том, что человек просто хочет узнать подробнее: «как выбрать», «как сделать», «википедия», «отзывы», «характеристики».
Коммерческие запросы ― обязательная часть СЯ для сайта, где продаются товары или услуги. Некоммерческие хорошо использовать для блога.
- По местоположению ― геозависимые и геонезависимые запросы
Если вы живёте в Новосибирске и запрашиваете «спектакли сегодня вечером», Яндекс и Google выдадут вам программу театров Новосибирска, а не Петербурга или Ярославля. Практически все коммерческие запросы ― геозависимы, потому что у продавца должна быть возможность доставить товар или оказать услугу.
Пример разбора ключей:
Поисковый запрос имеет тело, спецификатор и хвост.
- Тело — самый высокочастотный ключ без понятного намерения пользователя. Например, «саженцы»: неясно, что хочет человек ― купить их или посмотреть информацию.
- Спецификатор чётко показывает намерение. Например, «купить саженцы», «как выбрать саженцы».
- Хвост запроса уточняет цель: «как посадить саженцы яблони весной», «купить саженцы яблони в Москве».
Шаг 3. Очистка базы от нерелевантных запросов
Эту работу стоит сделать вручную. При отборе рассматривайте запросы не только как SEO-специалист, но и как маркетолог.
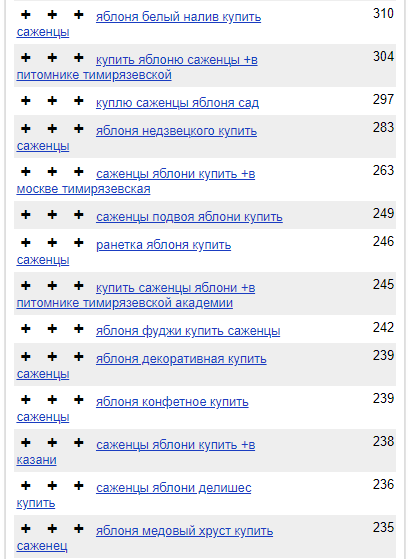
Не упускайте низкочастотные запросы ― они приведут вам хороший трафик. Если посмотреть на этот перечень как маркетолог, то можно сделать полезные выводы:
- Людям нравятся сорта яблок «Медовый хруст», «Делишес», «Конфетное», «Белый налив». Если в ассортименте их нет, желательно начать их продавать.
- Людям удобно выбирать яблони по сортам, и сорта можно поставить в фильтр. Ключи можно использовать в карточках товаров и метатегах.
Какие ключи нужно удалить из списка при подборе СЯ:
- Ключи-дубли
- Запросы с геолокацией, где вы не работаете
- Запросы с ошибками в правописании
- Запросы, на которые у вас не хватает товаров или услуг ― менее 5
- Ключи, которые не относятся к вашей тематике, которых нет среди вашего ассортимента товаров. Например, если вы интернет-магазин, а не питомник, то ключ «купить саженцы яблони в питомнике» вам не подходит.
- Пустые ключи с нулевым трафиком
Пустые запросы кажутся популярными, но по факту по ним мало показов. А значит, если вы будете оптимизировать под них страницу, то потратите много сил, но не получите результата. Пустые ключи проверяйте в Wordstat через опцию «!», как на скрине ниже:
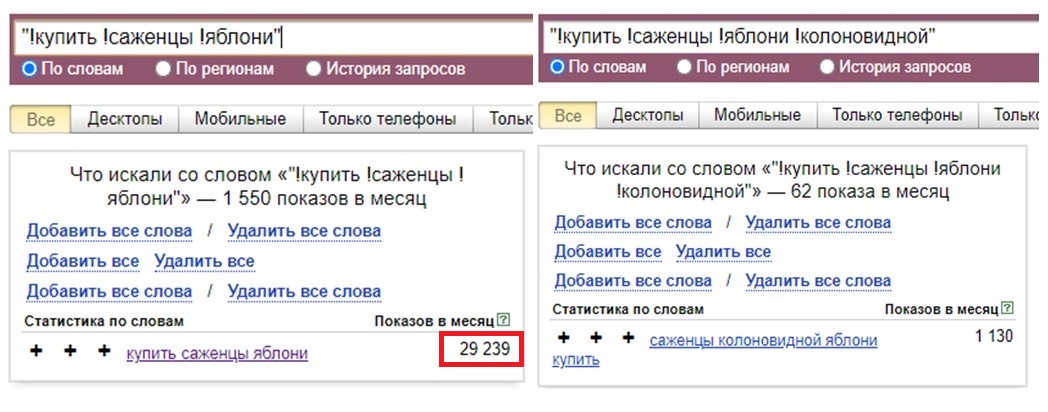
Чем выше чистый спрос, тем перспективнее ключ ― оставляем его.
Шаг 4. Кластеризация запросов: как её сделать
Кластеризация ― разбивка запросов на группы и распределение их по страницам сайта на основе выдачи поисковика и логики маркетолога. Под каждую группу подбирается страница сайта и создаётся лист в Excel-файле. Для автоматической кластеризации используйте комплексные сервисы для SEO, например сайт Мутаген.
Обязательно прочищайте каждый кластер вручную. Ошибки в автоматической кластеризации неизбежны. Сравнивайте результаты разных сервисов, потому что со 100%-й точностью ни одна программа не сможет определить, к какому кластеру относится слово.
Особенно часто автоматическая кластеризация выдаёт ошибки:
- при анализе нового ассортимента, где нет устоявшейся выдачи;
- на низкочастотных запросах;
- в узких тематиках и в региональных запросах.
Не используйте для кластеризации только топ выдачи, потому что он зависит от изменений алгоритмов Яндекса и Google: выйдет обновление, и топ поменяется. Но не группируйте запросы только на основе логики, потому что пользователи непредсказуемы.
Так, колоновидные и карликовые яблони ― это низкорослые деревья. Они выглядят похоже, но это разные виды. Помещать ли их в одну группу? Понимают ли пользователи, что это не одно и то же? Посмотрим, как разделит эти запросы сервис:
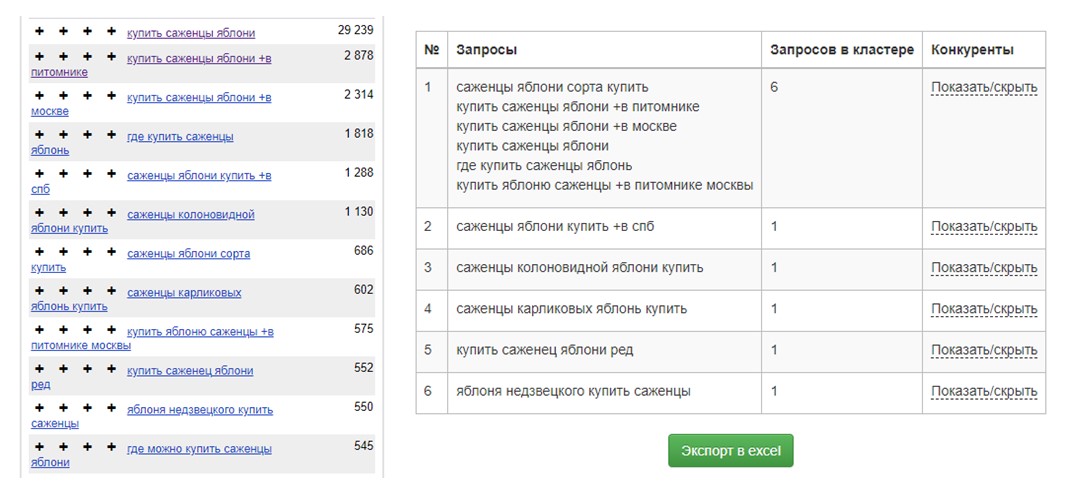
Как мы видим, колоновидные и карликовые яблони, несмотря на сходство, потребуют разных страниц ― пользователи-садоводы понимают отличия этих типов плодовых деревьев.
При кластеризации руководствуйтесь правилами:
- По одному кластеру продвигаем одну страницу, чтобы не было дублей.
- Данные на странице должны соответствовать запросу.
- Молодые и небольшие сайты продвигайте по низкочастотным и среднечастотным запросам.
Информационные запросы подходят для блога и страницы «Вопрос-ответ». Коммерческие ― для категорий и карточек товаров. Транзакционные ― для главной страницы и категорий. Навигационные ― для главной страницы.
Ошибки при составлении семантического ядра
№1. Две и более тематики (кластера) на одну страницу
Например, страница создаётся под ключ «Саженцы плодовых», но её также оптимизируют под запросы «Колоновидные саженцы плодовых». Получается несоответствие одной теме. А после этого ещё создают страницы под «Колоновидные плодовые». От таких дублей путаются и поисковые системы, и пользователи.
На каких страницах допустимо использовать несколько кластеров:
- на главной странице;
- на страницах, которые продвигаются большой ссылочной массой;
- на информационных страницах с длинными текстами;
- когда топ неконкурентный;
- когда запросы узкие.
Вывод: один запрос ― одна страница.
№2. Включение в СЯ нерелевантных и пустых запросов
Нельзя включать в СЯ слова, которые не соответствуют тематике или ассортименту бизнеса — они не принесут трафика. Например, для формирования СЯ интернет-магазинов будут нерелевантными запросы со словами «бесплатно», «скачать», «форум», «википедия».
№3. Оптимизировать без учёта потребностей целевой аудитории
При подборе ключей смотрите на запросы не только как оптимизатор, но и как маркетолог.
№4. Пренебрежение низкочастотными запросами
Соберите максимум тематических низкочастотных запросов. В совокупности они дают отличный трафик, и при этом с ними легче ранжироваться в поиске благодаря меньшей конкуренции.
№5. Нарушать работающую оптимизацию страниц
Если страница оптимизирована под запросы, которые уже приносят трафик, то важно не потерять наработанный поток посетителей. Для этого в «Яндекс.Метрике» надо посмотреть фразы, по которым оптимизирована страница, и добавить их в СЯ.
№6. Не чистить кластеры вручную
Проверяйте вручную автоматически созданные кластеры. При этом опирайтесь и на логику, и на топ выдачи.
№7. Создавать семантическое ядро раз и навсегда
Раз в 4–6 месяцев нужно обновлять СЯ. Пользователи задают новые запросы, а какие-то из прежних ключей в ядре становятся нецелевыми.