В этой статье мы познакомимся с определением архитектуры процессора и самыми распространёнными и актуальными архитектурами.
Прежде чем рассмотреть основные виды архитектур процессоров, необходимо понять, что это такое. Под архитектурой процессора обычно понимают две совершенно разные сущности.
С программной точки зрения архитектура процессора — это совместимость с определённым набором команд (Intel x86), их структуры (система адресации, набор регистров) и способа исполнения (счётчик команд).
Говоря простым языком, это способность программы, собранной для архитектуры x86, работать практически на любой x86-совместимой системе. При этом такая программа не будет работать, например, на ARM системе.
С аппаратной точки зрения архитектура процессора — это некий набор свойств и качеств, присущий целому семейству процессоров (Skylake – процессоры Intel Core 5 и 6 поколений).
Если тема кажется сложной, можно начать со статьи о том, чем CPU отличается от GPU.
Виды архитектур
В этой статье мы рассмотрим самые распространенные и актуальные архитектуры с программной точки зрения, кроме узкоспециализированных (графических, математических, тензорных).
CISC
CISC (англ. Complex Instruction Set Computer — «компьютер с полным набором команд») — тип процессорной архитектуры, в первую очередь, с нефиксированной длиной команд, а также с кодированием арифметических действий в одной команде и небольшим числом регистров, многие из которых выполняют строго определенную функцию.
Самый яркий пример CISC архитектуры — это x86 (он же IA-32) и x86_64 (он же AMD64).
В CISC процессорах одна команда может быть заменена ей аналогичной, либо группой команд, выполняющих ту же функцию. Отсюда вытекают плюсы и минусы архитектуры: высокая производительность благодаря тому, что несколько команд могут быть заменены одной аналогичной, но большая цена по сравнению с RISC процессорами из-за более сложной архитектуры, в которой многие команды сложнее раскодировать.
RISC
RISC (англ. Reduced Instruction Set Computer — «компьютер с сокращённым набором команд») — архитектура процессора, в котором быстродействие увеличивается за счёт упрощения инструкций: их декодирование становится более простым, а время выполнения — меньшим. Первые RISC-процессоры не имели даже инструкций умножения и деления и не поддерживали работу с числами с плавающей запятой.
По сравнению с CISC эта архитектура имеет константную длину команды, а также меньшее количество схожих инструкций, позволяя уменьшить итоговую цену процессора и энергопотребление, что критично для мобильного сегмента. У RISC также большее количество регистров.
Примеры RISC-архитектур: PowerPC, серия архитектур ARM (ARM7, ARM9, ARM11, Cortex).
В общем случае RISC быстрее CISC. Даже если системе RISC приходится выполнять 4 или 5 команд вместо одной, которую выполняет CISC, RISC все равно выигрывает в скорости, так как RISC-команды выполняются в 10 раз быстрее.
Отсюда возникает закономерный вопрос: почему многие всё ещё используют CISC, когда есть RISC? Всё дело в совместимости. x86_64 всё ещё лидер в desktop-сегменте только по историческим причинам. Так как старые программы работают только на x86, то и новые desktop-системы должны быть x86(_64), чтобы все старые программы и игры могли работать на новой машине.
Для Open Source это по большей части не является проблемой, так как пользователь может найти в интернете версию программы под другую архитектуру. Сделать же версию проприетарной программы под другую архитектуру может только владелец исходного кода программы.
MISC
MISC (англ. Minimal Instruction Set Computer — «компьютер с минимальным набором команд»).
Ещё более простая архитектура, используемая в первую очередь для ещё большего уменьшения итоговой цены и энергопотребления процессора. Используется в IoT-сегменте и недорогих компьютерах, например, роутерах.
Для увеличения производительности во всех вышеперечисленных архитектурах может использоваться “спекулятивное исполнение команд”. Это выполнение команды до того, как станет известно, понадобится эта команда или нет.
VLIW
VLIW (англ. Very Long Instruction Word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно.
По сути является архитектурой CISC со своим аналогом спекулятивного исполнения команд, только сама спекуляция выполняется во время компиляции, а не во время работы программы, из-за чего уязвимости Meltdown и Spectre невозможны для этих процессоров. Компиляторы для процессоров этой архитектуры сильно привязаны к конкретным процессорам. Например, в следующем поколении максимальная длина «очень длинной команды» может из условных 256 бит стать 512 бит, и тут приходится выбирать между увеличением производительности путём компиляции под новый процессор и обратной совместимостью со старым процессором. Опять же, Open Sourсe позволяет простой перекомпиляцией получить программу под конкретный процессор.
Примеры архитектуры: Intel Itanium, Эльбрус-3.
Виртуальные архитектуры
Но раз нельзя запустить программу одной архитектуры на другой, то откуда берутся магические JAR-файлы, которые можно запустить на любой машине? Это пример виртуальной JVM-архитектуры, которая, по сути, эмулируется на целевой реальной машине. Поэтому достаточно JVM-машины для целевой архитектуры для запуска на ней любой Java-программы. Другим примером виртуальной архитектуры является .NET CIL.
Из минусов виртуальных архитектур можно выделить меньшую производительность по сравнению с реальными архитектурами. Этот минус нивелируется с помощью JIT- и AOT-компиляции. Однако большим плюсом будет кроссплатформенность.
Дальнейшим развитием этих архитектур стали гибридные архитектуры. Например современные x86_64 процессоры хотя и CISC-совместимы, но являются процессорами с RISC-ядром. В таких гибридных CISC-процессорах CISC-инструкции преобразовываются в набор внутренних RISC-команд. Какое дальнейшее развитие получат архитектуры процессора, покажет только время.

Многие говорят, что разница между RISC и CISC стала несущественной. Так ли это? И если нет, то в чем разница между современными RISC и CISC процессорами?
Компания Apple выпустила процессор Apple Silicon M1, который произвел фурор. Теперь вы можете задаться вопросом, чем он отличается от процессоров Intel и AMD? Вероятно, вы слышали, что M1 — процессор с архитектурой ARM, а ARM — это RISC, в отличие от Intel и AMD.
Если вы читали про разницу между микропроцессорами RISC и CISC, то вы знаете, что множество людей утверждают об отсутствии практической разницы между ними в современном мире. Но так ли это на самом деле?
Хорошо, сейчас вы немного запутались и хотите исчерпывающих ответов. Эта статья — отличное начало.
Я разобрал сотни комментариев по этой теме и столько же написал в ответ. Некоторые из них были от инженеров, которые причастны к созданию этих микропроцессоров.
Я начну с базовых вещей, которые необходимо понять, прежде чем начать отвечать на интересующие вопросы о разнице RISC и CISC.
Вот темы, которые будут рассмотрены в данной статье:
- Что такое микропроцессор?
- Что такое архитектура набора команд (ISA)?
- Зачем выбирать ISA?
- В чем разница между наборами команд RISC и CISC?
- Философия CISC.
- Философия RISC.
- Конвейеризация.
- Архитектура Load / Store.
- Сжатый набор инструкций.
- Микрокод и микрокоманды.
- Чем отличаются микрокоманды от инструкции RISC?
- Гипертрединг (аппаратные потоки).
- Действительно ли стоит различать RISC и CISC?
Я использую данные темы в заголовках, поэтому вы можете читать только про то, что вам интересно.
Что такое микропроцессор?
Давайте сначала разберемся что такое микропроцессор. Вероятно, у вас уже есть предположения, иначе вы не открыли бы эту статью.
В общем случае процессор — это мозг компьютера. Он читает инструкции из памяти, которые указывают, что делать компьютеру. Инструкции — это просто числа, которые интерпретируются специальным образом.
В памяти нет ничего, что позволяло бы отличить обычное число от инструкции. Поэтому разработчики операционных систем должны быть уверены, что инструкции и данные лежат там, где процессор ожидает их найти.
Микропроцессоры (CPU) выполняют очень простые операции. Вот пример нескольких инструкций, которые выполняет процессор:
load r1, 150
load r2, 200
add r1, r2
store r1, 310
Это человекочитаемая форма того, что должно быть просто списком чисел для компьютера. Например, load r1, 150 в обычном RISC микропроцессоре представляется в виде 32-битного числа. Это значит, что число представлено 32 символами, каждый из которых 0 или 1.
load в первой строчке перемещает содержимое ячейки памяти 150 в регистр r1. Оперативная память компьютера (RAM) — это хранилище миллиардов чисел. Каждое число хранится по своему адресу, и так микропроцессор получает доступ к правильному числу.
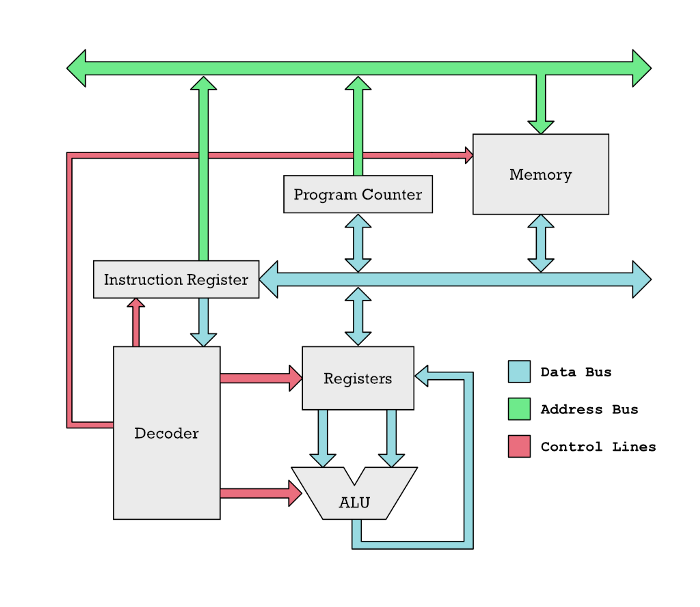
Упрощенная диаграмма операций в микропроцессоре. Инструкции помещаются в регистр инструкций, где происходит декодирование. Декодер активирует нужные части процессора и операция выполняется.
Далее вы можете заинтересоваться, что такое регистр. Эта концепция достаточно старая. Старые механические кассовые аппараты были основаны на этой концепции. В те времена регистр был чем-то вроде механического приспособления, в котором хранилось число, с которым вы хотели работать. Часто в таких аппаратах был аккумуляторный регистр, в который вы могли добавлять числа, а регистр сохранял сумму.

Арифметический калькулятор Феликс. Русский механический калькулятор. Внизу виден аккумуляторный регистр, сохранявший до тринадцати десятичных знаков. Наверху — входной регистр, вмещающий пять знаков. Слева внизу — счетный регистр.
Ваши электронные калькуляторы работают по такому же принципу. Чаще всего на дисплее отображается содержимое аккумуляторного регистра, а вы выполняете действия, которые влияют на его содержимое.
Аналогичное справедливо для микропроцессора. В нем есть множество регистров, которым даны имена — например, A, B, C или r1, r2, r3, r4 и так далее. Инструкции микропроцессора обычно производят операции над этими регистрами.
В нашем примере add r1, r2 складывает содержимое r1 и r2 и полученный результат записывает в r1.
В конце мы сохраняем полученный результат в оперативной памяти в ячейке с адресом 310 с помощью команды store r1, 310.
Что такое архитектура набора команд (ISA)?
Как вы можете представить, количество инструкций, которые понимает процессор, ограничено. Если вы знакомы с программированием, вы знаете, что можно определять собственные функции. Так вот, машинные команды не имеют такой возможности.
Существует фиксированное количество команд, которые понимает процессор. И вы как программист не можете его расширить.
В мире представлено множество различных микропроцессоров, и они не используют одинаковый набор команд. Иными словами, они интерпретируют числа в инструкции по-разному.
Одна архитектура микропроцессора трактует число 501012 как add r10, r12, а другая архитектура — как load r10, 12. Комбинация инструкций, которые понимает процессор, и регистров, которые ему доступны, называется архитектурой набора команды (Instruction Set Architecture, ISA).
Микропроцессоры, например, Intel и AMD, используют архитектуру набора команд x86. А микропроцессоры, например, A12, A13, A14 от Apple, понимают набор команд ARM. Теперь в список ARM-процессоров можно включить M1.
Это те микропроцессоры, которые мы называем Apple Silicon. Они используют архитектуру набора команд ARM, как и множество других микропроцессоров телефонов и планшетов. Даже игровые приставки, такие как Nintendo и самый быстрый суперкомпьютер, используют набор команд ARM.
Набор команд x86 и ARM не является взаимозаменяемым. Программа компилируется под определенный набор команд, если, конечно, это не JavaScript, Java, C# или что-то подобное. В этом случае программа компилируется в байт-код, который похож на набор команд для несуществующего процессора. Для запуска такого кода требуется Just-In-Time компилятор или интерпретатор, который транслирует байт-код в инструкции, понятные для микропроцессора в вашем компьютере.
Это значит, что большинство программ, доступных на Mac, не будут запускаться на Mac с M1. Программы рассчитаны на набор инструкций x86. Чтобы решить эту проблему, программы перекомпилируются с использованием нового набора инструкций. У Apple есть козырь в рукаве, который называется Rosetta 2. Это решение позволяет транслировать инструкции x86 в инструкции ARM.
Почему произошел переход на совершенно другой набор команд?
Закономерный вопрос. Зачем использовать новый набор команд для Mac? Почему Apple не могла использовать набор команд x86 в микропроцессорах Apple Silicon? Так бы отпала необходимость в перекомпиляции или трансляции с помощью Rosetta 2.
Что ж. Архитектура набора команд сильно влияет на архитектуру процессора. Использование определенной архитектуры набора команд может усложнить или упростить задачу по созданию высокопроизводительного или энергоэффективного процессора.
Второй важный момент заключается в лицензировании. Apple не может свободно создавать свои процессоры с набором команд x86. Это часть интеллектуальной собственности Intel, а Intel не хочет конкурентов. Для сравнения, компания ARM не производит собственных микропроцессоров. Они занимаются проектированием архитектуры набора команд и предоставляют эталонные образцы микропроцессоров, которые ее реализуют.
Таким образом, ARM делает то, что вы хотите. Этого хочет и Apple. Они хотят создавать собственные решения для компьютеров со специализированным оборудованием для машинного обучения, криптографии и распознавания лиц. Если вы используете x86, то вам придется делать это на внешних чипах. Из соображений эффективности Apple хочет сделать все на одной большой интегральной схеме, то есть на том, что мы называем системой на кристалле (System-On-a-Chip, SoC).
Разработка началась со смартфонов и планшетов. Эти устройства слишком маленькие и не позволяют сделать множество чипов на одной большой материнской плате. Вместо этого необходимо уместить буквально все в один чип, который содержит микропроцессор, графический ускоритель, оперативную память и другое специализированное оборудование.

Материнская плата ПК, где графический ускоритель, сетевая карта и модули памяти подключаются через разъемы. Она слишком большая для планшетов и смартфонов, которые используют систему на кристалле.
Сейчас этот тренд наблюдается в ноутбуках, а чуть позже придет и к настольным ПК. Тесная интеграция оборудования дает повышенную производительность. Также негибкая система лицензирования x86 — еще один минус.
Но давайте не будем отходить в сторону от главной темы. Архитектуры набора команд обычно следуют разным основополагающим философиям. Набор команд x86 — это то, что мы называем архитектурой CISC, в то время как архитектура ARM следует принципам RISC. В этом заключается основное различие.

Инструкции CISC могут быть любой длины. Максимальная теоретическая длина инструкции x86 может быть бесконечной, но на практике не превышает 15 байт. Инструкции RISC имеют ограниченную длину.
В чем разница между набором команд RISC и CISC?
Аббревиатура CISC обозначает Complex Instruction Set Computer, а RISC — Reduced Instruction Set Computer.
Сегодня объяснить разницу между этими наборами команд сложнее, чем во время их появления, так как в процессе развития они заимствовали идеи друг у друга. Более того, проводилась маркетинговая кампания по размытию границ между ними.
Минуем маркетинговую дезинформацию
Пол ДеМоне (Paul DeMone) написал статью в 2000 году, которая дает некоторое представление о существовавшем тогда маркетинговом давлении.
В 1987 году лучшим среди x86 был процессор Intel 386DX, а среди RISC — MIPS R2000.
Несмотря на то, что процессор Intel имеет вдвое больше транзисторов (275 000 против 115 000 у MIPS) и вдвое больше кэш-памяти, процессор x86 проигрывает во всех тестах производительности.
Оба процессора работают на частоте 16 МГц, но RISC-процессор показывал результаты в 2-4 раза лучше.
Поэтому неудивительно, что в начале 90-х распространилась идея, что процессоры RISC значительно производительнее.
У Intel возникли проблемы с восприятием на рынке. Им было сложно убедить инвесторов и покупателей в том, что процессоры на устаревшей архитектуре CISC могут быть лучше процессоров RISC.
Так Intel стала позиционировать свои процессоры как RISC с простым декодером, который превращал команды CISC в команды RISC.
Таким образом, Intel выставила себя в очень привлекательном виде. Компания заявляла, что покупатель получает технологически совершенные процессоры RISC, которые понимают знакомый многим набор команд x86.
Давайте проясним один момент. Внутри процессора x86 нет RISC-составляющей. Это просто маркетинговый ход. Боб Колвеллс (Bob Colwells), один из создателей Intel Pentium Pro с RISC-составляющей, сам говорил об этом.
Теперь вы знаете, как эта ложь распространилась по интернету, — да, Intel сделала удачный маркетинговый ход. Он сработал, потому что в нем есть доля правды. Но чтобы действительно понять разницу между RISC и CISC, вам нужно избавиться от этого мифа.
Мысль о том, что внутри CISC-процессора может быть RISC, только запутает вас.
Философия CISC
Давайте поговорим о том, что из себя представляют RISC и CISC. И то, и другое — философия того, как нужно проектировать процессоры.
Взглянем на философию CISC. Эту философию сложно определить, так как микросхемы, которые мы определяем как CISC, очень разнообразны. Однако в них можно выделить общие закономерности.
В конце 1970, когда началась разработка CISC-процессоров, память была очень дорогой. Компиляторы тоже были плохие, а люди писали на ассемблере.
Так как память была дорогой, люди искали способ минимизировать использование памяти. Одно из таких решений — использовать сложные инструкции процессора, которые делают много действий.
Это также помогло программистам на ассемблере, так как они смогли писать более простые программы, ведь всегда найдется инструкция, которая выполняет то, что нужно.
Через некоторое время это стало сложным. Проектирование декодеров для таких команд стало существенной проблемой. Изначально ее решили с помощью микрокода.
В программировании повторяющийся код выносится в отдельные подпрограммы (функции), которые можно вызывать множество раз.
Идея микрокода очень близка к этому. Для каждой инструкции из набора создается подпрограмма, которая состоит из простых инструкций и хранится в специальной памяти внутри микропроцессора.
Таким образом, процессор содержит небольшой набор простых инструкций. На их основе можно создать множество сложных инструкций из набора команд с помощью добавления подпрограмм в микрокод.
Микрокод хранится в ROM-памяти (Read-Only Memory, только для чтения), которая значительно дешевле оперативной памяти. Следовательно, уменьшение использования оперативной памяти через увеличение использования постоянной памяти — выгодный компромисс.
Какое-то время все выглядело очень хорошо. Но со временем начались проблемы, связанные с подпрограммами в микрокоде. В них появились ошибки. Исправление ошибки в микрокоде в разы сложнее, чем в обычной программе. Нельзя получить доступ к этому коду и протестировать его как обычную программу.
Разработчики стали думать, что существует другой, более простой способ справиться с этими трудностями.
Философия RISC
Оперативная память стала дешеветь, компиляторы стали лучше, а большинство разработчиков перестало писать на ассемблере.
Эти технологические изменения спровоцировали появление философии RISC.
Сперва люди анализировали программы и заметили, что большинство сложных инструкций CISC не используются большинством программистов.
Разработчики компиляторов затруднялись в выборе правильной сложной инструкции. Вместо этого они предпочли использовать комбинацию нескольких простых инструкций для решения проблемы.
Вы можете сказать, что здесь применимо правило 80/20: примерно 80% времени тратится на выполнение 20% инструкций.
Идея RISC заключается в замене сложных инструкций на комбинацию простых. Так не придется заниматься сложной отладкой микрокода. Вместо этого разработчики компилятора будут решать возникающие проблемы.
Есть разногласия в том, как понимать слово «сокращенный» (reduced) в аббревиатуре RISC. Люди думают, что сокращено количество инструкций. Но более правильная интерпретация — это уменьшение сложности команд.
RISC-код может быть непростым для человека. Много лет назад я совершил ошибку, когда решил, что самостоятельное написание ассемблерного кода для PowerPC (архитектура IBM RISC с огромным количеством инструкций) сэкономит мое время. Это принесло мне множество лишней работы и разочарований.
Одним из аргументов RISC было то, что люди перестали писать ассемблерный код, поэтому необходимо создать набор инструкций, удобный для компиляторов. Архитектура RISC оптимизирована для компиляторов, но не для людей.
Хотя есть некоторые наборы команд RISC, при использовании которых людям кажется, что они просты для изучения. С другой стороны, при использовании RISC часто нужно писать больше команд, чем в случае CISC.
Конвейеризация: инновация RISC
Еще одна основная идея RISC — это конвейеризация. Для объяснения я проведу небольшую аналогию.
Представьте процесс покупки в продуктовом магазине. Хотя этот процесс отличается от страны к стране, я расскажу на примере родной Норвегии. Действия на кассе можно разделить на несколько шагов.
- Переместить покупки на конвейерную ленту и отсканировать штрих-коды на них.
- Использовать платежный терминал для оплаты.
- Положить оплаченное в сумку.

Хорошее векторное изображение, созданное на pch.vector (источник: www.freepik.com)
Если такое происходит без конвейеризации, то следующий покупать сможет переместить вещи на ленту только после того, как текущий покупатель заберет свои покупки. Аналогичное поведение изначально встречалось в CISC-процессорах, в которых по умолчанию нет конвейеризации.
Это неэффективно, так как следующий покупатель может начать использовать ленту, пока предыдущий кладет товар в сумку. Более того, даже платежный терминал можно использовать, пока человек собирает покупки. Получается, что ресурсы используются неэффективно.
Представим, что каждое действие занимает фиксированный промежуток времени или один такт. Это значит, что обслуживание одного покупателя занимает три такта. Таким образом, за девять тактов будут обслужены три покупателя.
Подключим конвейеризацию к данному процессу. Как только я начну работать с платежным терминалом, следующий за мной покупатель начнет выкладывать продукты на ленту.
Как только я начну складывать продукты в сумку, следующий покупатель начнет работу с платежным терминалом. При этом третий покупатель начнет выкладывать покупки из корзины.
В результате каждый такт кто-то будет завершать упаковку своих покупок и выходить из магазина. Таким образом, за девять тактов можно обслужить шесть покупателей. С течением времени благодаря конвейеризации мы приблизимся к скорости обслуживания «один покупатель за такт», а это почти девятикратный прирост.
Мы можем сказать, что работа с кассой занимает три такта, но пропускная способность кассы — один покупатель в такт.
В терминологии микропроцессоров это значит, что одна инструкция выполняется три такта, но средняя пропускная способность — одна инструкция в такт.
В этом примере я сделал предположение, что обработка каждого этапа занимает одинаковое количество времени. Иными словами, перенос продуктов из корзины на ленту занимает столько же времени, сколько оплата покупок.
Если время каждого этапа сильно варьируется, то это работает не так хорошо. Например, если кто-то взял очень много продуктов и долго выкладывает их на ленту, то зона с платежным терминалом и упаковкой продуктов будет простаивать. Это негативно влияет на эффективность схемы.
Проектировщики RISC прекрасно это понимали, поэтому попытались стандартизировать время выполнения каждой инструкции. Они разделены на этапы, каждый из которых выполняется примерно одинаковое количество времени. Таким образом, ресурсы внутри микропроцессора используются по максимуму.
Если рассмотреть ARM RISC-процессор, то мы обнаружим пятиступенчатый конвейер инструкций.
- (Fetch) Извлечение инструкции из памяти и увеличение счетчика команд, чтобы извлечь следующую инструкцию в следующем такте.
- (Decode) Декодирование инструкции — определение, что эта инструкция делает. То есть активация необходимых для выполнения этой инструкции частей микропроцессора.
- (Execute) Выполнение включает использование арифметико-логического устройства (АЛУ) или совершение сдвиговых операций.
- (Memory) Доступ к памяти, если необходимо. Это то, что делает инструкция load.
- (Write Back) Запись результатов в соответствующий регистр.
Инструкции ARM состоят из секций, каждая из которых работает с одним из этих этапов, а выполнение этапа обычно занимает один такт. То есть инструкции ARM очень удобно конвейеризировать.
Более того, каждая инструкция имеет одинаковый размер, то есть этап Fetch знает, где будет располагаться следующая инструкция, и ему не нужно проводить декодирование.
С инструкциями CISC все не так просто. Они могут быть разной длины. То есть без декодирования фрагмента инструкции нельзя узнать ее размер и где располагается следующая инструкция.
Вторая проблема CISC — сложность инструкций. Многократный доступ к памяти и выполнение множества вещей не позволяют легко разделить инструкцию CISC на отдельные части, которые можно выполнять поэтапно.
Конвейеризация — это особенность, которая позволила первым RISC-процессорам на голову обогнать своих конкурентов в тестах производительности.

Складской робот как аналогия для конвейеризации. Использовалась в одной из моих новых статей.
В качестве альтернативного объяснения конвейеризации я написал историю, построенную на аналогии со складским роботом: Why Pipeline a Microprocessor?
Архитектура Load / Store
Чтобы количество тактов, необходимых для каждой инструкции, было примерно одинаковым и удобным для конвейеризации, набор инструкций RISC четко отделяет загрузку из памяти и сохранение в память от остальных инструкций.
Например, в CISC может существовать инструкция, которая загружает данные из памяти, производит сложение, умножение, что-нибудь еще и записывает результат обратно в память.
В мире RISC такого быть не может. Операции типа сложения, сдвига и умножения выполняются только с регистрами. Они не имеют доступа к памяти.
Это очень важный момент для конвейеризации. Иначе инструкции в конвейере могут зависеть друг от друга.
Большое количество регистров
Большая проблема для RISC — это упрощение инструкций, что ведет к увеличению их количества. Больше инструкций требуют больше памяти — недорогой, но медленной. Если программа RISC потребляет больше памяти, чем программа CISC, то она будет медленнее, так как процессор будет постоянно ждать медленного чтения из памяти.
Проектировщики RISC сделали несколько наблюдений, которые позволили решить эту проблему. Они заметили, что множество инструкций перемещают данные между памятью и регистрами, чтобы подготовиться к выполнению. Имея большое количество регистров, они смогли сократить количество обращений к памяти.
Это потребовало улучшений в компиляторах. Компиляторы должны хорошо анализировать программы, чтобы понимать, когда переменные можно хранить в регистре, а когда их стоит записать в память. Работа с множеством регистров стала важной задачей для компиляторов, позволяющей ускорить работу на RISC-процессорах.
Инструкции в RISC проще. В них нет большого количества разных режимов адресации, поэтому, например, среди 32-битных команд есть больше бит, чтобы указать номер регистра.
Это очень важно. В процессоре с легкостью могут разместиться сотни регистров. Это не так сложно и не требует большого количества транзисторов. Проблема заключается в недостатке бит, указывающих адрес регистра. Так, например, в x86 есть только 3 бита для указания регистра. Это дает нам всего 23 = 8 регистров. Процессоры RISC экономят биты из-за меньшего количества способов адресации. Таким образом, для адресации используется 5 бит, что дает 25 = 32 регистра. Очевидно, что это пример и значения могут отличаться, но тенденция сохраняется.
Сжатый набор инструкций
Сжатый набор инструкций — это относительно новая идея для мира RISC, созданная для решения проблемы большого потребления памяти, с которой не сталкиваются CISC-процессоры.
Поскольку эта идея нова, то ARM пришлось модернизировать ее под существующую архитектуру. А вот современный RISC-V специально проектировался под сжатый набор инструкций и потому поддерживает их с самого начала.
Это несколько переработанная идея CISC, так как CISC инструкции могут быть как очень короткими, так и очень длинными.
Процессоры RISC не могут добавить короткие инструкции, так как это усложняет работу конвейеров. Вместо этого проектировщики решили использовать сжатые инструкции.
Это означает, что подмножество наиболее часто используемых 32-битных инструкций помещается в 16-битные инструкции. Таким образом, когда процессор выбирает инструкцию, он может выбрать две инструкции.
Так, например, в RISC-V есть специальный «флаг», который обозначает, сжатая это инструкция или нет. Если инструкция сжатая, то она будет разобрана в две отдельные 32-битные инструкции.
Это интересный момент, так как вся остальная часть микропроцессора работает как обычно. На вход подаются привычные однородные 32-битные инструкции, и все остальное работает предсказуемо.
Следовательно, сжатые инструкции не добавляют никаких новых инструкций. Использование этой функции в значительной степени зависит от умных сборщиков и компиляторов. Сжатая инструкция использует меньше битов и, следовательно, не может выполнять все вариации того, что может делать обычная 32-битная инструкция.
Более того, сжатая инструкция имеет доступ только к 8 наиболее используемым регистрам, а не ко всем 32. Также я не смогу загрузить константы с большим числом или с большим адресом в памяти.
Таким образом, компилятор или сборщик должен решить, стоит ли упаковывать конкретную пару инструкций вместе или нет. Сборщик должен искать возможности для выполнения сжатия.
Хотя это все выглядит как CISC, это не он. Большая часть микропроцессора, конвейер команд и прочее используют 32-битные инструкции.
В ARM вам даже нужно переключать режим для выполнения сжатых инструкций. Сжатый набор инструкций на ARM называется Thumb. Это тоже сильно отличается от CISC. Вы не будете инициировать изменение режима для выполнения одной короткой инструкции.
Сжатые наборы инструкций изменили положение дел. Некоторые варианты RISC используют меньше байт, чем те же программы на x86.
Большие кэши
Кэши — это специальная форма очень быстрой памяти, которая располагается на микросхеме процессора. Они занимают дорогостоящую кремниевую площадь, необходимую процессору, поэтому есть ограничения по размеру кэшей.
Идея кэширования заключается в том, что большинство программ запускают небольшую часть себя гораздо чаще, чем остальную часть. Часто небольшие части программы повторяются бесчисленное количество раз, например, в случае циклов.
Следовательно, если поместить наиболее часто используемые части программы в кэш, то можно добиться значительного прироста скорости.
Это была ранняя стратегия RISC, когда программы для RISC занимали больше места, чем программы для CISC. Поскольку процессоры RISC были проще, для их реализации требовалось меньше транзисторов. Это оставляло больше кремниевой площади, которую можно было потратить на другие вещи, например, для кэшей.
Таким образом, имея большие кэши, процессоры RISC компенсировали то, что их программы больше, чем программы CISC.
Однако со сжатием инструкций это уже не так.
CISC наносит ответный удар — микрооперации
Конечно, CISC не сидел сложа руки и не ждал, когда RISC его повергнет. Intel и AMD разработали собственные стратегии по эмуляции хороших решений RISC.
В частности, они искали способ конвейеризации инструкций, который никогда не работал с традиционными инструкциями CISC.
Было принято решение сделать внутренности CISC-процессора более RISC-похожими. Способ, которым это было достигнуто, — разбиение CISC-инструкции на более простые, названные микрооперациями.
Микрооперации, как инструкции RISC, легко конвейеризировать, потому что у них меньше зависимостей между друг другом и они выполняются за предсказуемое количество тактов.
Мое иллюстрированное руководство по микрооперациям: What the Heck is a Micro-Operation?
В чем различие микроопераций и микрокода?
Микрокод — это маленькие программы в ROM-памяти, которые выполняются для имитации сложной инструкции. В отличие от микроопераций их нельзя конвейеризировать. Они не созданы для этого.
На самом деле микрокод и микрооперации существуют бок о бок. В процессоре, который использует микрооперации, программы микрокода будут использоваться для генерации серии микроопераций, которые помещаются в конвейер для последующего выполнения.
Имейте в виду, что микрокод в традиционном CISC-процессоре должен производить декодирование и выполнение. По мере выполнения микрокод берет под свой контроль различные ресурсы процессора, такие как АЛУ, регистры и так далее.
В современных CISC микрокод выполнит работу быстрее, потому что не использует ресурсов процессора. Он используется просто для генерации последовательности микроопераций.
Как микрооперации отличаются от RISC-инструкций
Это самое распространенное заблуждение. Люди думают, что микрооперации — это то же самое, что и RISC-инструкции. Но это не так.
Инструкции RISC существуют на уровне набора команд. Это то, с чем работают компиляторы. Они думают о том, что вы хотите сделать, а мы пытаемся оптимизировать это.
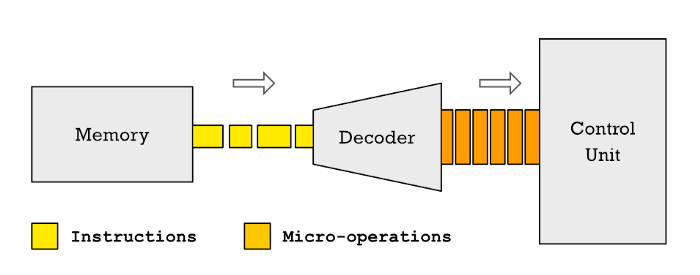
Инструкции прибывают из памяти, обычно из высокоскоростного кэша. Далее они входят в декодер, который разбивает каждую инструкцию на одну или несколько микроопераций. Хотя они выполняют меньше одной инструкции, они значительно больше.
Микрооперация — это нечто совершенно иное. Микрооперации, как правило, большие. Они могут быть больше 100 бит. Неважно, насколько они большие, потому что они существуют временно. Это различает их от инструкций RISC, которые составляют программы и могут занимать гигабайты памяти. Инструкции не могут быть сколь угодно большими.
Микрооперации специфичны для каждой модели процессора. Каждый бит указывает часть процессора, которую необходимо включить или выключить при исполнении.
В общем случае нет необходимости в декодировании, если можно сделать большую инструкцию. Каждый бит отвечает за определенный ресурс в процессоре.
Таким образом, разные процессоры с одинаковым набором команд будут иметь разные микрокоды.
Фактически многие высокопроизводительные RISC-процессоры превращают инструкции в микрооперации. Это потому что микрооперации даже проще, чем инструкции RISC. Но использование микроопераций не является обязательным. Процессор ARM с меньшей производительностью может не использовать микрооперации, а процессор с более высокой производительностью и теми же инструкциями может использовать.
Преимущество RISC существует до сих пор. Набор инструкций CISC не проектировался для конвейеризации. Следовательно, разбиение этих инструкций на микрооперации — сложная задача, которая не всегда решается эффективно. Перевод инструкций RISC в микрооперации обычно бывает более простым.
Фактически некоторые RISC-процессоры используют микрокод для некоторых инструкций, как CISC-процессоры. Одним из таких примеров является сохранение и восстановление состояния регистров при вызове подпрограмм. Когда одна программа переходит к другой подпрограмме для выполнения задачи, эта подпрограмма будет использовать некоторые регистры для локальных вычислений. Код, вызывающий подпрограмму, не хочет, чтобы его данные в регистрах изменялись случайным образом, поэтому он должен их сохранить в памяти.
Это настолько частое явление, что добавление конкретной инструкции для сохранения нескольких регистров в память было слишком заманчивым. В противном случае эти инструкции могут съесть много памяти. Поскольку это предполагает многократный доступ к памяти, имеет смысл добавить это как программу микрокода.
Однако не все RISC процессоры делают это. Например, RISC-V пытается быть более «чистым» и не имеет специальной инструкции для этого. Команды RISC-V оптимизированы для конвейеризации. Более строгое следование философии RISC делает конвейеризацию более эффективной.
Гипертрединг (аппаратные потоки)
Еще один трюк, который используется CISC, — это гипертрединг.
Напомню, что микрооперации непростые. Конвейер команд не будет заполнен полностью на постоянной основе, как у RISC.
Поэтому используется трюк под названием гипертрединг. Процессор CISC берет несколько потоков инструкций. Каждый поток инструкций разбивается на части и конвертируется в микрооперации.
Поскольку этот процесс несовершенен, вы получите ряд пробелов в конвейере. Но, имея дополнительный поток инструкций, вы можете поместить в эти промежутки другие микрооперации и таким образом заполнить конвейер.
Эта стратегия актуальна и для RISC-процессоров, потому что не каждая инструкция может исполняться каждый такт. Доступ к памяти, например, занимает больше времени. Аналогично для сохранения и восстановления регистров с помощью сложной инструкции, которую предоставляют некоторые RISC-процессоры. В коде также есть переходы, которые вызывают пробелы в конвейере.
Следовательно, более продвинутые и производительные процессоры RISC, такие как IBM POWER, тоже будут использовать аппаратные потоки.
В моем понимании трюк с гипертредингом более выгоден для процессоров CISC. Создание микроопераций — менее идеальный процесс, и он создает больше пробелов в конвейере, следовательно, гипертрединг дает больший прирост производительности.
Если ваш конвейер всегда заполнен, то от гипертрединга/аппаратных потоков нет никакой пользы.
Аппаратные потоки могут представлять угрозу безопасности. Intel столкнулась с проблемами безопасности, потому что один поток инструкций может влиять на другой. Я не знаю подробностей, но некоторые производители предпочитают отключать аппаратные потоки по этой причине.
Как правило, аппаратные потоки дают примерно 20% прирост производительности. То есть процессор с 5 ядрами и гипертредингом будет приблизительно похож на процессор с 6 ядрами без него. Но данное значение зависит во многом от архитектуры процессора.
В любом случае, это одна из причин, почему ряд производителей высокопроизводительных чипов ARM, таких как Ampere, выпускают 80-ядерный процессор без гипертрединга. Более того, я не уверен, что хоть какой-то процессор ARM использует аппаратные потоки.
Процессор Ampere используется в дата-центрах, где важна безопасность.
Действительно ли стоит различать RISC и CISC?
Да, в основе лежат принципиально разные философии. Это не так важно для высокопроизводительных чипов, поскольку у них такое же большое количество транзисторов и сложность разделения инструкций x86 затмевается всем остальным.
Однако эти чипы выглядит по-разному, и к ним необходим разный подход.
Некоторые характеристики RISC больше не имеют особого смысла. Наборы инструкций RISC не обязательно малы. Хотя это во многом зависит от того, как вы считаете.
Взгляд на RISC-V может дать хорошее представление о разнице. RISC-V основан на идее адаптировать создание конкретных микросхем с возможностью выбирать, какие расширения набора команд будут использоваться.
Тем не менее, все еще существует минимальный набор основных инструкций, и это очень похоже на RISC:
- фиксированный размер инструкции;
- инструкции разработаны для использования определенных частей процессора и оптимизированы для конвейерной обработки;
- архитектура Load/Store. Большинство инструкций работают с регистрами. Работа с памятью производится в основном с помощью специальных инструкций, созданных исключительно для этого;
- множество регистров, чтобы избежать частого доступа к памяти.
Для сравнения, инструкции CISC могут быть переменной длины. Люди могут спорить, что микрооперации — это стиль RISC, но микрокод — это деталь реализации, близкая к аппаратной.
Одна из ключевых идей RISC — переложить тяжелую работу на компилятор. Это все еще так. Компилятор не может преобразовать микрооперации для оптимального выполнения.
Время наиболее критично при выполнении микроопераций, чем при компиляции. Это очевидное преимущество, которое позволяет передовым компиляторам перестраивать код вместо того, чтобы полагаться на драгоценный кремний.
Хотя процессоры RISC с годами получили более специализированные инструкции, например, для векторной обработки, у них по-прежнему нет сложности с множеством режимов доступа к памяти как у CISC.
Источники и дополнительное чтение
Источники для этой статья я указывал в предыдущей статье.
Также отмечу следующие источники:
- RISC vs. CISC Still Matters от Paul DeMone.
- Instruction Set Architecture.
- RISC.
- Intel 8086.
- On ARM Performance от Xavier Tobin.
- RISC-V compressed instruction set format.
- Видеопрезентация того, как хорошо работает сжатый набор инструкций в RISC-V.
- Классическая конвейеризация RISC. Более подробно рассказывается о том, как наборы инструкций RISC разработаны для работы с конвейерами. Что делается на каждом этапе и так далее.
- Status Register. Я не обсуждал эту тему, но мне интересно узнать больше о компромиссах для различных версий RISC и конвейерной обработки. Многие процессоры RISC, например, не имеют «флагов» состояния для арифметических операций, только «флаг» общего назначения.
- Why Is Apple’s M1 Chip So Fast?
- Learn Assembly Programming the Fun Way
- Random Facts About ARM, x86, RISC-V, AVR and MIPS Microprocessors

Аббревиатура «RISC», от английского — reduced instruction set computer, переводится на русский как «сокращенное (ограниченное) число команд (инструкций)».
Очень часто в каталогах продукции различных производителей можно встретить название раздела или описание товара с указанием «на базе RISC». Данное заявление не относится к описанию каких-либо особых функций или характеристик оборудования. Оно связано только с одним из важнейших элементов любой ЭВМ, ее «вычислительным сердцем», без которого, не может функционировать ни один компьютер в мире. Указывая «RISC», производитель подразумевает только одно – процессор.
Свое начало «RISC» архитектура процессоров берет в середине 70-х – 80-х годов. Исследователями того времени, в частности представители IT-гиганта IBM, было выяснено, что большинство комбинаций команд и прямых методов адресации, не были задействованы использовавшимися в то время компиляторами («сборщики» исходного программного кода высокого уровня в программу на машинном языке, «понятную» компьютеру). Кроме того, было обнаружено, что программы, реализующие набор инструкций актуальных процессоров, зачастую обрабатывают сложные операции значительнее медленнее простых, выполняющие те же действия. Основная проблема заключалась в общей оптимизации микрокода процессора. Для решения простых задач процессоры того времени представляли из себя слишком сложные устройства, содержащие в себе большое количество инструкций, половина которых, могла даже быть не задействована. Соответственно, обработка всех инструкций сказывалась и на общей производительности процессора. Учтя все минусы современных процессоров того времени, было принято решение о разработке новой архитектуры. Основной фокус – сделать инструкции процессора настолько простыми, чтобы они легко и эффективно конвейеризировались (технология организации вычислений в процессорах и контроллерах). После нескольких лет исследований, в начале 80-х годов, было выпущено несколько видов процессоров, общее название которых и дало имя всей архитектуры – RISC. Своим созданием новая архитектура обязана американскому инженеру Дэвиду Паттерсону, руководителю проекта Berkeley RISC с 1980 по 1984 годы. В рамках данного проекта были разработаны дебютные процессоры новой архитектуры — RISC I и RISC II.

Профессора кафедры «Электротехника и компьютерные науки (EECS)» калифорнийского университета в Беркли, слева направо, Дэвид Паттерсон и Карло Секин. Участники проекта «Berkeley RISC». (ссылка на источник)
CISC и RISC процессоры. Характерные отличия, преимущества и недостатки
Все процессоры в мире, условно можно поделить на два типа – RISC, о нем уже было ранее сказано, и CISC. Что же такое CISC-процессор? Аббревиатура «CISC», от английского complete instruction set computing, переводится как «полный набор команд (инструкций)».
Главные особенности, определяющие архитектуру CISC:
- большое количество различных по длине и формату команд, выполняемых за несколько тактов центрального процессор
- управление с помощью программируемой логики (кодировка инструкций)
- преобладание двухадресной адресации и развитый механизм адресации операндов (переменная, над которой производят операции в коде)
CISC-процессоры являются так называемыми «классическими» процессорами. Они содержат в сотни раз больше команд, чем RISC-архитектура, используют больше способов адресации и т.д. На рубеже 80—90-ых в мире разгорелся настоящий «жаркий» спор, о том, какой же процессор лучше? С одной стороны баррикад, поставщики процессоров RISC — Hewlett-Packard (PA-RISC), Sun Microsystems Computers (SPARC), Silicon Graphics (MIPS) (R210000), союз IBM и Motorola (PowerPC), с другой – Intel и AMD. И решение было найдено не в технических аргументах сторон, а в технологическом преимуществе Intel и AMD. Но, с начала 2000-х, с момента появления мобильных решений и стремительного скачка развития в этом сегменте технологий, архитектура RISC обрела новую жизнь. Кроме того, во многих современных процессорах CISC, отдельные блоки и модули инструкций, представляют из себя, не что иное как RISC-процессор.
Наглядное сравнение процессоров CISС и RISC архитектур. CISC – массивный, мощный Кадиллак с эффектными спойлерами. RISC – быстрый, маневренный, компактный Porsche. (Из выступления Дэвида Паттерсона в 1985 году,ссылка).
В данной части мы не будем подробно рассматривать технические характеристики процессоров RISC, основные принципы построения архитектуры, алгоритмы логики и т.д. На данную тему, в просторах интернета, можно найти множество различных статей, как в англоязычном, так и в русскоязычном сегменте. Нас же, в первую очередь интересует вопрос – «Что получит обычный пользователь, приобретая оборудования на базе архитектуры RISС процессора?». Именно этот вопрос, послужит основным тезисом при разборе преимуществ и недостатков далее.
Преимущества
- Главное, и, пожалуй, основополагающее преимущество при выборе оборудование на базе процессора RISC — цена. Связано это в первую очередь с тем, что наборы инструкций RISC-процессоров просты и соответственно, для их выполнения, нужно меньшее количество логических элементов, что в конечном счете влияет на итоговую стоимость процессора. Кроме того, производство RISC-процессоров не требует сложных технологических процессоров, по сравнению с CISC, и занимает гораздо меньше времени.
- Общее быстродействие процессора. Связано это в первую очередь с небольшим числом команд, форматов, режимов и т.д., что ведет к упрощению схемы декодирования, и оно происходит быстрее.
- Использование семейства операционных систем Linux. Можно сказать, что оборудование на базе процессора RISC является идеальным для установки операционных систем Linux. Мощный рывок в развитии, особенно за последние несколько лет, RISC-подобные процессоры получили благодаря использованию открытого программного обеспечения, которое в дальнейшем раскрылось в использование различных дистрибутивов под разные задачи и от разных разработчиков. Любой производитель оборудования на RISC-процессоре, как правило может предоставить все необходимые драйвера, даже под несколько дистрибутивов. По запросу также есть возможность получить SDK (software development kit) набор.
К сожалению, недостатки RISC процессоров, тесно связаны с их преимуществами.
Недостатки
- Недостаточная производительность и функциональность. К сожалению, да, несмотря на свое быстродействие, процессоры RISC не предназначены для решения сложных и трудоемких задач. Для обработки больших массивов данных, сложной графической информации, развертывания виртуальных сред и т.д., оборудование на базе RISC-процессора не подходит.
- Большая часть программного обеспечения, сегодня написана под процессоры Intel и AMD, соответственно для работы с архитектурой RISC, оно должно быть перекомпилировано или переписано заново, что часто создает определенные сложности, а порой и просто невыполнимость задачи.
- Сокращенное число команд в архитектуре RISC, создает ситуации, когда на выполнение нескольких функций, приходится тратить несколько команд, в отличие от одной в архитектуре CISC. Это удлиняет не только код программы, но и увеличивает трафик команд между памятью и центральным процессором. Проводимые исследования показатели, что в среднем, длина кода программы в архитектуре RISC на 30% больше, чем аналогичной программы в CISC.

Простой пример сравнения СISC-кода и RISC-кода.
Основные RISC-процессоры. Что применяют в промышленности?
Как уже упоминалось выше, на сегодняшний день, RISС-подобные процессоры активно развиваются в своем сегменте рынка. Большую часть этого сегмента, 80%-90% занимают процессоры для товары широкого потребления. Конечно же, это различные смартфоны, планшетные компьютеры, игровые приставки и т.д. Любое мобильное устройство, где необходимо использование процессора, с вероятностью 90% построено на вычислительной мощности RISC-подобного процессора. Но, возможно Вы об этом не слышали и сам термин «RISC-подобный» вызывает дополнительные вопросы. Неоднократно в данной статье говорилось о RISC-подобных процессорах, что же это такое? RISC-подобные процессоры – это процессоры, в базисе архитектуры которых, были заложены основные идеи при разработке первых RISC процессоров, но в дальнейшем, приобретали свои уникальные свойства, особенности и развивались уже собственным путем. Инженеры-разработчики данных процессоров, черпали вдохновение именно из идей проекта «Berkeley RISC». Самые известные архитектуры RISC-подобных процессоров это ARM, MIPS, SPARK. Но конечно же есть и другие, менее распространённые, либо применяемые только в специализированных сферах, такие как – SuperH (SH), PowerPC, AVR и другие. Даже Intel и AMD разработали некогда свою собственную архитектуру на RISC-ядре – Intel P5/P6 и AMD K5/K6/K7. Но, стоит сказать об интересной особенности, данные компании занимаются лишь проектированием и лицензированием микропроцессорных устройств, но своих производственных мощностей не имеют. Например, лицензиатами архитектуры ARM, являются такие известные мировые производителя как AMD, Apple, Samsung, Qualcomm, Sony, HiSilicon и многие другие. Соответственно, такие современные процессоры как Snapdragon 865, Kirin 980, Samsung Exynos Octa 990 и Apple A12Z, разработаны на ARM-микропроцессоре. Самые известные производители, использующие в своих процессорах MIPS архитектуру, это Realtek, Broadcom, Atheros, ATI, Toshiba и российская компания «Т-Платформа», использующий процессорные ядра P5600 архитектуры MIPS32 Release 5 в процессоре Baikal-T1. Как мы можем увидеть, рынок RISC-подобных процессоров в массовом сегменте достаточно широкий, и можно найти решения отвечающее любым задач, но как обстоят дела в промышленном сегменте?
Особенности промышленных компьютеров RISC
Развитие RISC-подобных процессоров в промышленной отрасли отличается от массового рынка. В первую очередь это связано с не таким огромным спросом на устройства с данным типом процессора. Если у производителя есть возможности, он может реализовать в своем устройстве уже готовое процессорное ядро от стороннего разработчика и в дальнейшем просто оптимизировать под него программное обеспечение. Чаще всего так и происходит и самые распространённым для применения процессором в данном контексте является Cortex, являющийся процессором ARM архитектуры от разработчика ARM Holdings. Более сложный путь, иметь собственный процессор, развитие и разработка которого полностью зависят от самого производителя. Одним из таких производителей является компания DMP, которая выпускает процессоры собственной линейки под названием Vortex86. Процессоры серии Vortex86 являются процессорами так называемой «системой на кристалле» (от. System-on-a-Chip, SoC), т.е. один чип включающий в себя CPU, North Bridge и South Bridge.
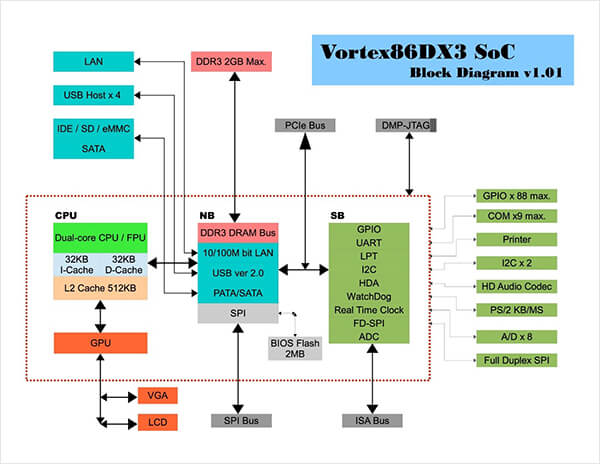
Блок-диаграмма процессора Vortex86DX3.
На базе данного семейства процессоров подразделение производителя DMP, компанияiCOP, разрабатывает и выпускает промышленное оборудование различного форм-фактора. У компании есть три основные линейки, каждая из которых включает различные варианты конфигураций и функционала для задач любой сложности.
Так какие же основные преимущества у промышленных компьютеров на базе процессоров RISC? Перечислим их по пунктам:
- Цена. Стоимость промышленного вычислительного оборудования в основе которого лежит RISC-подобный процессор, всегда будет ниже по сравнению с аналогичным оборудованием, но на базе процессоров Intel или AMD. Основные доводы были проведены нами ранее. В этом случае нет зависимости массовый это сегмент или промышленный.
- Долгий уровень поддержки. Это означает то, что производитель RISC-подобного процессора не зависит от решений мировых корпораций и тенденций на массовом рынке. Производитель смотрит только на промышленный сегмент и может даже руководствоваться необходимыми рамками производства той или иной модели процессора, в условиях применения исключительно только в одном проекте. Да, в таком случае, это должен быть довольно крупный проект, но решение принимается индивидуально в процессе общения с конечным пользователем. Срок такой поддержки может достигать 15-20 лет.
- Поддержка работы в экстремально низких температурах. Это одно из главных преимуществ RISC-подобных процессоров в промышленности. За счет своей достаточной производительности, низкого тепловыделения и архитектуры, оборудование на базе RISС-подобных процессоров поддерживает и проще адаптируется к работе при низких минусовых температурах.
- Свобода разработки программного обеспечения с поддержкой производителя процессора. Если планируется использовать ОС на базе любого дистрибутива Linux, то адаптировать программное обеспечение под RISC-подобный процессор намного проще из-за простых наборов инструкций, выполнение которых происходит достаточно быстро. Дополним это преимущество и возможностью писать программы для Linux почти на любом языке программирования, начиная от Java и Python и заканчивая С++.
- Гибкая конфигурация и разработка решений под ключ. Можно сказать, это основный интерес производителей RISC-подобных процессоров, предлагать не стандартные решения, а уникальные и зачастую разработанные специально под какие-то специализированные нужды. Даже на базе, например какой-либо стандартной платы, в основе которой лежит процессор Vortex86, производитель готов создать устройство только с необходимыми заказчику функциями.
Особенности промышленных компьютеров RISC
С момента своего появления и до сегодняшних дней, эволюция процессоров RISC сделала гигантский скачок вперед и запас потенциала их дальнейшего развития еще очень и очень велик. С появления узкоспециализированных процессоров в рамках закрытых научных программ до базовой вычислительной основы миллионов устройств по всему миру, кажется, прошло совсем немного времени, но данный промежуток ярко показывает насколько это была гениальная инженерная мысль с последующим ее огромным влиянием на развитие всей IT-индустрии.
Источник: https://ipc2u.ru/articles/prostye-resheniya/ne-khotite-riscovat-uznayte-bolshe-o-protsessorakh-arkhitektury-risc/

In computer science, a reduced instruction set computer (RISC) is a computer architecture designed to simplify the individual instructions given to the computer to accomplish tasks. Compared to the instructions given to a complex instruction set computer (CISC), a RISC computer might require more instructions (more code) in order to accomplish a task because the individual instructions are written in simpler code. The goal is to offset the need to process more instructions by increasing the speed of each instruction, in particular by implementing an instruction pipeline, which may be simpler to achieve given simpler instructions.[1]
The key operational concept of the RISC computer is that each instruction performs only one function (e.g. copy a value from memory to a register). The RISC computer usually has many (16 or 32) high-speed, general-purpose registers with a load–store architecture in which the code for the register-register instructions (for performing arithmetic and tests) are separate from the instructions that grant access to the main memory of the computer. The design of the CPU allows RISC computers few simple addressing modes[2] and predictable instruction times that simplify design of the system as a whole.
The conceptual developments of the RISC computer architecture began with the IBM 801 project in the late 1970s, but these were not immediately put into use. Designers in California picked up the 801 concepts in two seminal projects, Stanford MIPS and Berkeley RISC. These were commercialized in the 1980s as the MIPS and SPARC systems. IBM eventually produced RISC designs based on further work on the 801 concept, the IBM POWER architecture, PowerPC, and Power ISA. As the projects matured, many similar designs, produced in the late 1980s and early 1990s, created the central processing units that increased the commercial utility of the Unix workstation and of embedded processors in the laser printer, the router, and similar products.
In the minicomputer market, companies that included Celerity Computing, Pyramid Technology, and Ridge Computers began offering systems designed according to RISC or RISC-like principles in the early 1980s.[3][4][5][6][7] Few of these designs began by using RISC microprocessors.
The varieties of RISC processor design include the ARC processor, DEC Alpha, the AMD Am29000, the ARM architecture, the Atmel AVR, Blackfin, Intel i860, Intel i960, LoongArch, Motorola 88000, the MIPS architecture, PA-RISC, Power ISA, RISC-V, SuperH, and SPARC. RISC processors are used in supercomputers, such as the Fugaku.[8]
History and development[edit]
A number of systems, going back to the 1960s, have been credited as the first RISC architecture, partly based on their use of the load–store approach.[9] The term RISC was coined by David Patterson of the Berkeley RISC project, although somewhat similar concepts had appeared before.[10]
The CDC 6600 designed by Seymour Cray in 1964 used a load–store architecture with only two addressing modes (register+register, and register+immediate constant) and 74 operation codes, with the basic clock cycle being 10 times faster than the memory access time.[11] Partly due to the optimized load–store architecture of the CDC 6600, Jack Dongarra says that it can be considered a forerunner of modern RISC systems, although a number of other technical barriers needed to be overcome for the development of a modern RISC system.[12]
IBM 801[edit]

Michael J. Flynn views the first RISC system as the IBM 801 design,[2] begun in 1975 by John Cocke and completed in 1980. The 801 developed out of an effort to build a 24-bit high-speed processor to use as the basis for a digital telephone switch. To reach their goal of switching 1 million calls per hour (300 per second) they calculated that the CPU required performance on the order of 12 million instructions per second (MIPS),[13] compared to their fastest mainframe machine of the time, the 370/168, which performed at 3.5 MIPS.[14]
The design was based on a study of IBM’s extensive collection of statistics gathered from their customers. This demonstrated that code in high-performance settings made extensive use of processor registers, and that they often ran out of them. This suggested that additional registers would improve performance. Additionally, they noticed that compilers generally ignored the vast majority of the available instructions, especially orthogonal addressing modes. Instead, they selected the fastest version of any given instruction and then constructed small routines using it. This suggested that the majority of instructions could be removed without affecting the resulting code. These two conclusions worked in concert; removing instructions would allow the instruction opcodes to be shorter, freeing up bits in the instruction word which could then be used to select among a larger set of registers.[13]
The telephone switch program was canceled in 1975, but by then the team had demonstrated that the same design would offer significant performance gains running just about any code. In simulations, they showed that a compiler tuned to use registers wherever possible would run code about three times as fast as traditional designs. Somewhat surprisingly, the same code would run about 50% faster even on existing machines due to the improved register use. In practice, their experimental PL/8 compiler, a slightly cut-down version of PL/I, consistently produced code that ran much faster on their existing mainframes.[13]
A 32-bit version of the 801 was eventually produced in a single-chip form as the IBM ROMP in 1981, which stood for ‘Research OPD [Office Products Division] Micro Processor’.[15] This CPU was designed for «mini» tasks, and found use in peripheral interfaces and channel controllers on later IBM computers. It was also used as the CPU in the IBM RT PC in 1986, which turned out to be a commercial failure.[16] Although the 801 did not see widespread use in its original form, it inspired many research projects, including ones at IBM that would eventually lead to the IBM POWER architecture.[17][18]
RISC and MIPS[edit]
By the late 1970s, the 801 had become well-known in the industry. This coincided with new fabrication techniques that were allowing more complex chips to come to market. The Zilog Z80 of 1976 had 8,000 transistors, whereas the 1979 Motorola 68000 (68k) had 68,000. These newer designs generally used their newfound complexity to expand the instruction set to make it more orthogonal. Most, like the 68k, used microcode to do this, reading instructions and re-implementing them as a sequence of simpler internal instructions. In the 68k, a full 1⁄3 of the transistors were used for this microcoding.[19]
In 1979, David Patterson was sent on a sabbatical from the University of California, Berkeley to help DEC’s west-coast team improve the VAX microcode. Patterson was struck by the complexity of the coding process and concluded it was untenable.[20] He first wrote a paper on ways to improve microcoding, but later changed his mind and decided microcode itself was the problem. With funding from the DARPA VLSI Program, Patterson started the Berkeley RISC effort. The Program, practically unknown today, led to a huge number of advances in chip design, fabrication, and even computer graphics. Considering a variety of programs from their BSD Unix variant, the Berkeley team found, as had IBM, that most programs made no use of the large variety of instructions in the 68k.[21]
Patterson’s early work pointed out an important problem with the traditional «more is better» approach; even those instructions that were critical to overall performance were being delayed by their trip through the microcode. If the microcode was removed, the programs would run faster. And since the microcode ultimately took a complex instruction and broke it into steps, there was no reason the compiler couldn’t do this instead. These studies suggested that, even with no other changes, one could make a chip with 1⁄3 fewer transistors that would run faster.[21] In the original RISC-I paper they noted:[22]
Skipping this extra level of interpretation appears to enhance performance while reducing chip size.[22]
It was also discovered that, on microcoded implementations of certain architectures, complex operations tended to be slower than a sequence of simpler operations doing the same thing. This was in part an effect of the fact that many designs were rushed, with little time to optimize or tune every instruction; only those used most often were optimized, and a sequence of those instructions could be faster than a less-tuned instruction performing an equivalent operation as that sequence. One infamous example was the VAX’s INDEX instruction.[23]
The Berkeley work also turned up a number of additional points. Among these was the fact that programs spent a significant amount of time performing subroutine calls and returns, and it seemed there was the potential to improve overall performance by speeding these calls. This led the Berkeley design to select a method known as register windows which can significantly improve subroutine performance although at the cost of some complexity.[22] They also noticed that the majority of mathematical instructions were simple assignments; only 1⁄3 of them actually performed an operation like addition or subtraction. But when those operations did occur, they tended to be slow. This led to far more emphasis on the underlying arithmetic data unit, as opposed to previous designs where the majority of the chip was dedicated to control and microcode.[21]
The resulting Berkeley RISC was based on gaining performance through the use of pipelining and aggressive use of register windowing.[23][22] In a traditional CPU, one has a small number of registers, and a program can use any register at any time. In a CPU with register windows, there are a huge number of registers, e.g., 128, but programs can only use a small number of them, e.g., eight, at any one time. A program that limits itself to eight registers per procedure can make very fast procedure calls: The call simply moves the window «down» by eight, to the set of eight registers used by that procedure, and the return moves the window back.[24] The Berkeley RISC project delivered the RISC-I processor in 1982. Consisting of only 44,420 transistors (compared with averages of about 100,000 in newer CISC designs of the era), RISC-I had only 32 instructions, and yet completely outperformed any other single-chip design, with estimated performance being higher than the VAX.[22] They followed this up with the 40,760-transistor, 39-instruction RISC-II in 1983, which ran over three times as fast as RISC-I.[22]
As the RISC project began to become known in Silicon Valley, a similar project began at Stanford University in 1981. This MIPS project grew out of a graduate course by John L. Hennessy, produced a functioning system in 1983, and could run simple programs by 1984.[25] The MIPS approach emphasized an aggressive clock cycle and the use of the pipeline, making sure it could be run as «full» as possible.[25] The MIPS system was followed by the MIPS-X and in 1984 Hennessy and his colleagues formed MIPS Computer Systems to produce the design commercially.[25][26] The venture resulted in a new architecture that was also called MIPS and the R2000 microprocessor in 1985.[26]
The overall philosophy of the RISC concept was widely understood by the second half of the 1980s, and led the designers of the MIPS-X to put it this way in 1987:
The goal of any instruction format should be: 1. simple decode, 2. simple decode, and 3. simple decode. Any attempts at improved code density at the expense of CPU performance should be ridiculed at every opportunity.[27]
Commercial breakout[edit]

In the early 1980s, significant uncertainties surrounded the RISC concept. One concern involved the use of memory; a single instruction from a traditional processor like the Motorola 68k may be written out as perhaps a half dozen of the simpler RISC instructions. In theory, this could slow the system down as it spent more time fetching instructions from memory. But by the mid-1980s, the concepts had matured enough to be seen as commercially viable.[16][25]
Commercial RISC designs began to emerge in the mid-1980s. The first MIPS R2000 appeared in January 1986, followed shortly thereafter by Hewlett-Packard’s PA-RISC in some of their computers.[16] In the meantime, the Berkeley effort had become so well known that it eventually became the name for the entire concept. In 1987 Sun Microsystems began shipping systems with the SPARC processor, directly based on the Berkeley RISC-II system.[16][28] The US government Committee on Innovations in Computing and Communications credits the acceptance of the viability of the RISC concept to the success of the SPARC system.[16] The success of SPARC renewed interest within IBM, which released new RISC systems by 1990 and by 1995 RISC processors were the foundation of a $15 billion server industry.[16]
By the later 1980s, the new RISC designs were easily outperforming all traditional designs by a wide margin. At that point, all of the other vendors began RISC efforts of their own. Among these were the DEC Alpha, AMD Am29000, Intel i860 and i960, Motorola 88000, IBM POWER, and, slightly later, the IBM/Apple/Motorola PowerPC. Many of these have since disappeared due to them often offering no competitive advantage over others of the same era. Those that remain are often used only in niche markets or as parts of other systems; of the designs from these traditional vendors, only SPARC and POWER have any significant remaining market.[citation needed]
The ARM architecture is illustrative of the adaptations made by RISC vendors to respond to changing competitive circumstances, being first introduced to deliver higher performance in desktop computers such as the Acorn Archimedes, but also being introduced in embedded applications such as laser printer raster image processing.[29] ARM, in partnership with Apple, developed a low-power design and then specialized in that market, which at the time was a niche. With the rise in mobile computing, especially after the introduction of the iPhone, ARM became the most widely used high-end CPU design in the market.[clarification needed]
Competition between RISC and conventional CISC approaches was also the subject of theoretical analysis in the early 1980s, leading, for example, to the iron law of processor performance.
Since 2010, a new open source instruction set architecture (ISA), RISC-V, has been under development at the University of California, Berkeley, for research purposes and as a free alternative to proprietary ISAs. As of 2014, version 2 of the user space ISA is fixed.[30] The ISA is designed to be extensible from a barebones core sufficient for a small embedded processor to supercomputer and cloud computing use with standard and chip designer–defined extensions and coprocessors. It has been tested in silicon design with the ROCKET SoC, which is also available as an open-source processor generator in the CHISEL language.
Characteristics and design philosophy[edit]
Confusion around the definition of RISC deriving from the formulation of the term, along with the tendency to opportunistically categorize processor architectures with relatively few instructions (or groups of instructions) as RISC architectures, led to attempts to define RISC as a design philosophy. One attempt to do so was expressed as the following:
A RISC processor has an instruction set that is designed for efficient execution by a pipelined processor and for code generation by an optimizing compiler.
— Michael Slater, Microprocessor Report[31]
Instruction set philosophy[edit]
A common misunderstanding of the phrase «reduced instruction set computer» is that instructions are simply eliminated, resulting in a smaller set of instructions.[32]
In fact, over the years, RISC instruction sets have grown in size, and today many of them have a larger set of instructions than many CISC CPUs.[33][34] Some RISC processors such as the PowerPC have instruction sets as large as the CISC IBM System/370, for example; conversely, the DEC PDP-8—clearly a CISC CPU because many of its instructions involve multiple memory accesses—has only 8 basic instructions and a few extended instructions.[35]
The term «reduced» in that phrase was intended to describe the fact that the amount of work any single instruction accomplishes is reduced—at most a single data memory cycle—compared to the «complex instructions» of CISC CPUs that may require dozens of data memory cycles in order to execute a single instruction.[36]
The term load–store architecture is sometimes preferred.
Another way of looking at the RISC/CISC debate is to consider what is exposed to the compiler. In a CISC processor, the hardware may internally use registers and flag bit in order to implement a single complex instruction such as STRING MOVE, but hide those details from the compiler.
The internal operations of a RISC processor are «exposed to the compiler», leading to the backronym ‘Relegate Interesting Stuff to the Compiler’.[37][38]
Instruction format[edit]
Most RISC architectures have fixed-length instructions and a simple encoding, which simplifies fetch, decode, and issue logic considerably. This is among the main goals of the RISC approach.[22]
Some of this is possible only due to the contemporary move to 32-bit formats. For instance, in a typical program, over 30% of all the numeric constants are either 0 or 1, 95% will fit in one byte, and 99% in a 16-bit value.[39] When computers were based on 8- or 16-bit words, it would be difficult to have an immediate combined with the opcode in a single memory word, although certain instructions like increment and decrement did this implicitly by using a different opcode. In contrast, a 32-bit machine has ample room to encode an immediate value, and doing so avoids the need to do a second memory read to pick up the value. This is why many RISC processors allow a 12- or 13-bit constant to be encoded directly into the instruction word.[22]
Assuming a 13-bit constant area, as is the case in the MIPS and RISC designs, another 19 bits are available for the instruction encoding. This leaves ample room to indicate both the opcode and one or two registers. Register-to-register operations, mostly math and logic, require enough bits to encode the two or three registers being used. Most processors use the three-operand format, of the form A = B + C, in which case three registers numbers are needed. If the processor has 32 registers, each one requires a 5-bit number, for 15 bits. If one of these registers is replaced by an immediate, there is still lots of room to encode the two remaining registers and the opcode. Common instructions found in multi-word systems, like INC and DEC, which reduce the number of words that have to be read before performing the instruction, are unnecessary in RISC as they can be accomplished with a single register and the immediate value 1.[22]
The original RISC-I format remains a canonical example of the concept. It uses 7 bits for the opcode and a 1-bit flag for conditional codes, the following 5 bits for the destination register, and the next five for the first operand. This leaves 14 bits, the first of which indicates whether the following 13 contain an immediate value or uses only five of them to indicate a register for the second operand.[22] A more complex example is the MIPS encoding, which used only 6 bits for the opcode, followed by two 5-bit registers. The remaining 16 bits could be used in two ways, one as a 16-bit immediate value, or as a 5-bit shift value (used only in shift operations, otherwise zero) and the remaining 6 bits as an extension on the opcode. In the case of register-to-register arithmetic operations, the opcode was 0 and the last 6 bits contained the actual code; those that used an immediate value used the normal opcode field at the front.[40]
One drawback of 32-bit instructions is reduced code density, which is more adverse a characteristic in embedded computing than it is in the workstation and server markets RISC architectures were originally designed to serve. To address this problem, several architectures, such as ARM, Power ISA, MIPS, RISC-V, and the Adapteva Epiphany, have an optional short, feature-reduced compressed instruction set. Generally, these instructions expose a smaller number of registers and fewer bits for immediate values, and often use a two-instruction format to eliminate one register number from instructions. A two-operand format in a system with 16 registers requires 8 bits for register numbers, leaving another 8 for an opcode or other uses. The SH5 also follows this pattern, albeit having evolved in the opposite direction, having added longer 32-bit instructions to an original 16-bit encoding.
Hardware utilization[edit]
For any given level of general performance, a RISC chip will typically have far fewer transistors dedicated to the core logic which originally allowed designers to increase the size of the register set and increase internal parallelism.[citation needed]
Other features of RISC architectures include:
- Single-cycle operation, described as «the rapid execution of simple functions that dominate a computer’s instruction stream», thus seeking to deliver an average throughput approaching one instruction per cycle for any single instruction stream[41]
- Uniform instruction format, using single word with the opcode in the same bit positions for simpler decoding
- All general-purpose registers can be used equally as source/destination in all instructions, simplifying compiler design (floating-point registers are often kept separate)
- Simple addressing modes with complex addressing performed by instruction sequences
- Few data types in hardware (no byte string or binary-coded decimal [BCD], for example)
RISC designs are also more likely to feature a Harvard memory model, where the instruction stream and the data stream are conceptually separated; this means that modifying the memory where code is held might not have any effect on the instructions executed by the processor (because the CPU has a separate instruction and data cache), at least until a special synchronization instruction is issued; CISC processors that have separate instruction and data caches generally keep them synchronized automatically, for backwards compatibility with older processors.
Many early RISC designs also shared the characteristic of having a branch delay slot, an instruction space immediately following a jump or branch. The instruction in this space is executed, whether or not the branch is taken (in other words the effect of the branch is delayed). This instruction keeps the ALU of the CPU busy for the extra time normally needed to perform a branch. Nowadays the branch delay slot is considered an unfortunate side effect of a particular strategy for implementing some RISC designs, and modern RISC designs generally do away with it (such as PowerPC and more recent versions of SPARC and MIPS).[citation needed]
Some aspects attributed to the first RISC-labeled designs around 1975 include the observations that the memory-restricted compilers of the time were often unable to take advantage of features intended to facilitate manual assembly coding, and that complex addressing modes take many cycles to perform due to the required additional memory accesses. It was argued[by whom?] that such functions would be better performed by sequences of simpler instructions if this could yield implementations small enough to leave room for many registers, reducing the number of slow memory accesses. In these simple designs, most instructions are of uniform length and similar structure, arithmetic operations are restricted to CPU registers and only separate load and store instructions access memory. These properties enable a better balancing of pipeline stages than before, making RISC pipelines significantly more efficient and allowing higher clock frequencies.
Yet another impetus of both RISC and other designs came from practical measurements on real-world programs. Andrew Tanenbaum summed up many of these, demonstrating that processors often had oversized immediates. For instance, he showed that 98% of all the constants in a program would fit in 13 bits, yet many CPU designs dedicated 16 or 32 bits to store them. This suggests that, to reduce the number of memory accesses, a fixed length machine could store constants in unused bits of the instruction word itself, so that they would be immediately ready when the CPU needs them (much like immediate addressing in a conventional design). This required small opcodes in order to leave room for a reasonably sized constant in a 32-bit instruction word.
Since many real-world programs spend most of their time executing simple operations, some researchers decided to focus on making those operations as fast as possible. The clock rate of a CPU is limited by the time it takes to execute the slowest sub-operation of any instruction; decreasing that cycle-time often accelerates the execution of other instructions.[42] The focus on «reduced instructions» led to the resulting machine being called a «reduced instruction set computer» (RISC). The goal was to make instructions so simple that they could easily be pipelined, in order to achieve a single clock throughput at high frequencies.
Later, it was noted that one of the most significant characteristics of RISC processors was that external memory was only accessible by a load or store instruction. All other instructions were limited to internal registers. This simplified many aspects of processor design: allowing instructions to be fixed-length, simplifying pipelines, and isolating the logic for dealing with the delay in completing a memory access (cache miss, etc.) to only two instructions. This led to RISC designs being referred to as load–store architectures.[43]
Comparison to other architectures[edit]
Some CPUs have been specifically designed to have a very small set of instructions—but these designs are very different from classic RISC designs, so they have been given other names such as minimal instruction set computer (MISC) or transport triggered architecture (TTA).
RISC architectures have traditionally had few successes in the desktop PC and commodity server markets, where the x86-based platforms remain the dominant processor architecture. However, this may change, as ARM-based processors are being developed for higher performance systems.[44] Manufacturers including Cavium, AMD, and Qualcomm have released server processors based on the ARM architecture.[45][46] ARM further partnered with Cray in 2017 to produce an ARM-based supercomputer.[47] On the desktop, Microsoft announced that it planned to support the PC version of Windows 10 on Qualcomm Snapdragon-based devices in 2017 as part of its partnership with Qualcomm. These devices will support Windows applications compiled for 32-bit x86 via an x86 processor emulator that translates 32-bit x86 code to ARM64 code.[48][49] Apple announced they will transition their Mac desktop and laptop computers from Intel processors to internally developed ARM64-based SoCs called Apple silicon; the first such computers, using the Apple M1 processor, were released in November 2020.[50] Macs with Apple silicon can run x86-64 binaries with Rosetta 2, an x86-64 to ARM64 translator.[51]
Outside of the desktop arena, however, the ARM RISC architecture is in widespread use in smartphones, tablets and many forms of embedded devices. While early RISC designs differed significantly from contemporary CISC designs, by 2000 the highest-performing CPUs in the RISC line were almost indistinguishable from the highest-performing CPUs in the CISC line.[52][53][54]
Use of RISC architectures[edit]
RISC architectures are now used across a range of platforms, from smartphones and tablet computers to some of the world’s fastest supercomputers such as Fugaku, the fastest on the TOP500 list as of November 2020, and Summit, Sierra, and Sunway TaihuLight, the next three on that list.[55]
Low-end and mobile systems[edit]
By the beginning of the 21st century, the majority of low-end and mobile systems relied on RISC architectures.[56] Examples include:
- The ARM architecture dominates the market for low-power and low-cost embedded systems (typically 200–1800 MHz in 2014). It is used in a number of systems such as most Android-based systems, the Apple iPhone, iPod Touch, iPad, Apple Watch, and Apple TV, Microsoft Windows Phone (former Windows Mobile), RIM devices, Nintendo Game Boy Advance, DS, 3DS and Switch, Raspberry Pi, etc.
- IBM’s PowerPC was used in the GameCube, Wii, PlayStation 3, Xbox 360 and Wii U gaming consoles.
- The MIPS line (at one point used in many SGI computers) was used in the PlayStation, PlayStation 2, Nintendo 64, PlayStation Portable game consoles, and residential gateways like Linksys WRT54G series.
- Hitachi’s SuperH, originally in wide use in the Sega Super 32X, Saturn and Dreamcast, now developed and sold by Renesas as the SH4.
- Atmel AVR, used in a variety of products ranging from Xbox handheld controllers and the Arduino open-source microcontroller platform to BMW cars.
- RISC-V, the open-source fifth Berkeley RISC ISA, with 32- or 64-bit address spaces, a small core integer instruction set, and an experimental «Compressed» ISA for code density and designed for standard and special-purpose extensions.
Desktop and laptop computers[edit]
- IBM’s PowerPC architecture was used in Apple’s Macintosh computers from 1994, when they began a switch from Motorola 68000 family processors, to 2005, when they transitioned to Intel x86 processors.[57]
- Some chromebooks use ARM-based platforms since 2012.[58]
- Apple uses inhouse-designed processors based on the ARM architecture for its lineup of desktop and laptop computers since its transition from Intel processors,[59] and the first such computers were released in November 2020.[50]
- Microsoft uses Qualcomm[60] ARM-based processors for its Surface line. HP Inc and Lenovo have released Windows PCs with an ARM-based Qualcomm Snapdragon.
Workstations, servers, and supercomputers[edit]
- MIPS, by Silicon Graphics (ceased making MIPS-based systems in 2006).
- SPARC, by Oracle (previously Sun Microsystems), and Fujitsu.
- IBM’s IBM POWER architecture, PowerPC, and Power ISA were and are used in many of IBM’s supercomputers, mid-range servers and workstations.
- Hewlett-Packard’s PA-RISC, also known as HP-PA (discontinued at the end of 2008).
- Alpha, used in single-board computers, workstations, servers and supercomputers from Digital Equipment Corporation, then Compaq and finally Hewlett-Packard (HP)(discontinued as of 2007).
- RISC-V, the open source fifth Berkeley RISC ISA, with 64- or 128-bit address spaces, and the integer core extended with floating point, atomics and vector processing, and designed to be extended with instructions for networking, I/O, and data processing. A 64-bit superscalar design, «Rocket», is available for download. It is implemented in the European Processor Initiative processor.
- The ARM architecture was used in the Fujitsu A64FX chip to create Fugaku, the world’s fastest supercomputer in 2020.
Open source[edit]
RISC architectures have become popular in open source processors and soft microprocessors since they are relatively simple to implement, which makes them suitable for FPGA implementations and prototyping, for instance. Examples include:
- OpenRISC, an open instruction set and micro-architecture first introduced in 2000.
- LEON, an open source, radiation-tolerant implementation of the SPARC V8 instruction set (targeting space applications).
- Libre-SOC, an open source SoC based on the Power ISA with extensions for video and 3D graphics.
- There are also several open source RISC-V implementations.
Awards[edit]
In 2022 Steve Furber, John L. Hennessy, David A. Patterson and Sophie M. Wilson were awarded the Charles Stark Draper Prize by the United States National Academy of Engineering for their contributions to the invention, development, and implementation of reduced instruction set computer (RISC) chips.[61][62]
See also[edit]
- Classic RISC pipeline
- Microprocessor
- No instruction set computing
- One-instruction set computer
References[edit]
- ^ Chen, Crystal; Novick, Greg; Shimano, Kirk. «Pipelining». RISC Architecture.
- ^ a b Flynn, Michael J. (1995). Computer Architecture: Pipelined and Parallel Processor Design. Jones & Bartlett Learning. pp. 54–56. ISBN 0867202041.
- ^ Colwell, Robert P.; Hitchcock III, Charles Y.; Jensen, E. Douglas; Sprunt, H. M. Brinkley; Kollar, Charles P. (September 1985). «Instruction Sets and Beyond: Computers, Complexity, and Controversy» (PDF). Computer. IEEE. pp. 8–19.
- ^ Aletan, Samuel O. (1 April 1992). «An overview of RISC architecture». Proceedings of the 1992 ACM/SIGAPP Symposium on Applied computing: technological challenges of the 1990’s. SAC ’92. Kansas City, Missouri: Association for Computing Machinery. pp. 11–20. doi:10.1145/143559.143570.
- ^ Markoff, John (November 1984). «New Chips — RISC Chips». Byte. Vol. 9, no. 12. McGraw-Hill. pp. 191–206.
- ^ Boursin de l’Arc, Philippe. «Histoire de l’Informatique et d’Internet». boursinp.free.fr.
- ^ Manuel, Tom (3 September 1987). «Inside Technology — The Frantic Search for More Speed» (PDF). Electronics. McGraw-Hill. pp. 59–62.
- ^ «Japan’s Fugaku gains title as world’s fastest supercomputer». RIKEN. Retrieved 24 June 2020.
- ^ Fisher, Joseph A.; Faraboschi, Paolo; Young, Cliff (2005). Embedded Computing: A VLIW Approach to Architecture, Compilers and Tools. Elsevier. p. 55. ISBN 1558607668.
- ^ Reilly, Edwin D. (2003). Milestones in computer science and information technology. Greenwood Publishing. pp. 50. ISBN 1-57356-521-0.
- ^ Grishman, Ralph (1974). Assembly Language Programming for the Control Data 6000 Series and the Cyber 70 Series. Algorithmics Press. p. 12. OCLC 425963232.
- ^ Dongarra, Jack J.; et al. (1987). Numerical Linear Algebra on High-Performance Computers. pp. 6. ISBN 0-89871-428-1.
- ^ a b c Cocke, John; Markstein, Victoria (January 1990). «The evolution of RISC technology at IBM» (PDF). IBM Journal of Research and Development. 34 (1): 4–11. doi:10.1147/rd.341.0004.
- ^ IBM System/370 System Summary (Technical report). IBM. January 1987.
- ^ Šilc, Jurij; Robič, Borut; Ungerer, Theo (1999). Processor architecture: from dataflow to superscalar and beyond. Springer. pp. 33. ISBN 3-540-64798-8.
- ^ a b c d e f Funding a Revolution: Government Support for Computing Research by Committee on Innovations in Computing and Communications 1999 ISBN 0-309-06278-0 page 239
- ^ Nurmi, Jari (2007). Processor design: system-on-chip computing for ASICs and FPGAs. Springer. pp. 40–43. ISBN 978-1-4020-5529-4.
- ^ Hill, Mark Donald; Jouppi, Norman Paul; Sohi, Gurindar (1999). Readings in computer architecture. Gulf Professional. pp. 252–4. ISBN 1-55860-539-8.
- ^ Starnes, Thomas (May 1983). «Design Philosophy Behind Motorola’s MC68000». Byte. p. Photo 1.
- ^ Patterson, David (30 May 2018). «RISCy History». AM SIGARCH.
- ^ a b c «Example: Berkeley RISC II». Archived from the original on 13 June 2022.
- ^ a b c d e f g h i j Patterson, David A.; Sequin, Carlo H. (1981). RISC I: A Reduced Instruction Set VLSI Computer. 8th annual symposium on Computer Architecture. Minneapolis, MN, USA. pp. 443–457. doi:10.1145/285930.285981. As PDF
- ^ a b Patterson, D. A.; Ditzel, D. R. (1980). «The case for the reduced instruction set computer». ACM SIGARCH Computer Architecture News. 8 (6): 25–33. CiteSeerX 10.1.1.68.9623. doi:10.1145/641914.641917. S2CID 12034303.
- ^ Sequin, Carlo; Patterson, David (July 1982). Design and Implementation of RISC I (PDF). Advanced Course on VLSI Architecture. University of Bristol. CSD-82-106.
- ^ a b c d Chow, Paul (1989). The MIPS-X RISC microprocessor. Springer. pp. xix–xx. ISBN 0-7923-9045-8.
- ^ a b Nurmi 2007, pp. 52–53
- ^ Weaver, Vincent; McKee, Sally. Code Density Concerns for New Architectures (PDF). ICCD 2009.
- ^ Tucker, Allen B. (2004). Computer science handbook. Taylor & Francis. pp. 100–6. ISBN 1-58488-360-X.
- ^ «Olivetti buys RISC card». Acorn User. August 1988. p. 7. Retrieved 24 May 2021.
- ^ Waterman, Andrew; Lee, Yunsup; Patterson, David A.; Asanovi, Krste. «The RISC-V Instruction Set Manual, Volume I: Base User-Level ISA version 2.0». University of California, Berkeley. Technical Report EECS-2014-54. Retrieved 1 March 2022.
- ^ Slater, Michael (June 1990). «What is RISC?». IEEE Micro. pp. 96–95. Retrieved 20 March 2023.
- ^ Esponda, Margarita; Rojas, Ra’ul (September 1991). «Section 2: The confusion around the RISC concept». The RISC Concept — A Survey of Implementations. Freie Universitat Berlin. B-91-12.
- ^ Stokes, Jon «Hannibal». «RISC vs. CISC: the Post-RISC Era». Ars Technica.
- ^
Borrett, Lloyd (June 1991). «RISC versus CISC». Australian Personal Computer. - ^ Jones, Douglas W. «Doug Jones’s DEC PDP-8 FAQs». PDP-8 Collection, The University Of Iowa Department of Computer Science.
- ^ Dandamudi, Sivarama P. (2005). «Ch. 3: RISC Principles». Guide to RISC Processors for Programmers and Engineers. Springer. pp. 39–44. doi:10.1007/0-387-27446-4_3. ISBN 978-0-387-21017-9.
the main goal was not to reduce the number of instructions, but the complexity
- ^ Walls, Colin (18 April 2016). «CISC and RISC».
- ^ Fisher, Joseph A.; Faraboschi, Paolo; Young, Cliff (2005). Embedded Computing: A VLIW Approach to Architecture, Compilers and Tools. Elsevier. p. 57. ISBN 9781558607668.
- ^ Alexander, W. Gregg; Wortman, David (November 1975). «Static and Dynamic Characteristics of XPL Programs». IEEE Computer. 8 (11): 41–48. doi:10.1109/C-M.1975.218804. S2CID 39685209.
- ^ Soares, João; Rocha, Ricardo. «Encoding MIPS Instructions» (PDF).
- ^ Colwell, Robert P.; Hitchcock III, Charles Y.; Jensen, E. Douglas; Sprunt, H. M. Brinkley; Kollar, Charles P. (September 1985). «Instruction Sets and Beyond: Computers, Complexity and Controversy». Computer. The Institute of Electrical and Electronics Engineers, Inc. 18 (9): 8–19. doi:10.1109/MC.1985.1663000. S2CID 7306378. Retrieved 25 March 2023.
- ^ «Microprocessors From the Programmer’s Perspective» by Andrew Schulman 1990
- ^ Dowd, Kevin; Loukides, Michael K. (1993). High Performance Computing. O’Reilly. ISBN 1565920325.
- ^ Vincent, James (9 March 2017). «Microsoft unveils new ARM server designs, threatening Intel’s dominance». The Verge. Retrieved 12 May 2017.
- ^ Russell, John (31 May 2016). «Cavium Unveils ThunderX2 Plans, Reports ARM Traction is Growing». HPC Wire. Retrieved 8 March 2017.
- ^ AMD’s first ARM-based processor, the Opteron A1100, is finally here, ExtremeTech, 14 January 2016, retrieved 14 August 2016
- ^ Feldman, Michael (18 January 2017). «Cray to Deliver ARM-Powered Supercomputer to UK Consortium». Top500.org. Retrieved 12 May 2017.
- ^ «Microsoft is bringing Windows desktop apps to mobile ARM processors». The Verge. 8 December 2016. Retrieved 8 December 2016.
- ^ «How x86 emulation works on ARM». Microsoft Docs. 15 February 2018.
- ^ a b «Introducing the next generation of Mac» (Press release). Apple Inc. 10 November 2020.
- ^ «macOS Big Sur is here» (Press release). Apple Inc. 12 November 2020.
- ^ Carter, Nicholas P. (2002). Schaum’s Outline of Computer Architecture. McGraw Hill Professional. p. 96. ISBN 0-07-136207-X.
- ^ Jones, Douglas L. (2000). «CISC, RISC, and DSP Microprocessors» (PDF).
- ^
Singh, Amit. «A History of Apple’s Operating Systems». Archived from the original on 3 April 2020.the line between RISC and CISC has been growing fuzzier over the years
- ^ «Top 500 The List: November 2020». TOP 500. Retrieved 2 January 2021.
- ^ Dandamudi 2005, pp. 121–123
- ^ Bennett, Amy (2005). «Apple shifting from PowerPC to Intel». Computerworld. Retrieved 24 August 2020.
- ^ Vaughan-Nichols, Steven J. «Review: The ARM-powered Samsung Chromebook». ZDNet. Retrieved 28 April 2021.
- ^ DeAngelis, Marc (22 June 2020). «Apple starts its two-year transition to ARM this week». Engadget. Retrieved 24 August 2020.
Apple has officially announced that it will be switching from Intel processors to its own ARM-based, A-series chips in its Mac computers.
- ^ Smith, Chris (16 September 2020). «Microsoft to launch a new ARM-based Surface this fall». Boy Genius Report. Retrieved 20 March 2023.
- ^ «Recipients of the Charles Stark Draper Prize for Engineering». nae.edu.
- ^ «Charles Stark Draper Prize for Engineering». nae.edu.
External links[edit]
- «RISC vs. CISC». RISC Architecture. Stanford University. 2000.
- «What is RISC». RISC Architecture. Stanford University. 2000.
- Savard, John J. G. «Not Quite RISC». Computers.
- Mashey, John R. (5 September 2000). «Yet Another Post of the Old RISC Post [unchanged from last time]». Newsgroup: comp.arch. Usenet: 8p20b0$dhh$3@murrow.corp.sgi.com.
Nth re-posting of CISC vs RISC (or what is RISC, really)
RISC
— Reduced Instruction
Set Computer –
архитектура компьютера с сокращенным
набором команд.В ходе анализа частоты
выполнения тех или иных команд выяснено,
что 40% команд используются крайне редко.
RISC-архитектура предполагает
реализацию в ЭВМ сокращенного набора
простейших, но часто употребляемых
команд, что позволяет упростить
аппаратурные средства процессора и
благодаря этому получить возможность
повысить его быстродействие.
Современные
процессоры типа RISC
характеризуются следующими особенностями:
-
упрощенный набор команд, имеющих
одинаковую длину. Например, выполнение
типичной команды можно разделить на
этапы:
-
выборка команды
-
декодирование команды
-
выполнение операции
-
обращение к памяти
-
запоминание результата
Все
команды в RISC имеют одну
структуру, количество команд – обычно
не более 50-100.
-
Большинство команд выполняется за 4-5
тактов процессора. -
Отсутствуют макрокоманды, усложняющие
структуру процессора и уменьшающие
скорость его работы. -
Взаимодействие с оперативной памятью
ограничивается операциями пересылки
данных. -
Уменьшено число способов адресации
(не используется косвенная, обычно 2-3
простых способов) -
Используется конвейер команд.
-
Применяется высокоскоростная память.
В
ЭВМ с RISC машинным циклом называют время,
в течение которого производится выборка
двух операндов из регистров, выполнение
операции в АЛУ и запоминание результата
в регистре. Большинство команд в RISC
являются быстрыми командами типа
«регистр — регистр» и выполняются без
обращений к ОП. Обращения к ОП сохраняются
лишь в командах загрузки регистров из
памяти и запоминания в ОП. Чтобы это
было возможным, процессор должен
содержать достаточно большое число
общих регистров.
Новый
подход к архитектуре команд процессора
значительно сократил площадь, требуемой
для него на кристалле интегральной
микросхемы. Это позволило резко увеличить
число регистров (более 100 по лекциям, а
вообще в типовых RISC-процессорах
реализуются 32 или большее число регистров
по сравнению с 8 — 16 регистрами в
CISC-архитектурах). В результате процессор
стал на 20-30% реже обращаться к оперативной
памяти. Упростилась топология процессора,
сократились сроки ее разработки, она
стала дешевле.
Особенностью
RISC архитектуры является
механизм перекрывающихся окон,
предназначенный для уменьшения числа
обращений к оперативной памяти и
межрегистровых передач, что способствует
увеличению производительности ЭВМ.
Процедурам динамически выделяются
небольшие группы регистров фиксированной
длины (регистровые окна). Окна
последовательно выполняемых процедур
перекрываются, благодаря чему возможна
передача параметров из одной процедуры
в другую. При этом не возникает
необходимость передачи содержимого
регистра в память.
Окно состоит
из трех подгрупп регистров:
-
первая подгруппа содержит параметры,
переданные данной процедуре от процедуры,
вызвавшей её, и результаты для вызывающей
процедуры при возврате в неё. -
вторая подгруппа содержит локальные
переменные процедуры. -
третья является буфером для двухстороннего
обмена.
В
1989 фирме Intel удалось на
основе RISC-архитектуры создать
однокристальный микропроцессор
80860, который практически представляет
собой кремниевый эквивалент суперЭВМ
Cray-1.
В
настоящее время многие архитектуры
процессоров являются RISC-подобными, к
примеру, ARM, DEC Alpha, SPARC, AVR, MIPS, POWER и PowerPC.
Наиболее широко используемые в настольных
компьютерах процессоры архитектуры
x86 ранее являлись CISC-процессорами, однако
новые процессоры, начиная с Intel 486DX,
являются CISC-процессорами с RISC-ядром.
Они непосредственно перед исполнением
преобразуют CISC-инструкции x86-процессоров
в более простой набор внутренних
инструкций RISC.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
RISC (англ. Restricted (reduced) instruction set computer — компьютер с сокращённым набором команд) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — короче. Первые RISC-процессоры даже не имели инструкций умножения и деления. Это также облегчает повышение тактовой частоты и делает более эффективной суперскалярность (распараллеливание инструкций между несколькими исполнительными блоками).
Наборы инструкций в более ранних архитектурах для облегчения ручного написания программ на языках ассемблеров или прямо в машинных кодах, а также для упрощения реализации компиляторов, выполняли как можно больше работы. Нередко в наборы включались инструкции для прямой поддержки конструкций языков высокого уровня. Другая особенность этих наборов — большинство инструкций, как правило, допускали все возможные методы адресации (т. н. «ортогональность системы команд (англ.)») — к примеру, и операнды, и результат в арифметических операциях доступны не только в регистрах, но и через непосредственную адресацию, и прямо в памяти. Позднее такие архитектуры были названы CISC (англ. Complex instruction set computer).
Однако многие компиляторы не задействовали все возможности таких наборов инструкций, а на сложные методы адресации уходит много времени из-за дополнительных обращений к медленной памяти. Было показано, что такие функции лучше исполнять последовательностью более простых инструкций, если при этом процессор упрощается и в нём остаётся место для большего числа регистров, за счёт которых можно сократить количество обращений к памяти. В первых архитектурах, причисляемых к RISC, большинство инструкций для упрощения декодирования имеют одинаковую длину и похожую структуру, арифметические операции работают только с регистрами, а работа с памятью идёт через отдельные инструкции загрузки (load) и сохранения (store). Эти свойства и позволили лучше сбалансировать этапы конвейеризации, сделав конвейеры в RISC значительно более эффективными и позволив поднять тактовую частоту.
Характерные особенности RISC-процессоров
Фиксированная длина машинных инструкций (например, 32 бита) и простой формат команды.
Специализированные команды для операций с памятью — чтения или записи. Операции вида «прочитать-изменить-записать» отсутствуют. Любые операции «изменить» выполняются только над содержимым регистров (т. н. архитектура load-and-store).
Большое количество регистров общего назначения (32 и более).
Отсутствие поддержки операций вида «изменить» над укороченными типами данных — байт, 16-битное слово. Так, например, система команд DEC Alpha содержала только операции над 64-битными словами, и требовала разработки и последующего вызова процедур для выполнения операций над байтами, 16- и 32-битными словами.
Отсутствие микропрограмм внутри самого процессора. То, что в CISC процессоре исполняется микропрограммами, в RISC процессоре исполняется как обыкновенный (хотя и помещённый в специальное хранилище) машинный код, не отличающийся принципиально от кода ядра ОС и приложений. Так, например, обработка отказов страниц в DEC Alpha и интерпретация таблиц страниц содержалась в так называемом PALCode (Privileged Architecture Library), помещённом в ПЗУ. Заменой PALCode можно было превратить процессор Alpha из 64-битного в 32-битный, а также изменить порядок байтов в слове и формат входов таблиц страниц виртуальной памяти.