Время на прочтение
4 мин
Количество просмотров 289K
Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свой путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений — все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом
--создание таблицы
create table student_grades (
name varchar,
subject varchar,
grade int);
-- наполнение таблицы данными
insert into student_grades (
values
('Петя', 'русский', 4),
('Петя', 'физика', 5),
('Петя', 'история', 4),
('Маша', 'математика', 4),
('Маша', 'русский', 3),
('Маша', 'физика', 5),
('Маша', 'история', 3));
--запрос всех данных из таблицы
select *
from student_grades;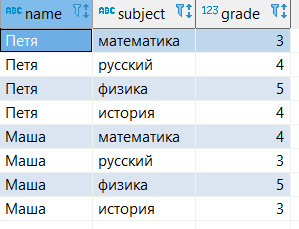
SQL часто используется для вычислений в данных различных метрик или агрегаций значений по измерениям. Помимо функций агрегации для этого широко используются оконные функции.
Оконная функция в SQL — функция, которая работает с выделенным набором строк (окном, партицией) и выполняет вычисление для этого набора строк в отдельном столбце.
Партиции (окна из набора строк) — это набор строк, указанный для оконной функции по одному из столбцов или группе столбцов таблицы. Партиции для каждой оконной функции в запросе могут быть разделены по различным колонкам таблицы.

В чем заключается главное отличие оконных функций от функций агрегации с группировкой?
При использовании агрегирующих функций предложение GROUP BY сокращает количество строк в запросе с помощью их группировки.
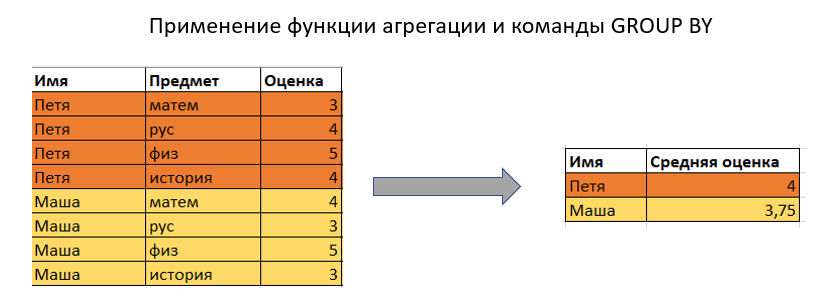
При использовании оконных функций количество строк в запросе не уменьшается по сравнении с исходной таблицей.

Порядок расчета оконных функций в SQL запросе
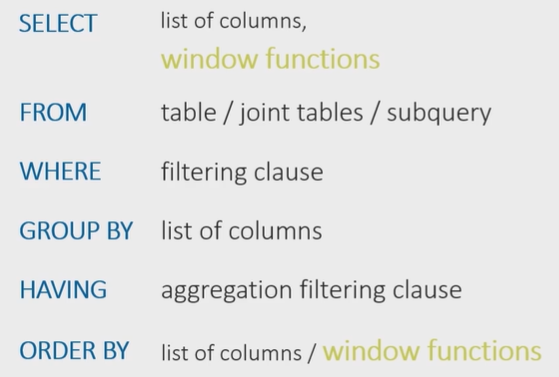
Сначала выполняется команда выборки таблиц, их объединения и возможные подзапросы под командой FROM.
Далее выполняются условия фильтрации WHERE, группировки GROUP BY и возможная фильтрация c HAVING
Только потом применяется команда выборки столбцов SELECT и расчет оконных функций под выборкой.
После этого идет условие сортировки ORDER BY, где тоже можно указать столбец расчета оконной функции для сортировки.
Здесь важно уточнить, что партиции или окна оконных функций создаются после разделения таблицы на группы с помощью команды GROUP BY, если эта команда используется в запросе.
Синтаксис оконных функций
Синтаксис оконных функций вне зависимости от их класса будет так или иначе состоять из идентичных команд.
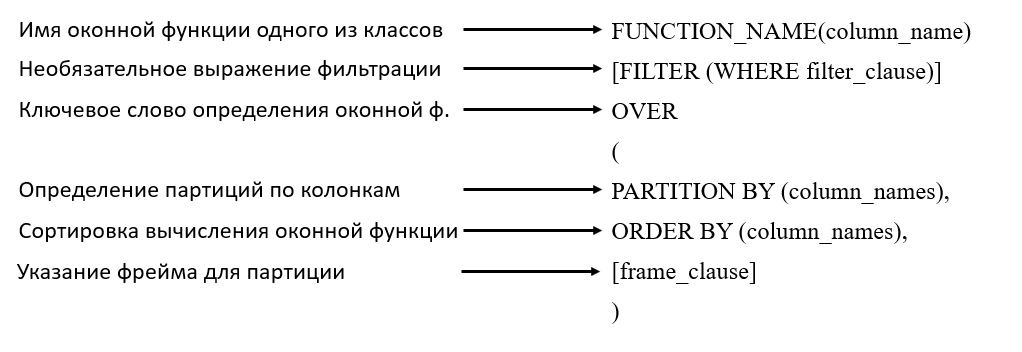
Оконные функции можно прописывать как под командой SELECT, так и в отдельном ключевом слове WINDOW, где окну дается алиас (псевдоним), к которому можно обращаться в SELECT выборке.

Классы Оконных функций
Множество оконных функций можно разделять на 3 класса:
-
Агрегирующие (Aggregate)
-
Ранжирующие (Ranking)
-
Функции смещения (Value)

Агрегирующие:
Можно применять любую из агрегирующих функций — SUM, AVG, COUNT, MIN, MAX
select name, subject, grade,
sum(grade) over (partition by name) as sum_grade,
avg(grade) over (partition by name) as avg_grade,
count(grade) over (partition by name) as count_grade,
min(grade) over (partition by name) as min_grade,
max(grade) over (partition by name) as max_grade
from student_grades;
Ранжирующие:
В ранжирующих функция под ключевым словом OVER обязательным идет указание условия ORDER BY, по которому будет происходить сортировка ранжирования.
ROW_NUMBER() — функция вычисляет последовательность ранг (порядковый номер) строк внутри партиции, НЕЗАВИСИМО от того, есть ли в строках повторяющиеся значения или нет.
RANK() — функция вычисляет ранг каждой строки внутри партиции. Если есть повторяющиеся значения, функция возвращает одинаковый ранг для таких строчек, пропуская при этом следующий числовой ранг.
DENSE_RANK() — то же самое что и RANK, только в случае одинаковых значений DENSE_RANK не пропускает следующий числовой ранг, а идет последовательно.
select name, subject, grade,
row_number() over (partition by name order by grade desc),
rank() over (partition by name order by grade desc),
dense_rank() over (partition by name order by grade desc)
from student_grades;
Про NULL в случае ранжирования:
Для SQL пустые NULL значения будут определяться одинаковым рангом
Функции смещения:
Это функции, которые позволяют перемещаясь по выделенной партиции таблицы обращаться к предыдущему значению строки или крайним значениям строк в партиции.
LAG() — функция, возвращающая предыдущее значение столбца по порядку сортировки.
LEAD() — функция, возвращающая следующее значение столбца по порядку сортировки.
На простом примере видно, как можно в одной строке получить текущую оценку, предыдущую и следующую оценки Пети в четвертях.
--создание таблицы
create table grades_quartal (
name varchar,
quartal varchar,
subject varchar,
grade int);
--наполнение таблицы данными
insert into grades_quartal (
values
('Петя', '1 четверть', 'физика', 4),
('Петя', '2 четверть', 'физика', 3),
('Петя', '3 четверть', 'физика', 4),
('Петя', '4 четверть', 'физика', 5)
);
--запрос всех данных из таблицы
select *
from grades_quartal;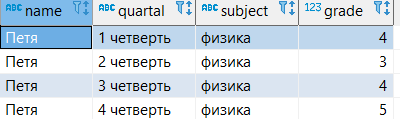
select name, quartal, subject, grade,
lag(grade) over (order by quartal) as previous_grade,
lead(grade) over (order by quartal) as next_grade
from grades_quartal;
FIRST_VALUE()/LAST_VALUE() — функции возвращающие первое или последнее значение столбца в указанной партиции. В качестве аргумента указывает столбец, значение которого нужно вернуть. В оконной функции под словом OVER обязательное указание ORDER BY условия.
В следующей версии статьи разберем отдельно такое понятие как фрейм окна функции или window frame и рассмотрим на простых примерах как он используется.
Telegram канал про аналитику данных и бизнес-анализ
Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы
У вас может возникнуть вопрос – «Что значит оконные?»
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.

Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
SELECT Название функции (столбец для вычислений) OVER ( PARTITION BY столбец для группировки ORDER BY столбец для сортировки ROWS или RANGE выражение для ограничения строк в пределах группы )
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:

OVER()
Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER() AS 'Sum' FROM Orders

Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' FROM Orders

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Medium) AS 'Sum' FROM Orders

К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна;
- «Значение» PRECEDING – определяет число строк перед текущей строкой (не допускается в предложении RANGE).;
- «Значение» FOLLOWING — определяет число строк после текущей строки (не допускается в предложении RANGE).
Разберем на примере:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Conversions ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS 'Sum' FROM Orders

В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders

Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders

Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG или LEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders

Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить (в этой статье я рассказываю как посчитать медиану, благодаря этой функции);
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders

Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.

Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders

Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.
WITH First AS ( SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders ) SELECT First_Click , SUM(Conversions) AS 'Conversions' FROM First GROUP BY First_Click

С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders

Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table

Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
WITH Ranks AS (
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table
)
SELECT
Medium
, SUM(Time_Decay) AS 'Value'
, SUM(Conversions) AS 'Conversions'
FROM Ranks
GROUP BY Medium
ORDER BY Value DESC

Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Полезные ссылки:
- SELECT — предложение OVER (Transact-SQL)
- Как работать с оконными функциями в Google BigQuery — подробное руководство
- Модель атрибуции на основе онлайн/офлайн данных в Google BigQuery
- Об авторе
- Свежие записи

Время на прочтение
4 мин
Количество просмотров 247K
Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свой путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений — все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом
--создание таблицы
create table student_grades (
name varchar,
subject varchar,
grade int);
-- наполнение таблицы данными
insert into student_grades (
values
('Петя', 'русский', 4),
('Петя', 'физика', 5),
('Петя', 'история', 4),
('Маша', 'математика', 4),
('Маша', 'русский', 3),
('Маша', 'физика', 5),
('Маша', 'история', 3));
--запрос всех данных из таблицы
select *
from student_grades;
Время на прочтение
4 мин
Количество просмотров 247K
Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свой путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений — все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом
--создание таблицы
create table student_grades (
name varchar,
subject varchar,
grade int);
-- наполнение таблицы данными
insert into student_grades (
values
('Петя', 'русский', 4),
('Петя', 'физика', 5),
('Петя', 'история', 4),
('Маша', 'математика', 4),
('Маша', 'русский', 3),
('Маша', 'физика', 5),
('Маша', 'история', 3));
--запрос всех данных из таблицы
select *
from student_grades;
SQL часто используется для вычислений в данных различных метрик или агрегаций значений по измерениям. Помимо функций агрегации для этого широко используются оконные функции.
Оконная функция в SQL — функция, которая работает с выделенным набором строк (окном, партицией) и выполняет вычисление для этого набора строк в отдельном столбце.
Партиции (окна из набора строк) — это набор строк, указанный для оконной функции по одному из столбцов или группе столбцов таблицы. Партиции для каждой оконной функции в запросе могут быть разделены по различным колонкам таблицы.
В чем заключается главное отличие оконных функций от функций агрегации с группировкой?
При использовании агрегирующих функций предложение GROUP BY сокращает количество строк в запросе с помощью их группировки.
При использовании оконных функций количество строк в запросе не уменьшается по сравнении с исходной таблицей.
Порядок расчета оконных функций в SQL запросе
Сначала выполняется команда выборки таблиц, их объединения и возможные подзапросы под командой FROM.
Далее выполняются условия фильтрации WHERE, группировки GROUP BY и возможная фильтрация c HAVING
Только потом применяется команда выборки столбцов SELECT и расчет оконных функций под выборкой.
После этого идет условие сортировки ORDER BY, где тоже можно указать столбец расчета оконной функции для сортировки.
Здесь важно уточнить, что партиции или окна оконных функций создаются после разделения таблицы на группы с помощью команды GROUP BY, если эта команда используется в запросе.
Синтаксис оконных функций
Синтаксис оконных функций вне зависимости от их класса будет так или иначе состоять из идентичных команд.
Оконные функции можно прописывать как под командой SELECT, так и в отдельном ключевом слове WINDOW, где окну дается алиас (псевдоним), к которому можно обращаться в SELECT выборке.
Классы Оконных функций
Множество оконных функций можно разделять на 3 класса:
-
Агрегирующие (Aggregate)
-
Ранжирующие (Ranking)
-
Функции смещения (Value)
Агрегирующие:
Можно применять любую из агрегирующих функций — SUM, AVG, COUNT, MIN, MAX
select name, subject, grade,
sum(grade) over (partition by name) as sum_grade,
avg(grade) over (partition by name) as avg_grade,
count(grade) over (partition by name) as count_grade,
min(grade) over (partition by name) as min_grade,
max(grade) over (partition by name) as max_grade
from student_grades;
Ранжирующие:
В ранжирующих функция под ключевым словом OVER обязательным идет указание условия ORDER BY, по которому будет происходить сортировка ранжирования.
ROW_NUMBER() — функция вычисляет последовательность ранг (порядковый номер) строк внутри партиции, НЕЗАВИСИМО от того, есть ли в строках повторяющиеся значения или нет.
RANK() — функция вычисляет ранг каждой строки внутри партиции. Если есть повторяющиеся значения, функция возвращает одинаковый ранг для таких строчек, пропуская при этом следующий числовой ранг.
DENSE_RANK() — то же самое что и RANK, только в случае одинаковых значений DENSE_RANK не пропускает следующий числовой ранг, а идет последовательно.
select name, subject, grade,
row_number() over (partition by name order by grade desc),
rank() over (partition by name order by grade desc),
dense_rank() over (partition by name order by grade desc)
from student_grades;
Про NULL в случае ранжирования:
Для SQL пустые NULL значения будут определяться одинаковым рангом
Функции смещения:
Это функции, которые позволяют перемещаясь по выделенной партиции таблицы обращаться к предыдущему значению строки или крайним значениям строк в партиции.
LAG() — функция, возвращающая предыдущее значение столбца по порядку сортировки.
LEAD() — функция, возвращающая следующее значение столбца по порядку сортировки.
На простом примере видно, как можно в одной строке получить текущую оценку, предыдущую и следующую оценки Пети в четвертях.
--создание таблицы
create table grades_quartal (
name varchar,
quartal varchar,
subject varchar,
grade int);
--наполнение таблицы данными
insert into grades_quartal (
values
('Петя', '1 четверть', 'физика', 4),
('Петя', '2 четверть', 'физика', 3),
('Петя', '3 четверть', 'физика', 4),
('Петя', '4 четверть', 'физика', 5)
);
--запрос всех данных из таблицы
select *
from grades_quartal;
select name, quartal, subject, grade,
lag(grade) over (order by quartal) as previous_grade,
lead(grade) over (order by quartal) as next_grade
from grades_quartal;
FIRST_VALUE()/LAST_VALUE() — функции возвращающие первое или последнее значение столбца в указанной партиции. В качестве аргумента указывает столбец, значение которого нужно вернуть. В оконной функции под словом OVER обязательное указание ORDER BY условия.
В следующей версии статьи разберем отдельно такое понятие как фрейм окна функции или window frame и рассмотрим на простых примерах как он используется.
Telegram канал про аналитику данных и бизнес-анализ
Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы
У вас может возникнуть вопрос – «Что значит оконные?»
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.
Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
SELECT Название функции (столбец для вычислений) OVER ( PARTITION BY столбец для группировки ORDER BY столбец для сортировки ROWS или RANGE выражение для ограничения строк в пределах группы )
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:
OVER()
Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER() AS 'Sum' FROM Orders
Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' FROM Orders
Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Medium) AS 'Sum' FROM Orders
К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна;
- «Значение» PRECEDING – определяет число строк перед текущей строкой (не допускается в предложении RANGE).;
- «Значение» FOLLOWING — определяет число строк после текущей строки (не допускается в предложении RANGE).
Разберем на примере:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Conversions ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS 'Sum' FROM Orders
В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders
Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders
Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG или LEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders
Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить (в этой статье я рассказываю как посчитать медиану, благодаря этой функции);
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders
Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.
Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders
Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.
WITH First AS ( SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders ) SELECT First_Click , SUM(Conversions) AS 'Conversions' FROM First GROUP BY First_Click
С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders
Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table
Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
WITH Ranks AS (
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table
)
SELECT
Medium
, SUM(Time_Decay) AS 'Value'
, SUM(Conversions) AS 'Conversions'
FROM Ranks
GROUP BY Medium
ORDER BY Value DESC
Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Полезные ссылки:
- SELECT — предложение OVER (Transact-SQL)
- Как работать с оконными функциями в Google BigQuery — подробное руководство
- Модель атрибуции на основе онлайн/офлайн данных в Google BigQuery
- Об авторе
- Свежие записи
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
[badge style=»blue»]Примечание[/badge] Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010: 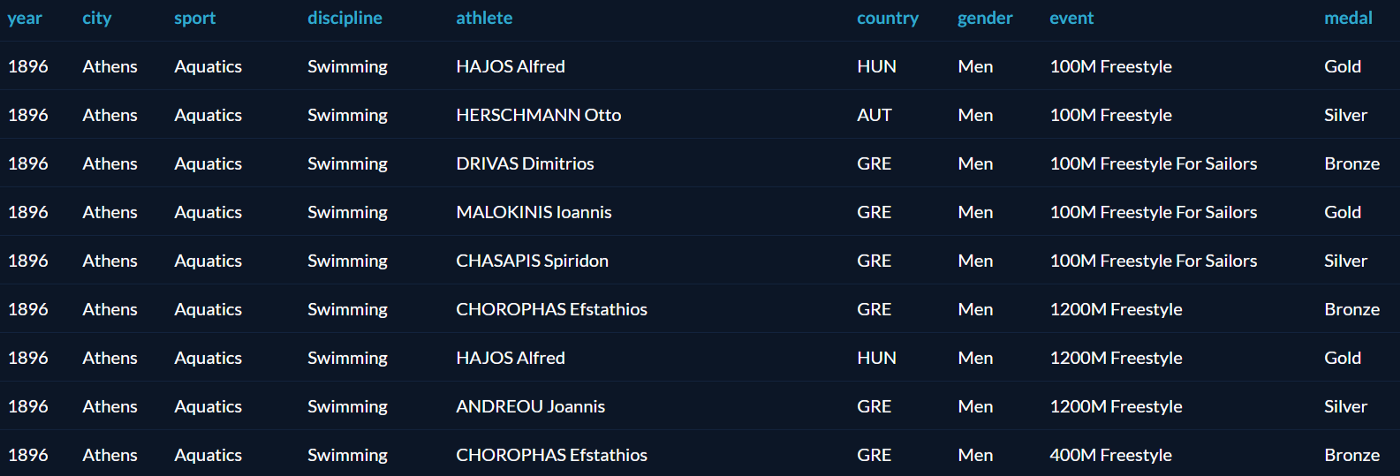
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
[badge style=»blue»]Примечание[/badge] Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
[badge style=»blue»]Примечание[/badge] Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
ROW_NUMBER и ORDER BY
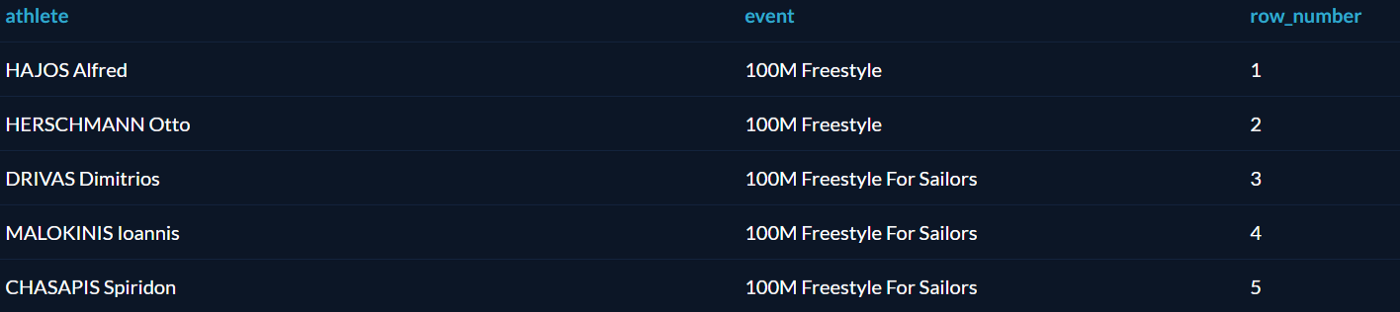
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
SELECT
athlete,
event,
ROW_NUMBER() OVER() AS row_number
FROM Summer_Medals
ORDER BY row_number ASC;
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
SELECT
athlete,
event,
ROW_NUMBER() OVER() AS row_number
FROM Summer_Medals
ORDER BY row_number ASC;
Каждая пара «спортсмен — вид спорта» получила номер, причём к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:
SELECT
sport,
ROW_NUMBER() OVER(ORDER BY sport ASC) AS Row_N
FROM (
SELECT DISTINCT sport
FROM Summer_Medals
) AS sports
ORDER BY sport ASC;
PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
LAG
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы
WITH Tennis_Gold AS (
SELECT
Athlete,
Gender,
Year,
Country
FROM
Summer_Medals
WHERE
Year >= 2004 AND
Sport = 'Tennis' AND
event = 'Singles' AND
Medal = 'Gold')-- Оконная функция разделяет по полу и берёт чемпиона из предыдущей строки
SELECT
Athlete as Champion,
Gender,
Year,
LAG(Athlete) OVER (PARTITION BY gender
ORDER BY Year ASC) AS Last_Champion
FROM Tennis_Gold
ORDER BY Gender ASC, Year ASC;
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
LEAD
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы
WITH Tennis_Gold AS (
SELECT
Athlete,
Gender,
Year,
Country
FROM
Summer_Medals
WHERE
Year >= 2004 AND
Sport = 'Tennis' AND
event = 'Singles' AND
Medal = 'Gold')-- Оконная функция разделяет по полу и берёт чемпиона из следующей строки
SELECT
Athlete as Champion,
Gender,
Year,
LEAD(Athlete) OVER (PARTITION BY gender
ORDER BY Year ASC) AS Future_Champion
FROM Tennis_Gold
ORDER BY Gender ASC, Year ASC;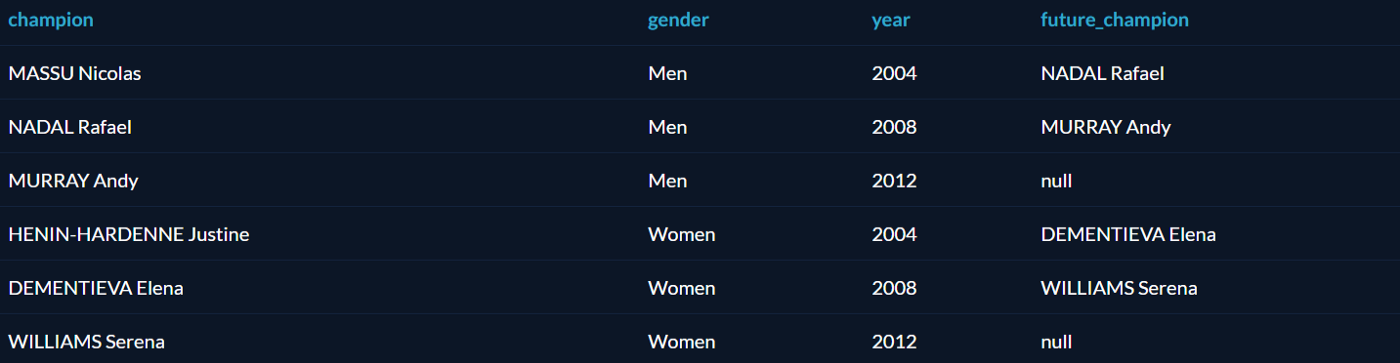
RANK
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
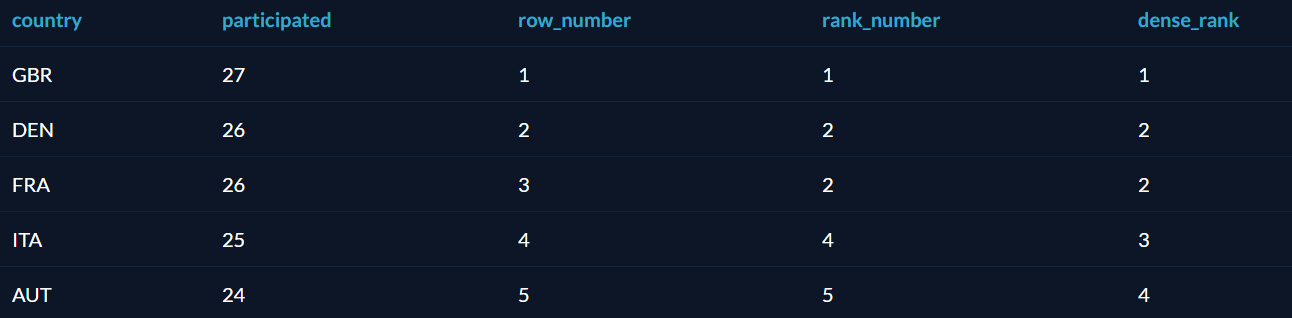
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Вот код:
-- Табличное выражение выбирает страны и считает годы
WITH countries AS (
SELECT
Country,
COUNT(DISTINCT year) AS participated
FROM
Summer_Medals
WHERE
Country in ('GBR', 'DEN', 'FRA', 'ITA','AUT')
GROUP BY
Country)
-- Разные оконные функции ранжируют страны
SELECT
Country,
participated,
ROW_NUMBER()
OVER(ORDER BY participated DESC) AS Row_Number,
RANK()
OVER(ORDER BY participated DESC) AS Rank_Number,
DENSE_RANK()
OVER(ORDER BY participated DESC) AS Dense_Rank
FROM countries
ORDER BY participated DESC;Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.
Адаптированный перевод статьи «Intro to Window Functions in SQL»
В языке Transact-SQL существует очень полезный и мощный инструмент для формирования различных аналитических отчетов – это инструкция OVER, которая работает совместно с так называемыми «оконными функциями», именно об этом мы сегодня с Вами и поговорим.

Содержание
- Инструкция OVER в Transact-SQL
- Упрощенный синтаксис инструкции OVER
- Оконные функции в Transact-SQL
- Исходные данные для примеров
- Агрегатные оконные функции
- Ранжирующие оконные функции
- Оконные функции смещения
- Аналитические оконные функции
Инструкция OVER в Transact-SQL
OVER – это инструкция T-SQL, которая определяет окно для применения оконной функции. «Окно» в Microsoft SQL Server – это контекст, в котором работает функция с определённым набором строк, относящихся к текущей строке.
Оконная функция – это функция, которая соответственно работает с окном, т.е. набором строк, и возвращает значение на основе неких вычислений.
Как я уже отметил, оконные функции используют в аналитических отчетах, например, для вычисления каких-то статистических значений (суммы, скользящие средние, промежуточные итоги и так далее) для каждой строки результирующего набора данных.
Честно скажу это очень удобный и полезный функционал Microsoft SQL Server. Впервые поддержка оконных функций появилась в версии Microsoft SQL Server 2005, в которой была реализованы базовая функциональность. В Microsoft SQL Server 2012 функционал оконных функций был расширен, и теперь он с лёгкостью решает много задач, которые до этого решались написанием дополнительного, в некоторых случаях, сложного, непонятного кода (вложенные запросы и т.д.).
Упрощенный синтаксис инструкции OVER
Оконная функция (столбец для вычислений) OVER (
[PARTITION BY столбец для группировки]
[ORDER BY столбец для сортировки]
[ROWS или RANGE выражение для ограничения строк в пределах группы]
)
В выражении для ограничения строк в группе можно использовать следующие ключевые слова:
- ROWS – ограничивает строки;
- RANGE — логически ограничивает строки за счет указания диапазона значений в отношении к значению текущей строки;
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы. Данная инструкция используется только как начальная точка окна;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы, соответственно, она может быть указана только как конечная точка окна;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке, она может быть задана как начальная или как конечная точка;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна, при этом верхняя граница не может быть меньше нижней границы;
- «Значение» PRECEDING – определяет число строк перед текущей строкой. Эта инструкция не допускается в предложении RANGE;
- «Значение» FOLLOWING — определяет число строк после текущей строки. Если FOLLOWING используется как начальная точка окна, то конечная точка должна быть также указана с помощью FOLLOWING. Эта инструкция не допускается в предложении RANGE.
Примечание! Чтобы указать выражение для дополнительного ограничения строк (ROWS или RANGE) в окне должна быть указана инструкция ORDER BY.
А сейчас давайте рассмотрим оконные функции, которые существуют в Transact-SQL.
Заметка! Функции TRIM, LTRIM и RTRIM в T-SQL – описание, отличия и примеры.
Оконные функции в Transact-SQL
В T-SQL оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать несколько оконных функций. Если инструкция PARTITION BY не указана, функция будет обрабатывать все строки результирующего набора. Некоторые функции не поддерживают инструкцию ORDER BY, ROWS или RANGE.
Исходные данные для примеров
Перед тем как перейти к рассмотрению использования оконных функций, давайте сначала создадим тестовые данные, для того чтобы выполнять примеры.
В качестве сервера у меня будет выступать Microsoft SQL Server 2016 Express.
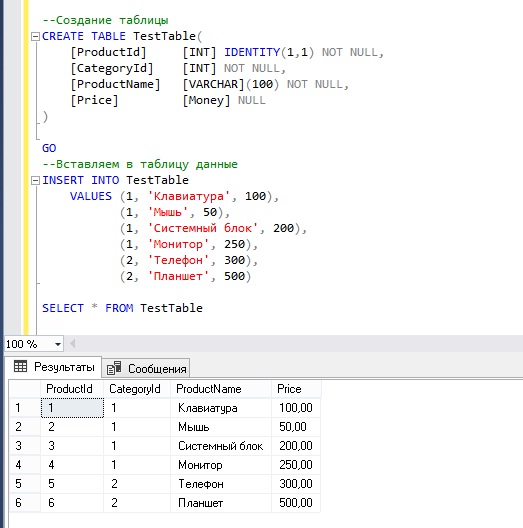
Допустим, у нас будет таблица TestTable, которая содержит список товаров с некоторыми характеристиками.
--Создание таблицы
CREATE TABLE TestTable(
[ProductId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryId] [INT] NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [Money] NULL
)
GO
--Вставляем в таблицу данные
INSERT INTO TestTable
VALUES (1, 'Клавиатура', 100),
(1, 'Мышь', 50),
(1, 'Системный блок', 200),
(1, 'Монитор', 250),
(2, 'Телефон', 300),
(2, 'Планшет', 500)
SELECT * FROM TestTable
Агрегатные оконные функции
Агрегатные функции – это функции, которые выполняют на наборе данных вычисления и возвращают итоговое значение. Агрегатные функции, я думаю, всем известны — это, например:

- SUM – возвращает сумму значений в столбце;
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются). Если написать COUNT(*), то будут учитываться все записи, т.е. все строки. Возвращает тип данных INT;
- COUNT_BIG – работает также как COUNT, только возвращает тип данных BIGINT.
Обычно агрегатные функции используются в сочетании с инструкцией GROUP BY, которая группирует строки, но их также можно использовать и без GROUP BY, например, с использованием инструкции OVER, и в данном случае они будут вычислять значения в определённом окне (наборе данных) для каждой текущей строки. Это очень удобно, если Вам необходимо получить какую-нибудь величину по отношению к общей сумме, например.
Пример использования агрегатных оконных функций с инструкцией OVER.
В этом примере продемонстрировано простое применение некоторых агрегатных оконных функций.
SELECT ProductId, ProductName, CategoryId, Price,
SUM(Price) OVER (PARTITION BY CategoryId) AS [SUM],
AVG(Price) OVER (PARTITION BY CategoryId) AS [AVG],
COUNT(Price) OVER (PARTITION BY CategoryId) AS [COUNT],
MIN(Price) OVER (PARTITION BY CategoryId) AS [MIN],
MAX(Price) OVER (PARTITION BY CategoryId) AS [MAX]
FROM TestTable
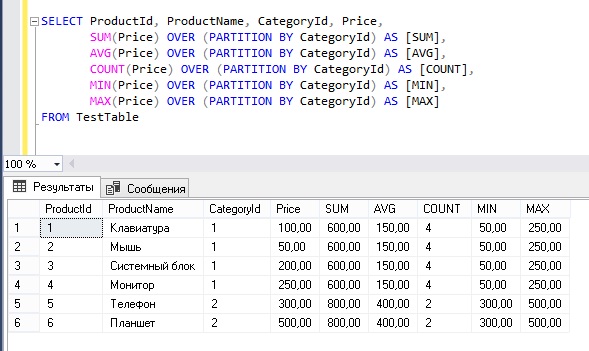
Как видите, у нас вывелись все строки, включая столбцы с агрегированными данными, сгруппированными по категории.
Ранжирующие оконные функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в группе. Например, их можно использовать для того, чтобы пронумеровать строки по группам или выставить ранг и составить рейтинг.
В Microsoft SQL Server существуют следующие ранжирующие функции:
- ROW_NUMBER – функция возвращает номер строки, используется для нумерации строк в секции результирующего набора;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая возвращает результирующий набор, разделённый на группы по определенному столбцу.
Пример использования ранжирующих оконных функций с инструкцией OVER.
В данном примере мы пронумеруем строки в каждой категории, при этом используем сортировку по столбцу ProductId, а также выставим ранг каждому товару в категории на основе его цены.
SELECT ProductId, ProductName, CategoryId, Price,
ROW_NUMBER() OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [ROW_NUMBER],
RANK() OVER (PARTITION BY CategoryId ORDER BY Price) AS [RANK]
FROM TestTable
ORDER BY ProductId
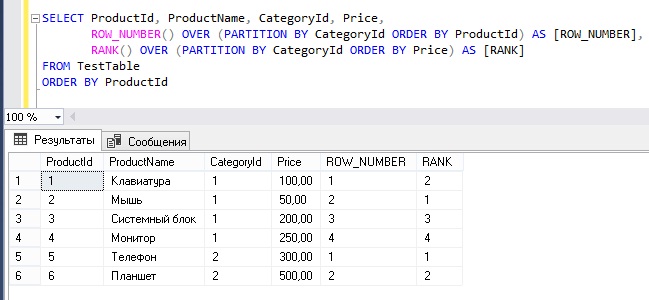
Более детально про ранжирующие функции мы говорили в материале – Функции ранжирования и нумерации в Transact-SQL.
Оконные функции смещения
Функции смещения – это функции, которые позволяют перемещаться и, соответственно, обращаться к разным строкам в наборе данных (окне) относительно текущей строки или просто обращаться к значениям в начале или в конце окна. Эти функции появились в Microsoft SQL Server 2012.
К функциям смещения в T-SQL относятся:
- LEAD – функция обращается к данным из следующей строки набора данных. Ее можно использовать, например, для того чтобы сравнить текущее значение строки со следующим. Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- LAG – функция обращается к данным из предыдущей строки набора данных. В данном случае функцию можно использовать для того, чтобы сравнить текущее значение строки с предыдущим. Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE — функция возвращает первое значение из набора данных, в качестве параметра принимает столбец, значение которого необходимо вернуть;
- LAST_VALUE — функция возвращает последнее значение из набора данных, в качестве параметра принимает столбец, значение которого необходимо вернуть.
Пример использования оконных функций смещения в T-SQL.
В этом примере сначала мы вернем следующее и предыдущее значение идентификатора товара в категории. Затем с помощью FIRST_VALUE и LAST_VALUE получим первое и последнее значение идентификатора товара в категории, при этом в качестве примера я покажу, как используется синтаксис дополнительного ограничения строк. А потом, используя необязательные параметры функций LEAD и LAG, мы сместимся уже на 2 строки относительно текущей, при этом, если после смещения функцией LAG такой строки не окажется, нам вернется 0, так как мы укажем третий необязательный параметр со значением 0.
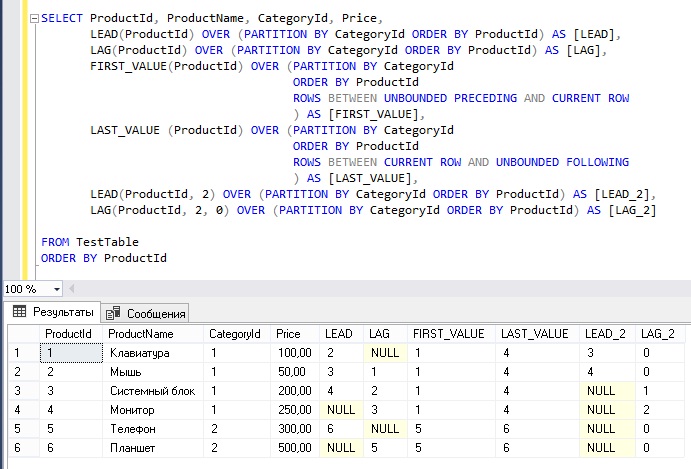
SELECT ProductId, ProductName, CategoryId, Price,
LEAD(ProductId) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LEAD],
LAG(ProductId) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LAG],
FIRST_VALUE(ProductId) OVER (PARTITION BY CategoryId
ORDER BY ProductId
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS [FIRST_VALUE],
LAST_VALUE (ProductId) OVER (PARTITION BY CategoryId
ORDER BY ProductId
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS [LAST_VALUE],
LEAD(ProductId, 2) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LEAD_2],
LAG(ProductId, 2, 0) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LAG_2]
FROM TestTable
ORDER BY ProductId
Аналитические оконные функции
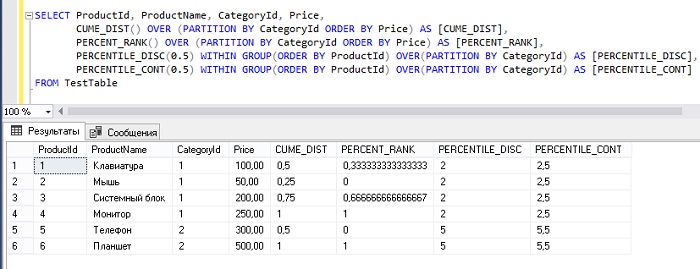
Здесь я перечислю так называемые функции распределения, которые возвращают информацию о распределении данных. Эти функции очень специфичны и в основном используются для статистического анализа, к ним относятся:
- CUME_DIST — вычисляет и возвращает интегральное распределение значений в наборе данных. Иными словами, она определяет относительное положение значения в наборе;
- PERCENT_RANK — вычисляет и возвращает относительный ранг строки в наборе данных;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
У функций PERCENTILE_CONT и PERCENTILE_DISC синтаксис немного отличается, столбец, по которому сортировать данные, указывается с помощью ключевого слова WITHIN GROUP.
Пример использования аналитических оконных функций в T-SQL.
SELECT ProductId, ProductName, CategoryId, Price,
CUME_DIST() OVER (PARTITION BY CategoryId ORDER BY Price) AS [CUME_DIST],
PERCENT_RANK() OVER (PARTITION BY CategoryId ORDER BY Price) AS [PERCENT_RANK],
PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY ProductId) OVER(PARTITION BY CategoryId) AS [PERCENTILE_DISC],
PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY ProductId) OVER(PARTITION BY CategoryId) AS [PERCENTILE_CONT]
FROM TestTable
Оконные функции языка T-SQL мы рассмотрели, некоторые из них, как я уже говорил, очень полезны и значительно упрощают написание SQL запросов, всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL, у меня на этом все, пока!
Заметка! Все возможности языка SQL и T-SQL очень подробно рассматриваются в моих видеокурсах по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL в Microsoft SQL Server.
Вопрос 1
Какие ОС называются мультипрограммными
1. обеспечивающие одновременную работу нескольких пользователей
2. поддерживающие сетевую работу компьютеров
+3. обеспечивающие запуск одновременно нескольких программ
4. состоящие более чем из одной программы
Вопрос 2
Какие существуют способы реализации ядра системы?
+1. многоуровневая (многослойная) организация
+2. микроядерная организация
3. реализация распределеннная
4. монолитная организация
Вопрос 3
Что обычно входит в состав ядра ОС
+1. высокоуровневые диспетчеры ресурсов
+2. аппаратная поддержка функций ОС процессором
+ 3. базовые исполнительные модули
+ 4. набор системных API-функций
Вопрос 4
Какие особенности характерны для современных универсальных операционных систем?
+ 1. поддержка многозадачности
+ 2. поддержка сетевых функций
+ 3. обеспечение безопасности и защиты данных
4. предоставление большого набора системных функций разработчикам приложений
Вопрос 5
Какие утверждения относительно понятия «API-функция» являются правильными?
+ 1. API-функции определяют прикладной программный интерфейс
+ 2. API-функции используются при разработке приложений для доступа к ресурсам компьютера
3. API-функции реализуют самый нижний уровень ядра системы
4. API-функции — это набор аппаратно реализованных функций системы
Вопрос 6
Какие особенности характерны для ОС Unix
+ 1. открытость и доступность исходного кода
2. ориентация на использование оконного графического интерфейса
+ 3. использование языка высокого уровня С
+ 4. возможность достаточно легкого перехода на другие аппаратные платформы
Вопрос 7
Какие типы операционных систем используются наиболее часто в настоящее время?
+ 1. системы семейства Windows
+ 2. системы семейства Unix/Linux
3. системы семейства MS DOS
4. системы семейства IBM OS 360/370
Вопрос 8
Какие задачи необходимо решать при создании мультипрограммных ОС
+ 1. защита кода и данных разных приложений, размещенных вместе в основной памяти
+ 2. централизованное управление ресурсами со стороны ОС
+ 3. переключение процессора с одного приложения на другое
4. необходимость размещения в основной памяти кода и данных сразу многих приложений
Вопрос 9
Какое соотношение между используемыми на СЕРВЕРАХ операционными системами сложилось в настоящее время?
+ 1. примерно поровну используются системы семейств Windows и Unix/Linux
2. около 10 % — системы семейства Windows, около 90 % — системы смейства Unix/Linux
3. около 90 % — системы семейства Windows, около 10 % — системы семейства Unix/Linux
4. около 30 % — системы семейства Windows, около 30 % — системы семейства Unix/Linux, около 40 % — другие системы
Вопрос 10
Какие утверждения относительно понятия «Ядро операционной системы» являются правильными?
+ 1. ядро реализует наиболее важные функции ОС
+ 2. подпрограммы ядра выполняются в привилегированном режиме работы процессора
3. ядро в сложных ОС может строиться по многоуровневому принципу
4. ядро всегда реализуется на аппаратном уровне
Вопрос 11
Какие сообщения возникают при нажатии на клавиатуре алфавитно-цифровой клавиши?
+ 1. WM_KeyDown
+ 2. WM_Char
+ 3. WM_KeyUp
4. WM_KeyPress
Вопрос 12
Какие шаги в алгоритме взаимодействия приложения с системой выполняются операционной системой
1. формирование сообщения и помещение его в системную очередь
+ 2. распределение сообщений по очередям приложений
+ 3. вызов оконной функции для обработки сообщения
4. извлечение сообщения из очереди приложения
Вопрос 13
Что представляет собой понятие “сообщение” (message)?
1. небольшую структуру данных, содержащую информацию о некотором событии
2. специальную API-функцию, вызываемую системой при возникновении события
3. однобайтовое поле с кодом происшедшего события
+ 4. небольшое окно, выводящее пользователю информацию о возникшем событии
Вопрос 14
Какие утверждения относительно иерархии окон являются справедливыми
+ 1. главное окно может содержать любое число подчиненных окон
+ 2. любое подчиненное окно может содержать свои подчиненные окна
3. подчиненные окна могут быть двух типов – дочерние и всплывающие
+ 4. приложение может иметь несколько главных окон
Вопрос 15
Как можно узнать координаты текущего положения мыши при нажатии левой кнопки
+ 1. с помощью события WM_LbuttonDown и его поля LPARAM
2. с помощью события WM_LbuttonDown и его поля WPARAM
3. с помощью события WM_LbuttonDown и его полей WPARAM и LPARAM
4. с помощью события WM_LbuttonCoordinates
Вопрос 16
Какие функции можно использовать для получения контекста устройства?
+ 1. GetDC
+ 2. BeginPaint
3. ReleaseDC
4. CreateContext
Вопрос 17
Какая инструкция (оператор) является основной при написании оконной функции?
+ 1. инструкция множественного выбора типа Case — Of
2. условная инструкция if – then
3. инструкция цикла с известным числом повторений
4. инструкция цикла с неизвестным числом повторений
Вопрос 18
Какой вызов позволяет добавить строку в элемент-список?
+ 1. SendMessage (MyEdit, lb_AddString, 0, строка)
2. SendMessage (“Edit”, lb_AddString, 0, строка)
3. SendMessage (MyEdit, AddString, 0, строка)
4. SendMessage (MyEdit, строка, lb_AddString, 0)
Вопрос 19
Какие утверждения относительно оконной функции являются правильными
+ 1. оконная функция принимает 4 входных параметра
+ 2. тело оконной функции – это инструкция выбора с обработчиками событий
+ 3. оконная функция обязательно должна обрабатывать сообщение wm_Destroy
+ 4. оконная функция явно вызывается из основной функции приложения
Вопрос 20
Какие сообщения возникают при нажатии на клавиатуре функциональной клавиши?
+ 1. WM_KeyDown
+ 2. WM_KeyUp
3. WM_KeyPress
4. WM_Char
Вопрос 21
Что может быть причиной появления внутреннего прерывания
+ 1. попытка деления на ноль
2. попытка выполнения запрещенной команды
+ 3. попытка обращения по несуществующему адресу
4. щелчок кнопкой мыши
Вопрос 22
Какие операции определяют взаимодействие драйвера с контроллером
+ 1. проверка состояния устройства
+ 2. запись данных в регистры контроллера
+ 3. чтение данных из регистров контроллера
4. обработка прерываний от устройства
Вопрос 23
Какие операции включает в себя вызов обработчика нового прерывания
+ 1. обращение к таблице векторов прерываний для определения адреса первой команды вызываемого обработчика
2. сохранение контекста для прерываемого программного кода
+ 3. занесение в счетчик команд начального адреса вызываемого обработчика
+ 4. внесение необходимых изменений в таблицу векторов прерываний
Вопрос 24
Что входит в программный уровень подсистемы ввода/вывода
+ 1. драйверы
2. диспетчер ввода/вывода
+ 3. системные вызовы
4. контроллеры
Вопрос 25
Что определяет понятие “порт ввода/вывода”
+ 1. порядковый номер или адрес регистра контроллера
2. машинную команду ввода/вывода
3. устройство ввода/вывода
4. контроллер устройства ввода/вывода
Вопрос 26
Какие существуют типы прерываний
+ 1. внешние или аппаратные прерывания
+ 2. внутренние прерывания или исключения
+ 3. программные псевдопрерывания
4. системные прерывания
Вопрос 27
Какие утверждения относительно понятия прерывания являются правильными
+ 1. прерывания — это механизм реагирования вычислительной системы на происходящие в ней события
2. прерывания используются для синхронизации работы основных устройств вычислительной системы
+ 3. прерывания возникают в непредсказуемые моменты времени
4. прерывания — это основной механизм планирования потоков
Вопрос 28
Какую информацию могут содержать регистры контроллеров устройства
+ 1. текущее состояние устройства
+ 2. текущую выполняемую устройством команду
3. данные, передаваемые от устройства системе
4. данные, передаваемые системой устройству
Вопрос 29
Как выстраиваются аппаратные прерывания в зависимости от их приоритета
1. сбой аппаратуры > таймер > дисковые устройства > сетевые устройства > клавиатура и мышь
2. сбой аппаратуры > таймер > дисковые устройства > клавиатура и мышь > сетевые устройства
+ 3. таймер > сбой аппаратуры > дисковые устройства > сетевые устройства > клавиатура и мышь
4. сбой аппаратуры > дисковые устройства > таймер > сетевые устройства > клавиатура и мышь
Вопрос 30
Что может быть причиной появления внешнего прерывания
+ 1. нажатие клавиши на клавиатуре
+ 2. завершение дисковой операции
3. обращение выполняемой процессором команды по несуществующему адресу
4. попытка выполнения запрещенной команды
Краткий гайд, который поможет разобраться в оконных функциях ORDER BY и PARTITION BY.
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
%save-sc0%
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
SELECT
athlete,
event,
ROW_NUMBER() OVER() AS row_number
FROM Summer_Medals
ORDER BY row_number ASC;
Каждая пара «спортсмен — вид спорта» получила номер, причём к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:
SELECT
sport,
ROW_NUMBER() OVER(ORDER BY sport ASC) AS Row_N
FROM (
SELECT DISTINCT sport
FROM Summer_Medals
) AS sports
ORDER BY sport ASC;
PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
LAG
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы
WITH Tennis_Gold AS (
SELECT
Athlete,
Gender,
Year,
Country
FROM
Summer_Medals
WHERE
Year >= 2004 AND
Sport = 'Tennis' AND
event = 'Singles' AND
Medal = 'Gold')
-- Оконная функция разделяет по полу и берёт чемпиона из предыдущей строки
SELECT
Athlete as Champion,
Gender,
Year,
LAG(Athlete) OVER (PARTITION BY gender
ORDER BY Year ASC) AS Last_Champion
FROM Tennis_Gold
ORDER BY Gender ASC, Year ASC;
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
LEAD
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы
WITH Tennis_Gold AS (
SELECT
Athlete,
Gender,
Year,
Country
FROM
Summer_Medals
WHERE
Year >= 2004 AND
Sport = 'Tennis' AND
event = 'Singles' AND
Medal = 'Gold')
-- Оконная функция разделяет по полу и берёт чемпиона из следующей строки
SELECT
Athlete as Champion,
Gender,
Year,
LEAD(Athlete) OVER (PARTITION BY gender
ORDER BY Year ASC) AS Future_Champion
FROM Tennis_Gold
ORDER BY Gender ASC, Year ASC;
RANK
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Вот код:
-- Табличное выражение выбирает страны и считает годы
WITH countries AS (
SELECT
Country,
COUNT(DISTINCT year) AS participated
FROM
Summer_Medals
WHERE
Country in ('GBR', 'DEN', 'FRA', 'ITA','AUT')
GROUP BY
Country)
-- Разные оконные функции ранжируют страны
SELECT
Country,
participated,
ROW_NUMBER()
OVER(ORDER BY participated DESC) AS Row_Number,
RANK()
OVER(ORDER BY participated DESC) AS Rank_Number,
DENSE_RANK()
OVER(ORDER BY participated DESC) AS Dense_Rank
FROM countries
ORDER BY participated DESC;
Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.

Window functions are an advanced type of function in SQL. They let you work with observations more easily.
Window functions give you access to features like advanced analytics and data manipulation without the need to write complex queries.
In this lesson you will learn about what window functions are and how they work. Without further ado let’s get started.
What is a Window Function?
Before learning exactly what a window function is, let’s define the meaning of a term that will appear frequently in this article: result set.
In SQL, a result set is the data or result that is returned from a query. That is, it’s the result (table) of running the code of a select statement.
For you to understand what a window function is, let’s break the words down into pieces.
What exactly is a window in SQL?
A window is basically a set of rows or observations in a table or result set. In a table you may have more than one window depending on how you specify the query – you will learn about this shortly. A window is defined using the OVER() clause in SQL.
You will learn how to determine the number of windows in a result set later in this article.
What is a Function?
Functions are predefined in SQL and you use them to perform operations on data. They let you do things like aggregating data, formatting strings, extracting dates, and so on.
So windows functions are SQL functions that enable us to perform operations on a window – that is, a set of records.
The interesting thing about window functions is that with them you can specify the windows you want to apply the function on. For example, we can partition the full result set into various groups/windows.
Before we go into the syntax of Window functions, let’s have a look at the categories of window functions.
Different Types of Window Functions
There are a lot of window functions that exist in SQL but they are primarily categorized into 3 different types:
- Aggregate window functions
- Value window functions
- Ranking window functions
Aggregate window functions are used to perform operations on sets of rows in a window(s). They include SUM(), MAX(), COUNT(), and others.
Rank window functions are used to rank rows in a window(s). They include RANK(), DENSE_RANK(), ROW_NUMBER(), and others.
Value window functions are like aggregate window functions that perform multiple operations in a window, but they’re different from aggregate functions. They include things like LAG(), LEAD(), FIRST_VALUE(), and others. We will see their usefulness later in the section.
Sample Table
In this tutorial you will be working with a table called student_score which contains data such as student_id, student_name, dep_name and score.
You can create the table using the following code:
DROP TABLE IF EXISTS student_score;
CREATE TABLE student_score (
student_id SERIAL PRIMARY KEY,
student_name VARCHAR(30),
dep_name VARCHAR(40),
score INT
);
INSERT INTO student_score VALUES (11, 'Ibrahim', 'Computer Science', 80);
INSERT INTO student_score VALUES (7, 'Taiwo', 'Microbiology', 76);
INSERT INTO student_score VALUES (9, 'Nurain', 'Biochemistry', 80);
INSERT INTO student_score VALUES (8, 'Joel', 'Computer Science', 90);
INSERT INTO student_score VALUES (10, 'Mustapha', 'Industrial Chemistry', 78);
INSERT INTO student_score VALUES (5, 'Muritadoh', 'Biochemistry', 85);
INSERT INTO student_score VALUES (2, 'Yusuf', 'Biochemistry', 70);
INSERT INTO student_score VALUES (3, 'Habeebah', 'Microbiology', 80);
INSERT INTO student_score VALUES (1, 'Tomiwa', 'Microbiology', 65);
INSERT INTO student_score VALUES (4, 'Gbadebo', 'Computer Science', 80);
INSERT INTO student_score VALUES (12, 'Tolu', 'Computer Science', 67);Syntax for Window Functions
In a simple expression, a window function looks like this:
function(expression|column) OVER(
[ PARTITION BY expr_list optional]
[ ORDER BY order_list optional]
)Let’s go over the syntax piece by piece:
function(expression|column) is the window function such as SUM() or RANK().
OVER() specifies that the function before it is a window function not an ordinary one. So when the SQL engine sees the over clause it will know that the function before the over clause is a window function.
The OVER() clause has some parameters which are optional depending on what you want to achieve. The first one being PARTITION BY.
The PARTITION BY divides the result set into different partitions/windows. For example if you specify the PARTITION BY clause by a column(s) then the result-set will be divided into different windows of the value of that column(s).
The expr_list in the PARTITION BY clause is:
expression | column_name [, expr_list ]Which means that the PARTITION BY can have an expression, a column, or more than one occurrence or an expression or column which must be separated by a comma. For example PARTITION BY column1, column2.
The next parameter ORDER BY is used to sort the observations in a window. The ORDER BY clause takes order_list which is:
expression | column_name [ ASC | DESC ]
[ NULLS FIRST | NULLS LAST ][, order_list ]where order_list can be a expression or column name and you can also specify the sort order (either ascending or descending), or you can sort any null values first or last. Also the order by can take many expressions or column names.
As stated earlier, the OVER() clause is used to specify the window in a result set. Now one thing to note is if any parameter is not specified in the OVER() clause the default number of windows in the result set will be one.
You use the PARTITION BY and ORDER BY parameters to determine or specify the numbers of windows. Let’s go over an example.
How to Use a Window Function – Example
Let’s go over an example of how to use a window function. Say for instance you want to compare the minimum score and maximum score from all the records in the table we created earlier. You can do that using a window function as shown below.
Remember that not specifying a partition clause in the OVER clause will cause all the windows to span through the entire dataset.
SELECT
*,
MAX(score) OVER() AS maximum_score,
MIN(score) OVER() AS minimum_score
FROM student_score;As you can see, we have the minimum and maximum salary across the entire dataset.
Also, note that the above query can be also achieved using subqueries like this:
SELECT *,
(SELECT MAX(score) FROM student_score) AS maximum_score,
(SELECT MIN(score) FROM student_score) AS minimum_score
FROM student_score;As you can see, the window function is easier to comprehend compared to the subquery method which looks a bit more advanced.
How to Use a Window Function with PARTITION BY
Say, for instance, that you want to split the dataset into different partitions. Then you want to compare each record in each partition with an aggregate value or a calculated value of each partition. You can specify the PARTITION BY clause in the OVER function.
For example, say you want to compare the maximum score and average score in each department with the individual score. You can do this by specifying the PARTITION BY clause in the OVER statement and also use it with the aggregate function you want to use to achieve your desired result.
SELECT
*,
MAX(score)OVER(PARTITION BY dep_name) AS dep_maximum_score,
ROUND(AVG(score)OVER(PARTITION BY dep_name), 2) AS dep_average_score
FROM student_score;You can see that the PARTITION BY clause specified in the OVER() clause split the result set into 4 different partitions. This is because there are 4 different departments in the dep_name column (which are Biochemistry, Computer Science, Industrial Chemistry, and Microbiology).
Now after the PARTITION BY clause, you can then calculate the aggregate function for each record in the different departments.

You can see from the above image that the aggregate function MAX() and AVG() is calculated for each partition.
Other Examples of Window Functions
Let’s go over some of the common window functions you will work with in SQL.
How to Use the ROW_NUMBER Function
You use ROW_NUMBER() to assign serial numbers to records in a window. Say we want to assign serial numbers to the records in a partition. For example, we want to add row numbers to the dataset based on their names in alphabetical order. You can do that using the following code:
SELECT
*,
ROW_NUMBER() OVER(ORDER BY student_name) AS name_serial_number
FROM student_score;
As you can see from the above image, the student_name with the smallest value (that is, the one that falls earliest in the alphabet) is Gbadebo since it starts with G. Then 1 is added as its row number which is followed by the name that begins with H, and so on.
How to Use the RANK Function
RANK(), as the name implies, lets you rank observations in a window but with gaps. Let’s see what this means:
SELECT
*,
RANK()OVER(PARTITION BY dep_name ORDER BY score DESC)
FROM student_score;
As you can see in the above code, the result set was partitioned into different windows based on the department column. Then we used the ORDER BY clause to sort the student records based on their score in descending order in each partition. After that, we applied the RANK function.
Now concerning the gaps, as you can see in the highlighted part in the above image, two records in the Computer Science department have the same score (80). This caused both to be ranked with the value 2 (instead of one being ranked 2 and the other 3). So it doesn’t know how to handle a tie, basically.
You can avoid this scenario using another window function called DENSE_RANK that ranks observations in a window without these gaps.
How to Use the DENSE_RANK Function
DENSE_RANK is similar to RANK except that it ranks observations in a window without gaps.
SELECT
*,
DENSE_RANK()OVER(PARTITION BY dep_name ORDER BY score DESC)
FROM student_score;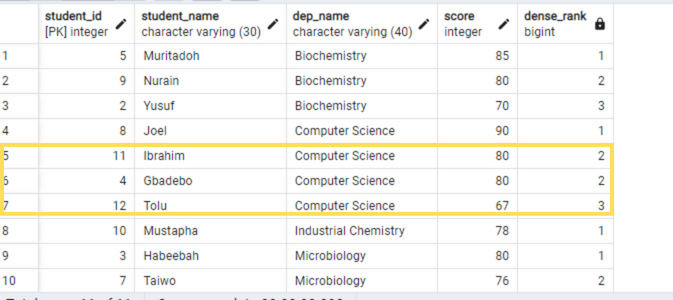
As you can see in the output above, when using DENSE_RANK, the next rank number (which is 3) was assigned to Tolu (unlike when using RANK which assigned Tolu a rank of 4, skipping 3 because of the tie).
How to Use the LAG Function
LAG is used to return the offset row before the current row within a window. By default it returns the previous row before the current row.
You typically use LAG when you want to compare the value of a previous row with the current row. It’s commonly applied in time-series analysis. For example:
SELECT
*,
LAG(score) OVER(PARTITION BY dep_name ORDER BY score)
FROM student_score;
As shown in the first partition, the first record in the biochemistry partition (Yusuf’s) does not have a previous value (that is, no record comes before it) so that’s why null was returned. Then moving to the next record – Muritadoh’s – it has a previous record, so it returns the previous value which is 70.
How to Use the Frame Clause in ORDER BY
Now you’ve learned some common window functions you might work with on a daily basis. So let’s move on to learning another key concept related to the ORDER BY clause called the frame clause.
A frame clause, as the name implies, provides the frame (that is, the set of rows in a window) on which the function is to be applied. You use it to provide the offset of rows to be included or calculated with the current row (that is, the rows before or after the current row – the SQL engine process row one after the other).
Now before we look into how to specify a frame clause, let’s look at some of the frame clause’s assumptions:
- First, a frame clause does not apply to ranking functions. The ranking function only ranks the observation in the window based on the
ORDER BYclause. - When using an aggregate window function, you may not include the
ORDER BYclause. But when you use theORDER BYclause, it’s a best practice to specify the frame clause for accurate results. What this means is say you want to use an aggregate window function and you want to also order the observations in that window by a column. It’s best practice is to specify a frame clause so that you will get an accurate result. But if you are not ordering the observations in the window when using an aggregate function, you don’t need to specify a frame clause.
You can specify a frame clause using two things – ROWS and RANGE. But in this part you will learn how to use the ROWS keyword since it is commonly used to specify a frame clause. The RANGE keyword is beyond the scope of this article.
The ROWS clause defines the frame in terms of the physical offset rows from the current rows. That is, it is used to specify the rows that will be used in conjunction with the current row for calculation.
For example the following frame clause ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING defines a frame that includes the current row, 1 row preceding it and 1 row following it.
Let’s look at the keywords that you can use in conjunction with the ROWS clause:
N PRECEDINGis a keyword you use to specify the N rows that will be included in the calculation along with the current row. For example3 PRECEDINGmeans 3 rows preceding the current row.N FOLLOWINGworks likeN PRECEDINGexcepts that it works in an opposite manner.N FOLLOWINGspecifies the numbers of row after the current row.UNBOUNDED PRECEDINGmeans all rows before the current row.UNBOUNDED FOLLOWINGmeans all rows after the current row.CURRENT ROWis used to specify the current row.
For example, let’s look at the below frame clause:
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW will use less than or equal to 2 rows before the current row, along with the current row for the calculation.
Frame clause example
Let’s look at an example. Say for instance you want to get the cumulative sum of all the student scores. You can do that by using a frame clause.
So first, to be able to do this, you need to first know the types of keywords you will specify in the frame clause.
Since you want to sum up all rows before the current row and the current row itself, you can use the UNBOUNDED PRECEDING keyword. Remember that this gets all rows before the current row and also uses the current row itself.
So the code to achieve that task is shown below:
SELECT
*,
SUM(score)OVER(ORDER BY student_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cummulative_sum
FROM student_scoreLet’s break down the window function code:
SUM(score)OVER(ORDER BY student_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cummulative_sum
Firstly in the OVER() clause, we sort the entire window – which is the whole dataset – using the student id.
Then we specify the frame clause which is ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. This is all rows before the current row and the current row will be used for calculation.
The result is shown in the below image:
The first row in the dataset does not have any row before it. But since we also specify the CURRENT ROW keyword as the last frame, then the SQL engine finds its sum which equals 65.
Then moving to the second row. It has 1 row before it. So the SQL engine sums the score of the first row 65 with the current row which is 70. That is why the result is 135…and so on down the table.
When to Use a Window Function
You’ve learned what window functions are in this tutorial. Some practical cases where you can use them are:
- When you want to compare an aggregate value in a window with individual records in that window.
- When you want to do things like ranking, percentile, cumulative sum or running total, moving average, and so on.
Conclusion
In this tutorial, you’ve learned what window functions are, and you’ve also looked at some of the clauses you can add in Windows functions. One example is the PARTITION BY clause, which divides the result set into separate partitions or windows.
You also learned how to utilize the ORDER BY clause to order observations in a window and you saw various common examples of window functions.
Finally, you learned another advanced clause that you can use with window functions, the frame clause, which allows you to access more features of a window.
Thank you for reading all the way to the end. You can use the tutorial listed below to learn about more SQL window functions.
9.22. Window Functions
9.22. Window Functions Window functions provide the ability to perform calculations across sets of rows that are related to the current …
PostgreSQL Documentation

Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started