304 Глава 21. Многомерное шкалирование В этом окне вы можете выбрать один из возможных типов матрицы. Если ваша матрица является квадратной (число строк равно числу столбцов) и симметричной (значения над главной диагональю равны значениям под главной диагональю), то следует оставить установленным переключатель Square symmetric (Квадратная симметричная). Этот тип матрицы используется в примере с многомерными ме- тодами, поскольку сравнения одного метода с другим и наоборот дают одинако- вый результат. Если матрица является квадратной, но не симметричной, следует установить переключатель Square asymmetric (Квадратная асимметричная). Такой тип матрицы используется в примере с социограммой студентов. Наконец, если ваша матрица не является квадратной, установите переключатель Rectangular (Прямоугольная) и введите число строк в расположенное рядом поле. Этот тип матрицы используется реже, например при шкалировании предпочтений, и в дан- ной книге не описывается.
В случае если необходимо, чтобы программа SPSS создала матрицу различий по имеющимся данным, в окне Multidimensional Scaling (Многомерное шкалирование) следует установить переключатель Create distances from data (Вычислить расстоя- ния по данным). В ответ SPSS создаст матрицу различий для тех переменных, ко- торые вы указали в списке Variables (Переменные). По умолчанию вычисляется Евклидово расстояние (по формуле Пифагора я 2 + Ь 2 = с 2), и если такой способ вычисления устраивает вас, то никаких дополнительных действий с вашей сто- роны не требуется. Если же вы хотите применить иной способ вычисления рас- стояния, то следует щелкнуть па кнопке Measure (Мера), открыв диалоговое ок- но Multidimensional Scaling: Create Measure from Data (Многомерное шкалирование: Создание меры для данных), представленное на рис. 21.3.
Рис. 21.3. Диалоговое окно Multidimensional Scaling: Create Measure from Data Как можно видеть, диалоговое окно содержит 3 области: Measure (Мера), Transform Values (Трансформация значений) и Create Distance Matrix (Создание матрицы расстоя- ний). Помимо формулы для Евклидова расстояния существует еще несколько
Задача
многомерного шкалирования состоит в
построении переменных на основе имеющихся
расстояний между объектами. В частности,
если нам даны расстояния между городами,
программа многомерного шкалирования
должна восстановить систему координат
(с точностью до поворота и единицы длины)
и приписать координаты каждому городу
так, чтобы зрительно карта и изображение
городов в этой системе координат совпали.
Близость может определяться не только
расстоянием в километрах, но и другими
показателями, такими как размеры
миграционных потоков между городами,
интенсивность телефонных звонков, а
также расстояниями в многомерном
признаковом пространстве. В последнем
случае задача построения такой системы
координат близка к задаче, решаемой
факторным анализом: сжатию данных,
описанию их небольшим числом переменных.
Нередко требуется также наглядное
представление свойств объектов. В этом
случае полезно придать координаты
переменным, расположив переменные в
геометрическом пространстве. С технической
точки зрения это всего лишь транспонирование
матрицы данных. Для определенности мы
будем говорить о создании геометрического
пространства для объектов, специально
оговаривая случаи анализа множества
свойств. В социальных исследованиях
методом многомерного шкалирования
создают зрительный образ «социального
пространства» объектов наблюдения
или свойств. Для такого образа наиболее
приемлемо создание двумерного
пространства.
Основная
идея метода состоит в приписывании
каждому объекту значений координат
так, чтобы матрица евклидовых расстояний
между объектами в этих координатах,
помноженная на константу оказалась
близка к матрице расстояний между
объектами, определенной из каких-либо
соображений ранее. Метод весьма трудоемкий
и рассчитан на анализ данных, имеющих
небольшое число объектов.
ЗАКЛЮЧЕНИЕ
В предложенном
методическом пособии представлены
методические аспекты анализа данных,
реализованного в статистическом пакете
SPSS. Дается краткое изложение содержания
методов и анализа получаемых статистических
результатов с демонстрацией в командах
и выдаче пакета. Возможности применения
методов математической статистики
проиллюстрированы на социологических
данных. Думается, основной задачей
пособия было не столько помочь получить
практические навыки по работе с
статистическим пакетом SPSS,
а, скорее, показать его возможности в
решении тех или иных проблем, связанных
с обработкой различного рода информации,
в первую очередь, в области гуманитарного
знания.
Изучение темы с
целью конкретизации и более глубокого
освоения предложенного пакета программ
можно будет развить в рамках соответствующего
лекционного курса.
Рекомендуемая литература
-
SPSSдляWindows. Руководство
пользователя SPSS, Книга 1. — М.: Статистические
системы и сервис. 1995. -
SPSSBASE8.0. Руководство
пользователя SPSS. — М.: СПСС РУСЬ. 1998. -
SPSSBASE8.0. Руководство по
применению SPSS. — М.: СПСС РУСЬ. 1998. -
SPSS
BASE 7.5. Syntax Reference GuideРуководство
пользователя SPSS. — Chicago:
1997. -
SPSS.
Regression Models 9.0. – Chicago, 1999. -
SPSS.
Exact tests 6.1 for windows. – Chicago, 1995. -
SPSS.
Professional statistics. – Chicago, 1994 -
Green
H.William. Econometric Analysis. — Upper Saddle River, New Jersey,
1997. -
Handbook
of Statistical Modeling for Social and Behavioral Sciences. — New
York and London: Plenium press, 1995. -
Айвазян
С.А., Мхиторян, В.С. Прикладная статистика
и основы эконометрики. — М.:»Юнити»,
1998. -
Толстова
Ю.Н. Анализ социологических данных.
Методология, дескриптивная статистика,
изучение связей между номинальными
признаками. — М.: Научный мир, 2000. -
Ростовцев
П.С., Костин В.С., Олех А.Л. Множественные
сравнения в таблицах для неальтернативных
вопросов// Анализ и моделирование
экономических процессов переходного
периода в России. Выпуск 4.- Новосибирск:
ИЭиОПП СО РАН, 1999. — С.148-164.
Соседние файлы в папке Методички
- #
- #
- #
304 Глава 21. Многомерное шкалирование В этом окне вы можете выбрать один из возможных типов матрицы. Если ваша матрица является квадратной (число строк равно числу столбцов) и симметричной (значения над главной диагональю равны значениям под главной диагональю), то следует оставить установленным переключатель Square symmetric (Квадратная симметричная). Этот тип матрицы используется в примере с многомерными ме- тодами, поскольку сравнения одного метода с другим и наоборот дают одинако- вый результат. Если матрица является квадратной, но не симметричной, следует установить переключатель Square asymmetric (Квадратная асимметричная). Такой тип матрицы используется в примере с социограммой студентов. Наконец, если ваша матрица не является квадратной, установите переключатель Rectangular (Прямоугольная) и введите число строк в расположенное рядом поле. Этот тип матрицы используется реже, например при шкалировании предпочтений, и в дан- ной книге не описывается.
В случае если необходимо, чтобы программа SPSS создала матрицу различий по имеющимся данным, в окне Multidimensional Scaling (Многомерное шкалирование) следует установить переключатель Create distances from data (Вычислить расстоя- ния по данным). В ответ SPSS создаст матрицу различий для тех переменных, ко- торые вы указали в списке Variables (Переменные). По умолчанию вычисляется Евклидово расстояние (по формуле Пифагора я 2 + Ь 2 = с 2), и если такой способ вычисления устраивает вас, то никаких дополнительных действий с вашей сто- роны не требуется. Если же вы хотите применить иной способ вычисления рас- стояния, то следует щелкнуть па кнопке Measure (Мера), открыв диалоговое ок- но Multidimensional Scaling: Create Measure from Data (Многомерное шкалирование: Создание меры для данных), представленное на рис. 21.3.
Рис. 21.3. Диалоговое окно Multidimensional Scaling: Create Measure from Data Как можно видеть, диалоговое окно содержит 3 области: Measure (Мера), Transform Values (Трансформация значений) и Create Distance Matrix (Создание матрицы расстоя- ний). Помимо формулы для Евклидова расстояния существует еще несколько
1.1 Подготовка данных к анализу
Анализ маркетинговой информации с применением программы SPSS включает выполнение следующих необходимых шагов, представленных на рисунке 1.1:
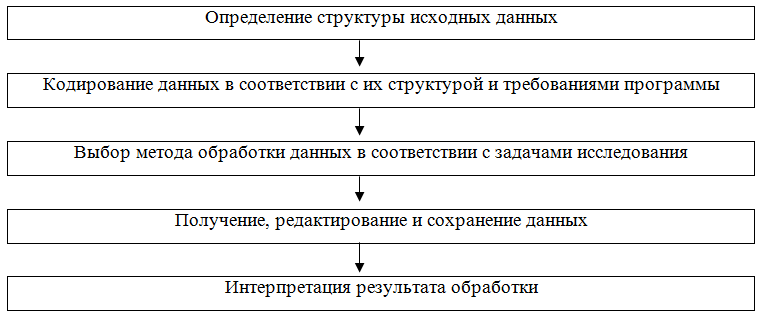
Рисунок 1.1 — Анализ данных с применением программы SPSS
- На первом этапе необходимо проверить правильность составления анкет, полноту заполнения и качество интервьюирования, а также репрезентативность выборки.
- На этапе кодирования необходимо присвоить код каждому возможному варианту ответа по каждому вопросу. С этой целью используются следующие типы шкал измерения переменных:
- Номинальная
- Порядковая (ранговая)
- Интервальная
- Относительная
От выбора шкалы (таблица 1.1) зависит вся последующая методика изучения данных и определение возможности расчета статистических показателей.
№ Тип шкалы Особенности построения 1 Номинальная Каждому свойству потребителя ставится в соответствие некоторый код, позволяющий отличить одно значение от другого. По данной шкале измеряются как
правило качественные характеристики объекта исследования. Например, значению свойства пол «мужской» присваивается код «1», «женский» — код «2».2 Порядковая Присваивает значения свойствам потребителя, находящимся на разных уровнях по отношению друг к другу. Ответы респондентов можно упорядочить по уровню
изучаемого свойства переменной. Например, по степени предпочтений покупателей различных марок товара, «наиболее предпочитаемой» присваиваем код «1», коды 2, 3, 4 присваиваются маркам по
степени убывания предпочтений.3 Интервальная Позволяет дать количественную оценку различиям между переменными, т.е. определить насколько одно значение схоже или отличается от другого.
Например, шкала Цельсия, календарь. Данная шкала также используется при кодировании ответов респондентов, полученных в результате применения в процессе анкетирования семантического
дифференциала. Например, когда от респондентов требуется оценить качество продукта по семибалльной шкале.4 Относительная Предполагает существование естественного нуля. Поэтому в данной шкале можно сравнивать значения переменной по отношению друг к другу. Это могут
быть физические характеристики (вес, длина, объем и пр.) и экономические характеристики (цена, объем продаж, прибыль и пр.).Таблица 1.1 — Типы шкал
В программе SPSS интервальная и относительная шкалы объединяются в метрическую шкалу.
- Выбор метода обработки данных основывается на итогах предыдущих этапов маркетинговых исследований, характеристиках информации, а также задачах, поставленных перед маркетинговым исследованием. Могут быть
использованы следующие виды анализа: описательные статистики, корреляционный анализ, построение таблиц сопряженности, кросс—табуляция, проверка статистических гипотез о виде распределения, дисперсионный анализ,
дискриминантный анализ, кластерный анализ, многомерное шкалирование, факторный анализ, анализ соответствий, регрессионный анализ, совместный анализ. - В результате проведенного анализа исследователь получает массив данных, доступный осмыслению и содержательной интерпретации. На данном этапе необходимо представить, отредактировать и сохранить полученные данные,
так как исчерпывающий анализ обычно требует многократной обработки данных с применением разных методов. - Интерпретация результата обработки данных — самостоятельная задача исследователя. Опираясь на полученные статистические данные важно выявить причинно—следственные отношения между изучаемыми признаками,
факторы, оказывающие наибольшее влияние на исследуемую проблему, дать грамотную обоснованную оценку ситуации и выстроить прогноз.
1.2 Структура редактора данных
Вверх
Файл исходной базы данных для проведения анализа в SPSS формируется в редакторе данных (Data Editor). Редактор данных имеет две вкладки: «Переменные» (Variable View) и «Данные» (Date View). Вкладки представляют
собой таблицы, содержащие информацию о данных, собранных для проведения анализа.
Во вкладке «Переменные» представлена таблица с данными, котрые описывают свойства переменных. Каждая строка отображает переменную (вопрос анкеты), каждый столбец — ее свойства.
В столбце «Имя» (Name) записывают имя переменной — это может быть номер или часть вопроса в анкете. Например, переменная «пол», «занятость», «марка». Имя переменной не является произвольным, оно может содержать буквы
латинского алфавита и цифры, а также некоторые символы: $, #. Длина имени не более 64 знаков. Не допускаются пробелы и буквы других алфавитов. Имя переменной должно начинаться с буквы и не может заканчиваться знаком
подчеркивания «__» и точкой.
В столбце «Тип» (Туре) задается тип переменной; текущим типом является числовой (Numeric). В подавляющем большинстве случаев лучше иметь дело с числовыми переменными. Если
требуется изменить тип переменной, нужно нажать на кнопку «Тип переменной» (Van ible Type).
В столбце «Ширина» (Width) задается максимальное количество знаков, которые может иметь переменная, включая дробную часть.
В столбце «Десятичные» (Decimal) выбирается количество десятичных знаков после запятой, в случае если тип переменной допускает использование дробных чисел.
В столбце «Метка» (Label) можно задать метку переменной. Метка используется для того, чтобы боле подробно отразить смысл переменной. Это своего рода комментарий к имени переменной. При задании меток переменных часто используются формулировки вопросов, содержащихся в анкете.
В столбце «Значения» (Values) отображаются значения меток переменных. В поле «Значения» указываются коды возможных вариантов ответа на этот вопрос. Для заполнения
данного столбца необходимо произвести кодировку вариантов ответа. В диалоговом окне «Значение меток переменных» в поле «Значение» указываются числовые коды вариантов
ответа, а в поле «Метка» — их формулировки.
В столбце «Пропущенные значения» (Missing) следует указать, какие коды вариантов ответов следует исключить из анализа. Например, отсутствие определенного ответа: «98»
— не знаю, «99» — нет ответа.
В столбце «Столбцы» (Columns) таблицы «Переменные» указывается ширина столбца, содержащего значения соответствующей переменной в таблице другой вкладки редактора
данных: «Данные» (Date View). По умолчанию ширина столбца задается «8».
В столбце «Выравнивание» (Alignment задается положение кодов ответов в таблице «Значения переменных» во вкладке редактора данных «Данные». Они могут быть
выровнены по правому краю (Right), по левому краю (Left) или по центру (Center). По умолчанию задается выравнивание по правому краю.
В столбце «Шкала измерения» (Measure) указывается тип шкалы, по которой измеряется переменная. По умолчанию задается метрическая шкала (Scale). В случае необходимости тип шкалы
можно изменить
Основное правило создания файла данных в SPSS: переменные должны быть одновариантными, каждая переменная может иметь только одну метку. Таким образом, если вопрос может иметь несколько
вариантов ответа каждого респондента, необходимо создать несколько одновариантных переменных (дихотомическая кодировка данных).
Например, на вопрос «Какую марку одежды Вы предпочитаете?» может быть закодирован следующим образом: «1» —предпочитаю, «0» — не предпочитаю. Следовательно,
ответы респондентов так, как показано в таблице 1.2.
| Респонденты | Марка A | Марка B | Марка C |
|---|---|---|---|
| Респондент 1 | 1 | 0 | 1 |
| Респондент 2 | 0 | 1 | 1 |
| Респондент 3 | 0 | 1 | 1 |
| Респондент 4 | 1 | 0 | 1 |
Таблица 1.2 — Дихотомическая кодировка данных. Вопрос анкеты «Какую марку одежды Вы предпочитаете?»
1.1 Подготовка данных к анализу
Анализ маркетинговой информации с применением программы SPSS включает выполнение следующих необходимых шагов, представленных на рисунке 1.1:
Рисунок 1.1 — Анализ данных с применением программы SPSS
- На первом этапе необходимо проверить правильность составления анкет, полноту заполнения и качество интервьюирования, а также репрезентативность выборки.
- На этапе кодирования необходимо присвоить код каждому возможному варианту ответа по каждому вопросу. С этой целью используются следующие типы шкал измерения переменных:
- Номинальная
- Порядковая (ранговая)
- Интервальная
- Относительная
От выбора шкалы (таблица 1.1) зависит вся последующая методика изучения данных и определение возможности расчета статистических показателей.
№ Тип шкалы Особенности построения 1 Номинальная Каждому свойству потребителя ставится в соответствие некоторый код, позволяющий отличить одно значение от другого. По данной шкале измеряются как
правило качественные характеристики объекта исследования. Например, значению свойства пол «мужской» присваивается код «1», «женский» — код «2».2 Порядковая Присваивает значения свойствам потребителя, находящимся на разных уровнях по отношению друг к другу. Ответы респондентов можно упорядочить по уровню
изучаемого свойства переменной. Например, по степени предпочтений покупателей различных марок товара, «наиболее предпочитаемой» присваиваем код «1», коды 2, 3, 4 присваиваются маркам по
степени убывания предпочтений.3 Интервальная Позволяет дать количественную оценку различиям между переменными, т.е. определить насколько одно значение схоже или отличается от другого.
Например, шкала Цельсия, календарь. Данная шкала также используется при кодировании ответов респондентов, полученных в результате применения в процессе анкетирования семантического
дифференциала. Например, когда от респондентов требуется оценить качество продукта по семибалльной шкале.4 Относительная Предполагает существование естественного нуля. Поэтому в данной шкале можно сравнивать значения переменной по отношению друг к другу. Это могут
быть физические характеристики (вес, длина, объем и пр.) и экономические характеристики (цена, объем продаж, прибыль и пр.).Таблица 1.1 — Типы шкал
В программе SPSS интервальная и относительная шкалы объединяются в метрическую шкалу.
- Выбор метода обработки данных основывается на итогах предыдущих этапов маркетинговых исследований, характеристиках информации, а также задачах, поставленных перед маркетинговым исследованием. Могут быть
использованы следующие виды анализа: описательные статистики, корреляционный анализ, построение таблиц сопряженности, кросс—табуляция, проверка статистических гипотез о виде распределения, дисперсионный анализ,
дискриминантный анализ, кластерный анализ, многомерное шкалирование, факторный анализ, анализ соответствий, регрессионный анализ, совместный анализ. - В результате проведенного анализа исследователь получает массив данных, доступный осмыслению и содержательной интерпретации. На данном этапе необходимо представить, отредактировать и сохранить полученные данные,
так как исчерпывающий анализ обычно требует многократной обработки данных с применением разных методов. - Интерпретация результата обработки данных — самостоятельная задача исследователя. Опираясь на полученные статистические данные важно выявить причинно—следственные отношения между изучаемыми признаками,
факторы, оказывающие наибольшее влияние на исследуемую проблему, дать грамотную обоснованную оценку ситуации и выстроить прогноз.
1.2 Структура редактора данных
Вверх
Файл исходной базы данных для проведения анализа в SPSS формируется в редакторе данных (Data Editor). Редактор данных имеет две вкладки: «Переменные» (Variable View) и «Данные» (Date View). Вкладки представляют
собой таблицы, содержащие информацию о данных, собранных для проведения анализа.
Во вкладке «Переменные» представлена таблица с данными, котрые описывают свойства переменных. Каждая строка отображает переменную (вопрос анкеты), каждый столбец — ее свойства.
В столбце «Имя» (Name) записывают имя переменной — это может быть номер или часть вопроса в анкете. Например, переменная «пол», «занятость», «марка». Имя переменной не является произвольным, оно может содержать буквы
латинского алфавита и цифры, а также некоторые символы: $, #. Длина имени не более 64 знаков. Не допускаются пробелы и буквы других алфавитов. Имя переменной должно начинаться с буквы и не может заканчиваться знаком
подчеркивания «__» и точкой.
В столбце «Тип» (Туре) задается тип переменной; текущим типом является числовой (Numeric). В подавляющем большинстве случаев лучше иметь дело с числовыми переменными. Если
требуется изменить тип переменной, нужно нажать на кнопку «Тип переменной» (Van ible Type).
В столбце «Ширина» (Width) задается максимальное количество знаков, которые может иметь переменная, включая дробную часть.
В столбце «Десятичные» (Decimal) выбирается количество десятичных знаков после запятой, в случае если тип переменной допускает использование дробных чисел.
В столбце «Метка» (Label) можно задать метку переменной. Метка используется для того, чтобы боле подробно отразить смысл переменной. Это своего рода комментарий к имени переменной. При задании меток переменных часто используются формулировки вопросов, содержащихся в анкете.
В столбце «Значения» (Values) отображаются значения меток переменных. В поле «Значения» указываются коды возможных вариантов ответа на этот вопрос. Для заполнения
данного столбца необходимо произвести кодировку вариантов ответа. В диалоговом окне «Значение меток переменных» в поле «Значение» указываются числовые коды вариантов
ответа, а в поле «Метка» — их формулировки.
В столбце «Пропущенные значения» (Missing) следует указать, какие коды вариантов ответов следует исключить из анализа. Например, отсутствие определенного ответа: «98»
— не знаю, «99» — нет ответа.
В столбце «Столбцы» (Columns) таблицы «Переменные» указывается ширина столбца, содержащего значения соответствующей переменной в таблице другой вкладки редактора
данных: «Данные» (Date View). По умолчанию ширина столбца задается «8».
В столбце «Выравнивание» (Alignment задается положение кодов ответов в таблице «Значения переменных» во вкладке редактора данных «Данные». Они могут быть
выровнены по правому краю (Right), по левому краю (Left) или по центру (Center). По умолчанию задается выравнивание по правому краю.
В столбце «Шкала измерения» (Measure) указывается тип шкалы, по которой измеряется переменная. По умолчанию задается метрическая шкала (Scale). В случае необходимости тип шкалы
можно изменить
Основное правило создания файла данных в SPSS: переменные должны быть одновариантными, каждая переменная может иметь только одну метку. Таким образом, если вопрос может иметь несколько
вариантов ответа каждого респондента, необходимо создать несколько одновариантных переменных (дихотомическая кодировка данных).
Например, на вопрос «Какую марку одежды Вы предпочитаете?» может быть закодирован следующим образом: «1» —предпочитаю, «0» — не предпочитаю. Следовательно,
ответы респондентов так, как показано в таблице 1.2.
| Респонденты | Марка A | Марка B | Марка C |
|---|---|---|---|
| Респондент 1 | 1 | 0 | 1 |
| Респондент 2 | 0 | 1 | 1 |
| Респондент 3 | 0 | 1 | 1 |
| Респондент 4 | 1 | 0 | 1 |
Таблица 1.2 — Дихотомическая кодировка данных. Вопрос анкеты «Какую марку одежды Вы предпочитаете?»