From Wikipedia, the free encyclopedia

Instruction-level parallelism (ILP) is the parallel or simultaneous execution of a sequence of instructions in a computer program. More specifically ILP refers to the average number of instructions run per step of this parallel execution.[2]: 5
Discussion[edit]
ILP must not be confused with concurrency. In ILP there is a single specific thread of execution of a process. On the other hand, concurrency involves the assignment of multiple threads to a CPU’s core in a strict alternation, or in true parallelism if there are enough CPU cores, ideally one core for each runnable thread.
There are two approaches to instruction-level parallelism: hardware and software.
Hardware level works upon dynamic parallelism, whereas the software level works on static parallelism. Dynamic parallelism means the processor decides at run time which instructions to execute in parallel, whereas static parallelism means the compiler decides which instructions to execute in parallel.[3][clarification needed] The Pentium processor works on the dynamic sequence of parallel execution, but the Itanium processor works on the static level parallelism.
Consider the following program:
e = a + b f = c + d m = e * f
Operation 3 depends on the results of operations 1 and 2, so it cannot be calculated until both of them are completed. However, operations 1 and 2 do not depend on any other operation, so they can be calculated simultaneously. If we assume that each operation can be completed in one unit of time then these three instructions can be completed in a total of two units of time, giving an ILP of 3/2.
A goal of compiler and processor designers is to identify and take advantage of as much ILP as possible. Ordinary programs are typically written under a sequential execution model where instructions execute one after the other and in the order specified by the programmer. ILP allows the compiler and the processor to overlap the execution of multiple instructions or even to change the order in which instructions are executed.
How much ILP exists in programs is very application specific. In certain fields, such as graphics and scientific computing the amount can be very large. However, workloads such as cryptography may exhibit much less parallelism.
Micro-architectural techniques that are used to exploit ILP include:
- Instruction pipelining where the execution of multiple instructions can be partially overlapped.
- Superscalar execution, VLIW, and the closely related explicitly parallel instruction computing concepts, in which multiple execution units are used to execute multiple instructions in parallel.
- Out-of-order execution where instructions execute in any order that does not violate data dependencies. Note that this technique is independent of both pipelining and superscalar execution. Current implementations of out-of-order execution dynamically (i.e., while the program is executing and without any help from the compiler) extract ILP from ordinary programs. An alternative is to extract this parallelism at compile time and somehow convey this information to the hardware. Due to the complexity of scaling the out-of-order execution technique, the industry has re-examined instruction sets which explicitly encode multiple independent operations per instruction.
- Register renaming which refers to a technique used to avoid unnecessary serialization of program operations imposed by the reuse of registers by those operations, used to enable out-of-order execution.
- Speculative execution which allows the execution of complete instructions or parts of instructions before being certain whether this execution should take place. A commonly used form of speculative execution is control flow speculation where instructions past a control flow instruction (e.g., a branch) are executed before the target of the control flow instruction is determined. Several other forms of speculative execution have been proposed and are in use including speculative execution driven by value prediction, memory dependence prediction and cache latency prediction.
- Branch prediction which is used to avoid stalling for control dependencies to be resolved. Branch prediction is used with speculative execution.
It is known that the ILP is exploited by both the compiler and hardware support but the compiler also provides inherent and implicit ILP in programs to hardware by compile-time optimizations. Some optimization techniques for extracting available ILP in programs would include instruction scheduling, register allocation/renaming, and memory access optimization.
Dataflow architectures are another class of architectures where ILP is explicitly specified, for a recent example see the TRIPS architecture.
In recent years, ILP techniques have been used to provide performance improvements in spite of the growing disparity between processor operating frequencies and memory access times (early ILP designs such as the IBM System/360 Model 91 used ILP techniques to overcome the limitations imposed by a relatively small register file). Presently, a cache miss penalty to main memory costs several hundreds of CPU cycles. While in principle it is possible to use ILP to tolerate even such memory latencies, the associated resource and power dissipation costs are disproportionate. Moreover, the complexity and often the latency of the underlying hardware structures results in reduced operating frequency further reducing any benefits. Hence, the aforementioned techniques prove inadequate to keep the CPU from stalling for the off-chip data. Instead, the industry is heading towards exploiting higher levels of parallelism that can be exploited through techniques such as multiprocessing and multithreading.[4]
See also[edit]
- Data dependency
- Memory-level parallelism (MLP)
References[edit]
- ^ «The History of Computing». mason.gmu.edu. Retrieved 2019-03-24.
- ^ Goossens, Bernard; Langlois, Philippe; Parello, David; Petit, Eric (2012). «PerPI: A Tool to Measure Instruction Level Parallelism». Applied Parallel and Scientific Computing. Lecture Notes in Computer Science. Vol. 7133. pp. 270–281. doi:10.1007/978-3-642-28151-8_27. ISBN 978-3-642-28150-1. S2CID 26665479.
- ^ Hennessy, John L.; Patterson, David A. (1996). Computer Architecture: A Quantitative Approach.
- ^ Reflections of the Memory Wall
Further reading[edit]
- Aiken, Alex; Banerjee, Utpal; Kejariwal, Arun; Nicolau, Alexandru (2016-11-30). Instruction Level Parallelism. Professional Computing (1 ed.). Springer. ISBN 978-1-4899-7795-3. ISBN 1-4899-7795-3. (276 pages)
External links[edit]
- Approaches to addressing the Memory Wall
- Wired magazine article that refers to the above paper
- https://www.scribd.com/doc/33700101/Instruction-Level-Parallelism#scribd
- http://www.hpl.hp.com/techreports/92/HPL-92-132.pdf Archived 2016-03-04 at the Wayback Machine
Параллелизм на уровне команд (англ. Instruction-level parallelism — ILP) является мерой того, какое множество операций в компьютерной программе может выполняться одновременно. Потенциальное совмещение выполнения команд называется «параллелизмом на уровне команд».
Описание[править | править код]
Есть два подхода к выявлению параллелизма (parallelism extraction) на уровне команд:
- аппаратные средства — выявлением параллелизма в потоке операций занимаются специальные схемы процессора при исполнении кода программ;
- программное обеспечение — выявлением параллелизма занимается компилятор, который формирует исполняемый код программы под специальный процессор.
Уровень аппаратного обеспечения осуществляет динамический параллелизм, тогда как уровень программного обеспечения реализует статический параллелизм. Современные высокопроизводительные процессоры x86 (AMD Ryzen, Intel Core) работают на динамической последовательности параллельного выполнения (Внеочередное исполнение команд). Статический параллелизм применялся в процессорах Itanium (однако в Itanium 2 применялся гибридный подход).
Рассмотрим следующую программу:
- e = a + b
- f = c + d
- m = e * f
Операция 3 зависит от результатов операций 1 и 2, поэтому она не может быть вычислена, пока не будут завершены 1 и 2. Однако операции 1 и 2 не зависят от других операций, поэтому они могут быть вычислены одновременно. Если предположить, что каждая операция может быть завершена за одну единицу времени, то эти три инструкции могут быть завершены в общей сложности за две единицы времени, обеспечивая параллелизм равный 3/2.
Цель разработчиков компилятора и процессора заключается в выявлении параллелизма и получении от него максимального выигрыша. Обычные программы, как правило, написаны под последовательную модель исполнения, где команды выполняются одна за другой в порядке, установленном программистом. ILP позволяет компилятору и/или процессору распараллеливать выполнение нескольких инструкций или даже изменять порядок их выполнения.
Сколько ILP присутствует в программе сильно зависит от области её применения. В некоторых областях, таких как компьютерная графика и научные вычисления, число может быть очень большим. Тем не менее такие задачи как криптография могут демонстрировать гораздо меньше параллелизма.
Аппаратные методы выявления и использования параллелизма:
- Вычислительный конвейер, где выполнение нескольких инструкций может частично перекрываться;
- Суперскалярное выполнение операций, в которой несколько функциональных блоков используется для выполнения нескольких команд одновременно;
- Внеочередное исполнение, где инструкции выполняются в любом порядке, который не нарушает зависимости данных. Обратите внимание, что этот метод не зависит ни от конвейера, ни от суперскалярного выполнения. Текущие реализации внеочередного исполнения динамически (то есть во время выполнения программы и без помощи со стороны компилятора) получают ILP из обычных программ. Альтернативой является получение параллелизма во время компиляции и передача этой информации аппаратному обеспечению. Из-за сложности масштабирования техники внеочередного исполнения отрасль пересмотрела набор команд, которые явно кодируют несколько независимых операций в инструкции;
- Переименование регистров — метод, используемый для устранения ненужной сериализации (последовательного выполнения) операций, к которой приводит переиспользование регистров этими операциями, и используемый для внеочередного исполнения;
- Спекулятивное исполнение, которое позволяет выполнять инструкции целиком или частично до того, как станет ясно, нужно ли это выполнение. Часто используемой формой спекулятивного исполнения является спекулятивное исполнение потока управления, при котором инструкции (например, переход) за потоком управления выполняются до того, как определится та ветка программы, которую определяет инструкция перехода. Были предложены и используются несколько других форм спекулятивного исполнения, в том числе для спекулятивного исполнения, обусловленного предсказанием значения, предсказание зависимости по памяти и предсказание задержек кэша;
- Предсказание переходов, которое используется, чтобы избежать простаивания для разрешения управления зависимостями. Предсказатель переходов используется со спекулятивным исполнением.
Потоковые архитектуры представляют собой другой класс архитектур, где ILP явно указаны, см., например, архитектуру TRIPS.
Реализации[править | править код]
Ранние реализации ILP в таких мейнфреймах, как IBM System/360 Model 91, использовали методы ILP, чтобы преодолеть ограничения, налагаемые относительно небольшим регистровым файлом.
В микропроцессорах различные формы параллелизма на уровне инструкций стали применяться с конца 1980-х. В качестве примера первых суперскалярных процессоров можно привести Intel 960CA (1989 год[1]), IBM Power RS/6000 (1990 год), DEC Alpha 21064 (1992 год)[2]. Внеочередное исполнение команд и переименование регистров в микропроцессорах впервые было реализовано в IBM POWER1 (1990 г.).
Первым IA-32-процессором с конвейером стал Intel 80486 (1989 г.); первым суперскалярным IA-32-процессором стал Intel Pentium (1993 г); первый IA-32-процессор с внеочередным исполнением команд и переименованием регистров — Intel Pentium Pro (1995 г.),
В период с 1999 по 2005 год компании AMD и Intel вели активную конкурентную борьбу по выпуску все более и более производительных микропроцессоров для массового потребительского и серверного рынков. В процессорах, выпущенных за этот период, обеими компаниями активно совершенствовались техники эксплуатации параллелизма на уровне команд. Уменьшение техпроцесса позволяло поместить ещё больше транзисторов на подложке процессора с целью использовать их для построения ещё более сложных и эффективных суперскалярных конвейеров.
Обе компании повышали тактовую частоту процессоров (т. н. «гонка гигагерцев»). Например, в архитектуре NetBurst компания Intel наращивала стадии вычислительного конвейера, доведя их число в Pentium 4 Prescott до 31, что позволило добиться максимальных частот, но для обычного кода (не оптимизированного специально для Pentium 4) снизило IPC[en] на столько, что эти процессоры проигрывали в производительности процессорам Athlon 64 с существенно меньшей тактовой частотой.
К концу 2005 года стало ясно, что все эти способы и методы начали себя исчерпывать. Закон масштабирования Деннарда перестал работать. При неизменных темпах увеличения количества транзисторов производительность самих процессоров повышалась незначительно, но при этом росло энергопотребление процессоров и их тепловыделение, приблизившись к ограничениям недорогих систем теплоотвода (power ceiling, power wall[3][4]).
С конца 2005 года рост тактовых частот и однопоточной производительности значительно замедлились[5][6][7] и отрасль производства микропроцессоров начала движение в сторону использования других уровней параллелизма, а именно параллелизма на уровне потоков и задач, реализованого в многопроцессорности, многоядерности и аппаратной многопоточности[8]. Это отразилось в свою очередь на подходах к программированию[9].
См. также[править | править код]
- Зависимость данных
Примечания[править | править код]
- ↑ Ron Copeland. Intel Ready to Announce i960CA Microprocessor With 66 MIPS // InfoWorld. — 1989. — Т. 11, № 36. — С. 19. (англ.)
- ↑ Kai Hwang, Naresh Jotwani. Advanced Computer Architecture. — second edition. — McGraw-Hill Education, 2011. — С. 152. — 723 с. — ISBN 978-0-07-070210-3. (англ.)
- ↑ Christopher Mims. Why CPUs Aren’t Getting Any Faster (англ.). MIT Technology review (12 октября 2010). — «power wall (the chip’s overall temperature and power consumption). .. arguably the defining limit of the power of the modern CPU.» Дата обращения: 3 сентября 2016. Архивировано 16 сентября 2016 года.
- ↑ Russell Fish. Future of computers — Part 2: The Power Wall (англ.). EDN (6 января 2012). Дата обращения: 3 сентября 2016. Архивировано 6 сентября 2016 года.
- ↑ DATA PROCESSING IN EXASCALE-CLASS COMPUTER SYSTEMS, Chuck Moore (AMD), The Salishan Conference on High Speed Computing (LANL / LLNL / SNL) April 27, 2011
- ↑ The death of CPU scaling: From one core to many — and why we’re still stuck Архивная копия от 7 сентября 2016 на Wayback Machine, Joel Hruska on February 1, 2012
- ↑ A Look Back at Single-Threaded CPU Performance Архивная копия от 14 сентября 2016 на Wayback Machine, 2012 — после 2004 г рост однопоточной производительности по SpecInt составляет около 15-20 % в год, вместо 50 % в предыдущие десять лет
- ↑ [1] Архивная копия от 7 февраля 2018 на Wayback Machine Intel Developer Forum in 2005 — Intel President Paul Otellini — «We are dedicating all of our future product development to multicore designs. We believe this is a key inflection point for the industry».
- ↑ Herb Sutter. The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software Архивная копия от 10 июля 2016 на Wayback Machine
Литература[править | править код]
- David A. Patterson, John L. Hennessy. Computer Architecture: A Quantitative Approach, 5th Edition. — Morgan Kaufmann, 2011. — 856 p. — ISBN 012383872X. (англ.) — Глава 3, стр.148-247
- под ред. David Padua. Encyclopedia of Parallel Computing. — Springer, 2012. — 2366 p. — ISBN 0387098445. (англ.) — стр.935
- David Harris, Sarah Harris. Digital Design and Computer Architecture, 2nd Ed. — Morgan Kaufmann, 2012. — 712 p. — ISBN 0123944244. (англ.) — стр.444-452
- David A. Patterson, John L. Hennessy. Computer Organization and Design: The Hardware/Software Interface, 5th Edition. — Morgan Kaufmann, 2013. — 800 p. — ISBN 0124077269. (англ.) — Глава 4.10, стр.332-344
Ссылки[править | править код]
- Future of computing — Part 3: The ILP Wall and pipelines, EDN, 2012 (англ.)
- Герб Саттер. Бесплатного супа больше не будет // Herb Sutter. The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software (рус.)
Знакомство с уровнями распараллеливания
Время на прочтение
5 мин
Количество просмотров 37K

Распараллелить решение задачи можно на нескольких уровнях. Между этими уровнями нет четкой границы и конкретную технологию распараллеливания, бывает сложно отнести к одному из них. Приведенное здесь деление условно и служит, чтобы продемонстрировать разнообразие подходов к задаче распараллеливания.
Распараллеливание на уровне задач
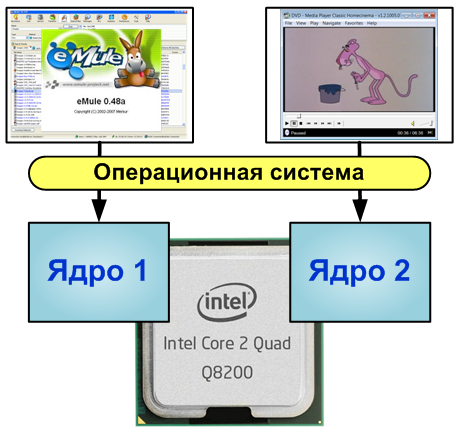
Часто распараллеливание на этом уровне является самым простым и при этом самым эффективным. Такое распараллеливание возможно в тех случаях, когда решаемая задача естественным образом состоит из независимых подзадач, каждую из которых можно решить отдельно. Хорошим примером может быть сжатие аудио-альбома. Каждая запись может обрабатываться отдельно, так как она никак не связана с другими.
Распараллеливание на уровне задач нам демонстрирует операционная система, запуская на многоядерной машине программы на разных ядрах. Если первая программа показывает нам фильм, а вторая является файлообменным клиентом, то операционная система спокойно сможет организовать их параллельную работу.
Другими примерами распараллеливания на этом уровне абстракции является параллельная компиляция файлов в Visual Studio 2008, обработка данных в пакетных режимах.
Как было сказано выше, данный вид распараллеливания прост и в ряде случаев весьма эффективен. Но если мы имеем дело с однородной задачей, то данный вид распараллеливания не применим. Операционная система никак не может ускорить программу, использующую только один процессор, сколько бы ядер ни было бы при этом доступно. Программа, разбивающая кодирование звука и изображения в видеофильме на две задачи ничего не получит от третьего или четвертого ядра. Что бы распараллелить однородные задачи, нужно спуститься на уровень ниже.
Уровень параллелизма данных
Название модели «параллелизм данных» происходит оттого, что параллелизм заключается в применении одной и той же операции к множеству элементов данных. Параллелизм данных демонстрирует архиватор, использующий для упаковки несколько ядер процессора. Данные разбиваются на блоки, которые единообразным образом обрабатываются (упаковываются) на разных узлах.

Данный вид параллелизма широко используется при решении задач численного моделирования. Счетная область представлена в виде ячеек, описывающих состояние среды в соответствующих точках пространства — давление, плотность, процентное соотношение газов, температура и так далее. Количество таких ячеек может быть огромным — миллионы и миллиарды. Каждая из этих ячеек должна быть обработана одним и тем же способом. Здесь модель параллелизма по данным крайне удобна, так как позволяет загрузить каждое ядро, выделив ему определенный набор ячеек. Счетная область разбивается на геометрические объекты, например параллелепипеды, и ячейки, вошедшие в эту область, отдаются на обработку определенному ядру. В математической физике такой тип параллелизма называют геометрическим параллелизмом.
Хотя геометрический параллелизм может показаться похожим на распараллеливание на уровне задач, он является более сложным в реализации. В случае задач моделирования необходимо передавать данные получаемые на границах геометрических областей другим ядрам. Часто используются специальные методы повышения скорости расчета, за счет балансировки нагрузки между вычислительными узлами.
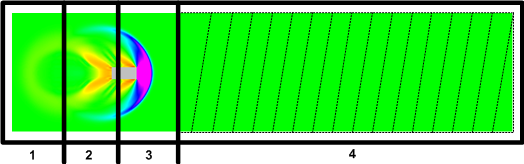
В ряде алгоритмов скорость вычисления, где активно протекают процессы, занимает больше времени, чем там, где среда спокойна. Как показано на рисунке, разбив счетную область на неравные части можно получить более равномерную загрузку ядер. Ядра 1, 2, и 3 обрабатывают маленькие области, где движется тело, а ядро 4 обрабатывает большую область, которая еще не подверглось возмущению. Все это требует дополнительного анализа и создания алгоритма балансировки.
Наградой за такое усложнение является возможность решать задачи длительного движения объектов за приемлемое время расчета. Примером может служить старт ракеты.

Уровень распараллеливания алгоритмов
Следующий уровень, это распараллеливание отдельных процедур и алгоритмов. Сюда можно отнести алгоритмы параллельной сортировки, умножение матриц, решение системы линейных уравнений. На этом уровне абстракций удобно использовать такую технологию параллельного программирования, как OpenMP.
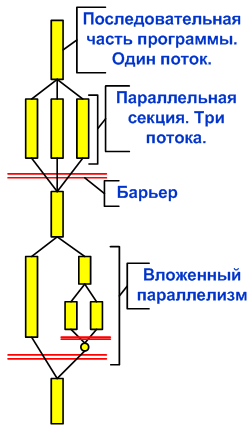
OpenMP (Open Multi-Processing) — это набор директив компилятора, библиотечных процедур и переменных окружения, которые предназначены для программирования многопоточных приложений на многопроцессорных системах. В OpenMP используется модель параллельного выполнения «ветвление-слияние». Программа OpenMP начинается как единственный поток выполнения, называемый начальным потоком. Когда поток встречает параллельную конструкцию, он создает новую группу потоков, состоящую из себя и некоторого числа дополнительных потоков, и становится главным в новой группе. Все члены новой группы (включая главный поток) выполняют код внутри параллельной конструкции. В конце параллельной конструкции имеется неявный барьер. После параллельной конструкции выполнение пользовательского кода продолжает только главный поток. В параллельный регион могут быть вложены другие параллельные регионы.
За счет идеи «инкрементального распараллеливания» OpenMP идеально подходит для разработчиков, желающих быстро распараллелить свои вычислительные программы с большими параллельными циклами. Разработчик не создает новую параллельную программу, а просто последовательно добавляет в текст последовательной программы OpenMP-директивы.
Задача реализации параллельных алгоритмов достаточно сложна и поэтому существует достаточно большое количество библиотек параллельных алгоритмов, позволяющих строить программы как из кубиков, не вдаваясь в устройство реализаций параллельной обработки данных.
Параллелизм на уровне инструкций
Наиболее низкий уровень параллелизма, осуществляемый на уровне параллельной обработки процессором нескольких инструкций. На этом же уровне находится пакетная обработка нескольких элементов данных одной командой процессора. Речь идет о технологиях MMX, SSE, SSE2 и так далее. Этот вид параллельности иногда выделяют в еще более глубокий уровень распараллеливания – параллелизм на уровне битов.
Программа представляет собой поток инструкций выполняемых процессором. Можно изменить порядок этих инструкций, распределить их по группам, которые будут выполняться параллельно, без изменения результата работы всей программы. Это и называется параллелизмом на уровне инструкций. Для реализации данного вида параллелизма в микропроцессорах используется несколько конвейеров команд, такие технологии как предсказание команд, переименование регистров.
Программист редко заглядывает на этот уровень. Да и в этом нет смысла. Работу по расположению команд в наиболее удобной последовательности для процессора выполняет компилятор. Интерес этот уровень распараллеливания может представлять только для узкой группы специалистов, выжимающие все возможности из SSEx или разработчиков компиляторов.
Вместо заключения
Этот текст не претендует на полноту рассказа об уровнях параллельности, а просто показывает многогранность вопроса использования многоядерных систем. Для тех, кто интересуется разработкой программ, хочу предложить несколько ссылок на ресурсы, посвященные вопросам параллельного программирования:
- Сообщество разработчиков программного обеспечения. Я не сотрудник Intel, но очень рекомендую этот ресурс как член этого сообщества. Очень много интересных статей, записей в блогах и обсуждений, касающихся параллельного программирования.
- Обзоры статей по параллельному программированию с использованием технологии OpenMP.
- http://www.parallel.ru/ Все о мире суперкомпьютеров и параллельных вычислений. Академическое сообщество. Технологии, конференции, дискуссионный клуб (форум) по параллельным вычислениям.
-
ЭВМ,
определение, назначение, классификации.
ЭЛЕКТРОННО-ВЫЧИСЛИТЕЛЬНЫЕ
МАШИНЫ (ЭВМ) — вычислительные машины,
основными элементами которых являются
электронные приборы, предназначенные
для автоматизации процесса обработки
информации и вычислений.
Классификация ЭВМ
по принципу действия:
-
Цифровые
вычислительные машины (ЦВМ) –
вычислительные машины дискретного
действия, работают с информацией,
представленной в дискретной (цифровой)
форме. ЦВМ отличаются высокой точностью
вычисления и удобством хранения
информации. -
Аналоговые
вычислительные машины (АВМ) –
вычислительные машины непрерывного
действия, работают с информацией,
представленной в непрерывной (аналоговой)
форме, т.е. в виде непрерывного рядя
значений какой-либо физической величины.
АВМ просты и удобны в эксплуатации,
характеризуются высоким быстродействием
и относительно высокой тонностью. -
Гибридные
вычислительные машины (ГВМ) –
вычислительные машины комбинированного
действия, работают с информацией,
представленной в цифровой и аналоговой
форме. Они совмещают преимущества ЦВМ
и ГВМ.
Классификация ЭВМ
по этапам создания:
-
1-е поколение, 50-е
годы. ЭВМ на электронных вакуумных
лампах. -
2-е поколение, 60-е
годы. ЭВМ на дискретных полупроводниковых
приборах. -
3-е поколение, 70-е
годы. ЭВМ на полупроводниковых
интегральных микросхемах малой и
средней степени интеграции (сотни —
тысячи элементов на кристалл). -
4-е поколение, 80-е
годы. ЭВМ на больших и сверхбольших
интегральных схемах. -
5-е поколение 90-е
годы. ЭВМ с многими десятками параллельно
работающих микропроцессоров. ЭВМ на
сверхсложных микропроцессорах с
параллельно-векторной структурой. -
6-е и последующее
поколения, оптоэлектронные ЭВМ с
массовым параллелизмом и нейронной
структурой – с распределенной сетью
большого числа не сложных микропроцессоров,
моделирующих архитектуру нейронных
биологических систем.
Классификация ЭВМ
по назначению:
-
Универсальные
ЭВМ – для решения широкого круга задач. -
Проблемно-ориентированные
ЭВМ – служат для решения более узкого
круга задач связанных, как правило, с
управлением технологическими объектами,
регистрацией, накоплением и обработкой
относительно небольших объемов данных. -
Специализированные
ЭВМ – используются для решения узкого
круга задач или реализации строго
определенной группы функций.
Классификация ЭВМ
по размерам и функциональным возможностям:
-
Супер ЭВМ —
вычислительная машина, значительно
превосходящая по своим техническим
параметрам большинство существующих
компьютеров. Из-за большой гибкости
самого термина до сих пор распространены
довольно нечёткие представления о
понятии «суперкомпьютер». В общем
случае, суперкомпьютер — это компьютер
значительно более мощный, чем доступные
для большинства пользователей машины.
При этом, скорость технического прогресса
сегодня такова, что нынешний лидер
легко может стать завтрашним аутсайдером.
Архитектура также не может считаться
признаком принадлежности к классу
суперкомпьютеров. Ранние компьютеры
CDC были обычными машинами, всего лишь
оснащёнными быстрыми для своего времени
скалярными процессорами, скорость
работы которых была в несколько десятков
раз выше, чем у компьютеров, предлагаемых
другими компаниями. Большинство
суперкомпьютеров 70-х оснащались
векторными процессорами, а к началу и
середине 80-х небольшое число (от 4 до
16) параллельно работающих векторных
процессоров практически стало стандартным
суперкомпьютерным решением. Конец 80-х
и начало 90-х годов охарактеризовались
сменой магистрального направления
развития суперкомпьютеров от
векторно-конвейерной обработки к
большому и сверхбольшому числу
параллельно соединённых скалярных
процессоров.
-
ЭВМ,
определение, назначение, понятия
вычислительная система и вычислительный
комплекс.
Вычислительная
система
(ВС) — это взаимосвязанная совокупность
аппаратных средств вычислительной
техники и программного обеспечения,
предназначенная для обработки информации.
ВЫЧИСЛИТЕЛЬНЫЙ КОМПЛЕКС —
взаимосвязанная совокупность средств
вычислительной техники, в которую входит
не менее 2 процессоров,
-
Схема
взаимодействия МПП и МВВ с совместно
используемыми шинами.
-
Периферийные
устройства, определение, назначение,
классификации
Основное назначение
ПУ — обеспечить поступление в ЭВМ из
окружающей среды программ и данных для
обработки, а также выдачу результатов
работы ЭВМ в виде, пригодном для восприятия
человека или для передачи на другую
ЭВМ, или в иной, необходимой форме.
ПУ
ЭВМ включают в себя внешние запоминающие
устройства, предназначенные для
сохранения и дальнейшего использования
информации, устройства ввода-вывода,
предназначенные для обмена информацией
между оперативной памятью машины и
носителями информации, либо другими
ЭВМ, либо оператором. Входными устройствами
могут быть: клавиатура, дисковая система,
мышь, модемы, микрофон; выходными —
дисплей, принтер, дисковая система,
модемы, звуковые системы, другие
устройства. С большинством этих устройств
обмен данными происходит в цифровом
формате. Для работы с разнообразными
датчиками и исполнительными устройствами
используются аналого-цифровые и
цифроаналоговые преобразователи для
преобразования цифровых данных в
аналоговые и наоборот.
-
Большой
и малый интерфейсы системы ввода вывода -
Основные
причины возникновения ошибок в технике
—
Плохое ПО
—
Неисправность оборудования
-
Понятие
«адресное пространство», основные
определения: слово, параграф, сегмент,
селектор сегмента
Адресное
пространство — это диапазон адресов,
обозначающих определенное место в
памяти.
Селектор
— это 16-битный идентификатор сегмента.
Он содержит индекс дескриптора в
дескрипторной таблице, бит определяющий,
к какой дескрипторной
таблице производится обращение
(LDT или GDT), а также запрашиваемые права
доступа к сегменту. Если селектор
хранится в сегментном регистре, то
обращение к дескрипторным таблицам
происходит только при загрузке селектора
в сегментный регистр, т.к. каждый
сегментный регистр хранит соответствующий
дескриптор в программно-недоступном
(«теневом») регистре-кэше.
Слово
– это единица информации
Для
каждого компьютера характерна длина
слова — два, четыре или восемь байтов.
Это не исключает использование ячеек
другой длины (например, полуслово,
двойное слово).
Фрагмент
памяти в 16 байт называется параграфом.
максимальный
размер сегмента может быть 65536 байт
(216). Минимальный – 16 байт (размер
параграфа). Таким образом, сегменты –
это виртуальные умозрительные части с
максимальным объемом 64 Кбайт каждая.
-
Способ
вычисления абсолютного адреса байта
Реальный
(абсолютный) адрес складывается из
значения сегмента, сдвинутого на 4
разряда влево (умноженного на 16), и
смещения.
-
Адресное
пространство, непосредственная адресация
При
прямой адресации исполнительный адрес
является составной частью команды (так
же, как значения при непосредственной
адресации). Микропроцессор 8×86 добавляет
этот исполнительный адрес к сдвинутому
содержимому регистра сегмента данных
DS и получает 20-битовый физический адрес
операнда.
MOV
AX,TABLE
-
Адресное
пространство, косвенная регистровая
адресация
При
косвенной регистровой адресации
исполнительный адрес операнда
содержится в базовом регистре ВХ,
регистре указателя базы ВР или индексном
регистре (SI или DI). Косвенные регистровые
операнды надо заключать в квадратные
скобки, чтобы отличить их от регистровых
операндов. Например, команда
MOV
AХ,[ВХ]
-
Адресное
пространство, прямая адресация по базе
При адресации по
базе Ассемблер вычисляет исполнительный
адрес с помощью сложения значения сдвига
с содержимым регистров ВХ или ВР.
Регистр ВХ удобно
использовать при доступе к структурированным
записям данных, расположенным в разных
областях памяти. В этом случае базовый
адрес записи помещается в базовый
регистр ВХ и доступ к ее отдельным
элементам осуществляется по их сдвигу
относительно базы. А для доступа к разным
записям одной и той же структуры
достаточно соответствующим образом
изменить содержимое базового регистра.
Предположим,
например, что требуется прочитать с
диска учетные записи для ряда работников.
При этом каждая запись содержит табельный
номер работника, номер отдела, номер
группы, возраст, тарифную ставку и т.д.
Если номер отдела хранится в пятом и
шестом бантах записи, а начальный адрес
записи содержится в регистре ВХ, то
команда
MOV AХ,[ВХ]+4
загрузит в регистр
АХ номер отдела, в котором служит данный
работник (рис. 3). (Сдвиг равен 4, а не 5,
потому что первый байт записи имеет
номер 0.)
-
Адресное
пространство, прямая адресация с
индексированием
При прямой адресации
с индексированием исполнительный адрес
вычисляется как сумма значений сдвига
и индексного регистра (DI или SI). Этот тип
адресации удобен для доступа к элементам
таблицы, когда сдвиг указывает на начало
таблицы, а индексный регистр — на ее
элемент.
Например, если
B_TABLE — таблица байтов, то последовательность
команд
MOV DI,2
MOV
AL,В_TABLE[DI]
загрузит третий
элемент таблицы в регистр AL.
В таблице слов
соседние элементы отстоят друг от друга
на два байта, поэтому при работе с ней
надо удваивать номер
элемента
при вычислении значения индекса.
Если TABLE — таблица слов, то для загрузки
в регистр АХ ее третьего элемента надо
использовать последовательность команд
MOV DI,4
MOV
AХ,TABLE[DI]
-
Адресное
пространство, адресация по базе с
индексированием
При адресации по
базе с индексированием исполнительный
адрес вычисляется как сумма значений
базового регистра, индексного регистра
и, возможно, сдвига.
Так как в этом
режиме адресации складывается два
отдельных смещения, то он удобен при
адресации двумерных массивов, когда
базовый регистр содержит начальный
адрес массива, а значения сдвига и
индексного регистра суть смещения по
строке и столбцу.
Предположим,
например, что Ваша ЭВМ следит за шестью
предохранительными клапанами на
химическом предприятии. Она считывает
их состояния каждые полчаса и запоминает
в ячейках памяти. За неделю эти считывания
образуют массив, состоящий из 336 блоков
(48 считываний в течение семи дней) по
шесть элементов в каждом, а всего — 2016
значений.
Если начальный
адрес массива загружен в регистр ВХ,
сдвиг блока (номер считывания, умноженный
на 12) — в регистре DI, а номер клапана задан
в переменной VALVE, то команда
MOV AX
,VALVE[BX][DI ]
загрузит требуемое
считывание состояния клапана в регистр
АХ. На рис. 5 изображен процесс извлечения
результата третьего считывания (с
номером 2) для клапана 4 из массива, у
которого смещение в сегменте данных
равно 100Н.
Приведем несколько
допустимых форматов операндов, адресуемых
по базе с индексированием:
MOVE
AX,[BX+2+DI]
MOVE
AX,[DI+BX+2]
MOVE
AX,[BX+2][DI]
MOVE
AX,[BX][DI+2]
-
Память,
типы внутренней памяти и их характеристики
Компьютерная
память это часть вычислительной
машины, физическое устройство или среда
для хранения данных, используемых в
вычислениях, в течение определённого
времени.
Выделяют следующие
виды внутренней памяти:
-
оперативная. В
нее помещаются программы для выполнения
и данные для работы программы, которые
используются микропроцессором. Она
обладает большим быстродействием и
является энергозависимой. Обозначается
RAM — Random Access Memory -память с произвольным
доступом;
-
кэш-память (от
англ. caсhe – тайник). Она служит буфером
между RAM и микропроцессором и позволяет
увеличить скорость выполнения операций,
т.к. является сверхбыстродействующей.
В нее помещаются данные, которые
процессор получил и будет использовать
в ближайшие такты своей работы. Эта
память хранит копии наиболее часто
используемых участков RAM. При обращении
микропроцессора к памяти сначала ищутся
данные в кэш-памяти, а затем, если
остается необходимость, в оперативной
памяти;
-
постоянная
память
— BIOS (Basic Input-Output System). В
нее данные занесены при изготовлении
компьютера. Обозначается ROM — Read Only
Memory. Хранит:
-
программы для
проверки оборудования при загрузке
операционной системы; -
программы начала
загрузки операционной системы; -
программы по
выполнению базовых функций по обслуживанию
устройств компьютера; -
программу настройки
конфигурации компьютера — Setup. Позволяет
установить характеристики: типы
видеоконтроллера, жестких дисков и
дисководов для дискет, режимы работы
с RAM, запрос пароля при загрузке и т.д;
-
полупостоянная
память
— CMOS (Complementary Metal-Oxide Semiconductor). Хранит
параметры конфигурации компьютера.
Обладает низким энергопотреблением,
потому не изменяется при выключении
компьютера, т.к. питается от аккумулятора;
-
видеопамять.
Используется для хранения видеоизображения,
выводимого на экран. Входит в состав
видеоконтроллера.
Внутренняя память
дискретна. Элементарной (минимальной)
единицей хранения информации является
бит. Он может содержать 02 или 12. Однако
компьютер при работе с памятью для
размещения или выборки данных из нее
оперирует не битами, а байтами и более
крупными единицами — словами и двойными
словами. В зависимости от класса
компьютера слово — это два или четыре
байта памяти.
Для обращения к
элементам памяти они снабжаются адресами,
начиная с нуля. Максимальный адрес
основной памяти определяется
функциональными возможностями того
или иного компьютера.
Важной характеристикой
памяти любого вида является ее объем,
называемый также емкостью. Этот параметр
показывает, какой максимальный объем
информации можно хранить в памяти.
Для измерения объема памяти используются
следующие единицы: байты, килобайты
(Кбайт),
мегабайты (Мбайт),
гигабайты (Гбайт).
Объем (емкость)
памяти — максимальное количество
хранимой в ней информации. (Записать
определение)
Способ обращения
к устройству памяти для чтения или
записи информации получил название
доступа. С этим понятием связан такой
параметр памяти, как время доступа, или
быстродействие памяти — время,
необходимое для чтения из памяти либо
записи в нее минимальной порции
информации. Очевидно, что для числового
выражения этого параметра используются
единицы измерения времени: миллисекунда,
микросекунда, наносекунда.
Время доступа, или
быстродействие, памяти — время,
необходимое для чтения из памяти либо
записи в нее минимальной порции
информации. (Записать
определение)
-
Память,
типы внешней памяти и их характеристики
Внешняя
(долговременная) память — это место
длительного хранения данных (программ,
результатов расчётов, текстов и т.д.),
не используемых в данный момент в
оперативной памяти компьютера. Внешняя
память, в отличие от оперативной, является
энергонезависимой. Носители внешней
памяти, кроме того, обеспечивают
транспортировку данных в тех случаях,
когда компьютеры не объединены в сети
(локальные или глобальные). Для работы
с внешней памятью необходимо наличие
накопителя (устройства, обеспечивающего
запись и (или) считывание информации) и
устройства хранения — носителя.
Основные виды
накопителей:
-
накопители на
гибких магнитных дисках (НГМД); -
накопители на
жестких магнитных дисках (НЖМД); -
накопители на
магнитной ленте (НМЛ); -
накопители CD-ROM,
CD-RW, DVD.
Им соответствуют
основные виды носителей:
-
гибкие магнитные
диски (Floppy
Disk) (диаметром
3,5’’ и ёмкостью 1,44 Мб; диаметром 5,25’’
и ёмкостью 1,2 Мб (в настоящее время
устарели и практически не используются,
выпуск накопителей, предназначенных
для дисков диаметром 5,25’’, тоже
прекращён)), диски для сменных носителей; -
жёсткие магнитные
диски (Hard
Disk); -
кассеты для
стримеров и других НМЛ; -
диски
CD-ROM, CD-R, CD-RW, DVD.
Запоминающие
устройства принято делить на виды и
категории в связи с их принципами
функционирования, эксплуатационно-техническими,
физическими, программными и др.
характеристиками. Так, например, по
принципам функционирования различают
следующие виды устройств: электронные,
магнитные, оптические и смешанные –
магнитооптические. Каждый тип устройств
организован на основе соответствующей
технологии хранения/воспроизведения/записи
цифровой информации. Поэтому, в связи
с видом и техническим исполнением
носителя информации, различают:
электронные, дисковые и ленточные
устройства.
Основные
характеристики накопителей и носителей:
-
информационная
ёмкость; -
скорость обмена
информацией; -
надёжность хранения
информации; -
стоимость.
Остановимся
подробнее на рассмотрении вышеперечисленных
накопителей и носителей.
Принцип работы
магнитных
запоминающих устройств
основан на способах хранения информации
с использованием магнитных свойств
материалов
-
Микропроцессор,
определение, назначение, основные
характеристики
Микропроцессор
(МП) — это программно-управляемое
электронное цифровое устройство,
предназначенное для обработки цифровой
информации и управления процессом этой
обработки, выполненное на одной или
нескольких интегральных схемах с высокой
степенью интеграции электронных
элементов.
Микропроцессор характеризуется:
1) тактовой частотой,
определяющей максимальное время
выполнения переключения элементов в
ЭВМ;
2) разрядностью,
т.е. максимальным числом одновременно
обрабатываемых двоичных разрядов
Разрядность МП
обозначается m/n/k/
и включает:
m
— Разрядность внутренних регистров,
определяет принадлежность к тому или
иному классу процессоров;
n
— Разрядность шины данных, определяет
скорость передачи информации;
k
— Разрядность шины адреса, определяет
размер адресного пространства. Например,
МП i8088
характеризуется значениями m/n/k=16/8/20;
3) архитектурой.
Понятие архитектуры микропроцессора
включает в себя систему команд и способы
адресации, возможность совмещения
выполнения команд во времени, наличие
дополнительных устройств в составе
микропроцессора, принципы и режимы его
работы выделяют понятия микроархитектуры
и макроархитектуры.
Процессор содержит в себе множество
отдельных элементов — транзисторов,
которые в совокупности и наделяют
компьютер способностью «думать». Точнее,
вычислять, производя определенные
математические операции с числами, в
которые преобразуется любая поступающая
в компьютер информация. Безусловно,
один транзистор никаких особых вычислений
произвести не может. Единственное, на
что способен этот электронный переключатель
— это пропустить сигнал дальше или
задержать его. Наличие сигнала дает
логическую единицу (да); его отсутствие
— логический же ноль (нет).
-
Микропроцессор,
определение, назначение, система команд
микропроцессора.
Система команд
— это набор
допустимых для данного процессора
управляющих кодов и способов адресации
данных. Система команд жестко связана
с конкретным типом процессора, поскольку
определяется аппаратной структурой
блока дешифрации команд, и обычно не
обладает переносимостью на другие типы
процессоров (хотя может иметь место
совместимость “снизу-вверх” в рамках
серии процессоров, как, например, в серии
i80x86
).
С физической точки
зрения код команды ничем не отличается
от обычных данных в двоичном коде,
размещенных в памяти вычислителя.
Конкретный двоичный код воспринимается
и обрабатывается процессором как команда
в том случае, когда он попадает в процессор
в фазе чтения кода команды.
зык программирования,
максимально приближенный к системе
команд конкретного микропроцессора –
это Ассемблер. В этом языке коду каждой
команды МП поставлена в соответствие
определенная мнемоника – краткое
буквенное название команды, например:
Пересылка данных
– MOV (от англ. move)
Сложение – ADD
Переход по программе
– JMP (от англ. jump)
и т.д.
(!) Вспомнить
примеры команд из лабораторных работ
Для программиста
система команд представляется как
минимально необходимый набор команд
для реализации вычислений и управления
ходом вычислительного процесса. В
систему команд традиционно входят такие
группы:
·
пересылка данных (регистр-регистр,
регистр-память, память-регистр,
специфические
команды типа память-память);все команды
пересылки выполняют, по сути, копирование
данных из ячейки-источника в ячейку-приемник;
·
арифметические операции (+, –, *, : );
·
логические операции (and,
or, xor, not) и
операции сдвига;
·
ввод-вывод – специфические команды для
передачи данных между процессором и
устройствами ввода-вывода, размещенными
в адресном пространстве ввода-вывода;
·
передача управления – при выполнении
такой команды процессор записывает в
счетчик команд PC
адрес следующей команды, взятый из
адресной части текущей команды;
·
специальные – останов, сброс, управление
прерываниями, управление режимом
пониженного энергопотребления и т.п.
-
Параллелизм,
суперскалярность, параллелизм данных
Параллелизм
— Основная идея подхода, основанного
на параллелизме данных, заключается в
том, что одна операция выполняется сразу
над всеми элементами массива данных.
Различные фрагменты такого массива
обрабатываются на векторном процессоре
или на разных процессорах параллельной
машины. Распределением данных между
процессорами занимается программа.
Векторизация или распараллеливание в
этом случае чаще всего выполняется уже
на этапе компиляции — перевода исходного
текста программы в машинные команды.
Идея распараллеливания
вычислений основана на том, что большинство
задач может быть разделено на набор
меньших задач, которые могут быть решены
одновременно. Обычно параллельные
вычисления требуют координации действий.
Параллельные вычисления существуют в
нескольких формах: параллелизм на уровне
битов, параллелизм на уровне инструкций,
параллелизм данных, параллелизм задач.
Параллельные вычисления использовались
много лет в основном в высокопроизводительных
вычислениях, но в последнее время к ним
возрос интерес вследствие существования
физических ограничений на рост тактовой
частоты процессоров. Параллельные
вычисления стали доминирующей парадигмой
в архитектуре
компьютеров,
в основном в форме многоядерных
процессоров.[2]
Писать программы
для параллельных систем сложнее, чем
для последовательных[3],
так как конкуренция за ресурсы представляет
новый класс потенциальных ошибок в
программном обеспечении (багов),
среди которых состояние
гонки
является самой распространённой.
Взаимодействие и синхронизация
между процессами представляют большой
барьер для получения высокой
производительности параллельных систем.
В последние годы также стали рассматривать
вопрос о потреблении электроэнергии
параллельными компьютерами.[4]
Характер увеличения скорости программы
в результате распараллеливания
объясняется законом
Амдала.
Суперскалярность (superscalar) — способность
исполнения процессором нескольких
инструкций (команд) за один такт.
Поддерживается большинством современных
центральных процессоров архитектуры
x86, начиная с пятого поколения (Intel
Pentium).
-
Параллелизм,
параллелизм на уровне битов
Эта форма параллелизма
основана на увеличении размера машинного
слова.
Увеличение размера машинного слова
уменьшает количество операций, необходимых
процессору для выполнения действий над
переменными, чей размер превышает размер
машинного слова. К примеру: на 8-битном
процессоре нужно сложить два 16-битных
целых числа. Для этого вначале нужно
сложить нижние 8 бит чисел, затем сложить
верхние 8 бит и к результату их сложения
прибавить значение флага
переноса.
Итого 3 инструкции. С 16-битным процессором
можно выполнить эту операцию одной
инструкцией.
Исторически
4-битные микропроцессоры были заменены
8-битными, затем появились 16-битные и
32-битные. 32-битные процессоры долгое
время были стандартом в повседневных
вычислениях. С появлением технологии
x86-64
для этих целей стали использовать
64-битные процессоры.
-
Параллелизм,
КЭШ память, технология Hyper
Treading
кэш-память (от англ. caсhe – тайник).
Она служит буфером между RAM и микропроцессором
и позволяет увеличить скорость выполнения
операций, т.к. является сверхбыстродействующей.
В нее помещаются данные, которые процессор
получил и будет использовать в ближайшие
такты своей работы. Эта память хранит
копии наиболее часто используемых
участков RAM. При обращении микропроцессора
к памяти сначала ищутся данные в
кэш-памяти, а затем, если остается
необходимость, в оперативной памяти;
HT
1. Данная технология
предназначена для увеличения эффективности
работы процессора. Дело в том, что, по
оценкам Intel, большую часть времени
работает всего 30% (кстати,
достаточно спорная цифра — подробности
ее вычисления неизвестны)
всех исполнительных устройств в
процессоре. Согласитесь, это достаточно
обидно. И то, что возникла идея каким-то
образом «догрузить» остальные 70%
— выглядит вполне логично (тем
более что сам по себе процессор Pentium 4,
в котором и внедрят эту технологию,
отнюдь не страдает от избыточной
производительности на мегагерц).
Так что эту идею автор вынужден признать
вполне здравой.
2. Суть технологии
Hyper Threading состоит в том, что во время
исполнения одной «нити» программы
простаивающие исполнительные устройства
могут заняться исполнением другой
«нити» программы (или
«нити» другой
программы).
Или, например, исполняя одну
последовательность команд, ожидать
данных из памяти для исполнения другой
последовательности.
3. Естественно,
выполняя различные «нити», процессор
должен каким-либо образом отличать,
какие команды к какой «нити»
относятся. Значит, есть какой-то механизм
(некая метка),
благодаря которой процессор отличает,
к какой «нити» относятся команды.
-
Параллелизм,
конвейерная обработка шины данных,
параллелизм на уровне инструкций
Параллелизм на уровне инструкций
Компьютерная
программа — это, по существу, поток
инструкций, выполняемых процессором.
Но можно изменить порядок этих инструкций,
распределить их по группам, которые
будут выполняться параллельно, без
изменения результата работы всей
программы. Данный приём известен как
параллелизм на уровне инструкций.
Продвижения в развитии параллелизма
на уровне инструкций в архитектуре
компьютеров происходили с середины
1980-х до середины 1990-х.
![]()
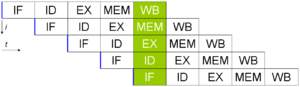
Классический
пример пятиступенчатого конвейера на
RISC-машине
(IF = выборка инструкции, ID = декодирование
инструкции, EX = выполнение инструкции,
MEM = доступ к памяти, WB = запись результата
в регистры).
Современные
процессоры имеют многоступенчатый
конвейер
команд. Каждой ступени конвейера
соответствует определённое действие,
выполняемое процессором в этой инструкции
на этом этапе. Процессор с N ступенями
конвейера может иметь одновременно до
N различных инструкций на разном уровне
законченности. Классический пример
процессора с конвейером — это
RISC-процессор
с 5-ю ступенями: выборка инструкции из
памяти (IF), декодирование инструкции
(ID), выполнение инструкции (EX), доступ к
памяти (MEM), запись результата в регистры
(WB). Процессор Pentium
4 имеет 35-тиступенчатый
конвейер.[5]
Пятиступенчатый
конвейер суперскалярного процессора,
способный выполнять две инструкции за
цикл. Может иметь по две инструкции на
каждой ступени конвейера, максимум 10
инструкций могут выполняться одновременно.
Некоторые процессоры,
дополнительно к использованию конвейеров,
обладают возможностью выполнять
несколько инструкций одновременно, что
даёт дополнительный параллелизм на
уровне инструкций. Возможна реализация
данного метода при помощи суперскалярности,
когда инструкции могут быть сгруппированы
вместе для параллельного выполнения
(если в них нет зависимости
между данными). Также возможны
реализации с использованием явного
параллелизма на уровне инструкций: VLIW
и EPIC.
Конвейерная
организация процессора означает,
что
многие сложные действия разбиваются
начто
многие сложные действия разбиваются
наэтапы
с небольшим временем выполнения.этапы
с небольшим временем выполнения.
Каждый
этап выполняется в отдельном
устройствеКаждый
этап выполняется в отдельном
устройстве(блоке).(блоке).
Конвейеризация
позволяет несколькимКонвейеризация
позволяет несколькимвнутренним
блокам МП работать одновременновнутренним
блокам МП работать одновременно,,совмещая
дешифрование команды, операциисовмещая
дешифрование команды, операцииАЛУ,
вычисление эффективного адреса и
циклыАЛУ,
вычисление эффективного адреса и
циклышины
нескольких командшины
нескольких команд
-
Параллелизм,
дополнительный контроль за целостностью
данных, параллелизм задач
Дополнительный
контроль за целостностью данных: проверка
на четность адресов и внутренних массивов
данных. Проверка на четность обеспечивает
обнаружение ошибок в 53% компонент на
кристалле Pentium,
не уменьшая скорость выполнения команд.
Стиль программирования, основанный на
параллелизме задач, подразумевает, что
вычислительная задача разбивается на
несколько относительно самостоятельных
подзадач и каждый процессор загружается
своей собственной подзадачей.
-
Параллелизм,
трассировка выполнения команд,
виртуализация
Трассиро́вка — процесс пошагового
выполнения программы. В режиме трассировки
программист видит последовательность
выполнения команд и значения переменных
на данном шаге выполнения программы,
что позволяет легче обнаруживать ошибки.
Трассировка может быть начата и окончена
в любом месте программы, выполнение
программы может останавливаться на
каждой команде или на точках
останова, трассировка может
выполняться с заходом в процедуры и без
заходов.
Виртуализация это абстракция вычислительных
ресурсов и предоставление пользователю
системы, которая «инкапсулирует»
(скрывает в себе) собственную реализацию.
Проще говоря, пользователь работает с
удобным для себя представлением объекта,
и для него не имеет значения, как объект
устроен в действительности
Виртуализация
серверов. Виртуализация
серверов подразумевает запуск на одном
физическом сервере нескольких виртуальных
серверов. Виртуальные машины или сервера
представляют собой приложения, запущенные
на хостовой операционной системе,
которые эмулируют физические
устройства сервера. На каждой
виртуальной машине может быть установлена
операционная система, на которую могут
быть установлены приложения и службы.
Типичные представители это продукты
VMware vSphere и
Microsoft
Hyper-V.
-
Системный
блок, форм-фактор, виды корпусов.
Систе́мный
блок (сленг.
системник, кейс, корпус) —
функциональный элемент, защищающий
внутренние компоненты компьютера
от внешнего воздействия и механических
повреждений, поддерживающий необходимый
температурный
режим внутри, экранирующий создаваемые
внутренними компонентами электромагнитное
излучение и являющийся основой для
дальнейшего расширения системы. Системные
блоки массово изготавливают заводским
способом из деталей на основе стали,
алюминия
и пластика.
Для креативного
творчества используются такие
материалы, как древесина
или органическое
стекло.
Заметную роль
играет здесь форм-фактор
материнской платы. «Что это за галиматья?»
— спросите вы. Форм-фактор
— это определение физических особенностей
материнской платы (главное их отличие
«на глаз» — это размер). Достигается это
не сверхновым оборудованием, которое
позволяет штамповать более компактные
и дешевые материнские платы, а за счет
уменьшения количества разъемов и блока
питания. То есть, в системник, влезет
только та материнская плата, которая
будет с ним одного форм-фактора, либо
на уровень меньше. Но прошу — вас не
паникуйте — все намного проще чем,
кажется. На
данный момент используется несколько
форм-факторов
для материнских плат:
1. ATX
— это
стандартный форм-фактор использующийся
в большинстве компьютеров, его, и только
его, я вам рекомендую брать.
2. Mini-ATX
— это уменьшенная версия ATX, материнская
плата этого форм-фактора используется
там же где и ATX. Часто в теперешних
компьютерах встречается именно эта
плата.
3. Micro-ATX
— более упрощенный чем ATX, по размерам
меньше, и естественно материнская плата
micro-ATX будет стоить дешевле, и сам корпус
размерами и ценой будет меньше.
4. Flex-ATX
— это еще более низкие по цене и качеству
материнские платы. Я их не видел, но
думаю — они сугубо для работы.
-
Горизонтальные
(размеры указаны в миллиметрах):-
Desktop (533×419×152)
-
FootPrint (406×406×152)
-
SlimLine (406×406×101)
-
UltraSlimLine (381×352×75)
-
-
Вертикальные
(размеры указаны в миллиметрах):-
MiniTower (152×432×432)
-
MidiTower (173×432×490)
-
BigTower (190×482×820)
-
SuperFullTower (разные
размеры)
-
-
Блок
питания, основное назначение,
характеристики
Главное
назначение блоков питания — преобразование
электрической энергии, поступающей из
сети переменного тока, в энергию,
пригодную для питания узлов компьютера.
Блок
питания преобразует сетевое переменное
напряжение 220 В, 50 Гц (120 В, 60 Гц) в постоянные
напряжения +3,3, +5 и +12 В. Как правило, для
питания цифровых схем (системной платы,
плат адаптеров и дисковых накопителей)
используется напряжение +3,3 или +5 В, а
для двигателей (дисководов и различных
вентиляторов) — +12 В. Компьютер работает
надежно только в том случае, если значения
напряжения в этих цепях не выходят за
установленные пределы.
Стабильность
напряжений
Далее рассмотрим
такую характеристику как, стабильность
напряжений, выдаваемых блоком питания.
В процессе работы, какой идеальный не
был бы блок питания, его напряжения
изменяются. Увеличение напряжения
вызывает в первую очередь увеличение
токов покоя всех схем, а также изменение
параметров схем. Так, например, для
усилителя мощности увеличение напряжения
увеличивает его выходную мощность.
Увеличенную мощность могут не выдержать
некоторые электронные детали и сгореть.
Это же увеличение мощности приводит к
росту рассеиваемой мощности электронными
элементами, а, следовательно, к росту
температуры этих элементов. Что приводит
к перегреву и/или изменению характеристик.
Снижение напряжения
наоборот уменьшает ток покоя, и также
ухудшает характеристики схем, например
амплитуду выходного сигнала. При снижении
ниже определенного уровня определенные
схемы перестают работать. Особенно к
этому чувствительна электроника жестких
дисков.
Допустимые
отклонения напряжения на линиях блока
питания описаны в стандарте ATX и в среднем
не должны превышать ±5% от номинала
линии.
Для комплексного
отображения величины просадки напряжений
используют кросс-нагрузочную
характеристику. Она представляет собой
цветовое отображение уровня отклонения
напряжения выбранной линии при нагрузке
двух линий: выбранной и +12В.
Коэффициент
полезного действия
Перейдем теперь
к коэффициенту полезного действия или
сокращенно КПД. Со школы многие помнят
– это отношение полезной работы к
затраченной. КПД показывает сколько из
потребленной энергии превратилось в
полезную энергию. Чем выше КПД, тем
меньше надо платить за электроэнергию
потребляемую компьютером. Большинство
качественных блоков питания имеют
схожий КПД, он варьирует в диапазоне не
больше 10%, но КПД блоков питания с ПККМ
(PPFC) и АККМ (APFC) существенно выше.
Коэффициент
мощности
Как параметр, на
который следует обращать внимание при
выборе БП, коэффициент мощности менее
значим, но от него зависят другие
величины. При малом значении коэффициента
мощности будет и малое значение КПД.
Как было отмечено выше, корректоры
коэффициента мощности приносят множество
улучшений. Больший коэффициент мощности
приведет к снижению токов в сети.
-
Блок
питания, основное назначение, перечислите
основные разъемы блока питания и их
назначение

ыбирая блока
питания, первым делом необходимо обращать
внимания на стандарт интерфейса (ATX
2.0, ATX 2.2, ATX 2.3).
Стандарт блока питания должен
соответствовать стандарту материнской
платы.
В 2003 года основной разъём
питания для материнской платы был
расширен на 4 контакта: с 20pin, до 24pin. Это
было необходимо для поддержки видеокарт
с интерфейсом PCIe, которые потребляют
до 75 W от материнской платы.


Основной
24-контактый разъём питания и 20+4 pin разъем
питания
Если видеокартам
не хватает получаемого питания через
разъем PCI-Express,
то используют дополнительный 6-контактный
кабель от блока питания.
Разъем
дополнительного питания видеокарт
PCI-Express схож с разъемом дополнительного
питания процессора.

4-контактный
разъем для питания процессора и
6-контактний разъем для дополнительного
питания PCIe-видеокарт
Разъем типа Molex
предназначен для обеспечения питанием
жестких дисков стандарта UltraATA
и других устройств (CD-, DVD-приводы). Но в
связи с ростом популярности жестких
дисков стандарта SATA,
количество разъемов Molex в блоках питания
уменьшилось.
Параллелизм уровня команд (Instruction Level Parallelism, ILP) – это потенциальное перекрытие нескольких инструкций во времени. Благодаря ILP такие инструкции могут выполняться параллельно, повышая производительность.
Базовый блок – это последовательность инструкций, имеющая одну точку входа и одну точку выхода. Параллелизм присутствует среди инструкций базового блока.
Для получения существенного прироста производительности необходимо использовать параллелизм не только внутри, но и между базовыми блоками.
Простейший способ увеличения ILP – использование параллелизма итераций цикла. Разворачивание циклов (Loop Unrolling) – увеличение числа инструкций базового блока (копирование тела цикла несколько раз).
Определение степени зависимости между инструкциями – критический
фактор для определения уровня параллелизма в программе. Независимые
инструкции могут выполняться одновременно. Зависимые должны
выполняться по порядку, однако они могут частично перекрываться во
времени
Зависимость – свойство программы.
Конфликт, возникший (или не возникший) из зависимости – свойство организации архитектуры.
Существует 3 типа зависимостей:
- Зависимости по данным.
- Зависимости по именам.
- Зависимости по управлению.
Зависимости по данным
Зависимость по данным возникает, в случаях:
- Инструкция i создает результат, используемый инструкцией j.
- Команда 2 зависит по данным от какой-либо команды 3, которая в свою очередь является зависимой по данным от команды 1.
Зависимости по именам
Зависимость по именам возникает, когда инструкции используют один и тот же регистр или ячейку памяти (имя), однако между ними нет передачи данных (потока данных), соответствующей имени.
Виды:
- Антизависимость – возникает, если команда_2 записывает в ячейку памяти, которую команда_1 считывает, и команда_1 выполняется первой.
- Зависимость по выходу – возникает, когда команда_1 и команда_2 пишут результат в одну и ту же ячейку памяти. Порядок выполнения этих команд должен сохраняться.
Переименование регистров – одна из техник для преодоления таких зависимостей.
Зависимости по управлению
Зависимости по управлению определяют порядок выполнения команд по отношению к команде условного перехода.
Имеются два ограничения, связанные с зависимостями по управлению:
- Зависящая по управлению команда, не может быть в результате перемещения поставлена перед командой условного перехода, стать независимой от него.
- Команда, не зависимая по управлению от команды условного перехода, не может быть поставлена после команды условного перехода так, что её выполнение станет управляться этим условным переходом.
Критической задачей при использовании ILP является сохранение корректности программы. Для этого необходимо поддерживать два свойства: поведение при исключениях и поток данных. Поведение при исключенияхподразумевает, что никакие перестановки команд не должны влиять на то, как выбрасывается исключение, на его семантику. Поток данных – это поток значений, порождаемый и потребляемый инструкциями. Для его поддержания нужно обеспечить сохранение зависимостей по данным и по управлению. ILP может выявляться компилятором и аппаратно. На широком использовании ILP базируются суперскалярные и VLIW-архитектуры.
Низкоуровневый параллелизм достигается, в частности, выдачей (issue) нескольких команд за один тактовый цикл. Процессоры, в которых реализуется этот принцип, делятся на две категории: суперскалярные и VLIW (Very Long Instruction Word – процессоры со сверхдлинным словом).
Суперскалярные процессоры способны за один такт вызывать для выполнения несколько команд (обычно от 2 до 6), что определяется как аппаратной реализацией, так и последовательностью команд.
Другой вид параллелизма реализуется во VLIW-системах. Первые системы действительно отличались длинным словом с командами, которые обращались к различным функциональным блокам.
Такое решение показало себя недостаточно гибким, т.к. не каждая команда использовала все доступные функциональные модули, в результате появлялось большое количество пустых операций.
В современных VLIW-системах предусматривается механизм маркировки связи команд для того, чтобы процессор мог выбрать и запустить связку. Задача по подготовке и завершению связок выполняется компилятором. Таким образом в VLIW-системах решение проблем совместимости переносится со стадии исполнения на стадию компиляции.
Преимущества такого подхода:
- Упрощается аппаратное обеспечение;
- Поскольку на стадии компиляции нет жестких временных ограничений, то поиск и составление связок может быть выполнен более качественно.
Суперскалярные:
- Динамическое расписание
- Аппаратное определение конфликтов
- Динамическая выдача инструкций
- Хорошая совместимость кода
VLIW:
- Статическое расписание
- Программное определение конфликтов
- Статическая выдача
- Проблемы совместимости кода для разных версий процессора