
A computer program is a sequence or set of instructions in a programming language for a computer to execute. Computer programs are one component of software, which also includes documentation and other intangible components.[1]
A computer program in its human-readable form is called source code. Source code needs another computer program to execute because computers can only execute their native machine instructions. Therefore, source code may be translated to machine instructions using the language’s compiler. (Assembly language programs are translated using an assembler.) The resulting file is called an executable. Alternatively, source code may execute within the language’s interpreter.[2]
If the executable is requested for execution, then the operating system loads it into memory and starts a process.[3] The central processing unit will soon switch to this process so it can fetch, decode, and then execute each machine instruction.[4]
If the source code is requested for execution, then the operating system loads the corresponding interpreter into memory and starts a process. The interpreter then loads the source code into memory to translate and execute each statement.[2] Running the source code is slower than running an executable.[a] Moreover, the interpreter must be installed on the computer.
Example computer program[edit]

The «Hello, World!» program is used to illustrate a language’s basic syntax. The syntax of the language BASIC (1964) was intentionally limited to make the language easy to learn.[5] For example, variables are not declared before being used.[6] Also, variables are automatically initialized to zero.[6] Here is an example computer program, in Basic, to average a list of numbers:[7]
10 INPUT "How many numbers to average?", A 20 FOR I = 1 TO A 30 INPUT "Enter number:", B 40 LET C = C + B 50 NEXT I 60 LET D = C/A 70 PRINT "The average is", D 80 END
Once the mechanics of basic computer programming are learned, more sophisticated and powerful languages are available to build large computer systems.[8]
History[edit]
Improvements in software development are the result of improvements in computer hardware. At each stage in hardware’s history, the task of computer programming changed dramatically.
Analytical Engine[edit]

In 1837, Charles Babbage was inspired by Jacquard’s loom to attempt to build the Analytical Engine.[9]
The names of the components of the calculating device were borrowed from the textile industry. In the textile industry, yarn was brought from the store to be milled. The device had a «store» which consisted of memory to hold 1,000 numbers of 50 decimal digits each.[10] Numbers from the «store» were transferred to the «mill» for processing. It was programmed using two sets of perforated cards. One set directed the operation and the other set inputted the variables.[9][11] However, after more than 17,000 pounds of the British government’s money, the thousands of cogged wheels and gears never fully worked together.[12]
Ada Lovelace worked for Charles Babbage to create a description of the Analytical Engine (1843).[13] The description contained Note G which completely detailed a method for calculating Bernoulli numbers using the Analytical Engine. This note is recognized by some historians as the world’s first computer program.[12] Other historians consider Babbage himself wrote the first computer program for the Analytical Engine. It listed a sequence of operations to compute the solution for a system of two linear equations.[14]
Universal Turing machine[edit]

In 1936, Alan Turing introduced the Universal Turing machine, a theoretical device that can model every computation.[15]
It is a finite-state machine that has an infinitely long read/write tape. The machine can move the tape back and forth, changing its contents as it performs an algorithm. The machine starts in the initial state, goes through a sequence of steps, and halts when it encounters the halt state.[16] All present-day computers are Turing complete.[17]
ENIAC[edit]

The Electronic Numerical Integrator And Computer (ENIAC) was built between July 1943 and Fall 1945. It was a Turing complete, general-purpose computer that used 17,468 vacuum tubes to create the circuits. At its core, it was a series of Pascalines wired together.[18] Its 40 units weighed 30 tons, occupied 1,800 square feet (167 m2), and consumed $650 per hour (in 1940s currency) in electricity when idle.[18] It had 20 base-10 accumulators. Programming the ENIAC took up to two months.[18] Three function tables were on wheels and needed to be rolled to fixed function panels. Function tables were connected to function panels by plugging heavy black cables into plugboards. Each function table had 728 rotating knobs. Programming the ENIAC also involved setting some of the 3,000 switches. Debugging a program took a week.[19] It ran from 1947 until 1955 at Aberdeen Proving Ground, calculating hydrogen bomb parameters, predicting weather patterns, and producing firing tables to aim artillery guns.[20]
Stored-program computers[edit]
Instead of plugging in cords and turning switches, a stored-program computer loads its instructions into memory just like it loads its data into memory.[21] As a result, the computer could be programmed quickly and perform calculations at very fast speeds.[22] Presper Eckert and John Mauchly built the ENIAC. The two engineers introduced the stored-program concept in a three-page memo dated February 1944.[23] Later, in September 1944, Dr. John von Neumann began working on the ENIAC project. On June 30, 1945, von Neumann published the First Draft of a Report on the EDVAC, which equated the structures of the computer with the structures of the human brain.[22] The design became known as the von Neumann architecture. The architecture was simultaneously deployed in the constructions of the EDVAC and EDSAC computers in 1949.[24]
The IBM System/360 (1964) was a family of computers, each having the same instruction set architecture. The Model 20 was the smallest and least expensive. Customers could upgrade and retain the same application software.[25] The Model 195 was the most premium. Each System/360 model featured multiprogramming[25]—having multiple processes in memory at once. When one process was waiting for input/output, another could compute.
IBM planned for each model to be programmed using PL/1.[26] A committee was formed that included COBOL, Fortran and ALGOL programmers. The purpose was to develop a language that was comprehensive, easy to use, extendible, and would replace Cobol and Fortran.[26] The result was a large and complex language that took a long time to compile.[27]

Computers manufactured until the 1970s had front-panel switches for manual programming.[28] The computer program was written on paper for reference. An instruction was represented by a configuration of on/off settings. After setting the configuration, an execute button was pressed. This process was then repeated. Computer programs also were automatically inputted via paper tape, punched cards or magnetic-tape. After the medium was loaded, the starting address was set via switches, and the execute button was pressed.[28]
Very Large Scale Integration[edit]

A major milestone in software development was the invention of the Very Large Scale Integration (VLSI) circuit (1964).[29] Following World War II, tube-based technology was replaced with point-contact transistors (1947) and bipolar junction transistors (late 1950s) mounted on a circuit board.[29] During the 1960s, the aerospace industry replaced the circuit board with an integrated circuit chip.[29]
Robert Noyce, co-founder of Fairchild Semiconductor (1957) and Intel (1968), achieved a technological improvement to refine the production of field-effect transistors (1963).[30] The goal is to alter the electrical resistivity and conductivity of a semiconductor junction. First, naturally occurring silicate minerals are converted into polysilicon rods using the Siemens process.[31] The Czochralski process then converts the rods into a monocrystalline silicon, boule crystal.[32] The crystal is then thinly sliced to form a wafer substrate. The planar process of photolithography then integrates unipolar transistors, capacitors, diodes, and resistors onto the wafer to build a matrix of metal–oxide–semiconductor (MOS) transistors.[33][34] The MOS transistor is the primary component in integrated circuit chips.[30]
Originally, integrated circuit chips had their function set during manufacturing. During the 1960s, controlling the electrical flow migrated to programming a matrix of read-only memory (ROM). The matrix resembled a two-dimensional array of fuses.[29] The process to embed instructions onto the matrix was to burn out the unneeded connections.[29] There were so many connections, firmware programmers wrote a computer program on another chip to oversee the burning.[29] The technology became known as Programmable ROM. In 1971, Intel installed the computer program onto the chip and named it the Intel 4004 microprocessor.[35]

The terms microprocessor and central processing unit (CPU) are now used interchangeably. However, CPUs predate microprocessors. For example, the IBM System/360 (1964) had a CPU made from circuit boards containing discrete components on ceramic substrates.[36]
Sac State 8008[edit]

The Intel 4004 (1971) was a 4-bit microprocessor designed to run the Busicom calculator. Five months after its release, Intel released the Intel 8008, an 8-bit microprocessor. Bill Pentz led a team at Sacramento State to build the first microcomputer using the Intel 8008: the Sac State 8008 (1972).[37] Its purpose was to store patient medical records. The computer supported a disk operating system to run a Memorex, 3-megabyte, hard disk drive.[29] It had a color display and keyboard that was packaged in a single console. The disk operating system was programmed using IBM’s Basic Assembly Language (BAL). The medical records application was programmed using a BASIC interpreter.[29] However, the computer was an evolutionary dead-end because it was extremely expensive. Also, it was built at a public university lab for a specific purpose.[37] Nonetheless, the project contributed to the development of the Intel 8080 (1974) instruction set.[29]
x86 series[edit]
![]()
In 1978, the modern software development environment began when Intel upgraded the Intel 8080 to the Intel 8086. Intel simplified the Intel 8086 to manufacture the cheaper Intel 8088.[38] IBM embraced the Intel 8088 when they entered the personal computer market (1981). As consumer demand for personal computers increased, so did Intel’s microprocessor development. The succession of development is known as the x86 series. The x86 assembly language is a family of backward-compatible machine instructions. Machine instructions created in earlier microprocessors were retained throughout microprocessor upgrades. This enabled consumers to purchase new computers without having to purchase new application software. The major categories of instructions are:[b]
- Memory instructions to set and access numbers and strings in random-access memory.
- Integer arithmetic logic unit (ALU) instructions to perform the primary arithmetic operations on integers.
- Floating point ALU instructions to perform the primary arithmetic operations on real numbers.
- Call stack instructions to push and pop words needed to allocate memory and interface with functions.
- Single instruction, multiple data (SIMD) instructions[c] to increase speed when multiple processors are available to perform the same algorithm on an array of data.
Changing programming environment[edit]
![]()
VLSI circuits enabled the programming environment to advance from a computer terminal (until the 1990s) to a graphical user interface (GUI) computer. Computer terminals limited programmers to a single shell running in a command-line environment. During the 1970s, full-screen source code editing became possible through a text-based user interface. Regardless of the technology available, the goal is to program in a programming language.
Programming paradigms and languages[edit]
Programming language features exist to provide building blocks to be combined to express programming ideals.[39] Ideally, a programming language should:[39]
- express ideas directly in the code.
- express independent ideas independently.
- express relationships among ideas directly in the code.
- combine ideas freely.
- combine ideas only where combinations make sense.
- express simple ideas simply.
The programming style of a programming language to provide these building blocks may be categorized into programming paradigms.[40] For example, different paradigms may differentiate:[40]
- procedural languages, functional languages, and logical languages.
- different levels of data abstraction.
- different levels of class hierarchy.
- different levels of input datatypes, as in container types and generic programming.
Each of these programming styles has contributed to the synthesis of different programming languages.[40]
A programming language is a set of keywords, symbols, identifiers, and rules by which programmers can communicate instructions to the computer.[41] They follow a set of rules called a syntax.[41]
- Keywords are reserved words to form declarations and statements.
- Symbols are characters to form operations, assignments, control flow, and delimiters.
- Identifiers are words created by programmers to form constants, variable names, structure names, and function names.
- Syntax Rules are defined in the Backus–Naur form.
Programming languages get their basis from formal languages.[42] The purpose of defining a solution in terms of its formal language is to generate an algorithm to solve the underlining problem.[42] An algorithm is a sequence of simple instructions that solve a problem.[43]
Generations of programming language[edit]
The evolution of programming language began when the EDSAC (1949) used the first stored computer program in its von Neumann architecture.[44] Programming the EDSAC was in the first generation of programming language.
- The first generation of programming language is machine language.[45] Machine language requires the programmer to enter instructions using instruction numbers called machine code. For example, the ADD operation on the PDP-11 has instruction number 24576.[46]
- The second generation of programming language is assembly language.[45] Assembly language allows the programmer to use mnemonic instructions instead of remembering instruction numbers. An assembler translates each assembly language mnemonic into its machine language number. For example, on the PDP-11, the operation 24576 can be referenced as ADD in the source code.[46] The four basic arithmetic operations have assembly instructions like ADD, SUB, MUL, and DIV.[46] Computers also have instructions like DW (Define Word) to reserve memory cells. Then the MOV instruction can copy integers between registers and memory.
-
- The basic structure of an assembly language statement is a label, operation, operand, and comment.[47]
-
- Labels allow the programmer to work with variable names. The assembler will later translate labels into physical memory addresses.
- Operations allow the programmer to work with mnemonics. The assembler will later translate mnemonics into instruction numbers.
- Operands tell the assembler which data the operation will process.
- Comments allow the programmer to articulate a narrative because the instructions alone are vague.
- The key characteristic of an assembly language program is it forms a one-to-one mapping to its corresponding machine language target.[48]
- The third generation of programming language uses compilers and interpreters to execute computer programs. The distinguishing feature of a third generation language is its independence from particular hardware.[49] Early languages include Fortran (1958), COBOL (1959), ALGOL (1960), and BASIC (1964).[45] In 1973, the C programming language emerged as a high-level language that produced efficient machine language instructions.[50] Whereas third-generation languages historically generated many machine instructions for each statement,[51] C has statements that may generate a single machine instruction.[d] Moreover, an optimizing compiler might overrule the programmer and produce fewer machine instructions than statements. Today, an entire paradigm of languages fill the imperative, third generation spectrum.
- The fourth generation of programming language emphasizes what output results are desired, rather than how programming statements should be constructed.[45] Declarative languages attempt to limit side effects and allow programmers to write code with relatively few errors.[45] One popular fourth generation language is called Structured Query Language (SQL).[45] Database developers no longer need to process each database record one at a time. Also, a simple statement can generate output records without having to understand how they are retrieved.
Imperative languages[edit]

Imperative languages specify a sequential algorithm using declarations, expressions, and statements:[52]
- A declaration introduces a variable name to the computer program and assigns it to a datatype[53] – for example:
var x: integer; - An expression yields a value – for example:
2 + 2yields 4 - A statement might assign an expression to a variable or use the value of a variable to alter the program’s control flow – for example:
x := 2 + 2; if x = 4 then do_something();
Fortran[edit]
FORTRAN (1958) was unveiled as «The IBM Mathematical FORmula TRANslating system.» It was designed for scientific calculations, without string handling facilities. Along with declarations, expressions, and statements, it supported:
- arrays.
- subroutines.
- «do» loops.
It succeeded because:
- programming and debugging costs were below computer running costs.
- it was supported by IBM.
- applications at the time were scientific.[54]
However, non-IBM vendors also wrote Fortran compilers, but with a syntax that would likely fail IBM’s compiler.[54] The American National Standards Institute (ANSI) developed the first Fortran standard in 1966. In 1978, Fortran 77 became the standard until 1991. Fortran 90 supports:
- records.
- pointers to arrays.
COBOL[edit]
COBOL (1959) stands for «COmmon Business Oriented Language.» Fortran manipulated symbols. It was soon realized that symbols did not need to be numbers, so strings were introduced.[55] The US Department of Defense influenced COBOL’s development, with Grace Hopper being a major contributor. The statements were English-like and verbose. The goal was to design a language so managers could read the programs. However, the lack of structured statements hindered this goal.[56]
COBOL’s development was tightly controlled, so dialects did not emerge to require ANSI standards. As a consequence, it was not changed for 15 years until 1974. The 1990s version did make consequential changes, like object-oriented programming.[56]
Algol[edit]
ALGOL (1960) stands for «ALGOrithmic Language.» It had a profound influence on programming language design.[57] Emerging from a committee of European and American programming language experts, it used standard mathematical notation and had a readable, structured design. Algol was first to define its syntax using the Backus–Naur form.[57] This led to syntax-directed compilers. It added features like:
- block structure, where variables were local to their block.
- arrays with variable bounds.
- «for» loops.
- functions.
- recursion.[57]
Algol’s direct descendants include Pascal, Modula-2, Ada, Delphi and Oberon on one branch. On another branch the descendants include C, C++ and Java.[57]
Basic[edit]
BASIC (1964) stands for «Beginner’s All-Purpose Symbolic Instruction Code.» It was developed at Dartmouth College for all of their students to learn.[7] If a student did not go on to a more powerful language, the student would still remember Basic.[7] A Basic interpreter was installed in the microcomputers manufactured in the late 1970s. As the microcomputer industry grew, so did the language.[7]
Basic pioneered the interactive session.[7] It offered operating system commands within its environment:
- The ‘new’ command created an empty slate.
- Statements evaluated immediately.
- Statements could be programmed by preceding them with a line number.
- The ‘list’ command displayed the program.
- The ‘run’ command executed the program.
However, the Basic syntax was too simple for large programs.[7] Recent dialects added structure and object-oriented extensions. Microsoft’s Visual Basic is still widely used and produces a graphical user interface.[6]
C[edit]
C programming language (1973) got its name because the language BCPL was replaced with B, and AT&T Bell Labs called the next version «C.» Its purpose was to write the UNIX operating system.[50] C is a relatively small language, making it easy to write compilers. Its growth mirrored the hardware growth in the 1980s.[50] Its growth also was because it has the facilities of assembly language, but uses a high-level syntax. It added advanced features like:
- inline assembler.
- arithmetic on pointers.
- pointers to functions.
- bit operations.
- freely combining complex operators.[50]

C allows the programmer to control which region of memory data is to be stored. Global variables and static variables require the fewest clock cycles to store. The stack is automatically used for the standard variable declarations. Heap memory is returned to a pointer variable from the malloc() function.
- The global and static data region is located just above the program region. (The program region is technically called the text region. It’s where machine instructions are stored.)
-
- The global and static data region is technically two regions.[58] One region is called the initialized data segment, where variables declared with default values are stored. The other region is called the block started by segment, where variables declared without default values are stored.
- Variables stored in the global and static data region have their addresses set at compile-time. They retain their values throughout the life of the process.
-
- The global and static region stores the global variables that are declared on top of (outside) the
main()function.[59] Global variables are visible tomain()and every other function in the source code.
- The global and static region stores the global variables that are declared on top of (outside) the
- On the other hand, variable declarations inside of
main(), other functions, or within{}block delimiters are local variables. Local variables also include formal parameter variables. Parameter variables are enclosed within the parenthesis of function definitions.[60] They provide an interface to the function.
-
- Local variables declared using the
staticprefix are also stored in the global and static data region.[58] Unlike global variables, static variables are only visible within the function or block. Static variables always retain their value. An example usage would be the functionint increment_counter(){static int counter = 0; counter++; return counter;}[e]
- Local variables declared using the
- The stack region is a contiguous block of memory located near the top memory address.[61] Variables placed in the stack are populated from top to bottom.[f][61] A stack pointer is a special-purpose register that keeps track of the last memory address populated.[61] Variables are placed into the stack via the assembly language PUSH instruction. Therefore, the addresses of these variables are set during runtime. The method for stack variables to lose their scope is via the POP instruction.
-
- Local variables declared without the
staticprefix, including formal parameter variables,[62] are called automatic variables[59] and are stored in the stack.[58] They are visible inside the function or block and lose their scope upon exiting the function or block.
- Local variables declared without the
- The heap region is located below the stack.[58] It is populated from the bottom to the top. The operating system manages the heap using a heap pointer and a list of allocated memory blocks.[63] Like the stack, the addresses of heap variables are set during runtime. An out of memory error occurs when the heap pointer and the stack pointer meet.
-
- C provides the
malloc()library function to allocate heap memory.[64] Populating the heap with data is an additional copy function. Variables stored in the heap are economically passed to functions using pointers. Without pointers, the entire block of data would have to be passed to the function via the stack.
- C provides the
C++[edit]
In the 1970s, software engineers needed language support to break large projects down into modules.[65] One obvious feature was to decompose large projects physically into separate files. A less obvious feature was to decompose large projects logically into abstract datatypes.[65] At the time, languages supported concrete (scalar) datatypes like integer numbers, floating-point numbers, and strings of characters. Concrete datatypes have their representation as part of their name.[66] Abstract datatypes are structures of concrete datatypes, with a new name assigned. For example, a list of integers could be called integer_list.
In object-oriented jargon, abstract datatypes are called classes. However, a class is only a definition; no memory is allocated. When memory is allocated to a class and bound to an identifier, it’s called an object.[67]
Object-oriented imperative languages developed by combining the need for classes and the need for safe functional programming.[68] A function, in an object-oriented language, is assigned to a class. An assigned function is then referred to as a method, member function, or operation. Object-oriented programming is executing operations on objects.[69]
Object-oriented languages support a syntax to model subset/superset relationships. In set theory, an element of a subset inherits all the attributes contained in the superset. For example, a student is a person. Therefore, the set of students is a subset of the set of persons. As a result, students inherit all the attributes common to all persons. Additionally, students have unique attributes that other people do not have. Object-oriented languages model subset/superset relationships using inheritance.[70] Object-oriented programming became the dominant language paradigm by the late 1990s.[65]
C++ (1985) was originally called «C with Classes.»[71] It was designed to expand C’s capabilities by adding the object-oriented facilities of the language Simula.[72]
An object-oriented module is composed of two files. The definitions file is called the header file. Here is a C++ header file for the GRADE class in a simple school application:
// grade.h // ------- // Used to allow multiple source files to include // this header file without duplication errors. // ---------------------------------------------- #ifndef GRADE_H #define GRADE_H class GRADE { public: // This is the constructor operation. // ---------------------------------- GRADE ( const char letter ); // This is a class variable. // ------------------------- char letter; // This is a member operation. // --------------------------- int grade_numeric( const char letter ); // This is a class variable. // ------------------------- int numeric; }; #endif
A constructor operation is a function with the same name as the class name.[73] It is executed when the calling operation executes the new statement.
A module’s other file is the source file. Here is a C++ source file for the GRADE class in a simple school application:
// grade.cpp // --------- #include "grade.h" GRADE::GRADE( const char letter ) { // Reference the object using the keyword 'this'. // ---------------------------------------------- this->letter = letter; // This is Temporal Cohesion // ------------------------- this->numeric = grade_numeric( letter ); } int GRADE::grade_numeric( const char letter ) { if ( ( letter == 'A' || letter == 'a' ) ) return 4; else if ( ( letter == 'B' || letter == 'b' ) ) return 3; else if ( ( letter == 'C' || letter == 'c' ) ) return 2; else if ( ( letter == 'D' || letter == 'd' ) ) return 1; else if ( ( letter == 'F' || letter == 'f' ) ) return 0; else return -1; }
Here is a C++ header file for the PERSON class in a simple school application:
// person.h // -------- #ifndef PERSON_H #define PERSON_H class PERSON { public: PERSON ( const char *name ); const char *name; }; #endif
Here is a C++ source file for the PERSON class in a simple school application:
// person.cpp // ---------- #include "person.h" PERSON::PERSON ( const char *name ) { this->name = name; }
Here is a C++ header file for the STUDENT class in a simple school application:
// student.h // --------- #ifndef STUDENT_H #define STUDENT_H #include "person.h" #include "grade.h" // A STUDENT is a subset of PERSON. // -------------------------------- class STUDENT : public PERSON{ public: STUDENT ( const char *name ); GRADE *grade; }; #endif
Here is a C++ source file for the STUDENT class in a simple school application:
// student.cpp // ----------- #include "student.h" #include "person.h" STUDENT::STUDENT ( const char *name ): // Execute the constructor of the PERSON superclass. // ------------------------------------------------- PERSON( name ) { // Nothing else to do. // ------------------- }
Here is a driver program for demonstration:
// student_dvr.cpp // --------------- #include <iostream> #include "student.h" int main( void ) { STUDENT *student = new STUDENT( "The Student" ); student->grade = new GRADE( 'a' ); std::cout // Notice student inherits PERSON's name << student->name << ": Numeric grade = " << student->grade->numeric << "n"; return 0; }
Here is a makefile to compile everything:
# makefile # -------- all: student_dvr clean: rm student_dvr *.o student_dvr: student_dvr.cpp grade.o student.o person.o c++ student_dvr.cpp grade.o student.o person.o -o student_dvr grade.o: grade.cpp grade.h c++ -c grade.cpp student.o: student.cpp student.h c++ -c student.cpp person.o: person.cpp person.h c++ -c person.cpp
Declarative languages[edit]
Imperative languages have one major criticism: assigning an expression to a non-local variable may produce an unintended side effect.[74] Declarative languages generally omit the assignment statement and the control flow. They describe what computation should be performed and not how to compute it. Two broad categories of declarative languages are functional languages and logical languages.
The principle behind a functional language is to use lambda calculus as a guide for a well defined semantic.[75] In mathematics, a function is a rule that maps elements from an expression to a range of values. Consider the function:
times_10(x) = 10 * x
The expression 10 * x is mapped by the function times_10() to a range of values. One value happens to be 20. This occurs when x is 2. So, the application of the function is mathematically written as:
times_10(2) = 20
A functional language compiler will not store this value in a variable. Instead, it will push the value onto the computer’s stack before setting the program counter back to the calling function. The calling function will then pop the value from the stack.[76]
Imperative languages do support functions. Therefore, functional programming can be achieved in an imperative language, if the programmer uses discipline. However, a functional language will force this discipline onto the programmer through its syntax. Functional languages have a syntax tailored to emphasize the what.[77]
A functional program is developed with a set of primitive functions followed by a single driver function.[74] Consider the snippet:
function max(a,b){/* code omitted */}
function min(a,b){/* code omitted */}
function difference_between_largest_and_smallest(a,b,c) {
return max(a,max(b,c)) - min(a, min(b,c));
}
The primitives are max() and min(). The driver function is difference_between_largest_and_smallest(). Executing:
put(difference_between_largest_and_smallest(10,4,7)); will output 6.
Functional languages are used in computer science research to explore new language features.[78] Moreover, their lack of side-effects have made them popular in parallel programming and concurrent programming.[79] However, application developers prefer the object-oriented features of imperative languages.[79]
Lisp[edit]
Lisp (1958) stands for «LISt Processor.»[80] It is tailored to process lists. A full structure of the data is formed by building lists of lists. In memory, a tree data structure is built. Internally, the tree structure lends nicely for recursive functions.[81] The syntax to build a tree is to enclose the space-separated elements within parenthesis. The following is a list of three elements. The first two elements are themselves lists of two elements:
((A B) (HELLO WORLD) 94)
Lisp has functions to extract and reconstruct elements.[82] The function head() returns a list containing the first element in the list. The function tail() returns a list containing everything but the first element. The function cons() returns a list that is the concatenation of other lists. Therefore, the following expression will return the list x:
cons(head(x), tail(x))
One drawback of Lisp is when many functions are nested, the parentheses may look confusing.[77] Modern Lisp environments help ensure parenthesis match. As an aside, Lisp does support the imperative language operations of the assignment statement and goto loops.[83] Also, Lisp is not concerned with the datatype of the elements at compile time.[84] Instead, it assigns (and may reassign) the datatypes at runtime. Assigning the datatype at runtime is called dynamic binding.[85] Whereas dynamic binding increases the language’s flexibility, programming errors may linger until late in the software development process.[85]
Writing large, reliable, and readable Lisp programs requires forethought. If properly planned, the program may be much shorter than an equivalent imperative language program.[77] Lisp is widely used in artificial intelligence. However, its usage has been accepted only because it has imperative language operations, making unintended side-effects possible.[79]
ML[edit]
ML (1973)[86] stands for «Meta Language.» ML checks to make sure only data of the same type are compared with one another.[87] For example, this function has one input parameter (an integer) and returns an integer:
fun times_10(n : int) : int = 10 * n;
ML is not parenthesis-eccentric like Lisp. The following is an application of times_10():
times_10 2
It returns «20 : int». (Both the results and the datatype are returned.)
Like Lisp, ML is tailored to process lists. Unlike Lisp, each element is the same datatype.[88] Moreover, ML assigns the datatype of an element at compile-time. Assigning the datatype at compile-time is called static binding. Static binding increases reliability because the compiler checks the context of variables before they are used.[89]
Prolog[edit]
Prolog (1972) stands for «PROgramming in LOGic.» It is a logic programming language, based on formal logic. The language was developed by Alain Colmerauer and Philippe Roussel in Marseille, France. It is an implementation of Selective Linear Definite clause resolution, pioneered by Robert Kowalski and others at the University of Edinburgh.[90]
The building blocks of a Prolog program are facts and rules. Here is a simple example:
cat(tom). % tom is a cat mouse(jerry). % jerry is a mouse animal(X) :- cat(X). % each cat is an animal animal(X) :- mouse(X). % each mouse is an animal big(X) :- cat(X). % each cat is big small(X) :- mouse(X). % each mouse is small eat(X,Y) :- mouse(X), cheese(Y). % each mouse eats each cheese eat(X,Y) :- big(X), small(Y). % each big animal eats each small animal
After all the facts and rules are entered, then a question can be asked:
- Will Tom eat Jerry?
The following example shows how Prolog will convert a letter grade to its numeric value:
numeric_grade('A', 4). numeric_grade('B', 3). numeric_grade('C', 2). numeric_grade('D', 1). numeric_grade('F', 0). numeric_grade(X, -1) :- not X = 'A', not X = 'B', not X = 'C', not X = 'D', not X = 'F'. grade('The Student', 'A').
?- grade('The Student', X), numeric_grade(X, Y). X = 'A', Y = 4
Here is a comprehensive example:[91]
1) All dragons billow fire, or equivalently, a thing billows fire if the thing is a dragon:
billows_fire(X) :- is_a_dragon(X).
2) A creature billows fire if one of its parents billows fire:
billows_fire(X) :- is_a_creature(X), is_a_parent_of(Y,X), billows_fire(Y).
3) A thing X is a parent of a thing Y if X is the mother of Y or X is the father of Y:
is_a_parent_of(X, Y):- is_the_mother_of(X, Y). is_a_parent_of(X, Y):- is_the_father_of(X, Y).
4) A thing is a creature if the thing is a dragon:
is_a_creature(X) :- is_a_dragon(X).
5) Norberta is a dragon, and Puff is a creature. Norberta is the mother of Puff.
is_a_dragon(norberta). is_a_creature(puff). is_the_mother_of(norberta, puff).
Notice that rule (2) is a recursive (inductive) definition. It can be understood purely declaratively, without any need to understand how it is executed.
Rule (3) shows how functions are represented by using relations. Here, the mother and father functions ensure that every individual has only one mother and only one father.
Prolog is an untyped language. Nonetheless, inheritance can be represented by using predicates. Rule (4) asserts that dragon is a subclass of creature.
Questions are answered using backward reasoning. Given the question:
Prolog generates two answers :
Practical applications for Prolog are knowledge representation and problem solving in artificial intelligence.
Object-oriented programming[edit]
Object-oriented programming is a programming method to execute operations (functions) on objects.[92] The basic idea is to group the characteristics of a phenomenon into an object container and give the container a name. The operations on the phenomenon are also grouped into the container.[92] Object-oriented programming developed by combining the need for containers and the need for safe functional programming.[93] This programming method need not be confined to an object-oriented language.[94] In an object-oriented language, an object container is called a class. In a non-object-oriented language, a data structure (which is also known as a record) may become an object container. To turn a data structure into an object container, operations need to be written specifically for the structure. The resulting structure is called an abstract datatype.[95] However, inheritance will be missing. Nonetheless, this shortcoming can be overcome.
Here is a C programming language header file for the GRADE abstract datatype in a simple school application:
/* grade.h */ /* ------- */ /* Used to allow multiple source files to include */ /* this header file without duplication errors. */ /* ---------------------------------------------- */ #ifndef GRADE_H #define GRADE_H typedef struct { char letter; } GRADE; /* Constructor */ /* ----------- */ GRADE *grade_new( char letter ); int grade_numeric( char letter ); #endif
The grade_new() function performs the same algorithm as the C++ constructor operation.
Here is a C programming language source file for the GRADE abstract datatype in a simple school application:
/* grade.c */ /* ------- */ #include "grade.h" GRADE *grade_new( char letter ) { GRADE *grade; /* Allocate heap memory */ /* -------------------- */ if ( ! ( grade = calloc( 1, sizeof ( GRADE ) ) ) ) { fprintf(stderr, "ERROR in %s/%s/%d: calloc() returned empty.n", __FILE__, __FUNCTION__, __LINE__ ); exit( 1 ); } grade->letter = letter; return grade; } int grade_numeric( char letter ) { if ( ( letter == 'A' || letter == 'a' ) ) return 4; else if ( ( letter == 'B' || letter == 'b' ) ) return 3; else if ( ( letter == 'C' || letter == 'c' ) ) return 2; else if ( ( letter == 'D' || letter == 'd' ) ) return 1; else if ( ( letter == 'F' || letter == 'f' ) ) return 0; else return -1; }
In the constructor, the function calloc() is used instead of malloc() because each memory cell will be set to zero.
Here is a C programming language header file for the PERSON abstract datatype in a simple school application:
/* person.h */ /* -------- */ #ifndef PERSON_H #define PERSON_H typedef struct { char *name; } PERSON; /* Constructor */ /* ----------- */ PERSON *person_new( char *name ); #endif
Here is a C programming language source file for the PERSON abstract datatype in a simple school application:
/* person.c */ /* -------- */ #include "person.h" PERSON *person_new( char *name ) { PERSON *person; if ( ! ( person = calloc( 1, sizeof ( PERSON ) ) ) ) { fprintf(stderr, "ERROR in %s/%s/%d: calloc() returned empty.n", __FILE__, __FUNCTION__, __LINE__ ); exit( 1 ); } person->name = name; return person; }
Here is a C programming language header file for the STUDENT abstract datatype in a simple school application:
/* student.h */ /* --------- */ #ifndef STUDENT_H #define STUDENT_H #include "person.h" #include "grade.h" typedef struct { /* A STUDENT is a subset of PERSON. */ /* -------------------------------- */ PERSON *person; GRADE *grade; } STUDENT; /* Constructor */ /* ----------- */ STUDENT *student_new( char *name ); #endif
Here is a C programming language source file for the STUDENT abstract datatype in a simple school application:
/* student.c */ /* --------- */ #include "student.h" #include "person.h" STUDENT *student_new( char *name ) { STUDENT *student; if ( ! ( student = calloc( 1, sizeof ( STUDENT ) ) ) ) { fprintf(stderr, "ERROR in %s/%s/%d: calloc() returned empty.n", __FILE__, __FUNCTION__, __LINE__ ); exit( 1 ); } /* Execute the constructor of the PERSON superclass. */ /* ------------------------------------------------- */ student->person = person_new( name ); return student; }
Here is a driver program for demonstration:
/* student_dvr.c */ /* ------------- */ #include <stdio.h> #include "student.h" int main( void ) { STUDENT *student = student_new( "The Student" ); student->grade = grade_new( 'a' ); printf( "%s: Numeric grade = %dn", /* Whereas a subset exists, inheritance does not. */ student->person->name, /* Functional programming is executing functions just-in-time (JIT) */ grade_numeric( student->grade->letter ) ); return 0; }
Here is a makefile to compile everything:
# makefile # -------- all: student_dvr clean: rm student_dvr *.o student_dvr: student_dvr.c grade.o student.o person.o gcc student_dvr.c grade.o student.o person.o -o student_dvr grade.o: grade.c grade.h gcc -c grade.c student.o: student.c student.h gcc -c student.c person.o: person.c person.h gcc -c person.c
The formal strategy to build object-oriented objects is to:[96]
- Identify the objects. Most likely these will be nouns.
- Identify each object’s attributes. What helps to describe the object?
- Identify each object’s actions. Most likely these will be verbs.
- Identify the relationships from object to object. Most likely these will be verbs.
For example:
- A person is a human identified by a name.
- A grade is an achievement identified by a letter.
- A student is a person who earns a grade.
Syntax and semantics[edit]
The syntax of a programming language is a list of production rules which govern its form.[97] A programming language’s form is the correct placement of its declarations, expressions, and statements.[98] Complementing the syntax of a language are its semantics. The semantics describe the meanings attached to various syntactic constructs.[97] A syntactic construct may need a semantic description because a form may have an invalid interpretation.[99] Also, different languages might have the same syntax; however, their behaviors may be different.
The syntax of a language is formally described by listing the production rules. Whereas the syntax of a natural language is extremely complicated, a subset of the English language can have this production rule listing:[100]
- a sentence is made up of a noun-phrase followed by a verb-phrase;
- a noun-phrase is made up of an article followed by an adjective followed by a noun;
- a verb-phrase is made up of a verb followed by a noun-phrase;
- an article is ‘the’;
- an adjective is ‘big’ or
- an adjective is ‘small’;
- a noun is ‘cat’ or
- a noun is ‘mouse’;
- a verb is ‘eats’;
The words in bold-face are known as «non-terminals». The words in ‘single quotes’ are known as «terminals».[101]
From this production rule listing, complete sentences may be formed using a series of replacements.[102] The process is to replace non-terminals with either a valid non-terminal or a valid terminal. The replacement process repeats until only terminals remain. One valid sentence is:
- sentence
- noun-phrase verb-phrase
- article adjective noun verb-phrase
- the adjective noun verb-phrase
- the big noun verb-phrase
- the big cat verb-phrase
- the big cat verb noun-phrase
- the big cat eats noun-phrase
- the big cat eats article adjective noun
- the big cat eats the adjective noun
- the big cat eats the small noun
- the big cat eats the small mouse
However, another combination results in an invalid sentence:
- the small mouse eats the big cat
Therefore, a semantic is necessary to correctly describe the meaning of an eat activity.
One production rule listing method is called the Backus–Naur form (BNF).[103] BNF describes the syntax of a language and itself has a syntax. This recursive definition is an example of a meta-language.[97] The syntax of BNF includes:
::=which translates to is made up of a[n] when a non-terminal is to its right. It translates to is when a terminal is to its right.|which translates to or.<and>which surround non-terminals.
Using BNF, a subset of the English language can have this production rule listing:
<sentence> ::= <noun-phrase><verb-phrase> <noun-phrase> ::= <article><adjective><noun> <verb-phrase> ::= <verb><noun-phrase> <article> ::= the <adjective> ::= big | small <noun> ::= cat | mouse <verb> ::= eats
Using BNF, a signed-integer has the production rule listing:[104]
<signed-integer> ::= <sign><integer> <sign> ::= + | - <integer> ::= <digit> | <digit><integer> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Notice the recursive production rule:
<integer> ::= <digit> | <digit><integer>
This allows for an infinite number of possibilities. Therefore, a semantic is necessary to describe a limitation of the number of digits.
Notice the leading zero possibility in the production rules:
<integer> ::= <digit> | <digit><integer> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Therefore, a semantic is necessary to describe that leading zeros need to be ignored.
Two formal methods are available to describe semantics. They are denotational semantics and axiomatic semantics.[105]
Software engineering and computer programming[edit]

Software engineering is a variety of techniques to produce quality software.[106] Computer programming is the process of writing or editing source code. In a formal environment, a systems analyst will gather information from managers about all the organization’s processes to automate. This professional then prepares a detailed plan for the new or modified system.[107] The plan is analogous to an architect’s blueprint.[107]
Performance objectives[edit]
The systems analyst has the objective to deliver the right information to the right person at the right time.[108] The critical factors to achieve this objective are:[108]
- The quality of the output. Is the output useful for decision-making?
- The accuracy of the output. Does it reflect the true situation?
- The format of the output. Is the output easily understood?
- The speed of the output. Time-sensitive information is important when communicating with the customer in real time.
Cost objectives[edit]
Achieving performance objectives should be balanced with all of the costs, including:[109]
- Development costs.
- Uniqueness costs. A reusable system may be expensive. However, it might be preferred over a limited-use system.
- Hardware costs.
- Operating costs.
Applying a systems development process will mitigate the axiom: the later in the process an error is detected, the more expensive it is to correct.[110]
Waterfall model[edit]
The waterfall model is an implementation of a systems development process.[111] As the waterfall label implies, the basic phases overlap each other:[112]
- The investigation phase is to understand the underlying problem.
- The analysis phase is to understand the possible solutions.
- The design phase is to plan the best solution.
- The implementation phase is to program the best solution.
- The maintenance phase lasts throughout the life of the system. Changes to the system after it’s deployed may be necessary.[113] Faults may exist, including specification faults, design faults, or coding faults. Improvements may be necessary. Adaption may be necessary to react to a changing environment.
Computer programmer[edit]
A computer programmer is a specialist responsible for writing or modifying the source code to implement the detailed plan.[107] A programming team is likely to be needed because most systems are too large to be completed by a single programmer.[114] However, adding programmers to a project may not shorten the completion time. Instead, it may lower the quality of the system.[114] To be effective, program modules need to be defined and distributed to team members.[114] Also, team members must interact with one another in a meaningful and effective way.[114]
Computer programmers may be programming in the small: programming within a single module.[115] Chances are a module will execute modules located in other source code files. Therefore, computer programmers may be programming in the large: programming modules so they will effectively couple with each other.[115] Programming-in-the-large includes contributing to the application programming interface (API).
Program modules[edit]
Modular programming is a technique to refine imperative language programs. Refined programs may reduce the software size, separate responsibilities, and thereby mitigate software aging. A program module is a sequence of statements that are bounded within a block and together identified by a name.[116] Modules have a function, context, and logic:[117]
- The function of a module is what it does.
- The context of a module are the elements being performed upon.
- The logic of a module is how it performs the function.
The module’s name should be derived first by its function, then by its context. Its logic should not be part of the name.[117] For example, function compute_square_root( x ) or function compute_square_root_integer( i : integer ) are appropriate module names. However, function compute_square_root_by_division( x ) is not.
The degree of interaction within a module is its level of cohesion.[117] Cohesion is a judgment of the relationship between a module’s name and its function. The degree of interaction between modules is the level of coupling.[118] Coupling is a judgement of the relationship between a module’s context and the elements being performed upon.
Cohesion[edit]
The levels of cohesion from worst to best are:[119]
- Coincidental Cohesion: A module has coincidental cohesion if it performs multiple functions, and the functions are completely unrelated. For example,
function read_sales_record_print_next_line_convert_to_float(). Coincidental cohesion occurs in practice if management enforces silly rules. For example, «Every module will have between 35 and 50 executable statements.»[119] - Logical Cohesion: A module has logical cohesion if it has available a series of functions, but only one of them is executed. For example,
function perform_arithmetic( perform_addition, a, b ). - Temporal Cohesion: A module has temporal cohesion if it performs functions related to time. One example,
function initialize_variables_and_open_files(). Another example,stage_one(),stage_two(), … - Procedural Cohesion: A module has procedural cohesion if it performs multiple loosely related functions. For example,
function read_part_number_update_employee_record(). - Communicational Cohesion: A module has communicational cohesion if it performs multiple closely related functions. For example,
function read_part_number_update_sales_record(). - Informational Cohesion: A module has informational cohesion if it performs multiple functions, but each function has its own entry and exit points. Moreover, the functions share the same data structure. Object-oriented classes work at this level.
- Functional Cohesion: a module has functional cohesion if it achieves a single goal working only on local variables. Moreover, it may be reusable in other contexts.
Coupling[edit]
The levels of coupling from worst to best are:[118]
- Content Coupling: A module has content coupling if it modifies a local variable of another function. COBOL used to do this with the alter verb.
- Common Coupling: A module has common coupling if it modifies a global variable.
- Control Coupling: A module has control coupling if another module can modify its control flow. For example,
perform_arithmetic( perform_addition, a, b ). Instead, control should be on the makeup of the returned object. - Stamp Coupling: A module has stamp coupling if an element of a data structure passed as a parameter is modified. Object-oriented classes work at this level.
- Data Coupling: A module has data coupling if all of its input parameters are needed and none of them are modified. Moreover, the result of the function is returned as a single object.
Data flow analysis[edit]

Data flow analysis is a design method used to achieve modules of functional cohesion and data coupling.[120] The input to the method is a data-flow diagram. A data-flow diagram is a set of ovals representing modules. Each module’s name is displayed inside its oval. Modules may be at the executable level or the function level.
The diagram also has arrows connecting modules to each other. Arrows pointing into modules represent a set of inputs. Each module should have only one arrow pointing out from it to represent its single output object. (Optionally, an additional exception arrow points out.) A daisy chain of ovals will convey an entire algorithm. The input modules should start the diagram. The input modules should connect to the transform modules. The transform modules should connect to the output modules.[121]
Functional categories[edit]

Computer programs may be categorized along functional lines. The main functional categories are application software and system software. System software includes the operating system, which couples computer hardware with application software.[122] The purpose of the operating system is to provide an environment where application software executes in a convenient and efficient manner.[122] Both application software and system software execute utility programs. At the hardware level, a microcode program controls the circuits throughout the central processing unit.
Application software[edit]
Application software is the key to unlocking the potential of the computer system.[123] Enterprise application software bundles accounting, personnel, customer, and vendor applications. Examples include enterprise resource planning, customer relationship management, and supply chain management software.
Enterprise applications may be developed in-house as a one-of-a-kind proprietary software.[124] Alternatively, they may be purchased as off-the-shelf software. Purchased software may be modified to provide custom software. If the application is customized, then either the company’s resources are used or the resources are outsourced. Outsourced software development may be from the original software vendor or a third-party developer.[125]
The potential advantages of in-house software are features and reports may be developed exactly to specification.[126] Management may also be involved in the development process and offer a level of control.[127] Management may decide to counteract a competitor’s new initiative or implement a customer or vendor requirement.[128] A merger or acquisition may necessitate enterprise software changes. The potential disadvantages of in-house software are time and resource costs may be extensive.[124] Furthermore, risks concerning features and performance may be looming.
The potential advantages of off-the-shelf software are upfront costs are identifiable, the basic needs should be fulfilled, and its performance and reliability have a track record.[124] The potential disadvantages of off-the-shelf software are it may have unnecessary features that confuse end users, it may lack features the enterprise needs, and the data flow may not match the enterprise’s work processes.[124]
One approach to economically obtaining a customized enterprise application is through an application service provider.[129] Specialty companies provide hardware, custom software, and end-user support. They may speed the development of new applications because they possess skilled information system staff. The biggest advantage is it frees in-house resources from staffing and managing complex computer projects.[129] Many application service providers target small, fast-growing companies with limited information system resources.[129] On the other hand, larger companies with major systems will likely have their technical infrastructure in place. One risk is having to trust an external organization with sensitive information. Another risk is having to trust the provider’s infrastructure reliability.[129]
Operating system[edit]

Scheduling, Preemption, Context Switching
An operating system is the low-level software that supports a computer’s basic functions, such as scheduling processes and controlling peripherals.[122]
In the 1950s, the programmer, who was also the operator, would write a program and run it. After the program finished executing, the output may have been printed, or it may have been punched onto paper tape or cards for later processing.[28] More often than not the program did not work. The programmer then looked at the console lights and fiddled with the console switches. If less fortunate, a memory printout was made for further study. In the 1960s, programmers reduced the amount of wasted time by automating the operator’s job. A program called an operating system was kept in the computer at all times.[130]
The term operating system may refer to two levels of software.[131] The operating system may refer to the kernel program that manages the processes, memory, and devices. More broadly, the operating system may refer to the entire package of the central software. The package includes a kernel program, command-line interpreter, graphical user interface, utility programs, and editor.[131]
Kernel Program[edit]
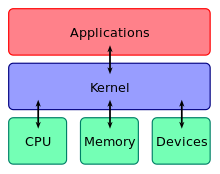
The kernel’s main purpose is to manage the limited resources of a computer:
- The kernel program should perform process scheduling.[132] The kernel creates a process control block when a program is selected for execution. However, an executing program gets exclusive access to the central processing unit only for a time slice. To provide each user with the appearance of continuous access, the kernel quickly preempts each process control block to execute another one. The goal for system developers is to minimize dispatch latency.
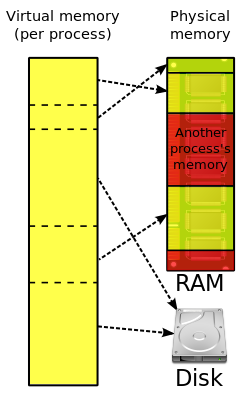
- The kernel program should perform memory management.
-
- When the kernel initially loads an executable into memory, it divides the address space logically into regions.[133] The kernel maintains a master-region table and many per-process-region (pregion) tables—one for each running process.[133] These tables constitute the virtual address space. The master-region table is used to determine where its contents are located in physical memory. The pregion tables allow each process to have its own program (text) pregion, data pregion, and stack pregion.
- The program pregion stores machine instructions. Since machine instructions do not change, the program pregion may be shared by many processes of the same executable.[133]
- To save time and memory, the kernel may load only blocks of execution instructions from the disk drive, not the entire execution file completely.[132]
- The kernel is responsible for translating virtual addresses into physical addresses. The kernel may request data from the memory controller and, instead, receive a page fault.[134] If so, the kernel accesses the memory management unit to populate the physical data region and translate the address.[135]
- The kernel allocates memory from the heap upon request by a process.[64] When the process is finished with the memory, the process may request for it to be freed. If the process exits without requesting all allocated memory to be freed, then the kernel performs garbage collection to free the memory.
- The kernel also ensures that a process only accesses its own memory, and not that of the kernel or other processes.[132]
- The kernel program should perform file system management.[132] The kernel has instructions to create, retrieve, update, and delete files.
- The kernel program should perform device management.[132] The kernel provides programs to standardize and simplify the interface to the mouse, keyboard, disk drives, printers, and other devices. Moreover, the kernel should arbitrate access to a device if two processes request it at the same time.
- The kernel program should perform network management.[136] The kernel transmits and receives packets on behalf of processes. One key service is to find an efficient route to the target system.
- The kernel program should provide system level functions for programmers to use.[137]
- Programmers access files through a relatively simple interface that in turn executes a relatively complicated low-level I/O interface. The low-level interface includes file creation, file descriptors, file seeking, physical reading, and physical writing.
- Programmers create processes through a relatively simple interface that in turn executes a relatively complicated low-level interface.
- Programmers perform date/time arithmetic through a relatively simple interface that in turn executes a relatively complicated low-level time interface.[138]
- The kernel program should provide a communication channel between executing processes.[139] For a large software system, it may be desirable to engineer the system into smaller processes. Processes may communicate with one another by sending and receiving signals.
Originally, operating systems were programmed in assembly; however, modern operating systems are typically written in higher-level languages like C, Objective-C, and Swift.[g]
Utility program[edit]
A utility program is designed to aid system administration and software execution. Operating systems execute hardware utility programs to check the status of disk drives, memory, speakers, and printers.[140] A utility program may optimize the placement of a file on a crowded disk. System utility programs monitor hardware and network performance. When a metric is outside an acceptable range, a trigger alert is generated.[141]
Utility programs include compression programs so data files are stored on less disk space.[140] Compressed programs also save time when data files are transmitted over the network.[140] Utility programs can sort and merge data sets.[141] Utility programs detect computer viruses.[141]
Microcode program[edit]
![]()
![]()
![]()
![]()
![]()
A microcode program is the bottom-level interpreter that controls the data path of software-driven computers.[142]
(Advances in hardware have migrated these operations to hardware execution circuits.)[142] Microcode instructions allow the programmer to more easily implement the digital logic level[143]—the computer’s real hardware. The digital logic level is the boundary between computer science and computer engineering.[144]
A logic gate is a tiny transistor that can return one of two signals: on or off.[145]
- Having one transistor forms the NOT gate.
- Connecting two transistors in series forms the NAND gate.
- Connecting two transistors in parallel forms the NOR gate.
- Connecting a NOT gate to a NAND gate forms the AND gate.
- Connecting a NOT gate to a NOR gate forms the OR gate.
These five gates form the building blocks of binary algebra—the digital logic functions of the computer.
Microcode instructions are mnemonics programmers may use to execute digital logic functions instead of forming them in binary algebra. They are stored in a central processing unit’s (CPU) control store.[146]
These hardware-level instructions move data throughout the data path.
The micro-instruction cycle begins when the microsequencer uses its microprogram counter to fetch the next machine instruction from random-access memory.[147] The next step is to decode the machine instruction by selecting the proper output line to the hardware module.[148]
The final step is to execute the instruction using the hardware module’s set of gates.
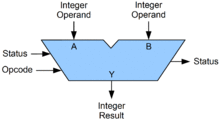
Instructions to perform arithmetic are passed through an arithmetic logic unit (ALU).[149] The ALU has circuits to perform elementary operations to add, shift, and compare integers. By combining and looping the elementary operations through the ALU, the CPU performs its complex arithmetic.
Microcode instructions move data between the CPU and the memory controller. Memory controller microcode instructions manipulate two registers. The memory address register is used to access each memory cell’s address. The memory data register is used to set and read each cell’s contents.[150]
Microcode instructions move data between the CPU and the many computer buses. The disk controller bus writes to and reads from hard disk drives. Data is also moved between the CPU and other functional units via the peripheral component interconnect express bus.[151]
Notes[edit]
- ^ A compiled program has each machine instruction ready for the CPU.
- ^ For more information, visit X86 assembly language#Instruction types.
- ^ introduced in 1999
- ^ Operators like
x++will usually compile to a single instruction. - ^ This function could be written more concisely as
int increment_counter(){ static int counter; return ++counter;}. 1) Static variables are automatically initialized to zero. 2)++counteris a prefix increment operator. - ^ Note that this is despite the metaphor of a stack, which normally grows from bottom to top.
- ^ The UNIX operating system was written in C, macOS was written in Objective-C, and Swift replaced Objective-C.
References[edit]
- ^ «ISO/IEC 2382:2015». ISO. 2020-09-03. Archived from the original on 2016-06-17. Retrieved 2022-05-26.
[Software includes] all or part of the programs, procedures, rules, and associated documentation of an information processing system.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 7. ISBN 0-201-71012-9.
- ^ Silberschatz, Abraham (1994). Operating System Concepts, Fourth Edition. Addison-Wesley. p. 98. ISBN 978-0-201-50480-4.
- ^ Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 32. ISBN 978-0-13-854662-5.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 30. ISBN 0-201-71012-9.
Their intention was to produce a language that was very simple for students to learn[.]
- ^ a b c Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 31. ISBN 0-201-71012-9.
- ^ a b c d e f Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 30. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 30. ISBN 0-201-71012-9.
The idea was that students could be merely casual users or go on from Basic to more sophisticated and powerful languages[.]
- ^ a b McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 16. ISBN 978-0-8027-1348-3.
- ^ Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 14. ISBN 978-0-13-854662-5.
- ^ Bromley, Allan G. (1998). «Charles Babbage’s Analytical Engine, 1838» (PDF). IEEE Annals of the History of Computing. 20 (4): 29–45. doi:10.1109/85.728228. S2CID 2285332. Archived (PDF) from the original on 2016-03-04. Retrieved 2015-10-30.
- ^ a b Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 15. ISBN 978-0-13-854662-5.
- ^ J. Fuegi; J. Francis (October–December 2003), «Lovelace & Babbage and the creation of the 1843 ‘notes’«, Annals of the History of Computing, 25 (4): 16, 19, 25, doi:10.1109/MAHC.2003.1253887
- ^ Rojas, Raúl (2023-03-24). «The First Computer Program». arXiv:2303.13740v1 [cs.GL].
- ^ Rosen, Kenneth H. (1991). Discrete Mathematics and Its Applications. McGraw-Hill, Inc. p. 654. ISBN 978-0-07-053744-6.
Turing machines can model all the computations that can be performed on a computing machine.
- ^ Linz, Peter (1990). An Introduction to Formal Languages and Automata. D. C. Heath and Company. p. 234. ISBN 978-0-669-17342-0.
- ^ Linz, Peter (1990). An Introduction to Formal Languages and Automata. D. C. Heath and Company. p. 243. ISBN 978-0-669-17342-0.
[A]ll the common mathematical functions, no matter how complicated, are Turing-computable.
- ^ a b c McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 102. ISBN 978-0-8027-1348-3.
- ^ McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 94. ISBN 978-0-8027-1348-3.
- ^ McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 107. ISBN 978-0-8027-1348-3.
- ^ McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 120. ISBN 978-0-8027-1348-3.
- ^ a b McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 118. ISBN 978-0-8027-1348-3.
- ^ McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 119. ISBN 978-0-8027-1348-3.
- ^ McCartney, Scott (1999). ENIAC – The Triumphs and Tragedies of the World’s First Computer. Walker and Company. p. 123. ISBN 978-0-8027-1348-3.
- ^ a b Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 21. ISBN 978-0-13-854662-5.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 27. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 29. ISBN 0-201-71012-9.
- ^ a b c Silberschatz, Abraham (1994). Operating System Concepts, Fourth Edition. Addison-Wesley. p. 6. ISBN 978-0-201-50480-4.
- ^ a b c d e f g h i «Bill Pentz — A bit of Background: the Post-War March to VLSI». Digibarn Computer Museum. August 2008. Archived from the original on March 21, 2022. Retrieved January 31, 2022.
- ^ a b To the Digital Age: Research Labs, Start-up Companies, and the Rise of MOS. Johns Hopkins University Press. 2002. ISBN 9780801886393. Archived from the original on February 2, 2023. Retrieved February 3, 2022.
- ^ Chalamala, Babu (2017). «Manufacturing of Silicon Materials for Microelectronics and Solar PV». Sandia National Laboratories. Archived from the original on March 23, 2023. Retrieved February 8, 2022.
- ^ «Fabricating ICs Making a base wafer». Britannica. Archived from the original on February 8, 2022. Retrieved February 8, 2022.
- ^ «Introduction to NMOS and PMOS Transistors». Anysilicon. 4 November 2021. Archived from the original on 6 February 2022. Retrieved February 5, 2022.
- ^ «microprocessor definition». Britannica. Archived from the original on April 1, 2022. Retrieved April 1, 2022.
- ^ «Chip Hall of Fame: Intel 4004 Microprocessor». Institute of Electrical and Electronics Engineers. July 2, 2018. Archived from the original on February 7, 2022. Retrieved January 31, 2022.
- ^ «360 Revolution» (PDF). Father, Son & Co. 1990. Archived (PDF) from the original on 2022-10-10. Retrieved February 5, 2022.
- ^ a b «Inside the world’s long-lost first microcomputer». c/net. January 8, 2010. Archived from the original on February 1, 2022. Retrieved January 31, 2022.
- ^ «Bill Gates, Microsoft and the IBM Personal Computer». InfoWorld. August 23, 1982. Archived from the original on 18 February 2023. Retrieved 1 February 2022.
- ^ a b Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 10. ISBN 978-0-321-56384-2.
- ^ a b c Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 11. ISBN 978-0-321-56384-2.
- ^ a b Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 159. ISBN 0-619-06489-7.
- ^ a b Linz, Peter (1990). An Introduction to Formal Languages and Automata. D. C. Heath and Company. p. 2. ISBN 978-0-669-17342-0.
- ^ Weiss, Mark Allen (1994). Data Structures and Algorithm Analysis in C++. Benjamin/Cummings Publishing Company, Inc. p. 29. ISBN 0-8053-5443-3.
- ^ Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 17. ISBN 978-0-13-854662-5.
- ^ a b c d e f Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 160. ISBN 0-619-06489-7.
- ^ a b c Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 399. ISBN 978-0-13-854662-5.
- ^ Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 400. ISBN 978-0-13-854662-5.
- ^ Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 398. ISBN 978-0-13-854662-5.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 26. ISBN 0-201-71012-9.
- ^ a b c d Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 37. ISBN 0-201-71012-9.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 160. ISBN 0-619-06489-7.
With third-generation and higher-level programming languages, each statement in the language translates into several instructions in machine language.
- ^ Wilson, Leslie B. (1993). Comparative Programming Languages, Second Edition. Addison-Wesley. p. 75. ISBN 978-0-201-56885-1.
- ^ Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 40. ISBN 978-0-321-56384-2.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 16. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 24. ISBN 0-201-71012-9.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 25. ISBN 0-201-71012-9.
- ^ a b c d Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 19. ISBN 0-201-71012-9.
- ^ a b c d «Memory Layout of C Programs». 12 September 2011. Archived from the original on 6 November 2021. Retrieved 6 November 2021.
- ^ a b Kernighan, Brian W.; Ritchie, Dennis M. (1988). The C Programming Language Second Edition. Prentice Hall. p. 31. ISBN 0-13-110362-8.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 128. ISBN 0-201-71012-9.
- ^ a b c Kerrisk, Michael (2010). The Linux Programming Interface. No Starch Press. p. 121. ISBN 978-1-59327-220-3.
- ^ Kerrisk, Michael (2010). The Linux Programming Interface. No Starch Press. p. 122. ISBN 978-1-59327-220-3.
- ^ Kernighan, Brian W.; Ritchie, Dennis M. (1988). The C Programming Language Second Edition. Prentice Hall. p. 185. ISBN 0-13-110362-8.
- ^ a b Kernighan, Brian W.; Ritchie, Dennis M. (1988). The C Programming Language Second Edition. Prentice Hall. p. 187. ISBN 0-13-110362-8.
- ^ a b c Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 38. ISBN 0-201-71012-9.
- ^ Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 65. ISBN 978-0-321-56384-2.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 193. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 39. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 35. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 192. ISBN 0-201-71012-9.
- ^ Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 22. ISBN 978-0-321-56384-2.
- ^ Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 21. ISBN 978-0-321-56384-2.
- ^ Stroustrup, Bjarne (2013). The C++ Programming Language, Fourth Edition. Addison-Wesley. p. 49. ISBN 978-0-321-56384-2.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 218. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 217. ISBN 0-201-71012-9.
- ^ Weiss, Mark Allen (1994). Data Structures and Algorithm Analysis in C++. Benjamin/Cummings Publishing Company, Inc. p. 103. ISBN 0-8053-5443-3.
When there is a function call, all the important information needs to be saved, such as register values (corresponding to variable names) and the return address (which can be obtained from the program counter)[.] … When the function wants to return, it … restores all the registers. It then makes the return jump. Clearly, all of this work can be done using a stack, and that is exactly what happens in virtually every programming language that implements recursion.
- ^ a b c Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 230. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 240. ISBN 0-201-71012-9.
- ^ a b c Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 241. ISBN 0-201-71012-9.
- ^ Jones, Robin; Maynard, Clive; Stewart, Ian (December 6, 2012). The Art of Lisp Programming. Springer Science & Business Media. p. 2. ISBN 9781447117193.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 220. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 221. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 229. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 227. ISBN 0-201-71012-9.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 222. ISBN 0-201-71012-9.
- ^ Gordon, Michael J. C. (1996). «From LCF to HOL: a short history». Archived from the original on 2016-09-05. Retrieved 2021-10-30.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 233. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 235. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 55. ISBN 0-201-71012-9.
- ^ Colmerauer, A.; Roussel, P. (1992). «The birth of Prolog» (PDF). ACM Sigplan Notices. Association for Computing Machinery. 28 (3): 5. doi:10.1145/155360.155362.
- ^ Kowalski, R., Dávila, J., Sartor, G. and Calejo, M., 2023. Logical English for law and education. In Prolog: The Next 50 Years (pp. 287-299). Cham: Springer Nature Switzerland.
- ^ a b Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 35. ISBN 0-201-71012-9.
Simula was based on Algol 60 with one very important addition — the class concept. … The basic idea was that the data (or data structure) and the operations performed on it belong together[.]
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 39. ISBN 0-201-71012-9.
Originally, a large number of experimental languages were designed, many of which combined object-oriented and functional programming.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 284. ISBN 0-256-08515-3.
While it is true that OOD [(object oriented design)] as such is not supported by the majority of popular languages, a large subset of OOD can be used.
- ^ Weiss, Mark Allen (1994). Data Structures and Algorithm Analysis in C++. Benjamin/Cummings Publishing Company, Inc. p. 57. ISBN 0-8053-5443-3.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 285. ISBN 0-256-08515-3.
- ^ a b c Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 290. ISBN 0-201-71012-9.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 78. ISBN 0-201-71012-9.
The main components of an imperative language are declarations, expressions, and statements.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 294. ISBN 0-201-71012-9.
- ^ Rosen, Kenneth H. (1991). Discrete Mathematics and Its Applications. McGraw-Hill, Inc. p. 615. ISBN 978-0-07-053744-6.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 291. ISBN 0-201-71012-9.
- ^ Rosen, Kenneth H. (1991). Discrete Mathematics and Its Applications. McGraw-Hill, Inc. p. 616. ISBN 978-0-07-053744-6.
- ^ Rosen, Kenneth H. (1991). Discrete Mathematics and Its Applications. McGraw-Hill, Inc. p. 623. ISBN 978-0-07-053744-6.
- ^ Rosen, Kenneth H. (1991). Discrete Mathematics and Its Applications. McGraw-Hill, Inc. p. 624. ISBN 978-0-07-053744-6.
- ^ Wilson, Leslie B. (2001). Comparative Programming Languages, Third Edition. Addison-Wesley. p. 297. ISBN 0-201-71012-9.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. Preface. ISBN 0-256-08515-3.
- ^ a b c Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 507. ISBN 0-619-06489-7.
- ^ a b Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 513. ISBN 0-619-06489-7.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 514. ISBN 0-619-06489-7.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 516. ISBN 0-619-06489-7.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 8. ISBN 0-256-08515-3.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 517. ISBN 0-619-06489-7.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 345. ISBN 0-256-08515-3.
- ^ a b c d Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 319. ISBN 0-256-08515-3.
- ^ a b Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 331. ISBN 0-256-08515-3.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 216. ISBN 0-256-08515-3.
- ^ a b c Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 219. ISBN 0-256-08515-3.
- ^ a b Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 226. ISBN 0-256-08515-3.
- ^ a b Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 220. ISBN 0-256-08515-3.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 258. ISBN 0-256-08515-3.
- ^ Schach, Stephen R. (1990). Software Engineering. Aksen Associates Incorporated Publishers. p. 259. ISBN 0-256-08515-3.
- ^ a b c Silberschatz, Abraham (1994). Operating System Concepts, Fourth Edition. Addison-Wesley. p. 1. ISBN 978-0-201-50480-4.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 147. ISBN 0-619-06489-7.
The key to unlocking the potential of any computer system is application software.
- ^ a b c d Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 147. ISBN 0-619-06489-7.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 147. ISBN 0-619-06489-7.
[A] third-party software firm, often called a value-added software vendor, may develop or modify a software program to meet the needs of a particular industry or company.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 148. ISBN 0-619-06489-7.
Heading: Proprietary Software; Subheading: Advantages; Quote: You can get exactly what you need in terms of features, reports, and so on.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 148. ISBN 0-619-06489-7.
Heading: Proprietary Software; Subheading: Advantages; Quote: Being involved in the development offers a further level of control over the results.
- ^ Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 147. ISBN 0-619-06489-7.
Heading: Proprietary Software; Subheading: Advantages; Quote: There is more flexibility in making modifications that may be required to counteract a new initiative by one of your competitors or to meet new supplier and/or customer requirements.
- ^ a b c d Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 149. ISBN 0-619-06489-7.
- ^ Tanenbaum, Andrew S. (1990). Structured Computer Organization, Third Edition. Prentice Hall. p. 11. ISBN 978-0-13-854662-5.
- ^ a b Kerrisk, Michael (2010). The Linux Programming Interface. No Starch Press. p. 21. ISBN 978-1-59327-220-3.
- ^ a b c d e Kerrisk, Michael (2010). The Linux Programming Interface. No Starch Press. p. 22. ISBN 978-1-59327-220-3.
- ^ a b c Bach, Maurice J. (1986). The Design of the UNIX Operating System. Prentice-Hall, Inc. p. 152. ISBN 0-13-201799-7.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 443. ISBN 978-0-13-291652-3.
- ^ Lacamera, Daniele (2018). Embedded Systems Architecture. Packt. p. 8. ISBN 978-1-78883-250-2.
- ^ Kerrisk, Michael (2010). The Linux Programming Interface. No Starch Press. p. 23. ISBN 978-1-59327-220-3.
- ^ Kernighan, Brian W. (1984). The Unix Programming Environment. Prentice Hall. p. 201. ISBN 0-13-937699-2.
- ^ Kerrisk, Michael (2010). The Linux Programming Interface. No Starch Press. p. 187. ISBN 978-1-59327-220-3.
- ^ Haviland, Keith (1987). Unix System Programming. Addison-Wesley Publishing Company. p. 121. ISBN 0-201-12919-1.
- ^ a b c Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 145. ISBN 0-619-06489-7.
- ^ a b c Stair, Ralph M. (2003). Principles of Information Systems, Sixth Edition. Thomson. p. 146. ISBN 0-619-06489-7.
- ^ a b Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 6. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 243. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 147. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 148. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 253. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 255. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 161. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 166. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 249. ISBN 978-0-13-291652-3.
- ^ Tanenbaum, Andrew S. (2013). Structured Computer Organization, Sixth Edition. Pearson. p. 111. ISBN 978-0-13-291652-3.

Введение
Я делала много вещей с компьютерами, но в моих знаниях всегда был пробел: что конкретно происходит при запуске программы на компьютере? Я думала об этом пробеле — у меня было много низкоуровневых знаний, но не было цельной картины. Программы действительно выполняются прямо в центральном процессоре (central processing unit, CPU)? Я использовала системные вызовы (syscalls), но как они работают? Чем они являются на самом деле? Как несколько программ выполняются одновременно?
Наконец, я сломалась и начала это выяснять. Мне пришлось перелопатить тонны ресурсов разного качества и иногда противоречащих друг другу. Несколько недель исследований и почти 40 страниц заметок спустя я решила, что гораздо лучше понимаю, как работают компьютеры от запуска до выполнения программы. Я бы убила за статью, в которой объясняется все, что я узнала, поэтому я решила написать эту статью.
И, как говорится, ты по-настоящему знаешь что-то, только если можешь объяснить это другому.
Более удобный формат статьи.
Содержание:
- 1. Основы
- Архитектура компьютера
- Процессоры наивны
- Два кольца, чтобы править всеми
- Системный вызов
- Интерфейсы оболочки: абстрагирование прерываний
- Жажда скорости / CISC
- 2. Нарезка времени
- Программные прерывания
- Расчет временного интервала
- Заметка 1: выгружаемость ядра
- Заметка 2: урок истории
- 3. Запуск программы
- Стандартное выполнение системного вызова
- Шаг 0. Определение
- Шаг 1. Настройка
- Шаг 2. Binfmt
- Скрипты
- Разные интерпретаторы
- В завершение
- 4. Elf
- Структура файла
- ELF Header
- Таблица заголовков программы
- Таблица заголовков разделов
- Данные
- Краткое объяснение связывания
- Динамическая компоновка в дикой природе
- Выполнение
- Структура файла
- 5. Преобразователь
- Память — это фикция
- Безопасность подкачки
- Иерархическая подкачка и другие оптимизации
- Обмен и подкачка по требованию
- 6. Вилки и коровы
- Мууу!
- В начале
- Возвращаемся к ядру
- Инициализация Linux
- Отображение памяти при клонировании
- В заключение
- Эпилог
1. Основы
Одной вещью, которая удивляла меня снова и снова, является то, насколько компьютеры просты. Эта простота очень красива, но порой превращается в кошмар.
Архитектура компьютера
ЦП — это место, в котором происходят все вычисления. Он начинает «пыхтеть» как только вы включаете компьютер, выполняя инструкцию за инструкцией.
Первым массовым ЦП был Intel 4004, спроектированный в конце 60-х итальянским физиком и инженером Федерико Фарджином. Это была 4-битная архитектура, а не 64-битная, которая используется сегодня. 4-битная архитектура была гораздо менее сложной, чем современные процессоры, но многое осталось почти неизменным.
«Инструкции», выполняемые ЦП — всего лишь двоичные (binary) данные: байт или два для представления запускаемой инструкции (код операции — opcode), за которыми следуют данные, необходимые для выполнения инструкции. То, что мы называем машинным кодом (machine code) — всего лишь серия этих бинарных инструкций в виде строки. Assemble — это полезный синтаксис, облегчающий чтение и запись сырых (raw) битов людьми. Он всегда компилируется в двоичные данные, понятные ЦП.

Ремарка: инструкции в машинном коде не всегда представлены 1:1, как в приведенном примере. Например,
add eax, 512преобразуется в05 00 02 00 00.Первый байт (
05) — это код операции, представляющий добавление регистра EAX к 32-битному числу. Остальные байты — это 512 (0x200) с порядком байтов little-endian.Defuse Security разработали полезный инструмент для преобразования языка ассемблера в машинный код.
Оперативная память или оперативное запоминающее устройство (Random Access Memory, RAM) — это основное хранилище компьютера, большое многоцелевое пространство, где хранятся все данные, используемые программами, запущенными на компьютере. Это включает код самих программ, а также код ядра (kernel) операционной системы. ЦП всегда читает машинный код прямо из ОП. Код, не загруженный в ОП, не может быть выполнен.
ЦП хранит указатель инструкции (instruction pointer), который указывает на место в ОП, где находится следующая инструкция. После выполнения всех инструкций, ЦП возвращает указатель в начало, и процесс повторяется. Это называется циклом выборки-исполнения (fetch-execute cycle).

После выполнения инструкции указатель передвигается за нее в ОП и таким образом указывает на следующую инструкцию. Указатель инструкции двигается вперед, и машинный код выполняется в порядке его хранения в памяти. Некоторые инструкции могут заставить указатель переместиться (перепрыгнуть — jump) в другое место (выполнить другую инструкцию вместо текущей или выполнить одну из инструкций в зависимости от определенного условия). Это делает возможным повторное и условное выполнение кода.
Указатель инструкции хранится в регистре (registry). Регистры — это маленькие хранилища, которые являются очень производительными для чтения и записи ЦП. Каждая архитектура ЦП имеет фиксированный набор регистров, используемых для всего: от хранения временных значений в процессе вычислений до настройки процессора.
Некоторые регистры доступны из машинного кода напрямую, например, ebx на приведенной выше диаграмме.
Другие регистры предназначены только для внутреннего использования ЦП, но часто могут обновляться или читаться с помощью специальных инструкций. Одним из примеров такого регистра является указатель инструкции, который не может читаться напрямую, но может обновляться, например, для выполнения другой инструкции вместо текущей.
Процессоры наивны
Вернемся к вопросу о том, что происходит при запуске программы на компьютере. Сначала происходит некоторая магия — мы поговорим об этом позже — и мы получаем файл с машинным кодом, который где-то хранится. ОС загружает его в ОП и указывает ЦП переместить указатель на определенную позицию в ОП. Начинается цикл выборки-исполнения, и программа запускается!
Ваш ЦП получает последовательные инструкции браузера из ОП и выполняет их, что приводит к рендерингу этой статьи.

ЦП имеют очень ограниченный кругозор. Они видят только указатель текущей инструкции и немного внутреннего состояния. Процессы — это абстракции ОС, а не нечто, что понимают или отслеживают ЦП.
У меня это вызывает больше вопросов, чем ответов:
- Если ЦП не знает о многозадачности (multiprocessing) и выполняет инструкции последовательно, почему он не застревает в выполняемой программе? Как могут одновременно выполняться несколько программ?
- Если программа выполняется в ЦП, и ЦП имеет прямой доступ к ОП, почему код из других процессов или, прости господи, ядра не имеет доступа к памяти?
- Каков механизм, предотвращающий выполнение любой инструкции любым процессом? И что такое системный вызов?
Вопрос о памяти заслуживает отдельного раздела (см. раздел 5). Если коротко, то большая часть обращений к памяти проходит через слой неправильного направления (misdirection), который переназначает все адресное пространство. Пока мы будем исходить из предположения, что программы имеют прямой доступ ко всей ОП, и компьютеры могут запускать только один процесс за раз. Со временем мы избавимся от обоих этих предположений.
Пришло время прыгнуть в нашу первую кроличью нору – в страну, полную системных вызовов и колец безопасности (security rings).
Ремарка: что такое ядро?
ОС вашего компьютера, такая как macOS, Windows или Linux — это коллекция программного обеспечения, выполняющая всю основную работу. «Основная работа» — это общее понятие, и, в зависимости от ОС, может включать такие вещи, как приложения, шрифты, иконки, которые поставляются с компьютером по умолчанию.
Каждая ОС имеет ядро. Когда вы включаете компьютер, указатель инструкции запускает какую-то программу. Этой программой является ядро. Ядро имеет почти полный доступ к памяти, периферийным устройствам и другим ресурсам и отвечает за запуск ПО, установленного на компьютере (пользовательских программ).
Linux — это всего лишь ядро, которому для полноценной работы требуется множество пользовательских программ, таких как оболочки (shells) и серверы отображения (display servers). Ядро macOS называется XNU, а современное ядро Windows — NT Kernel.
Два кольца, чтобы править всеми
Режим (mode) (иногда именуемый уровнем привилегий (privilege level) или кольцом (ring)), в котором находится процессор, управляет тем, что разрешено делать. В современных архитектурах имеется, как минимум, два варианта: режим ядра/администратора (kernel/supervisor mode) и режим пользователя (user mode). Несмотря на то, что архитектура может поддерживать более двух режимов, как правило, используются только режимы ядра и пользователя.
В режиме ядра разрешено все: ЦП может выполнять любую поддерживаемую инструкцию и обращаться к любой памяти. В режиме пользователя разрешен только определенный набор инструкций, ввод/вывод (input/output, I/O) и доступ к памяти ограничены, многие настройки ЦП заблокированы. Как правило, ядро и драйверы запускаются в режиме ядра, а приложения — в режиме пользователя.
Процессоры запускаются в режиме ядра. Перед выполнением программы ядро инициализирует переключение в пользовательский режим.

Пример того, как режимы процессора проявляются в реальной архитектуре: в x86-64 текущий уровень привилегий (current privilege level, CPL) может читаться из регистра cs (code segment — сегмент кода). В частности, CPL содержится в 2 наименьших битах регистра cs. Эти 2 бита могут хранить 4 возможных кольца x86-64: кольцо 0 — это режим ядра, а кольцо 3 — режим пользователя. Кольца 1 и 2 предназначены для запуска драйверов, но используются только несколькими нишевыми ОС. Если, например, битами CPL являются 11, ЦП запускается в режиме пользователя.
Системный вызов
Программы запускаются в режиме пользователя, потому что им нельзя предоставлять полный доступ к компьютеру. Режим пользователя делает свою работу, предотвращая доступ к большей части компьютера, но программам требуется ввод/вывод, память и возможность взаимодействия с ОС! Для этого ПО, запущенное в пользовательском режиме, обращается за помощью к ядру ОС. ОС затем реализуют собственные меры защиты.
Если вы писали код, взаимодействующий с ОС, то должны быть знакомы с функциями open, read, fork и exit. Под несколькими слоями абстракций эти функции используют системные вызовы для обращения к ОС за помощью. Системный вызов — это специальная процедура, позволяющая программе запускать переход из пространства пользователя в пространство ядра, перепрыгивать из кода программы в код ОС.
Передача управления из пространства пользователя в пространство ядра выполняется с помощью функций процессора, которые называются программными прерываниями (software interrupts):
- При запуске ОС сохраняет «таблицу векторов прерываний» (interrupt vector table, IVT) (в x86-64 она называется «таблицей дескрипторов прерываний» (interrupt descriptor table)) в ОП и регистрирует ее с помощью ЦП. IVT представляет собой таблицу сопоставления номера прерывания (interrupt number) и указателя обработчика кода (handler code pointer).

- Затем пользовательские программы могут использовать такие инструкции, как INT, указывающие процессору найти заданный номер прерывания в IVT, переключиться в режим ядра и переместить указатель инструкции на адрес памяти, указанный в IVT.
После завершения этого кода, ядро указывает ЦП переключиться обратно в режим пользователя и вернуть указатель инструкции в то место, где произошло прерывание. Это делается с помощью таких инструкций, как IRET.
Если вам интересно, то идентификатором прерывания для системных вызовов в Linux является 0x80. Список системных вызовов Linux можно найти здесь.
Интерфейсы оболочки: абстрагирование прерываний
Вот, что мы узнали о системных вызовах:
- программы, запущенные в режиме пользователя, не имеют доступа к вводу/выводу или памяти. Им приходится обращаться к ОС за помощью во взаимодействии с внешним миром;
- программы могут передавать управление ОС с помощью специальных инструкций, содержащих машинный код, таких как INT и IRET;
- программы не могут переключать уровни привилегий напрямую. Программные прерывания являются безопасными, поскольку процессор предварительно настраивается ОС относительно того, к какому коду ОС следует обращаться. Векторная таблица прерываний может настраиваться только в режиме ядра.
Программы должны передавать данные ОС при системном вызове. ОС должна знать не только то, какой системный вызов выполнять, но также располагать данными, необходимыми для его выполнения, такими как название файла (filename). Механизм передачи данных зависит от ОС и архитектуры, но, как правило, это делается посредством помещения данных в определенные регистры или в стек (stack) перед запуском прерывания.
Различия в том, как системные вызовы вызываются на разных устройствах означает, что реализация системных вызовов для каждой программы разработчиками является, по меньшей мере, непрактичной. Это также означало бы невозможность изменения ОС своей обработки прерываний во избежание поломки программ, рассчитанных на использование старых систем. Наконец, мы больше не пишем программы на языке ассемблера – нельзя ожидать от программистов перехода на assembly при каждом чтении файла или выделении памяти.

Поэтому ОС предоставляют слой абстракции поверх этих прерываний. «Переиспользуемые» высокоуровневые функции, оборачивающие необходимые инструкции на языке ассемблера, предоставляются libc в Unix-подобных системах и частью библиотеки под названием ntdll в Windows. Простой вызов этих функций не влечет переключения в режим ядра. Внутри библиотек код assembly передает управление ядру. Этот код гораздо более зависим от платформы, чем библиотечная обертка.
Когда мы вызываем exit(1) из C, запущенного на Unix, эта функция выполняет машинный код для запуска прерывания после помещения кода операции системного вызова и аргументов в правильный регистр/стек/что угодно. Компьютеры такие клевые!
Жажда скорости / CISC
Многие архитектуры CISC, такие как x86-64, содержат инструкции, предназначенные для системных вызовов, созданные из-за преобладания парадигмы системных вызовов.
Intel и AMD не очень хорошо координировали свои действия при работе над x86-64. Поэтому у нас имеется 2 набора оптимизированных инструкций системных вызовов. SYSCALL и SYSENTER являются оптимизированными альтернативами таких инструкций, как INT 0x80. Их инструкции возврата, SYSRET и SYSEXIT, предназначены для быстрого обратного перехода в пространство пользователя и продолжения выполнения кода программы.
Процессоры AMD и Intel имеют немного разную совместимость с этими инструкциями. SYSCALL, как правило, лучше подходит для 64-битных программ, а SYSENTER лучше поддерживается 32-битными программами.
Архитектуры RISC не имеют таких специальных инструкций. AArch64, архитектура RISC, которая применяется в Apple Silicon, использует только одну инструкцию прерывания для системных вызовов и программных прерываний.
Вот что мы узнали в этом разделе:
- процессоры выполняют инструкции в бесконечном цикле выборки-исполнения и не имеют ни малейшего понятия об ОС или программах. Режим процессора, обычно хранящийся в регистре, определяет, какие инструкции могут выполняться. Код ОС выполняется в режиме ядра и переключается на режим пользователя для запуска программ;
- для запуска исполняемого файла ОС переключается в режим пользователя и сообщает процессору входную точку кода в ОП. Поскольку программы имеют низкие привилегии, они вынуждены обращаться за помощью к коду ОС для взаимодействия с внешним миром. Системные вызовы – это стандартизированный способ переключения программ из режима пользователя в режим ядра и в код ОС;
- программы, как правило, используют эти системные вызовы путем вызова функций специальных библиотек. Эти функции являются обертками над машинным кодом для программных прерываний или специфических для архитектуры инструкций системных вызовов, которые передают управление ядру ОС и переключают кольца безопасности. Ядро делает свое дело, переключается обратно в режим пользователя и возвращается к коду программы.
Вернемся к вопросу о том, что если ЦП не отслеживает больше одного процесса и просто выполняет одну инструкцию за другой, почему он не застревает в запущенной программе. Как несколько программ могут работать одновременно?
Все дело в таймерах.
2. Нарезка времени
Предположим, что мы разрабатываем ОС и хотим, чтобы пользователи могли запускать несколько программ одновременно. У нас нет модного многоядерного процессора, наш ЦП может выполнять только одну инструкцию за раз.
К счастью, мы очень умные разработчики ОС. Мы выяснили, что конкурентность (concurrency) может имитироваться путем выполнения процессов по очереди. Если мы циклически перебираем процессы и выполняем по несколько инструкций из каждого, все процессы будут отзывчивыми и ни один из них не загрузит ЦП полностью.
Как вернуть управление из программного кода? После небольшого исследования выясняется, что большинство компьютеров содержат микросхемы (чипы) таймеров (timer chips). Мы можем запрограммировать чип таймера для переключение на обработчик прерываний ОС по прошествии определенного времени.
Программные прерывания
Ранее мы рассмотрели, как программные прерывания используются для передачи управления от пользовательской программы к ОС. Они называются «программными», поскольку произвольно запускаются программой – машинный код, выполняемый процессором в нормальном цикле выборки-исполнения, указывает ему передать управление ядру.

Планировщики (schedulers) ОС используют чипы таймеров, такие как PIT, для запуска программных прерываний в целях многозадачности:
- Перед началом выполнения кода программы, ОС устанавливает чип таймера для запуска прерывания по истечение определенного времени.
- ОС переключается в режим пользователя и переходит к следующей инструкции программы.
- Когда срабатывает таймер, ОС запускает программное прерывание для переключения в режим ядра, и переходит к коду ОС.
- ОС запоминает, где остановилось выполнение программы, загружает другую программу и повторяет процесс.
Это называется «вытесняющей многозадачностью» (preemptive multitasking); прерывание процесса называется «вытеснением» или «выгрузкой» (preemptive). Если вы, например, читаете эту статью в браузере и слушаете музыку на той же машине, ваш компьютер, вероятно, выполняет этот цикл тысячи раз в секунду.
Расчет временного интервала
Временной интервал (timeslice) – это период времени, в течение которого планировщик ОС позволяет процессу выполняться до его вытеснения. Простейшим способом определения временных интервалов является выделение каждому процессу одинакового интервала, например, в пределах 10 мс, и перебор задач по порядку. Это называется «циклическим планированием с фиксированным интервалом времени» (fixed timeslice round-robin scheduling).
Ремарка: забавные факты жаргона.
Временные интервалы часто называются «квантами» (quantums).
Разработчики ядра Linux используют единицу измерения jiffy для подсчета тиков таймера (timer ticks) с фиксированной частотой. Кроме прочего, эта единица используется для измерения длины временного интервала. Частота jiffy обычно составляет 1000 Гц, но может настраиваться при компиляции ядра.
Небольшим улучшением планирования с фиксированными временными интервалами является выбор целевой задержки (target latency) — оптимального наибольшего периода времени, необходимого процессору для ответа. Целевая задержка – это время, необходимое процессору для возобновления выполнения кода после вытеснения с учетом разумного количества процессов.
Временные интервалы вычисляются путем деления целевой задержки на количество задач. Такой подход лучше фиксированных интервалов, поскольку он устраняет ненужное переключение с меньшим количеством процессов. С целевой задержкой в 15 мс и 10 процессами каждый процесс получает 15/10 или 1.5 мс для выполнения. С 3 процессами каждый процесс получает 5 мс, а целевая задержка останется неизменной.
Переключение между процессами является дорогим с точки зрения вычислений, поскольку требует сохранения всего состояния текущей программы и восстановления другого состояния. В определенный момент слишком маленькие временные интервалы могут привести к проблемам с производительностью со слишком быстрым переключением между процессами. Распространенной практикой является установление нижнего порога (minimum granularity — минимальной степени детализации). Это означает, что целевая задержка превышается, если имеется достаточно процессов, чтобы минимальная степень детализации вступила в силу.
На момент написания статьи планировщик Linux использует целевую задержку в 6 мс и минимальную степень детализации в 0,75 мс.

Циклическое планирование с этим базовым расчетом кванта времени близко к тому, что в настоящее время делает большинство компьютеров. Большинство ОС, как правило, имеют более сложные планировщики, которые учитывают приоритеты процессов и сроки (deadlines). Начиная с 2007 г., Linux имеет планировщик под названием «Completely Fair Scheduler» (полностью честный планировщик). CFS делает много очень причудливых вещей из области компьютерных наук, чтобы расставить приоритеты и разделить время ЦП.
При каждом вытеснении процесса ОС должна загрузить сохраненный контекст выполнения новой программы, включая ее среду памяти. Это достигается за счет использования ЦП другой таблицы страниц (page table) — связки (отображения — mapping) между «виртуальными» и физическими адресами. Это также предотвращает доступ одной программы к памяти другой.
Заметка 1: выгружаемость ядра
До сих пор мы говорили только о выгрузке и планировании пользовательских процессов. Код ядра может заставить программы «лагать», если обработка системного вызова или выполнение кода драйвера происходят слишком долго.
Современные ядра, включая Linux, являются выгружаемыми. Это означает, что они программируются так, что код ядра может быть прерван и запланирован по аналогии с пользовательскими процессами.
Это не очень важно, если вы не собираетесь писать ядро или что-то в этом роде, но знания никогда не бывают лишними.
Заметка 2: урок истории
Древние ОС, включая классическую macOS и версии Windows задолго до NT, использовали предшественника вытесняющей многозадачности. Тогда не ОС выгружала программы, а программы «уступали» (yield) ОС. Они запускали программное прерывание, как бы говоря «эй, ты можешь запустить другую программу». Эти явные уступки были единственным для ОС способом восстановления контроля и переключения к следующему процессу.
Это называется «совместной многозадачностью» (cooperative multitasking). Основным недостатком такого подхода является то, что вредоносные или просто плохо спроектированные программы могут легко заморозить (freeze) всю ОС и почти невозможно обеспечить согласованность задач, выполняемых в реальном времени.
3. Запуск программы
Мы рассмотрели, как процессоры выполняют машинный код, загружаемый из исполняемых файлов, что такое безопасность на основе колец и как работают системные вызовы. В этом разделе мы глубоко погрузимся в ядро Linux для того, чтобы выяснить, как программы загружаются и выполняются.
Мы будем рассматривать Linux x86-64. Почему?
- Linux – это полнофункциональная производственная ОС для десктопной, мобильной и серверной сред. У Linux открытый исходный код, что делает возможным его изучение во всех подробностях;
- x86-64 – это архитектура, которая используется в большинстве современных компьютеров.
Тем не менее, большая часть из того, о чем мы будем говорить, распространяется на другие ОС и архитектуры.
Стандартное выполнение системного вызова

Начнем с очень важного системного вызова — execve. Он загружает программу и, если загрузка прошла успешно, заменяет текущий процесс этой программой. Существует несколько других системных вызовов (execlp, execvpe и др.), но все они так или иначе основаны на execve.
Ремарка:
execveat.
execveна самом деле построен на основеexecveat, более общем системной вызове, запускающем программу с некоторыми настройками. Для простоты мы в основном будем говорить оexecve, который является вызовомexecveatс настройками по умолчанию.Любопытно, что означает
ve?vозначает, что одним параметром является вектор (список) аргументов (argv), аeозначает, что другим параметром является вектор переменных среды окружения (envp). Другие системные вызовы имеют другие суффиксы для обозначения различных сигнатур вызова.atвexecveat— это просто «at», определяющее локацию (location) для запускаexecve.
Сигнатура вызова execve выглядит так:
int execve(const char *filename, char *const argv[], char *const envp[]);- аргумент
filenameопределяет путь к запускаемой программе; argv— это завершающийся нулем (null-terminated) (последним элементом является нулевой указатель (null pointer)) список аргументов программы. Аргументargc, который часто передается в основные функции C, на самом деле вычисляется позже системным вызовом для нулевого завершения;- аргумент
envpсодержит другой завершающийся нулем список переменных среды окружения, которые используются в качестве контекста для приложения. Они… условно (по соглашению) являются парамиKEY=VALUE(ключ=значение). Условно. Я обожаю компьютеры.
Забавный факт! Знаете ли вы, что правило, согласно которому первым аргументом должно быть название программы, это всего лишь соглашение? execve не выполняет никаких проверок на этот счет! Первым аргументом будет то, что передается execve в качестве первого элемента в списке argv, даже если этот элемент не имеет ничего общего с названием программы.
Что интересно, execve содержит некоторый код, который предполагает, что argv[0] — это название программы. Мы подробнее поговорим об этом позже.
Шаг 0. Определение
Мы знаем, как работают системные вызовы, но мы не рассматривали примеров реального кода! Посмотрим как определяется execve в исходном коде ядра Linux:
// fs/exec.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/exec.c#L2105-L2111
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}SYSCALL_DEFINE3 — это макрос (macro) для определения кода системного вызова с тремя аргументами.
Мне стало любопытно, почему арность содержится в названии макроса. Я погуглила и выяснила, что это обходной путь (workaround) для решения некоторых проблем безопасности.
Аргумент filename передается в функцию getname(), которая копирует строку из пространства пользователя в пространство ядра и выполняет некоторые действия по отслеживанию использования. Она возвращает структуру (struct) filename, определенную в include/linux/fs.h. Эта структура хранит указатель на оригинальную строку в пользовательском пространстве, а также новый указатель на значение, скопированное в пространство ядра:
// include/linux/fs.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/fs.h#L2294-L2300
struct filename {
const char *name; /* указатель на скопированную строку в пространстве ядра */
const __user char *uptr; /* указатель на оригинальную строку в пространстве пользователя */
int refcnt;
struct audit_names *aname;
const char iname[];
};Затем execve вызывает функцию do_execve(). Это, в свою очередь, приводит к вызову функции do_execve_common() с некоторыми дефолтными настройками. Системный вызов execveat, упоминавшийся ранее, также вызывает do_execve_common(), но передает ей больше пользовательских настроек.
Ниже представлены определения do_execve() и do_execveat():
// fs/exec.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/exec.c#L2028-L2046
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
static int do_execveat(int fd, struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp,
int flags)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(fd, filename, argv, envp, flags);
}В execveat файловый дескриптор (тип идентификатора, указывающего на некоторый ресурс) передается сначала в системный вызов, а затем — в do_execveat_common(). Это определяет директорию, по отношению к которой выполняется программа.
В execve для аргумента файлового дескриптора используется специальное значение AT_FDCWD. Это общая (распределенная — shared) константа ядра Linux, которая указывает функциям интерпретировать названия путей по отношению к текущей рабочей директории. Функции, принимающие файловые дескрипторы, как правило, содержат явные проверки типа if (fd == AT_FDCWD) { /* ... */ }.
Шаг 1. Настройка
Мы добрались до do_execveat_common() — главной функции обработки выполнения программы.
Первой важной задачей do_execveat_common() является установка структуры под названием linux_binprm. Я не буду приводить полное определение этой структуры, но вот несколько важных замечаний:
- такие структуры данных, как
mm_structиvm_area_structопределены для подготовки управления виртуальной памятью для новой программы; argcиenvcвычисляются и сохраняются для передачи в программу;filenameиinterpхранят название файла программы и ее интерпретатора, соответственно. Сначала они равны друг другу, но в некоторых случаях могут меняться: одним из случаев, когда исполняемый двоичный файл отличается от названия программы, является запуск интерпретируемых программ, таких как скрипты Python, с шебангом (shebang). В данном случаеfilenameбудет содержать название файла, аinterp— путь к интерпретатору Python;buf— это массив, заполненный первыми 256 байтами выполняемого файла. Он используется для определения формата файла и загрузки скриптов шебангов.
«binprm» расшифровывается как «binary program» (двоичная программа, бинарник).
Присмотримся к буферу buf:
// include/linux/binfmts.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/binfmts.h#L64
char buf[BINPRM_BUF_SIZE];Как мы видим, его длина определяется через константу BINPRM_BUF_SIZE. Определение этой константы находится в include/uapi/linux/binfmts.h:
// include/uapi/linux/binfmts.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/uapi/linux/binfmts.h#L18-L19
/* sizeof(linux_binprm->buf) */
#define BINPRM_BUF_SIZE 256Таким образом, ядро загружает 256 байт выполняемого файла в этот буфер памяти.
Ремарка: что такое UAPI?
Вы могли заметить, что путь кода выше содержит
/uapi/. Почему размер буфера не определяется в том же файлеinclude/linux/binfmts.h, в котором определяется структураlinux_binprm?UAPI расшифровывается как «userspace API» (интерфейс пользовательского пространства). В данном случае это означает, что кто-то решил, что длина буфера должна быть частью публичного интерфейса ядра. В теории все UAPI является публичным, а все не UAPI является частным для кода ядра.
Код ядра и пространства пользователя изначально сосуществовали в одном месте. В 2012 г. код UAPI был перемещен в отдельную директорию как попытка улучшения поддерживаемости кода.
Шаг 2. Binfmt
Следующей важной задачей ядра является перебор обработчиков (handlers) «binfmt» (binary format — двоичный формат). Эти обработчики определяются в таких файлах, как fs/binfmt_elf.c и fs/binfmt_flat.c. Модули ядра также могут добавлять свои обработчики binfmt в пул (pool).
Каждый обработчик предоставляет функцию load_binary(), которая «берет» структуру linux_binprm и проверяет, понимает ли обработчик формат программы.
Это часто включает в себя поиск магических чисел в буфере, попытку декодировать запуск программы (также из буфера) и/или проверку расширения файла. Если обработчик поддерживает формат, он готовит программу для запуска и возвращает код успеха (success code). В противном случае, происходит ранний выход (early exit) и возврат кода ошибки (error code).
Ядро перебирает функции load_binary() каждого binfmt до тех пор, пока не достигнет успеха. Иногда это происходит рекурсивно. Например, если скрипт имеет определенный интерпретатор, и сам интерпретатор является скриптом, иерархия может быть такой: binfmt_script > binfmt_script > binfmt_elf (где ELF — это исполняемый формат в конце цепочки).
Скрипты
Я специально остановилась на binfmt_script.
Вы когда-нибудь читали или писали шебанг? Эту строчку в начале скрипта, определяющую путь к интерпретатору?
#!/bin/bashЯ всегда считала, что это обрабатывается оболочкой, но нет! На самом деле шебанги являются «фичей» ядра, и скрипты выполняются с помощью тех же системных вызовов, что и другие программы. Компьютеры такие клевые!
Взглянем на то, как fs/binfmt_script.c проверяет, начинается ли файл с шебанга:
// fs/binfmt_script.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/binfmt_script.c#L40-L42
/* Файл не выполняется, если не начинается с "#!". */
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;Если файл начинается с шебанга, обработчик binfmt читает путь интерпретатора и любые разделенные пробелами аргументы после пути. Он останавливается по достижении новой строки или конца буфера.
Здесь происходит две интересные вещи.
Во-первых, помните буфер в linux_binprm, который заполняется первыми 256 байтами файла? Он используется не только для определения формата выполняемого файла, но из него также читаются шебанги в binfmt_script.
В ходе исследования я прочитала статью, описывающую этот буфер длиной 128 байт. В некоторый момент после публикации этой статьи размер буфера был увеличен до 256 байт! Почему? Я проверила логи редактирования строки кода, где определяется BINPRM_BUF_SIZE в исходном коде Linux, и вот что я обнаружила:

Поскольку шебанги обрабатываются ядром, и чтение происходит из buf вместо загрузки всего файла, они всегда обрезаются до длины buf. Вероятно, 4 года назад кого-то сильно раздражало, что его пути обрезаются до 128 байт, и они решили удвоить длину. Сегодня, если на Linux у вас есть шебанг, длиннее 256 символов, все, что следует за ними, будет полностью потеряно.

Представьте, что из-за этого у вас случился баг. Представьте, что вы пытаетесь выяснить причину поломки вашего кода. Представьте, что вы будете чувствовать, когда обнаружите, что причина лежит глубоко в ядре Linux. Горе следующему разработчику крупной компании, который обнаружит, что часть пути таинственным образом исчезла.
Во-вторых, помните, что argv[0] для названия программы – это всего лишь соглашение, поэтому вызывающий может передать любые argv в системный вызов, и они пройдут без модерации?
Так получилось, что binfmt_script – это одно из тех мест, где предполагается, что argv[0] – это название программы. argv[0] всегда удаляется, а вместо него (в начало argv) добавляется следующее:
- путь интерпретатора;
- аргументы для него;
- название файла скрипта.
Взглянем на пример вызова execve:
// аргументы: filename, argv, envp
execve("./script", [ "A", "B", "C" ], []);Гипотетический файл script содержит такой шебанг на первой строке:
#!/usr/bin/node --experimental-moduleМодифицированный argv, передаваемый в интерпретатор Node.js, будет выглядеть так:
[ "/usr/bin/node", "--experimental-module", "./script", "B", "C" ]После обновления argv обработчик завершает подготовку файла для выполнения путем установки linux_binprm.interp в значение пути интерпретатора. Наконец, он возвращает 0 в качестве индикатора успешной подготовки программы к выполнению.
Разные интерпретаторы
Другим интересным обработчиком является binfmt_misc. Он позволяет добавлять некоторые ограниченные форматы через настройки пользовательского пространства путем монтирования специальной файловой системы в /proc/sys/fs/binfmt_misc/. Программы могут производить специально отформатированные записи в файлы, находящиеся в этой директории, для добавления собственных обработчиков. Каждая конфигурация содержит информацию о том:
- как определять формат файла. Может определяться магическое число на определенном отступе (offset) или расширение файла для поиска;
- путь к исполняемому файлу интепретатора. Не существует способа определения аргументов интепретатора, для этого необходим скрипт-обертка;
- некоторые флаги конфигурации, включая один, определяющий, как
binfmt_miscобновляетargv.
Эта система binfmt_misc часто используется установками Java, настроенными на обнаружение файлов классов по их магическим байтам 0xCAFEBABE и файлам JAR по их расширению. В моей системе обработчик настроен на обнаружение байткода Python по расширению .pyc и его передачу соответствующему обработчику.
Это позволяет установщикам программ добавлять поддержку собственных форматов без написания высокопривилегированного кода ядра.
В завершение
Системный вызов всегда завершается одной из двух вещей:
- в конце концов, достигается исполняемый двоичный формат, который он понимает, и код выполняется. В этом случае происходит замена старого кода;
- или же после исчерпания всех возможностей в вызываемую программу возвращается код ошибки.
Если вы пользовались системой Unix, то могли заметить, что скрипты оболочки выполняются даже при отсутствии строки шебанга или расширения .sh.
$ echo "echo hello" > ./file
$ chmod +x ./file
$ ./file
hellochmod +x сообщает ОС, что файл является исполняемым. В противном случае, файл выполнить не получится.
Так почему скрипт оболочки выполняется как скрипт оболочки? Обработчики ядра не должны определять скрипты оболочки без явных меток!
На самом деле такое поведение не является частью ядра. Это обычный способ обработки ошибок оболочкой.
Когда мы выполняем файл с помощью оболочки и системный вызов проваливается, большинство оболочек повторяют выполнение файла как скрипта оболочки путем вызова оболочки с названием файла в качестве первого аргумента. Bash, как правило, использует себя в качестве интерпретатора, а ZSH обычно использует оболочку Борна.
Такое поведение является стандартным, поскольку оно определено в POSIX — старом стандарте, разработанном для обеспечения возможности переноса кода между разными системами Unix. Несмотря на то, что POSIX не в полной мере соблюдается большинством инструментов и ОС, многие его соглашения являются общепринятыми.
Если [системный вызов] проваливается из-за ошибки, аналогичной ошибке
[ENOEXEC], оболочка должна выполнить аналогичную команду с названием команды в качестве первого операнда и другими аргументами, передаваемыми в новую оболочку. Если исполняемый файл не является текстовым, оболочка может пропустить выполнение этой команды. В этом случае оболочка должна записать сообщение об ошибке и вернуть статус выхода 126.Источник: Shell Command Language, POSIX.1-2017.
Компьютеры такие клевые!
4. Elf
Теперь мы неплохо разбираемся в execve. В большинстве случаев ядро достигает программы, содержащей машинный код для запуска. Как правило, запуску кода предшествует некоторый процесс настройки, например, разные части программы должны загружаться в правильные места в памяти. Каждая программа нуждается в разном объеме памяти для разных вещей, поэтому у нас имеются стандартные форматы файлов для определения настроек программы для выполнения. Хотя Linux поддерживает много форматов, наиболее распространенным является ELF (executable and linkable format — исполняемый и связанный формат).
Ремарка: эльфы повсюду?
Когда мы запускаем приложение или программу командной строки на Linux, весьма вероятно, что запускается двоичный файл ELF. Однако, в macOS фактическим форматом является Mach-O. Mach-O делает тоже самое, что ELF, но имеет другую структуру. В Windows файлы
.exeимеют формат Portable Executable, который следует той же концепции.
В ядре Linux «бинарники» ELF обрабатываются обработчиком binfmt_elf, который является более сложным, чем большинство других обработчиков, и содержит тысячи строк кода. Он отвечает за разбор (парсинг) определенных деталей из файла ELF и использование их для загрузки процесса в память и его выполнение.
$ wc -l binfmt_* | sort -nr | sed 1d
2181 binfmt_elf.c
1658 binfmt_elf_fdpic.c
944 binfmt_flat.c
836 binfmt_misc.c
158 binfmt_script.c
64 binfmt_elf_test.cСтруктура файла
Перед рассмотрением того, как binfmt_elf выполняет файлы ELF, давайте взглянем на сам формат файла. Файлы ELF, как правило, состоят из 4 частей:

Каждый файл ELF имеет заголовок. У него очень важная роль — передача такой базовой информации о бинарнике, как:
- для какого процессора он предназначен. Файлы ELF могут содержать машинный код для разных типов процессора, таких как ARM и x86;
- предполагается ли запуск бинарника как исполняемого файла или его загрузка другой программой как «динамически связанной библиотеки». Мы поговорим о динамическом связывании позже;
- входная точка исполняемого файла. Определяется, куда конкретно в памяти загружать данные из файла ELF. Входная точка – это адрес в памяти, указывающий, где в памяти находится первая инструкция машинного кода после загрузки всего процесса.
Заголовок ELF всегда находится в начале файла. Он определяет локации таблицы заголовков программы (program header table) и таблицы заголовков разделов (section header table), которые могут находиться в любом месте внутри файла. Эти таблицы, в свою очередь, указывают на данные, хранящиеся где-то в файле.
Таблица заголовков программы
Таблица заголовков программы — это серия записей (entries), содержащих детали загрузки и запуска бинарника во время выполнения (runtime). Каждая запись имеет поле type (тип), сообщающее, какие детали она определяет: например, PT_LOAD означает, что запись содержит данные, которые должны быть загружены в память, а PT_NOTE означает сегмент, содержащий информационный текст, который может никуда не загружаться.

Каждая запись содержит информацию о том, где находятся данные в файле, и иногда о том, как загрузить данные в память:
- она указывает на позицию данных в файле ELF;
- она может определять адрес памяти, в который должны быть загружены данные. Если данные не должны загружаться в память, этот сегмент остается пустым;
- 2 поля определяют длину данных: одно для длины данных в памяти, другое для длины области памяти для создания. Если длина памяти превышает длину файла, дополнительная память заполняется нулями. Это позволяет программам резервировать статическую память для использования во время выполнения. Эти пустые сегменты памяти обычно называются сегментами BSS;
- наконец, поле
flagsопределяет, какие операции разрешаются при загрузке в память:PF_Rделает данные доступными только для чтения,PF_W— для записи,PF_X— для выполнения в ЦП.
Таблица заголовков разделов
Таблица заголовков разделов – это серия записей, содержащих информацию о разделах. Информация о разделе – это как карта, отображающая данные внутри файла ELF. Это облегчает понимание предполагаемого использования частей данных программами вроде отладчиков.

Например, таблица заголовков программы может определять большой набор данных для загрузки в память целиком. Один блок PT_LOAD может содержать как код, так и глобальные переменные! Для запуска программы их раздельное определение не требуется. ЦП начинает с входной точки и двигается вперед, извлекая данные по запросам программы. Однако, ПО типа отладчика для анализа программы должно точно знать, где начинается и заканчивается каждая часть данных, в противном случае, оно может попытаться декодировать строку «hello» как код (и поскольку строка не является валидным кодом, «взорваться»). Такая информация хранится в таблице заголовков разделов.
Хотя таблица заголовков разделов обычно включается, она на самом деле является опциональной. Файлы ELF могут прекрасно выполняться при полном удалении этой таблицы. Разработчики, которые хотят спрятать свой код, иногда намеренно удаляют или искажают ее в бинарниках ELF, чтобы затруднить их декодирование.
Каждый раздел содержит название (name), тип (type) и некоторые флаги, которые определяют, как данные должны использоваться и декодироваться. Стандартные названия обычно начинаются с точки по соглашению. Наиболее распространенными разделами являются:
.text— машинный код для загрузки в память и выполнения в ЦП. ТипSHT_PROGBITSс флагомSHF_EXECINSTRпомечает его как исполняемый. ФлагSHF_ALLOCозначает загрузку в память для выполнения;.data— инициализированные данные, жестко закодированные в исполняемом файле для загрузки в память. В этой секции может находиться, например, глобальная переменная, содержащая некоторый текст. Если вы пишете низкоуровневый код, это раздел, где «живет» статика. ТипSHT_PROGBITSпросто означает, что раздел содержит «информацию для программы». ФлагиSHF_ALLOCиSHF_WRITEобозначают его как доступную для записи память;.bss— ранее я упоминала, что обычно часть выделенной памяти начинается с нуля. Помещать кучу пустых байтов в файл ELF неразумно, для этого предназначен раздел BSS. О сегментах BSS полезно знать в процессе отладки. В таблице заголовков разделов есть запись, определяющая длину памяти для выделения. Типом здесь являетсяSHT_NOBITS, а флагами —SHF_ALLOCиSHF_WRITE;.rodata— это те же.data, но доступные только для чтения. В самой простой программе на языке C, запускающейprintf("Hello, world!"), строка «Hello, world!» будет находиться в разделе.rodata, а сам код отображения (printing code) — в разделе.text;.shstrtab— это забавный факт реализации! Сами названия разделов (такие как.textи.shtrtab) не включаются в таблицу заголовков разделов. Каждая запись содержит отступ (offset) к локации в файле ELF, содержащей ее название. Это облегчает парсинг записей таблицы благодаря их фиксированному размеру (отступ – это число фиксированного размера, а для включения в таблицу названия требуется строка переменного размера). Все эти данные о названиях хранятся в отдельном разделе.shstrtabс типомSHT_STRTAB.
Данные
Программа и записи таблицы разделов заголовков указывают на блоки данных внутри файла ELF, то ли загрузить их в память, то ли определить местонахождение кода, то ли просто именовать разделы. Все эти разные части данных содержатся в разделе «Data» файла ELF.

Краткое объяснение связывания
Вернемся к коду binfmt_elf: ядро заботится о двух типах записей из таблицы заголовков программы.
Сегменты PT_LOAD определяют, куда должны загружаться все данные программы, такие как разделы .text и .data. Ядро читает эти сущности из файла ELF для загрузки данных в память, чтобы программа могла быть выполнена ЦП.
Другим типом записей таблицы заголовков программы, о котором заботится ядро, является PT_INTERP, определяющим «время выполнения динамической компоновки» (dynamic linking runtime).
Начнем с того, что такое «связывание» или «компоновка» (linking). Программисты, как правило, пишут программы поверх библиотек повторно используемого кода, например, libc, о которой упоминалось ранее. При преобразовании исходного кода в исполняемый бинарник, программа вызывает компоновщик (linker), разрешающий все ссылки, определяя код библиотеки и копируя его в бинарник. Этот процесс называется «статическим связыванием» (static linking) – внешний код включается прямо в распространяемый файл.
Некоторые библиотеки являются очень популярными. Та же libc используется почти всеми программами, поскольку она представляет собой канонический интерфейс для взаимодействия с ОС через системные вызовы. Что делать? Включать отдельную копию libc в каждую программу на компьютере? Что если в libc появился баг? Придется обновлять все программы? Эти проблемы решаются за счет динамической компоновки.
Если статически связанной программе требуется функция foo() из библиотеки bar, копия этой функции включается в программу. Однако, при динамическом связывании в программу включается только ссылка, как бы говорящая «мне нужна foo() из bar«. При запуске программы (при условии, что bar установлена на компьютере) машинный код функции foo() загружается в память по требованию (on-demand). При обновлении установки bar, новый код загружается в программу при ее следующем запуске без необходимости изменения самой программы.

Динамическая компоновка в дикой природе
В Linux динамически связанные библиотеки вроде bar, как правило, упаковываются в файлы с расширением .so (shared object – общий объект). Эти файлы .so являются такими же файлами ELF, как и программы. Заголовок ELF содержит поле, определяющее, чем является файл, исполняемым файлом или библиотекой. Кроме того, общие объекты содержат раздел .dynsym в таблице заголовков разделов, в котором содержится информация о том, какие символы (symbols) экспортируются из файла и могут быть динамически связаны.
В Windows библиотеки вроде bar упаковываются в файлы с расширением .dll (dynamic link library – динамически подключаемая библиотека). В macOS используется расширение .dylib (dynamically linked library — динамически подключенная библиотека). Также как приложения macOS и файлы .exe Windows, эти форматы немного отличаются от файлов ELF, но следуют той же концепции и технике.
Интересным отличием двух типов связывания является то, что при статическом связывании в исполняемый файл включается (загружается в память) только используемая часть библиотеки. В случае динамического связывания в память загружается вся библиотека. На первый взгляд, это кажется менее эффективным, но на самом деле это позволяет современным ОС сохранять больше пространства путем однократной загрузки библиотеки в память и распределения кода между процессами. Совместно использоваться может только код, поскольку библиотеке требуется разное состояние для разных программ, но экономия все равно может составлять порядка десятков и сотен МБ ОЗУ.
Выполнение
Вернемся к ядру, выполняющему файлы ELF: если исполняемый бинарник является динамически связанным, ОС не может сразу перейти к его коду, поскольку в наличии имеется не весь код — динамически связанные программы содержат только ссылки на функции необходимых им библиотек!
Для запуска бинарника ОС необходимо определить требуемые библиотеки, загрузить их, заменить все именованные указатели реальными инструкциями по переходу и затем запустить полный код программы. Это очень сложный код, глубоко взаимодействующий с форматом ELF, поэтому он обычно представляет собой отдельную программу, а не часть ядра. Файлы ELF определяют путь к программе, которую они хотят использовать (что-то типа /lib64/ld-linux-x86-64.so.2) в записи PT_INTERP таблицы заголовков программы.
После чтения заголовка ELF и сканирования таблицы заголовков программы, ядро настраивает структуру памяти для программы. Все начинается с загрузки в память всех сегментов PT_LOAD, статических данных, пространства BSS и машинного кода программы. Если программа является динамически связанной, ядро должно выполнить интерпретатор ELF (PT_INTERP), поэтому оно также загружает в память данные, BSS и код интерпретатора.
Теперь ядру необходимо установить указатель инструкции для ЦП с целью восстановления при возвращении в пространство пользователя. Если исполняемый файл является динамически связанным, ядро устанавливает указатель инструкции в начало кода интерпретатора ELF в памяти. Иначе, ядро устанавливает его в начало исполняемого файла.
Ядро почти готово к возврату из системного вызова (помните, что мы по-прежнему находимся в execve). Оно отправляет argc, argv и переменные среды окружения в стек для чтения программой при запуске.
После этого регистры очищаются. Перед обработкой системного вызова ядро сохраняет текущее значение регистров в стеке для его последующего восстановления при переключении обратно на пространство пользователя. Перед возвращением в пользовательское пространство, ядро заполняет эту часть стека нулями.
Наконец, системный вызов завершается и ядро возвращается в пространство пользователя. Оно восстанавливает регистры, которые теперь заполнены нулями, и переходит к сохраненному указателю инструкции. Этот указатель теперь является начальной точкой новой программы (или интерпретатора ELF), и текущий процесс заменяется новым!
5. Преобразователь
До сих пор все наши разговоры о чтении и записи в память были слегка невнятными. Например, файлы ELF определяют конкретные адреса памяти для загрузки данных, так почему не возникает проблем с процессами, которые пытаются использовать одинаковые адреса? Почему кажется, что каждый процесс имеет доступ к разной памяти?
Мы понимаем, что execve – это системный вызов, заменяющий текущий процесс новой программой, но это не объясняет, как несколько процессов могут запускаться одновременно. Это также не объясняет, как запускается самая первая программа – процесс, порождающий (spawn) другие процессы.
Память – это фикция
Оказывается, что когда ЦП читает из или пишет в адрес памяти, речь идет не о локации в физической памяти (ОП). Это место в пространстве виртуальной памяти (virtual memory space).
ЦП «общается» с чипом под названием блок управления памятью (memory management unit, MMU). MMU с помощью словаря переводит локации в виртуальной памяти в локации в ОП. Когда ЦП получает инструкцию о чтении из адреса памяти 0xAD4DA83F, он обращается к MMU для перевода адреса. MMU «смотрит» в словарь, находит совпадающий физический адрес 0x70B7BD74 и возвращает это число ЦП. После этого ЦП читает из этого адреса в ОП.

После включения компьютер работает с физической ОП. Сразу после этого ОС создает словарь и указывает ЦП использовать MMU.
Этот словарь называется «таблицей страниц» (page table), а система перевода каждого адреса памяти называется «пейджингом» или «подкачкой» (paging). Записи таблицы страниц называются «страницами» (pages). Страница представляет собой связь определенной части (chunk) виртуальной памяти с ОП. Эти части всегда имеют фиксированный размер, у каждой архитектуры процессора он свой. Размер страницы x86-64 составляет 4 КБ, т.е. каждая страница определяет связь для блока памяти длиной 4096 байт (x86-64 позволяет ОС иметь большие страницы, размером 2 МБ или 4 ГБ, что повышает скорость преобразования адресов, но увеличивает фрагментацию и потери памяти).
Сама таблица страниц просто лежит в ОП. Хотя она может содержать миллионы записей, размер каждой записи составляет всего пару байт, поэтому она не занимает много места.
Для того чтобы включить подкачку при загрузке, ядро сначала создает таблицу страниц в ОП. Затем оно сохраняет физический адрес начала таблицы страниц в регистре под названием «базовый регистр таблицы страниц» (page table base register, PTBR). Наконец, ядро включает подкачку для преобразования всех адресов памяти с помощью MMU. В x86-64 старшие 20 бит регистра управления 3 (CR3) функционируют как PTBR. Бит 31 регистра CR0 (PG) устанавливается в 1 для разрешения подкачки.
Магия таблицы страниц заключается в возможности ее редактирования в процессе работы компьютера. Это позволяет каждому процессу иметь собственное изолированное пространство памяти, когда ОС переключает контекст от одного процесса к другому, важно привязать пространство виртуальной памяти к другой области физической памяти. Предположим, что у нас имеется два процесса: код и данные (вероятно, загруженные из файла ELF) процесса А находятся в 0x0000000000400000, а процесс Б получает доступ к коду и данным по тому же адресу. Эти два процесса даже могут быть экземплярами одной программы, поскольку между ними не возникает конфликтов из-за памяти! В физической памяти данные для процесса А лежат далеко от процесса Б, привязка к 0x0000000000400000 выполняется ядром при переключении процессов.

Ремарка: негативный факт о ELF.
В некоторых ситуациях
binfmt_elfдолжен сопоставить первую страницу памяти с нулями. Некоторые программы, написанные для UNIX System V Release 4.0 (SVr4), ОС 1988 г., первой поддерживающей ELF, полагаются на читаемость нулевых указателей. Каким-то чудесным образом некоторые программисты все еще полагаются на такое поведение.Похоже, разработчик ядра Linux, реализовавший это, был немного недоволен:
«Вы спрашиваете, зачем??? Ну, SVr4 отображает страницу как доступную только для чтения и некоторые приложения «зависят» от этого поведения. Поскольку у нас нет возможности их перекомпилировать, мы вынуждены эмулировать поведение SVr4. Вздох.»
Безопасность подкачки
Изоляция процессов, обеспечиваемая подкачкой памяти, не только улучшает эргономику кода (процессам не нужно беспокоиться об использовании памяти другими процессами), но и создает уровень безопасности: одни процессы не имеют доступа к памяти других процессов. Это половина ответа на вопрос:
Если программы выполняются прямо в ЦП, а ЦП имеет прямой доступ к ОП, почему код не может получить доступ к памяти другого процесса или, прости господи, ядра?
Что насчет памяти ядра? На самом деле, ядру требуется хранить много собственных данных для отслеживания всех запущенных процессов и той же таблицы страниц. При каждом прерывании или запуске системного вызова, когда ЦП входит в режим ядра, ядро должно каким-то образом получить доступ к этой памяти.
Решение Linux состоит в том, чтобы всегда выделять верхнюю половину виртуальной памяти ядру, поэтому Linux называется ядром старшей половины (higher half kernel). Windows практикует похожую технику, а macOS… немного более сложная (прим. пер.: обратите внимание, что здесь три разных ссылки).

С точки зрения безопасности будет ужасным, если пользовательские процессы будут иметь доступ к памяти ядра, поэтому подкачка добавляет второй слой безопасности: каждая страница должна определять флаги разрешений (permission flags). Один флаг определяет, доступна область памяти только для чтения или также для записи. Другой флаг сообщает ЦП, что только ядро имеет доступ к области. Этот флаг используется для защиты всего пространства старшей половины ядра – на самом деле пользовательским программам доступно все пространство памяти ядра в карте виртуальной памяти, они просто не имеют соответствующих разрешений.

Сама таблица страниц фактически содержится в пространстве памяти ядра! Когда чип таймера запускает аппаратное прерывание для переключения процессов, ЦП переключает уровень привилегий и переходит к коду ядра Linux. Нахождение в режиме ядра (кольцо 0 Intel) позволяет ЦП обращаться к защищенной области памяти ядра. Затем ядро может писать в таблицу страниц (которая находится где-то в этой верхней половине памяти) для повторной привязки нижней части виртуальной памяти для нового процесса. Когда ядро переключается к новому процессу и ЦП входит в режим пользователя, его доступ к памяти ядра закрывается.
Почти любой доступ к памяти проходит через MMU. Что насчет указателей обработчика таблицы дескрипторов прерываний? Они также обращаются к пространству виртуальной памяти ядра.
Иерархическая подкачка и другие оптимизации
64-битные системы имеют адреса памяти длиной 64 бита, следовательно, 64-битное пространство виртуальной памяти имеет размер колоссальных 16 эксбибайт. Это невероятно много, намного больше, чем может похвастаться любой современный компьютер или компьютер ближайшего будущего. Насколько мне известно, больше все ОП (больше 1,5 петабайт — менее 0,01% от 16 ЭБ) было у суперкомпьютера Blue Waters.
Если запись в таблице страниц требуется для каждого раздела виртуальной памяти размером 4 КБ, потребуется 4 503 599 627 370 496 таких записей. С записями таблицы страниц длиной 8 байт потребуется 32 пебибайта ОП только для хранения таблицы. Как видите, это по-прежнему превышает мировой рекорд по объему ОП в компьютере.
Поскольку невозможно (или, как минимум, очень непрактично) иметь последовательные записи таблицы страниц для всего возможного пространства памяти, архитектуры ЦП реализуют иерархическое разбиение по страницам (иерархическую подкачку — hierarchical paging). В таких системах существует несколько уровней таблиц страниц со все более мелкой степенью детализации. Записи верхнего уровня охватывают большие блоки памяти и указывают на таблицы страниц меньших блоков, создавая древовидную структуру (tree). Отдельные записи для блоков 4 КБ или любого другого размера являются листьями (leaves) дерева.
В x86-64 исторически используется четырехуровневая иерархическая подкачка. В этой системе каждая запись в таблице страниц определяется путем смещения начала содержащей ее таблицы на часть (portion) адреса. Эта часть начинается со старших битов, которые работают как префикс, поэтому запись охватывает все адреса, начинающиеся с этих битов. Запись указывает на начало следующего уровня таблицы, содержащей поддеревья для этого блока памяти, которые снова индексируются следующим набором битов.
Разработчики четырехуровневой подкачки также решили игнорировать старшие 16 бит всех виртуальных указателей в целях экономии места в таблице страниц. 48 бит дают нам виртуальное адресное пространство размером 128 ТБ, что считается достаточно большим.
Поскольку первые 16 бит пропущены, «самые значащие биты» (most significant bits) для индексации первого уровня таблицы страниц фактически начинаются с 47-го, а не с 63-го бита. Это также означает, что приведенная выше диаграмма старшей половины ядра была технически неточной: начальный адрес пространства ядра должен быть изображен как середина адресного пространства размером менее 64 бит.

Иерархическая подкачка решает проблему с пространством, поскольку на любом уровне дерева указатель на следующую запись может быть нулевым (0x0). Это позволяет исключить целые поддеревья таблицы страниц – неотображаемые (unmapped) области не занимают место в ОП. Поиск по несвязанным адресам памяти быстро завершается ошибкой, поскольку ЦП возвращает ошибку, как только встречает пустую запись выше по дереву. С помощью флага присутствия (presence flag) записи таблицы страниц могут быть помечены как непригодные для использования, даже если адрес выглядит валидным.
Еще одним преимуществом иерархической подкачки является возможность эффективного переключения больших разделов виртуальной памяти. Большой участок виртуальной памяти может сопоставляться с одной областью физической памяти для одного процесса и с другой областью для другого процесса. Ядро может хранить оба отображения в памяти и просто обновлять указатели на верхнем уровне дерева при переключении процессов. Если бы вся карта пространства памяти хранилась в виде плоского массива записей, ядру пришлось бы обновлять множество записей, что было бы медленным и требовало бы независимого отслеживания отображений памяти для каждого процесса.
Я сказала, что x86-64 «исторически» использует четырехуровневую подкачку, потому что последние процессоры реализуют пятиуровневую подкачку. Пятиуровневая подкачка добавляет еще один уровень абстракции, а также еще 9 бит адресации для расширения адресного пространства до 128 ПБ с 57-битными адресами. Такая подкачка поддерживается Linux с 2017 г., а также последними серверными версиями Windows 10 и 11.
Ремарка: ограничения физического адресного пространства.
ОС не используют все 64 бита виртуальных адресов, а ЦП не используют все 64 бита физических адресов. Когда 4-уровневая подкачка была стандартом, процессоры x86-64 не использовали более 46 бит. Это означало, что физическое адресное пространство было ограничено всего 64 ТБ. Процессоры с 5-уровневой подкачкой используют до 52 бит, поддерживая физическое адресное пространство до 4 ПБ.
На уровне ОС выгодно, чтобы виртуальное пространство было больше физического. Как сказал Линус Торвальдс: «[виртуальное пространство должно быть больше физического], по крайней мере, в 2 раза, а лучше в 10 и более. Кто этого не понимает, тот дурак. Конец дискуссии».
Обмен и подкачка по требованию
Доступ к памяти может завершиться ошибкой по нескольким причинам: адрес может находиться за пределами допустимого диапазона, он может не отображаться в таблице страниц или он может содержать запись, помеченную как отсутствующая. Во всех этих случаях MMU инициирует аппаратное прерывание, которое называется «отказом страницы» (page fault), чтобы передать управление ядру.
В случаях, когда чтение действительно было невалидным или запрещенным, ядро завершает программу с ошибкой сегментации (segmentation fault, segfault):
$ ./program
Segmentation fault (core dumped)Ремарка: происхождение segfault.
«Ошибка сегментации» означает разные вещи в зависимости от контекста. MMU запускает аппаратное прерывание, которое называется «ошибкой сегментации», когда происходит чтение памяти без разрешения, но «ошибка сегментации» — это также название сигнала, который ОС посылает работающей программе с целью ее принудительного завершения в связи с нелегальным доступом к памяти.
В других случаях доступ к памяти может быть «намеренно» неудачным, что позволяет ОС заполнить память и передать управление ЦП для повторной попытки. Например, ОС может сопоставить файл на диске с виртуальной памятью, не загружая его в ОП, и произвести такую загрузку только при запросе адреса и возникновении ошибки страницы (page fault). Это называется «подкачкой по требованию» (demand paging).

Это позволяет существовать таким системным вызовам, как mmap, которые лениво (отложенно — lazily) отображают целые файлы с диска в виртуальную память. Джастин Танни недавно значительно оптимизировал LLaMa.cpp, среду выполнения языковой модели Facebook, заставив всю логику загрузки использовать mmap.
При выполнении программы и ее библиотек, ядро фактически ничего не загружает в память. Создается только файл mmap — когда ЦП пытается выполнить код, немедленно возникает ошибка страницы, и ядро заменяет страницу реальным блоком памяти.
Подкачка по требованию также позволяет использовать метод, известный под названием «обмен» (swapping) или просто «подкачка». ОС могут освобождать физическую память, записывая страницы памяти на диск, а затем удаляя их из физической памяти, но сохраняя их в виртуальной памяти с флагом присутствия, установленным в 0. При чтении этой виртуальной памяти ОС восстанавливает память с диска в ОП и устанавливает флаг присутствия обратно в 1. При этом, ОС может менять местами разделы ОЗУ, чтобы освободить место для памяти, загружаемой с диска. Операции чтения и записи на диск являются медленными, поэтому ОС стараются свести подкачку к минимуму с помощью эффективных алгоритмов замены страниц.
Интересным приемом является использование указателей на физическую память таблицы страниц для хранения локаций файлов в физической памяти. Поскольку MMU возвращает ошибку страницы, как только увидит отрицательный флаг присутствия, валидным является адрес или нет, значения не имеет.
6. Вилки и коровы
Прим. пер.: автор играет со словами «fork» и «cow».
Последний вопрос: откуда берется первый процесс?
Если execve запускает новую программу, заменяя текущий процесс, то как запустить новую программу отдельно, в новом процессе? Это важно, если мы хотим делать несколько вещей на компьютере одновременно: когда мы дважды кликаем по иконке приложения, оно запускается отдельно, в то время как программа, в которой мы работали ранее, продолжает работать.
Ответом является другой системный вызов: fork, лежащий в основе многозадачности. fork очень прост: он клонирует (копирует) текущий процесс и его память, не трогая сохраненный указатель инструкции, и затем позволяет обоим процессам продолжаться. Программы продолжают работать независимо друг от друга, а все вычисления удваиваются.
Новый запущенный процесс называется «дочерним» (child), а клонируемый — «родительским» (parent). Процессы могут вызывать fork несколько раз, порождая много детей (потомков). Каждый потомок нумеруется с помощью идентификатора процесса (process ID, PID), который начинается с 1.
Бездумное дублирование кода довольно бесполезно, поэтому fork возвращает разные значения для родительского и дочернего процессов. Для предка он возвращает PID нового дочернего процесса, а для потомка — 0. Это позволяет выполнять другую работу в новом процессе, так что разветвление (forking) действительно полезно.
pid_t pid = fork();
// С этой точки код продолжается как обычно, но через
// два "одинаковых" процесса.
//
// Одинаковых... за исключением PID, возвращаемого из `fork()`!
//
// Это единственный индикатор того, что мы имеем дело
// с разными программами.
if (pid == 0) {
// Мы находимся в дочернем процессе.
// Производим некоторые вычисления и передаем результат предку!
} else {
// Мы в родительском процессе.
// Продолжаем делать то, что делали.
}Разветвление процесса может быть немного сложным для понимания. Будем считать, что вы знаете, как оно работает. Если нет, то загляните на этот неприглядный сайт с хорошим объяснением.
Таким образом, программы Unix запускают новые программы, вызывая fork и запуская execve в новом дочернем процессе. Это называется «шаблоном fork-exec» (fork-exec pattern). При запуске программы наш компьютер выполняет примерно такой код:
pid_t pid = fork();
if (pid == 0) {
// Заменяем дочерний процесс новой программой.
execve(...);
}
// Если мы попали сюда, значит, процесс не был заменен. Мы находимся в родительском процессе!
// PID дочернего процесса хранится в переменной `pid` на случай,
// если мы захотим его убить.
// Здесь продолжается код родительской программы...Мууу!
Вы могли заметить, что дублирование памяти процесса только для того, чтобы ее отбросить при загрузке другой программы, звучит немного неэффективно. Дублирование данных в физической памяти – это медленный процесс, но не дублирование таблиц страниц, поэтому мы просто не дублируем ОП: мы создаем копию таблицы страниц старого процесса для нового процесса – отображение указывает на ту же самую нижележащую физическую память.
Но дочерний процесс должен быть независим и изолирован от родительского! Нехорошо, если потомок будет писать в память предка, и наоборот!
Представляю вам COW (copy on write – копирование при записи, cow – корова). COW позволяет обоим процессам читать из одних и тех же физических адресов до тех пор, пока они не пытаются осуществить запись в память. Как только процесс пытается это сделать, данная страница копируется в ОП. Это позволяет обоим процессам иметь изолированную память без клонирования всего пространства памяти. Это обуславливает эффективность паттерна fork-exec. Поскольку ни один из старых процессов не пишет в память до загрузки нового бинарника, память не копируется.
COW реализована, как и много других забавных вещей, через хаки страниц (page hacks) и обработку аппаратного прерывания. После клонирования страниц с помощью fork, он помечает (устанавливает соответствующие флаги) страницы обоих процессов как доступные только для чтения. Это запускает segfault (разновидность аппаратного прерывания), которое обрабатывается ядром. Ядро, дублирующее память, обновляет страницу для разрешения записи и возвращается из прерывания для выполнения повторной попытки записи.
В начале
Каждый процесс на компьютере является результатом клонирования-выполнения (fork-execed) родительской программы, кроме одного: процесса инициализации (init process). Процесс инициализации устанавливается ядром вручную. Это первая пользовательская программа при запуске и последняя при завершении.
Хотите увидеть клевый мгновенный черный экран? Если у вас macOS или Linux, сохраните свою работу, откройте терминал и убейте процесс инициализации (PID 1):
$ sudo kill 1Ремарка: знания о процессе инициализации, к сожалению, применимы только к Unix-подобным системам, вроде macOS или Linux. Большая часть того, что вы изучите далее, неприменима к Windows, архитектура ядра которой сильно отличается.
Процесс инициализации отвечает за создание всех программ и служб, которые составляют ОС. Многие из них, в свою очередь, создают собственные сервисы и программы.

Завершение процесса инициализации завершает всех его потомков и всех их потомков, что приводит к завершению работы ОС.
Возвращаемся к ядру
Рассмотрим, как ядро запускает процесс инициализации.
Компьютер выполняет последовательность следующих вещей:
- Материнская плата поставляется с небольшим ПО, выполняющем поиск программы, которая называется «загрузчиком» (bootloader) в подключенных дисках. Она выбирает загрузчик, загружает его машинный код в ОП и выполняет этот код. Помните, что ОС еще не запущена. До запуска процесса инициализации многозадачности и системных вызовов не существует. В контексте, предшествующем инициализации, «выполнение» программы означает прямой переход к машинному коду в ОП без ожидания возврата.
- Загрузчик отвечает за обнаружение ядра, его загрузку в ОП и выполнение. Некоторые загрузчики, такие как GRUB, можно настраивать и/или выбирать между несколькими ОС. Встроенными загрузчиками macOS и Windows являются BootX и Windows Boot Manager, соответственно.
- Ядро запускается и приступает к выполнению большого количества задач по инициализации, включая установку обработчиков прерываний, загрузку драйверов и создания начального отображения памяти. Наконец, ядро переключается в режим пользователя и запускает программу инициализации.
- Теперь мы находимся в пространстве пользователя ОС! Программа инициализации выполняет скрипты инициализации, запускает сервисы и выполняет программы вроде оболочки/UI (user interface — пользовательский интерфейс).
Инициализация Linux
В Linux инициализация ядра (шаг 3) происходит в функции start_kernel в init/main.c. Эта функция вызывает более 200 других функций инициализации, поэтому я не буду включать в статью весь код, но рекомендую с ним ознакомиться. В конце start_kernel вызывается функция arch_call_rest_init:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L1087-L1088
/* Делаем остальное без "__init", теперь мы живы */
arch_call_rest_init();Ремарка: что значит без __init?
Функция
start_kernelопределяется какasmlinkage __visible void __init __no_sanitize_address start_kernel(void). Странные слова__visible,__initи__no_sanitize_addressявляются макросами препроцессора C и используются ядром Linux для добавления различного кода и поведения в функцию.В данном случае,
__init– это макрос, указывающий ядру выгрузить функцию и ее данные из памяти по завершении процесса запуска для сохранения пространства.Как это работает? Если не погружаться слишком глубоко в детали, само ядро Linux упаковано в виде файла ELF. Макрос
__initпревращается в__section(".init.text"), директиву компилятора для помещения кода в раздел.init.textвместо обычного раздела.text. Другие макросы также позволяют данным и константам помещаться в специальные разделы, например,__initdataпревращается в__section(".init.data").
arch_call_rest_init – это всего лишь функция-обертка:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L832-L835
void __init __weak arch_call_rest_init(void)
{
rest_init();
}В комментарии говорится «делаем остальное без __init», поскольку rest_init не определяется с помощью макроса __init. Это означает, что она не выгружается для очистки памяти:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L689-L690
noinline void __ref rest_init(void)
{Далее rest_init создает поток (thread) для процесса инициализации:
/*
* Сначала нам нужно создать процесс, чтобы он получил pid 1, однако
* задача инициализации, в конечном итоге, захочет создать kthreads, которые,
* если мы запланируем их до kthreadd, будут OOPS.
*/
pid = user_mode_thread(kernel_init, NULL, CLONE_FS);Параметр kernel_init, передаваемый в user_mode_thread – это функция, которая завершает некоторые задачи инициализации и затем ищет валидную программу инициализации для выполнения. Эта процедура начинается с некоторых базовых задач настройки. Я пропущу большую часть кода, где это происходит, за исключением вызова free_initmem. Это то место, где ядро освобождает разделы .init!
free_initmem();Теперь ядро может найти подходящую программу для запуска:
/*
* Мы пробуем каждую, пока не достигнем успеха.
*
* Вместо init можно использовать оболочку Борна, если мы
* пытаемся восстановить по-настоящему сломанную машину.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (CONFIG_DEFAULT_INIT[0] != '') {
ret = run_init_process(CONFIG_DEFAULT_INIT);
if (ret)
pr_err("Default init %s failed (error %d)n",
CONFIG_DEFAULT_INIT, ret);
else
return 0;
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");В Linux программа инициализации почти всегда находится или символически привязана к /sbin/init. Общими программами инициализации являются systemd, OpenRC и runit. kernel_init() по умолчанию обращается к /bin/sh, если не нашла ничего другого. Если она не находит /bin/sh, значит, что-то ужасно неправильно.
В macOS тоже есть программа инициализации! Она называется launchd и находится в /sbin/launchd. Попробуйте запустить ее в терминале и получите сообщение о том, что вы не являетесь ядром.
Здесь мы переходим к шагу 4 процесса запуска компьютера: процесс инициализации выполняется в пространстве пользователя и начинает запускать различные программы с помощью паттерна fork-exec.
Отображение памяти при клонировании
Мне стало интересно, как ядро Linux повторно отображает нижнюю часть памяти при клонировании процессов. Похоже, большая часть кода клонирования процессов содержится в kernel/fork.c. Начало этого файла подсказало мне правильное место для поиска:
// kernel/fork.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/kernel/fork.c#L8-L13
/*
* 'fork.c' содержит подпрограммы помощи (help-routines) для системного вызова 'fork'
* (см. также entry.S и др.).
* Клонирование является простым, когда вы его освоите, но
* управление памятью может быть стервой. См. 'mm/memory.c': 'copy_page_range()'
*/Похоже, функция copy_page_range() принимает некоторую информацию об отображении памяти и копирует таблицы страниц. При беглом просмотре функций, которые он вызывает, становится понятным, что здесь страницы делаются доступными только для чтения, чтобы стать страницами COW. Определение такой необходимости выполняется с помощью функции is_cow_mapping().
is_cow_mapping() определяется в include/linux/mm.h и возвращает true, если в отображении памяти есть флаги, указывающие, что память доступна для записи и не является распределенной (т.е. не используется несколькими процессами одновременно). Распределенная память не должна быть COW, поскольку она является общей. Полюбуйтесь немного непонятной маскировкой битов (bitmasking):
// include/linux/mm.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/mm.h#L1541-L1544
static inline bool is_cow_mapping(vm_flags_t flags)
{
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}Возвращаемся в kernel/fork.c, выполнение простой команды копирования для copy_page_range() приводит к одному вызову из функции dup_mmap()… которая, в свою очередь, вызывается функцией dum_mm()… которая вызывается функцией copy_mm()… которая, наконец, вызывается массивной функцией copy_process()! copy_process() — это ядро функции клонирования, и, в некотором смысле, суть того, как системы Unix выполняют программы — копирование и редактирование шаблона, созданного для первого процесса при запуске.
В заключение
Как выполняются программы?
На низком уровне: процессоры являются тупыми. Они содержат указатель на память и выполняют инструкции последовательно, пока не достигнут инструкции, указывающей им перейти куда-то еще.
Кроме инструкций перехода, последовательность выполнения инструкций также может нарушаться аппаратными и программными прерываниями. Ядра процессора не могут одновременно выполнять несколько программ, но многозадачность может имитироваться с помощью таймеров для повторяющегося запуска прерываний и переключения кодом ядра между разными указателями кода.
Кажется, что программы выполняются как целостные, изолированные единицы. Прямой доступ к системным ресурсам в режиме пользователя закрыт, пространство памяти изолировано с помощью подкачки, системные вызовы спроектированы таким образом, что предоставляют общий ввод/вывод без знания о реальном контексте выполнения. Системные вызовы — это инструкции, которые просят ЦП запустить некоторый код ядра, локация которого настраивается ядром при запуске.
Но… как выполняются программы?
После запуска компьютера ядро запускает процесс инициализации. Это первая программа, запущенная на высшем уровне абстракции, когда машинному коду не нужно беспокоиться о многих специфических деталях системы. Программа инициализации запускает программы, которые рендерят графическое окружение компьютера и отвечают за запуск другого ПО.
Для запуска программа клонируется с помощью системного вызова fork. Это клонирование является эффективным, поскольку все страницы памяти являются COW, и память не копируется в физическую ОП. В Linux за это отвечает функция copy_process().
Оба процесса проверяются на предмет клонированности. Если они являются клонированными, они используют системный вызов execve для обращения к ядру для замены текущего процесса новой программой.
Скорее всего, новая программа является файлом ELF, который парсится ядром для получения информации о том, как загружать программу и куда помещать ее код и данные в новом отображении виртуальной памяти. Ядро также может выполнять подготовку интерпретатора ELF в случае, когда программа является динамически связанной.
Затем ядро загружает отображение виртуальной памяти программы и возвращается в пространство пользователя с запущенной программой, что означает установку указателя инструкции ЦП в начало кода новой программы в виртуальной памяти.
Эпилог
Поздравляю! Теперь вы лучше понимаете, как работает компьютер. Я надеюсь, что вам было весело.
Позвольте вас проводить, подчеркнув, что знания, которые вы получили, реальны и актуальны. В следующий раз, когда вы задумаетесь о том, как компьютер запускает несколько приложений, я надеюсь, вы представите себе микросхемы таймера и аппаратные прерывания. Когда вы будете писать программу на каком-нибудь причудливом языке программирования и получите ошибку компоновщика (linker error), я надеюсь, вы вспомните, что такое компоновщик и за что он отвечает.
- Из-за путаницы с терминологией словом «оператор» в программировании нередко обозначают операцию ), см. Операция (программирование).
Инстру́кция или опера́тор (англ. statement) — наименьшая автономная часть языка программирования; команда или набор команд. Программа обычно представляет собой последовательность инструкций.
Многие языки (например, Си) различают инструкцию и определение. Различие в том, что инструкция исполняет код, а определение создаёт идентификатор (то есть можно рассматривать определение как инструкцию присваивания).
Ниже приведены основные общие инструкции языков программирования на языке Pascal[источник не указан 3579 дней].
| Определение типа |
TYPE SALARY = INTEGER |
|---|---|
| Объявление |
VAR A:INTEGER |
| Объявление |
A dd ? |
| Объявление |
int A; |
| Присваивание |
A := A + 1 |
| Последовательность инструкций |
A := A + 1; WRITELN(A) |
| Блок инструкций |
BEGIN WRITE('Number? '); READLN(NUMBER); END |
| Условная инструкция | |
| Переключатель |
switch (c) { case 'a': alert(); break; case 'q': quit(); break; } |
| Цикл со счетчиком (цикл For, цикл For..Next) |
FOR A:=1 TO 10 DO WRITELN(A) |
| Цикл с постусловием (цикл Repeat..Until, цикл Do..While) |
do { computation(&i); } while (i < 10); |
| Цикл с предусловием (цикл While) |
WHILE NOT EOF DO READLN |
| Вызов подпрограммы, процедуры или функции |
GOSUB 500 clearscreen() data = file.read() |
| Безусловный переход |
goto 1 |
| Утверждение |
assert(ptr != NULL); |
| Возврат из подпрограммы |
return true; |
См. также[править | править код]
- Директива (программирование), а также прагма (там же)
- Инструкции процессора (машинные инструкции)
- Система команд
|
|
Это заготовка статьи о компьютерных языках. Помогите Википедии, дополнив её. |
|
|
В статье не хватает ссылок на источники (см. рекомендации по поиску). Информация должна быть проверяема, иначе она может быть удалена. Вы можете отредактировать статью, добавив ссылки на авторитетные источники в виде сносок. (3 марта 2023) |
Базовый блок
-
Базовый блок (basic block, BB) — в программировании и теории компиляторов — понятие, обозначающее последовательность инструкций или кода, имеющую одну точку входа (только первая инструкция в последовательности может быть назначением инструкции передачи управления), одну точку выхода и не содержащую инструкций передачи управления ранее точки выхода.
Таким образом, базовый блок — это последовательность инструкций, каждая из которых исполняется тогда и только тогда, когда исполняется первая инструкция из последовательности.
На начало базового блока может указывать одновременно несколько инструкций перехода, конец же блока — либо инструкция передачи управления (jump), либо инструкция, предшествующая переходу.
Базовые блоки являются основной единицей кода, над которой проводятся оптимизации компилятором. Также они являются вершинами (или узлами) в графе потока управления.
Источник: Википедия
Связанные понятия
В императивном программировании порядок выполнения (порядок исполнения, порядок вычислений) — это способ упорядочения инструкций программы в процессе её выполнения.
Граф потока управления (англ. control flow graph, CFG) — в теории компиляции — множество всех возможных путей исполнения программы, представленное в виде графa.
Кодогенерация — часть процесса компиляции, когда специальная часть компилятора, кодогенератор, конвертирует синтаксически корректную программу в последовательность инструкций, которые могут выполняться на машине. При этом могут применяться различные, в первую очередь машинно-зависимые оптимизации. Часто кодогенератор является общей частью для множества компиляторов. Каждый из них генерирует промежуточный код, который подаётся на вход кодогенератору.
Управляющая последовательность (исключённая последовательность, экранированная последовательность, от англ. escape sequence) — совокупность идущих подряд значащих элементов, в группе теряющих для обрабатывающего механизма своё индивидуальное значение, одновременно с приобретением этой группой нового значения.
Паска́ль (англ. Pascal) — один из наиболее известных языков программирования, используется для обучения программированию в старших классах и на первых курсах вузов, является основой для ряда других языков.
Упоминания в литературе
Другой тип сканеров штрих-кодов – это лазерные сканеры, имеющие разные характеристики и размеры – от размера карандаша, до больших встраиваемых многоплоскостных сканеров, расстояние считывания которых достигает нескольких десятков сантиметров при любом наклоне этикетки. Существуют также радиосканеры с возможностью работы на удалении от базового блока на несколько десятков метров.
Связанные понятия (продолжение)
Блок (также говорят блок кода, блок команд, блок инструкций) в программировании — это логически сгруппированный набор идущих подряд инструкций в исходном коде программы, является основой парадигмы структурного программирования.
Си (англ. C) — компилируемый статически типизированный язык программирования общего назначения, разработанный в 1969—1973 годах сотрудником Bell Labs Деннисом Ритчи как развитие языка Би. Первоначально был разработан для реализации операционной системы UNIX, но впоследствии был перенесён на множество других платформ. Согласно дизайну языка, его конструкции близко сопоставляются типичным машинным инструкциям, благодаря чему он нашёл применение в проектах, для которых был свойственен язык ассемблера…
Блок инициализации (initialization block) — понятие в объектно-ориентированном программировании, в основном известное из языка Java, которое представляет собой последовательность команд, выполняемых при создании (загрузке) классов и объектов. Разработано, чтобы значительно увеличить мощность конструктора. Существуют два типа: статический блок инициализации, обычно называемый для краткости статический блок (static block), и динамический блок инициализации (instance block).
Фортра́н (англ. Fortran) — первый язык программирования высокого уровня, получивший практическое применение, имеющий транслятор и испытавший дальнейшее развитие. Создан в период с 1954 по 1957 год группой программистов под руководством Джона Бэкуса в корпорации IBM. Название Fortran является сокращением от FORmula TRANslator (переводчик формул). Фортран широко используется в первую очередь для научных и инженерных вычислений. Одно из преимуществ современного Фортрана — большое количество написанных…
Бейсик Вильнюс (также известен как BASIC-86) — реализация языка программирования Бейсик для 16-разрядных домашних и учебных компьютеров с процессорами архитектуры PDP-11. Первоначально разработан в вычислительном центре Вильнюсского государственного университета (ВЦКП ВГУ) в 1985 году.
Схе́ма — графическое представление определения, анализа или метода решения задачи, в котором используются символы для отображения данных, потока, оборудования и т. д.Блок-схема — распространенный тип схем (графических моделей), описывающих алгоритмы или процессы, в которых отдельные шаги изображаются в виде блоков различной формы, соединенных между собой линиями, указывающими направление последовательности. Правила выполнения регламентируются ГОСТ 19.701-90 «Схемы алгоритмов, программ, данных и систем…
Подробнее: Блок-схема
Самомодифицирующийся код (СМК) — программный приём, при котором приложение создаёт или изменяет часть своего программного кода во время выполнения. Такой код обычно применяют в программах, написанных под процессор с фон-неймановской организацией памяти.
Разработка синхронных цифровых интегральных схем на уровне передач данных между регистрами (англ. register transfer level, RTL — уровень регистровых передач) — способ разработки синхронных (англ.) цифровых интегральных схем, при применении которого работа схемы описывается в виде последовательностей логических операций, применяемых к цифровым сигналам (данным) при их передаче от одного регистра к другому (не описывается, из каких электронных компонентов или из каких логических вентилей состоит схема…
Подробнее: Уровень регистровых передач
Маши́нный код (платфо́рменно-ориенти́рованный код), маши́нный язы́к — система команд (набор кодов операций) конкретной вычислительной машины, которая интерпретируется непосредственно процессором или микропрограммами этой вычислительной машины.Компьютерная программа, записанная на машинном языке, состоит из машинных инструкций, каждая из которых представлена в машинном коде в виде т. н. опкода — двоичного кода отдельной операции из системы команд машины. Для удобства программирования вместо числовых…
Пифагор — функционально-потоковый язык программирования, предназначенный для разработки переносимых (архитектурно-независимых) параллельных программ.
Сопрограммы (англ. coroutines) — методика связи программных модулей друг с другом по принципу кооперативной многозадачности: модуль приостанавливается в определённой точке, сохраняя полное состояние (включая стек вызовов и счётчик команд), и передаёт управление другому. Тот, в свою очередь, выполняет задачу и передаёт управление обратно, сохраняя свои стек и счётчик.
Подробнее: Сопрограмма
Клу (англ. Clu, CLU) — объектно-ориентированный язык программирования, одним из первых реализовавший концепцию абстрактных типов данных и парадигму обобщённого программирования. Создан группой учёных Массачусетского технологического института под руководством Барбары Лисков в 1974 году, широкого применения в практике не нашёл, однако многие его элементы использованы при создании таких языков, как Ада, C++, Java, Sather, Python, C#.
Программи́руемый логи́ческий контро́ллер (сокр. ПЛК; англ. programmable logic controller, сокр. PLC; более точный перевод на русский — контроллер с программируемой логикой), программируемый контроллер — специальная разновидность электронной вычислительной машины. Чаще всего ПЛК используют для автоматизации технологических процессов. В качестве основного режима работы ПЛК выступает его длительное автономное использование, зачастую в неблагоприятных условиях окружающей среды, без серьёзного обслуживания…
ГОСТ Р 34.11-94 — устаревший российский криптографический стандарт вычисления хеш-функции.
Суперскалярный процессор (англ. superscalar processor) — процессор, поддерживающий так называемый параллелизм на уровне инструкций (то есть, процессор, способный выполнять несколько инструкций одновременно) за счёт включения в состав его вычислительного ядра нескольких одинаковых функциональных узлов (таких как АЛУ, FPU, умножитель (integer multiplier), сдвигающее устройство (integer shifter) и другие устройства). Планирование исполнения потока инструкций осуществляется динамически вычислительным…
Подробнее: Суперскалярность
Код операции, операционный код, опкод — часть машинного языка, называемая инструкцией и определяющая операцию, которая должна быть выполнена.
Конве́йер — способ организации вычислений, используемый в современных процессорах и контроллерах с целью повышения их производительности (увеличения числа инструкций, выполняемых в единицу времени — эксплуатация параллелизма на уровне инструкций), технология, используемая при разработке компьютеров и других цифровых электронных устройств.
Арифме́тико-логи́ческое устро́йство (АЛУ) (англ. arithmetic and logic unit, ALU) — блок процессора, который под управлением устройства управления (УУ) служит для выполнения арифметических и логических преобразований (начиная от элементарных) над данными, называемыми в этом случае операндами. Разрядность операндов обычно называют размером или длиной машинного слова.
Управля́ющий автома́т, устро́йство управле́ния проце́ссором (УУ) — блок, устройство, компонент аппаратного обеспечения компьютеров. Представляет собой конечный дискретный автомат. Структурно устройство управления состоит из: дешифратора команд (операций), регистра команд, узла формирования (вычисления) текущего исполнительного адреса, счётчика команд.
Аппаратные средства защиты информационных систем — средства защиты информации и информационных систем, реализованных на аппаратном уровне. Данные средства являются необходимой частью безопасности информационной системы, хотя разработчики аппаратуры обычно оставляют решение проблемы информационной безопасности программистам.
Из-за путаницы с терминологией словом «оператор» в программировании нередко обозначают операцию (англ. operator), см. Операция (программирование).Инстру́кция или опера́тор (англ. statement) — наименьшая автономная часть языка программирования; команда или набор команд. Программа обычно представляет собой последовательность инструкций.
Подробнее: Оператор (программирование)
Параллельные вычислительные системы — это физические компьютерные, а также программные системы, реализующие тем или иным способом параллельную обработку данных на многих вычислительных узлах.Например, для быстрой сортировки массива на двухпроцессорной машине можно разделить массив пополам и сортировать каждую половину на отдельном процессоре. Сортировка каждой половины может занять разное время, поэтому необходима синхронизация.
Данные — поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи, или обработки (ISO/IEC 2382-1:1993).
Барьер памяти (англ. memory barrier, membar, memory fence, fence instruction) — вид барьерной инструкции, которая приказывает компилятору (при генерации инструкций) и центральному процессору (при исполнении инструкций) устанавливать строгую последовательность между обращениями к памяти до и после барьера. Это означает, что все обращения к памяти перед барьером будут гарантированно выполнены до первого обращения к памяти после барьера.
Теорема Бёма — Якопини — положение структурного программирования, согласно которому любой исполняемый алгоритм может быть преобразован к структурированному виду, то есть такому виду, когда ход его выполнения определяется только при помощи трёх структур управления: последовательной (англ. sequence), ветвлений (англ. selection) и повторов или циклов (англ. iteration).
В информатике термин инструкция обозначает одну отдельную операцию процессора, определённую системой команд. В более широком понимании, «инструкцией» может быть любое представление элемента исполнимой программы, такой как байт-код.
Заимствование шифротекста (англ. ciphertext stealing, CTS) в криптографии — общий метод использования блочного режима шифрования, позволяющий обрабатывать сообщения произвольной длины за счет незначительного увеличения сложности реализации. В отличии от дополнения, получившийся шифротекст не становится кратным размеру блока используемого шифра, а остается равным длине исходного открытого текста.
Опера́тор ветвле́ния (усло́вная инстру́кция, усло́вный опера́тор) — оператор, конструкция языка программирования, обеспечивающая выполнение определённой команды (набора команд) только при условии истинности некоторого логического выражения, либо выполнение одной из нескольких команд (наборов команд) в зависимости от значения некоторого выражения.
Подробнее: Ветвление (программирование)
Универсальный асинхронный приёмопередатчик (УАПП, англ. Universal Asynchronous Receiver-Transmitter, UART) — узел вычислительных устройств, предназначенный для организации связи с другими цифровыми устройствами. Преобразует передаваемые данные в последовательный вид так, чтобы было возможно передать их по одной физической цифровой линии другому аналогичному устройству. Метод преобразования хорошо стандартизован и широко применяется в компьютерной технике (особенно во встраиваемых устройствах и системах…
Предвыборка кода — это выдача запросов со стороны процессора в оперативную память для считывания инструкций заблаговременно, до того момента, как эти инструкции потребуется исполнять. В результате этих запросов, инструкции загружаются из памяти в кэш. Когда инструкции, потребуется исполнять, доступ к ним будет осуществляться значительно быстрее, так как задержка при обращении в кэш на порядки меньше, чем при обращении в оперативную память.
Существуют и иные значения этого слова, см. Мир«МИР» (сокращение от «Машина для Инженерных Расчётов») — серия электронных вычислительных машин, созданных Институтом кибернетики Академии наук Украины, под руководством академика В. М. Глушкова.
Подробнее: МИР
Правило одного определения (One Definition Rule, ODR) — один из основных принципов языка программирования C++. Назначение ODR состоит в том, чтобы в программе не могло появиться два или более конфликтующих между собой определения одной и той же сущности (типа данных, переменной, функции, объекта, шаблона). Если это правило соблюдено, программа ведёт себя так, как будто в ней существует только одно, общее определение любой сущности. Нарушение ODR, если оно не будет обнаружено при компиляции и сборке…
Косвенный переход (от англ. indirect branch, также используются термины computed jump (вычисляемый переход), indirect jump (непрямой переход) и register-indirect jump (регистро-косвенный переход)) — тип программного контроля выполнения инструкций, представленный в виде некоторого набора инструкций машинного кода. Вместо указания адреса следующей инструкции для выполнения, как это принято для прямых переходов, здесь аргумент указывает местонахождение адреса.
Дизассемблер длин — транслятор, преобразующий машинный код в его длину; аналог дизассемблера, но вычисляющий только размер команды процессора. Обычно применяется с машинным кодом архитектур, допускающих значительную разницу в длине инструкций, обычно из класса CISC. Например, в x86 и x86_64 (Intel и AMD) команда занимает от 1 до 15 байтов. При этом в распространенных RISC архитектурах команда занимает либо всегда 4 байта или допускается использование 2 и 4 байтных команд.
Модель базы данных — тип модели данных, которая определяет логическую структуру базы данных и принципиально определяет, каким образом данные могут быть сохранены, организованы и обработаны. Наиболее популярным примером модели базы данных является реляционная модель, которая использует табличный формат.
Сеть Фе́йстеля, или конструкция Фейстеля (англ. Feistel network, Feistel cipher), — один из методов построения блочных шифров. Сеть состоит из ячеек, называемых ячейками Фейстеля. На вход каждой ячейки поступают данные и ключ. На выходе каждой ячейки получают изменённые данные и изменённый ключ. Все ячейки однотипны, и говорят, что сеть представляет собой определённую многократно повторяющуюся (итерированную) структуру. Ключ выбирается в зависимости от алгоритма шифрования/расшифрования и меняется…
Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Многопроходный компилятор (англ. Multi-pass compiler) — тип компилятора, который обрабатывает исходный код или абстрактное синтаксическое дерево программы несколько раз (в отличие от однопроходного компилятора, который проходит программу только один раз). Между проходами генерируется промежуточный код, который принимается следующим проходом в качестве входа. Таким образом, многопроходный компилятор обрабатывает код по частям, проход за проходом, а последний проход выдает финальный результат программы…
Программная конвейеризация циклов (англ. software pipelining) — это техника, используемая компиляторами для оптимизации циклов по аналогии с вычислительным конвейером в микропроцессорах. Является формой внеочередного исполнения с той разницей, что переупорядочивание выполняется не процессором, а компилятором (либо, в случае ручной оптимизации, программистом). Некоторые компьютерные архитектуры, например Intel IA-64, имеют явную аппаратную поддержку для упрощения программной конвейеризации циклов…
Ввод-вывод (от англ. input/output, I/O) в информатике — взаимодействие между обработчиком информации (например, компьютер) и внешним миром, который может представлять как человек, так и любая другая система обработки информации. Ввод — сигнал или данные, полученные системой, а вывод — сигнал или данные, посланные ею (или из неё). Термин также может использоваться как обозначение (или дополнение к обозначению) определенного действия: «выполнять ввод-вывод» означает выполнение операций ввода или вывода…
Внеочередное исполнение (англ. out-of-order execution) машинных инструкций — исполнение машинных инструкций не в порядке следования в машинном коде (как было при выполнении инструкций по порядку (англ. in-order execution)), а в порядке готовности к выполнению. Реализуется с целью повышения производительности вычислительных устройств. Среди широко известных машин впервые в существенной мере реализована в машинах CDC 6600 компании Control Data и IBM System/360 Model 91 компании IBM.
Мо́дульное программи́рование — это организация программы как совокупности небольших независимых блоков, называемых модулями, структура и поведение которых подчиняются определённым правилам. Использование модульного программирования позволяет упростить тестирование программы и обнаружение ошибок. Аппаратно-зависимые подзадачи могут быть строго отделены от других подзадач, что улучшает мобильность создаваемых программ.
Таблица виртуальных методов (англ. virtual method table, VMT) — координирующая таблица или vtable — механизм, используемый в языках программирования для поддержки динамического соответствия (или метода позднего связывания).
Цифровой сигнальный процессор (англ. digital signal processor, DSP, цифровой процессор обработки сигналов (ЦПОС)) — специализированный микропроцессор, предназначенный для обработки оцифрованных сигналов (обычно, в режиме реального времени).
Информация
Компьютерная программа
Компьютерная программа

- Области знаний:
- Управление программными проектами, Программное обеспечение ЭВМ
Компьютерная программа
Компью́терная програ́мма, набор (обычно последовательность) инструкций, реализующий алгоритм решения некоторой задачи, которая может быть выполнена на компьютере; компонент программного обеспечения. Процесс составления компьютерной программы называется программированием.
В зависимости от типа и специфики решаемых задач различают компьютерные программы прикладные, системные, встроенные. Большие программы создаются в виде набора взаимодействующих модулей – программных компонентов меньших размеров и сложности. Каждый модуль решает подзадачи в рамках общей задачи и взаимодействует с другими модулями только через заданный интерфейс.
Технические приёмы и правила построения (написания) компьютерной программы (иногда группируемые в т. н. парадигмы программирования) зависят от используемого языка программирования. Компьютерная программа на языке машинных команд (т. н. исполняемый файл) представляет собой набор битов, которые разбиваются на группы, кодирующие отдельные инструкции. Компьютерная программа на языке программирования высокого уровня понятнее человеку, поскольку инструкции такого языка представляют собой более привычную запись определённых действий. Для выполнения на компьютере такая программа либо компилируется в исполняемый файл, либо интерпретируется. В первом случае выполняется преобразование инструкций используемого языка в машинные коды. Во втором – в ходе исполнения специальная программа-интерпретатор читает инструкции данной программы и выполняет соответствующие действия.
Опубликовано 4 июля 2022 г. в 12:04 (GMT+3). Последнее обновление 10 мая 2023 г. в 15:27 (GMT+3).