Перевод статьи «SQL Order of Operations».
Мы привыкли, что компьютер выполняет команды программиста последовательно, в том порядке, который указал автор кода. Однако SQL относится к декларативным языкам, то есть SQL-запрос описывает ожидаемый результат, а не способ его получения.
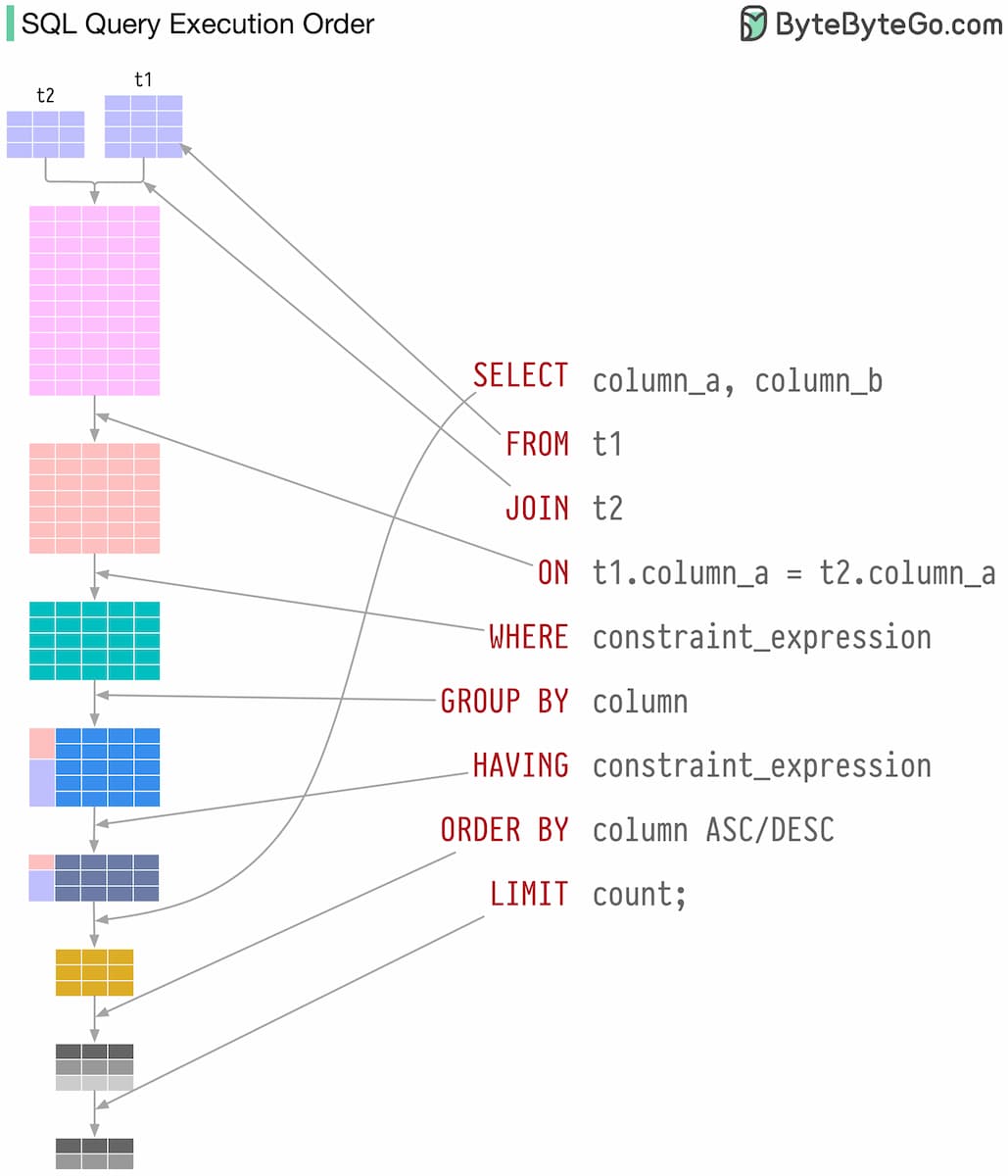
Давайте разберём, в какой последовательности выполняются шесть операций в SQL: SELECT, FROM, WHERE, GROUP BY, HAVING и ORDER BY.
База данных выполняет команды в строгой очерёдности, о которой полезно знать любому разработчику. Залог оптимального запроса тот же, что и залог успеха в приготовлении вкусного блюда: важно знать не только ингредиенты, но и когда каждый из них должен попасть в блюдо. Если база данных отойдет от стандартного сценария выполнения команд, то ее производительность может сильно пострадать.
База данных сотрудников
В этой статье мы поработаем с типичной базой сотрудников, относящихся к разным отделам. По каждому сотруднику известны его ID, имя, фамилия, зарплата и отдел:
Таблица EMPLOYEE:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
Таблица DEPARTMENT:
| DEPT_NAME | MANAGER | BUDGET |
|---|---|---|
| ACCOUNTING | 100 | 300,000 |
| IT | 101 | 250,000 |
| SALES | 104 | 700,000 |
Проанализировать порядок выполнения команд в запросах помогут типичные задачи:
- Найти имена сотрудников отдела IT
- Посчитать количество сотрудников каждого отдела с зарплатой выше 80 000.
Начнем с получения имён сотрудников отдела IT:
SELECT LAST_NAME, FIRST_NAME FROM EMPLOYEE WHERE DEPARTMENT = 'IT'
В первую очередь выполняется FROM EMPLOYEE:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
Затем наступает очередь WHERE DEPARTMENT = ‘IT’, который фильтрует колонку DEPARTMENT:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 101 | Mary | Sexton | 82,000 | IT |
| 103 | Agnes | Miller | 95,000 | IT |
Наконец, SELECT FIRST_NAME, LAST_NAME скрывает ненужные колонки и возвращает финальный результат:
| FIRST_NAME | LAST_NAME |
|---|---|
| Mary | Sexton |
| Agnes | Miller |
Отлично! После первого препарирования выяснилось, что простой запрос с операторами SELECT, FROM, и WHERE выполняется по следующей схеме:
- FROM (выбор таблицы)
- WHERE (фильтрация строк)
- SELECT (возврат результирующего датасета).
Влияние ORDER BY на план выполнения запроса
Допустим, что начальнику не понравился отчет, основанный на предыдущем запросе, потому что он хочет видеть имена в алфавитном порядке. Исправим это с помощью ORDER BY:
SELECT LAST_NAME, FIRST_NAME
FROM EMPLOYEE
WHERE DEPARTMENT = 'IT'
ORDER BY FIRST_NAME
Выполняться такой запрос будет так же, как и предыдущий. Только в конце ORDER BY отсортирует строки в алфавитном порядке по колонке FIRST_NAME:
| FIRST_NAME | LAST_NAME |
|---|---|
| Agnes | Miller |
| Mary | Sexton |
Таким образом, команды SELECT, FROM, WHERE и ORDER BY выполняются в следующей последовательности:
- FROM (выбор таблицы)
- WHERE (фильтрация строк)
- SELECT (возврат результирующего датасета)
- ORDER BY (сортировка)
GROUP BY и HAVING
Усложним задачу. Посчитаем количество сотрудников каждого отдела с зарплатой выше 80 000 и остортируем результат по убыванию. Нам подойдёт следующий запрос:
SELECT DEPARTMENT, COUNT(*)
FROM EMPLOYEES
WHERE SALARY > 80000
GROUP BY DEPARTMENT
ORDER BY COUNT(*) DESC
Как обычно, в первую очередь выполнится FROM EMPLOYEE и вернет сырые данные:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
После выполнения WHERE SALARY > 80000 выборка сузится:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
Затем применяется GROUP BY. При этом генерируется по одной записи для каждого отдельного значения в указанной колонке. В нашем примере мы создаем по одной записи для каждого отдельного значения колонки DEPARTMENT:
| DEPARTMENT |
|---|
| ACCOUNTING |
| IT |
| SALES |
После этого применяется SELECT с COUNT(*), производя промежуточный результат:
| DEPARTMENT | COUNT(*) |
|---|---|
| ACCOUNTING | 1 |
| IT | 2 |
| SALES | 1 |
Применение ORDER BY завершает выполнение запроса и возвращает конечный результат:
| DEPARTMENT | COUNT(*) |
|---|---|
| IT | 2 |
| ACCOUNTING | 1 |
| SALES | 1 |
План выполнения данного запроса следующий:
- FROM (выбор таблицы)
- WHERE (фильтрация строк)
- GROUP BY (агрегирование данных)
- SELECT (возврат результирующего датасета)
- ORDER BY (сортировка).
Добавим выражение HAVING
HAVING — это аналог WHERE для GROUP BY. С его помощью можно фильтровать агрегированные данные.
Давайте применим HAVING и определим, в каких отделах (за исключением отдела продаж) средняя зарплата сотрудников больше 80 000.
SELECT DEPARTMENT
FROM EMPLOYEES
WHERE DEPARTMENT <> 'SALES'
GROUP BY DEPARTMENT
HAVING AVG(SALARY) > 80000
По уже известной нам схеме сначала выберем все данные из таблицы при помощи FROM EMPLOYEE:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
Затем конструкция WHERE избавит нас от данных по отделу SALES:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
GROUP BY сгенерирует следующие записи:
| DEPARTMENT | AVG(SALARY) |
|---|---|
| ACCOUNTING | 79,250 |
| IT | 88,500 |
HAVING AVG(SALARY) > 80000 ограничит список:
| DEPARTMENT | AVG(SALARY) |
|---|---|
| IT | 88,500 |
А SELECT вернет финальный результат:
| DEPARTMENT |
|---|
| IT |
Порядок выполнения для данного запроса следующий:
- FROM (выбор таблицы)
- WHERE (фильтрация строк)
- GROUP BY (агрегирование данных)
- HAVING (фильтрация агрегированных данных)
- SELECT (возврат результирующего датасета).
Новый оператор — JOIN
До этого момента мы имели дело с одной таблицей. А что если воспользоваться JOIN и добавить ещё одну? Выясним фамилии и ID сотрудников, работающих в отделе с бюджетом более 275 000:
SELECT EMPLOYEE_ID, LAST_NAME
FROM EMPLOYEES
JOIN DEPARTMENT
ON DEPARTMENT = DEPT_NAME
WHERE BUDGET > 275000
FROM EMPLOYEE как обычно запрашивает данные из таблицы EMPLOYEES:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
А теперь JOIN запросит сырые данные из DEPARTMENT и скомбинирует данные двух таблиц по условию ON DEPARTMENT = DEPT_NAME:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT | DEPT_NAME | MANAGER | BUDGET |
|---|---|---|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 101 | Mary | Sexton | 82,000 | IT | IT | 101 | 250,000 |
| 102 | Chun | Yen | 80,500 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 103 | Agnes | Miller | 95,000 | IT | IT | 101 | 250,000 |
| 104 | Dmitry | Komer | 120,000 | SALES | SALES | 104 | 700,000 |
Потом применяем WHERE BUDGET > 275000:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT | DEPT_NAME | MANAGER | BUDGET |
|---|---|---|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 102 | Chun | Yen | 80,500 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 104 | Dmitry | Komer | 120,000 | SALES | SALES | 104 | 700,000 |
SELECT EMPLOYEE_ID, LAST_NAME покажет финальный результат:
| EMPLOYEE_ID | LAST_NAME |
|---|---|
| 100 | Smith |
| 102 | Yen |
| 104 | Komer |
Для этого запроса план выполнения следующий:
- FROM (выбор таблицы)
- JOIN (комбинация с подходящими по условию данными из второй таблицы)
- WHERE (фильтрация строк)
- SELECT (возврат результирующего датасета).
Итог
Примеры разных запросов убедительно продемонстрировали, что существует строгий порядок выполнения операций. Но этот порядок может меняться в зависимости от набора команд в запросе. Вот универсальная шпаргалка по очередности выполнения операций в SQL-запросах:
- FROM (выбор таблицы)
- JOIN (комбинация с подходящими по условию данными из других таблиц)
- WHERE (фильтрация строк)
- GROUP BY (агрегирование данных)
- HAVING (фильтрация агрегированных данных)
- SELECT (возврат результирующего датасета)
- ORDER BY (сортировка).
Помните, что если исключить из этого списка один из операторов, то план выполнения может измениться.

Опубликовано: четверг, 22 июня 2023 г. в 08:16
- DevOps
- SQL
В этой статье мы рассмотрим, как SQL запросы выполняются механизмом базы данных и как использовать эти знания для оптимизации запросов для повышения производительности и точности.
Что такое порядок выполнения SQL запроса
Порядок выполнения SQL запроса — это фактическая последовательность, в которой механизм базы данных обрабатывает различные компоненты SQL запроса. Это не то же самое, что порядок, в котором мы пишем запрос. Следуя определённому порядку выполнения, ядро базы данных может свести к минимуму дисковый ввод/вывод, эффективно использовать индексы и избежать ненужных операций. Это приводит к более быстрому выполнению запросов и меньшему потреблению ресурсов.
Возьмём пример SQL запроса и посмотрим, как он выполняется:
SELECT
customers.name,
COUNT(order_id) as Total_orders,
SUM(order_amount) as total_spent
FROM customers
JOIN orders ON customers.id = orders.customer_id
WHERE order_date >= '2023-01-01'
GROUP BY customers.name
HAVING total_spent >= 1000
ORDER BY customers.name
LIMIT 100;Порядок выполнения этого запроса следующий:
- Предложение FROM: Первым шагом является определение таблиц, задействованных в запросе. В данном случае это
customersиorders. - Предложение JOIN: Следующим шагом является выполнение операции объединения на основе условия объединения. В данном случае это
customers.id = orders.customer_id, которое связывает две таблицы, сопоставляяidклиентов. - Предложение WHERE: Третий шаг — применить условие фильтрации к объединённой таблице. В данном случае это
order_date >= '2023-01-01', который выбирает только заказы, сделанные 1 января 2023 года и позже. Теперь важно написать запрос SARGABLE, чтобы эффективно использовать индексы. SARGABLE означает Searched ARGUment ABLE и относится к запросам, которые могут использовать индексы для более быстрого выполнения. Мы углубимся в SARGABLE запросы позже. - Предложение GROUP BY: Четвёртый шаг — сгруппировать строки по указанным столбцам. В данном случае это
customers.name, которое создаёт группы на основе имени клиента. - Предложение HAVING: Пятый шаг — фильтрация групп по условию. В данном случае это
total_spent >= 1000, при котором выбираются группы с общей потраченной суммой 1000 и более. - Предложение SELECT: Шестой шаг — выбор столбцов и агрегатных функций из каждой группы. В данном случае это
customers.name,COUNT(order_id) as Total_ordersиSUM(order_amount) as total_spent. - Предложение ORDER: Седьмой шаг — сортировка строк по указанным столбцам. В данном случае это
customers.name, которое сортирует строки в алфавитном порядке по именам клиентов. - Предложение LIMIT: Последний шаг — пропустить несколько строк из отсортированного набора результатов. В данном случае результат ограничивается максимум
100строками.
Источник изображения
Почему запросы SARGABLE имеют значение
SARGABLE переводится как Искомый аргумент
и относится к запросам, которые могут использовать индексы для более быстрого выполнения. Индексы — это структуры данных, которые хранят подмножество столбцов из таблицы в отсортированном порядке, что позволяет выполнять быстрый поиск и сравнение.
Запрос SARGABLE, если он использует операторы и функции, которые могут использовать преимущества индексов. Например, использование операторов равенства (=), неравенства (<>, !=), диапазона (BETWEEN) или членства (IN) в индексированных столбцах может сделать запрос SARGABLE.
Запрос не SARGABLE, если он использует операторы или функции, которые препятствуют использованию индекса или требуют полного сканирования таблицы. Например, использование операторов отрицания (NOT), подстановочных знаков (LIKE) или арифметических операций (+, -, *, /) в индексированных столбцах может сделать запрос не SARGABLE.
Для написания SARGABLE запроса необходимо следовать некоторым общим рекомендациям:
- Избегайте использования функций для индексированных столбцов в предложении
WHERE, таких, какUPPER(),LOWER(),SUBSTRING()и т.д. - Избегайте использования арифметических операций над индексированными столбцами в предложении
WHERE, напримерстолбец + 1 > 10,столбец * 2 < 20и т.д. - Избегайте использования операторов отрицания для индексированных столбцов в предложении
WHERE, таких, какNOT IN,NOT LIKE,NOT EXISTSи т.д. - Избегайте использования подстановочных знаков в индексированных столбцах в предложении
WHEREс ведущими подстановочными знаками (%), такими какLIKE '%abc',LIKE -xyz%'и т.д. - Используйте соответствующие типы данных для столбцов и литералов, чтобы избежать неявных преобразований, которые могут повлиять на использование индекса.
Вот несколько примеров запросов SARGABLE и не SARGABLE:
Плохой: SELECT ... WHERE Year(myDate) = 2022
Исправленный: SELECT ... WHERE myDate >= '01-01-2022' AND myDate < '01-01-2023'
Плохой: Select ... WHERE SUBSTRING(DealerName,4) = 'Ford'
Исправленный: Select ... WHERE DealerName Like 'Ford%'
Плохой: Select ... WHERE DateDiff(mm, OrderDate, GetDate ()) >= 30
Исправленный: Select ... WHERE OrderDate < DateAdd(mm, -30, GetDate())Как настроить производительность на уровне базы данных
Повышение производительности в порядке выполнения SQL запроса включает в себя оптимизацию шагов, выполняемых ядром базу данных для обработки и выполнения SQL запросов. Вот несколько способов повысить производительность в порядке выполнения SQL запроса:
- Используйте соответствующие индексы: Проанализируйте шаблоны запросов и определите столбцы, часто используемые в операциях поиска, объединения и фильтрации. Создавайте индексы для этих столбцов для более быстрого извлечения данных и уменьшения потребности в полном сканировании таблиц.
- Оптимизируйте операции
JOIN: Убедитесь, что условияJOINэффективны и используйте соответствующие индексы. По возможности используйтеINNER JOINвместоOUTER JOIN, поскольку это обычно приводит к повышению производительности. Рассмотрите порядок объединения нескольких таблиц, чтобы свести к минимуму размер промежуточного набора результатов. - Ограничивайте размер набора результатов: Используйте предложение
LIMITдля ограничения количества строк возвращаемых запросом. Это может уменьшить объём обрабатываемых данных и сократить время ответа на запрос. - Избегайте ненужной сортировки и группировки: Устраните ненужные операции сортировки и группировки, включая их только по необходимости. Этого можно добиться путём тщательного анализа запроса и удаления ненужных предложений
ORDER BYиGROUP BY. - Ранняя фильтрация с предложением
WHERE: Применяйте условие фильтрации как можно раньше в порядке выполнения запроса с помощью предложенияWHERE. Это уменьшает количество строк, обрабатываемых на следующих этапах, повышая производительность. - Используйте подходящие типы данных: Выберите правильные типы данных для столбцов, чтобы обеспечить эффективное хранение и извлечение данных. Использование соответствующих типов данных. Использование соответствующих типов данных может помочь сократить потребление памяти и повысить скорость выполнения запросов.
- Избегайте ненужных вычислений и функций: Сведите к минимуму использование вычислений и функций в запросе, особенно в индексированных столбцах. Эти операции могут препятствовать использованию индекса и влиять на производительность. Рассмотрите возможность предварительного вычисления значений или использования производных столбцов, когда это необходимо.
- Инструменты оптимизации запросов: Используйте инструменты или подсказки оптимизации запросов для конкретной базы данных, чтобы направлять механизм базы данных в создании эффективных планов выполнения. Эти инструменты могут предоставить информацию, рекомендации и статистику для повышения производительности.
Заключение
Мы узнали, что порядок выполнения SQL влияет на производительность запросов и эффективность базы данных. Мы можем улучшить его с помощью индексации, объединений, фильтрации, запросов SARGABLE и рекомендаций. Это повысит скорость SQL запросов и сделать системы баз данных высокопроизводительными.
Для того чтобы понять, как получается
результат выполнения оператора SELECT,
рассмотрим концептуальную схему его
выполнения. Эта схема является именно
концептуальной, т.к. гарантируется, что
результат будет таким, как если бы он
выполнялся шаг за шагом в соответствии
с этой схемой. На самом деле, реально
результат получается более изощренными
алгоритмами, которыми «владеет»
конкретная СУБД.
Стадия 1. Выполнение одиночного оператора select
Если в операторе присутствуют ключевые
слова UNION, EXCEPT и INTERSECT, то запрос разбивается
на несколько независимых запросов,
каждый из которых выполняется отдельно:
Шаг 1 (FROM). Вычисляется прямое
декартовое произведение всех таблиц,
указанных в обязательном разделе FROM. В
результате шага 1 получаем таблицу A.
Шаг 2 (WHERE). Если в операторе SELECT
присутствует раздел WHERE, то сканируется
таблица A, полученная при выполнении
шага 1. При этом для каждой строки из
таблицы A вычисляется условное выражение,
приведенное в разделе WHERE. Только те
строки, для которых условное выражение
возвращает значение TRUE, включаются в
результат. Если раздел WHERE опущен, то
сразу переходим к шагу 3. Если в условном
выражении участвуют вложенные подзапросы,
то они вычисляются в соответствии с
данной концептуальной схемой. В результате
шага 2 получаем таблицу B.
Шаг 3 (GROUP BY). Если в операторе SELECT
присутствует раздел GROUP BY, то строки
таблицы B, полученной на втором шаге,
группируются в соответствии со списком
группировки, приведенным в разделе
GROUP BY. Если раздел GROUP BY опущен, то сразу
переходим к шагу 4. В результате шага 3
получаем таблицу С.
Шаг 4 (HAVING). Если в операторе SELECT
присутствует раздел HAVING, то группы, не
удовлетворяющие условному выражению,
приведенному в разделе HAVING, исключаются.
Если раздел HAVING опущен, то сразу переходим
к шагу 5. В результате шага 4 получаем
таблицу D.
Шаг 5 (SELECT). Каждая группа, полученная
на шаге 4, генерирует одну строку
результата следующим образом. Вычисляются
все скалярные выражения, указанные в
разделе SELECT. По правилам использования
раздела GROUP BY, такие скалярные выражения
должны быть одинаковыми для всех строк
внутри каждой группы. Для каждой группы
вычисляются значения агрегатных функций,
приведенных в разделе SELECT. Если раздел
GROUP BY отсутствовал, но в разделе SELECT есть
агрегатные функции, то считается, что
имеется всего одна группа. Если нет ни
раздела GROUP BY, ни агрегатных функций, то
считается, что имеется столько групп,
сколько строк отобрано к данному моменту.
В результате шага 5 получаем таблицу E,
содержащую столько колонок, сколько
элементов приведено в разделе SELECT и
столько строк, сколько отобрано групп.
Стадия 2. Выполнение операций union, except, intersect
Если в операторе SELECT присутствовали
ключевые слова UNION, EXCEPT и INTERSECT, то таблицы,
полученные в результате выполнения 1-й
стадии, объединяются, вычитаются или
пересекаются.
Стадия 3. Упорядочение результата
Если в операторе SELECT присутствует раздел
ORDER BY, то строки полученной на предыдущих
шагах таблицы упорядочиваются в
соответствии со списком упорядочения,
приведенном в разделе ORDER BY.
Пожалуйста, дайте порядок выполнения операторов sql запроса или дайте ссылку, где прочитать об этом: что за чем выполняется. Например (с потолка):
SELECT
t1.id AS id, t1.name AS name, count(*) AS cnt
FROM
tbl_name1 t1
INNER JOIN
tbl_name2 t2 ON t1.id = t2.id
WHERE
t1.id > 10
GROUP BY
t1.name
HAVING
cnt > 10
ORDER BY
t1.id
Сначала GROUP BY, потом? Последним ORDER BY…
Нигде не могу найти нормальной информации об этом :((
задан 13 авг 2011 в 6:19
Для SQL Server смотри ссылку.
Логический порядок обработки инструкции SELECT:
- FROM
- ON
- JOIN
- where
- GROUP BY
- WITH CUBE или WITH ROLLUP
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP
![]()
ответ дан 29 янв 2016 в 13:06
ЮрийЮрий
811 серебряный знак1 бронзовый знак
Порядок выполнения зависит от ситуации и определяется перед выполнением запроса. СУБД позволяют просмотреть план выполнения — это то, как именно СУБД решила выполнить запрос.
ответ дан 13 авг 2011 в 7:06
Олег НечитайлоОлег Нечитайло
1,4667 серебряных знаков14 бронзовых знаков
1
ответ дан 13 авг 2011 в 7:10
msimsi
11.5k16 серебряных знаков16 бронзовых знаков
5
SELECT
[DISTINCT | DISTINCTROW | ALL]
select_expression,...
[FROM table_references]
[WHERE where_definition]
[GROUP BY {unsigned_integer | col_name | formula} [ASC | DESC], ...]
[HAVING where_definition]
[ORDER BY {unsigned_integer | col_name | formula} [ASC | DESC], ...]
ответ дан 13 авг 2011 в 6:53
AvalonAvalon
1,0186 серебряных знаков14 бронзовых знаков
1
Понимание логической обработки запросов — ключ к разработке производительного кода SQL
Предлагаю вашему вниманию первую статью из серии материалов, посвященных логической обработке запросов. В ней речь пойдет о том, что я понимаю под этим термином, и будет предложен общий обзор проблемы. В следующих статьях я подробно расскажу об отдельных предложениях запроса.
Если бы меня попросили назвать фундаментальный вопрос в T-SQL, наиболее важный для практической работы, то, несомненно, я бы выбрал логическую обработку запросов. Необходимо с самого начала отметить, что этот термин не взят из какого-то формального источника. Я придумал его, чтобы объяснить студентам и читателям логическую, или концептуальную, интерпретацию запроса. Глубокое понимание этой темы — ключ к созданию правильного и надежного программного кода. Всегда на занятиях по T-SQL, будь то курсы для начинающих или для опытных специалистов, я начинаю с этой темы, поскольку она одинаково важна для всех.
Что означает «логическая обработка запросов»?
Чтобы понять, что здесь означает слово «логическая», нужно начать с основ T-SQL. Это широко известные базовые принципы, их взаимосвязь показана на рисунке 1.
 |
| Рисунок 1. Основы T-SQL |
T-SQL, или Transact-SQL, — диалект стандартного языка SQL, используемый Microsoft в нескольких продуктах, которые являются частью платформы обработки данных компании, таких как Microsoft SQL Server и Microsoft Azure SQL Database. Используя T-SQL, можно управлять данными в этих продуктах. T-SQL — собственный диалект Microsoft — базируется в основном на стандартном языке SQL с некоторыми расширениями. Язык SQL (Structured Query Language) поддерживается как Международной организацией по стандартизации (ISO), так и Американским национальным институтом стандартов (ANSI).
SQL, в свою очередь, основывается на реляционной модели — семантической модели представления данных, созданной Эдгаром Ф. Коддом в 1969 году. Реляционная же модель основана на двух областях математики: теории множеств и логике предикатов.
В реляционной модели определен важный принцип независимости физических данных. Это означает, что модель и основанный на ней язык определяют логические аспекты данных и манипуляций или, другими словами, смысл. Авторы модели избегают вдаваться в детали физической реализации (способы физической организации, хранения и доступа к данным, а также методы физической обработки — оптимизации и выполнения — запросов). Физическая часть зависит от используемой платформы базы данных. Не предполагается, что пользователь осмысливает информацию, основываясь на физических данных. Для этого служит логическая модель.
Хороший пример нарушения (то есть ложных ожиданий) принципа независимости физических данных — направить запрос к таблице без предложения ORDER BY и предположить, что данные будут возвращены в порядке кластеризованного индекса. Что касается модели отношения, то тело отношения представляет собой набор кортежей (в SQL отношение называется таблицей, а кортеж строкой), а набор в математике не упорядочен. Направляя запрос к отношению, вы получаете отношение, поэтому нет гарантии, что результат будет получен в определенном порядке.
Реализация Microsoft построена с учетом принципа независимости физических данных и потому не гарантирует, что данные после запроса будут получены в некотором особом порядке, если только во внешний запрос не добавлено предложение ORDER BY. Похожее нарушение принципа происходит, когда пользователи обновляют данные, и правильность решения зависит от обновления данных в порядке кластеризованного индекса (поищите в Интернете quirky update и узнаете, что имеется в виду).
Поэтому под логической обработкой запросов подразумевается логическая, или концептуальная, интерпретация запроса. Она основывается на стандарте SQL, в котором описано, как данные из входных таблиц преобразуются в ходе последовательности шагов в окончательный результат запроса. Это описание не зависит от каких-либо факторов физической интерпретации. Таким образом, изучая данную тему, важно не придавать значения показателям производительности — они не относятся к зоне ответственности SQL или реляционной модели.
Порядок логической обработки запросов
Первое любопытное обстоятельство, связанное с логической обработкой запросов, на которое следует обратить внимание, состоит в том, что порядок, в котором вводятся предложения основного запроса, отличается от порядка, в котором они интерпретируются логически. Это показано на рисунке 2.
|
|
| Рисунок 2. Порядок ввода предложений запросов с номерами шагов логической обработки запросов |
Предложения основного запроса показаны в том порядке, в котором их нужно вводить, а номера шагов представляют порядок логической обработки запросов. Обратите внимание, что, хотя вы вводите предложение SELECT первым, предложение FROM логически обрабатывается в первую очередь. На самом деле предложение SELECT логически обрабатывается только на пятом шаге.
Я поясню, что стоит за такой структурой. Дело в том, что разработчики SQL хотели, чтобы язык напоминал английский. Первоначальное название языка было SEQUEL (сокращение от Structured English QUEry Language), но из-за спора об авторских правах оно было изменено на SQL. Теперь вспомним, как структурированы инструкции в английском языке. Например, рассмотрим запрос Bring me the T-SQL Querying book from the shelf in my office (принесите мне книгу T-SQL Querying с полки в моем офисе). Обратите внимание, что инструкция начинается не с указания местонахождения объекта (офис), а с самого объекта (книга). Но если задуматься о порядке, в котором необходимо выполнять такую инструкцию, то сначала требуется зайти в комнату, потом найти полку, а затем уже взять книгу и принести ее.
Аналогично порядок ввода предложений запроса начинается с предложений SELECT, указывающих возвращаемые столбцы, следом идет предложение FROM, указывающее входные таблицы и табличные операторы, а затем предложение WHERE с фильтром строк и т. д. Однако логическая обработка запросов должна начинаться с идентификации задействованных таблиц (предложение FROM), затем необходимо применить все фильтры строк (WHERE), сгруппировать (GROUP BY), выполнить групповую фильтрацию (HAVING) и только после этого перейти к столбцам, которые нужно возвратить (SELECT).
После того как вы поймете разницу между порядком ввода предложений запроса и логическим порядком обработки запросов, становятся понятными многие особенности SQL, которые в противном случае кажутся странными.
На рисунке 2 показан требуемый порядок ввода предложений запроса. На рисунке 3 мы видим те же предложения на основе порядка логической обработки запроса.
|
|
| Рисунок 3. Порядок логической обработки предложений запроса |
На рисунке 4 показана подробная блок-схема логической обработки запроса. Входы — это таблицы, указанные в предложении FROM. Каждый шаг применяется к таблице или таблицам, предоставляемым в качестве входных данных, и возвращает виртуальную таблицу в качестве выходных данных. На самом последнем шаге окончательный результат запроса возвращается приложению или внешнему запросу.
|
|
| Рисунок 4. Блок-схема логической обработки запроса |
Если вам нравится решать задачи, рассмотрите другие шаги в блок-схеме. Впрочем, я буду их подробно разбирать в следующих статьях; пока они представлены для справки. При чтении следующих статей серии держите под рукой рисунки 2, 3 и 4. Они вам пригодятся.
Та же база данных и тестовые запросы
В моих примерах будет использоваться тестовая база данных с именем TSQLV4. Исходный текст, с помощью которого можно создать и заполнить базу данных, находится по адресу: http://tsql.solidq.com/SampleDatabases/TSQLV4.zip. Эта база данных представляет собой простую систему ввода информации о заказах с таблицами Sales.Customers, Sales.Orders (с заголовками заказов), Sales.OrderDetails (со строками заказов) и т. д. База данных совместима со всеми версиями, начиная с SQL Server 2008 и до 2016, а также с базой данных SQL Azure. Перед запуском программного кода из статей данной серии убедитесь, что эта база данных установлена и доступна. После установки используйте следующую команду для переключения контекста на эту базу данных:
USE TSQLV4;
Для объяснения логической обработки запросов будут использоваться два тестовых запроса, простой и сложный. В статье они именуются «простой тестовый запрос» и «сложный тестовый запрос». В листинге 1 показан простой тестовый запрос. Он возвращает данные заказчиков из Испании, разместивших не более трех заказов. Для подходящих заказчиков возвращаются идентификатор (customer ID) и число заказов. Запрос выдает строки, сортированные по числу заказов в возрастающем порядке.
Вероятно, вы привыкли «читать» запрос в соответствии с порядком ввода предложений. Попробуйте прочитать его в соответствии с порядком логической обработки запроса.
- FROM: запрос объединяет таблицы Customers и Orders на основании совпадений между идентификаторами customer ID заказчика и заказа. В запросе используется левое внешнее соединение, чтобы сохранить заказчиков, не разместивших заказы.
- WHERE: запрос фильтрует только строки, в которых указана страна заказчика — Испания (Spain).
- GROUP BY: запрос группирует оставшиеся строки по идентификатору customer ID заказчика.
- HAVING: запрос фильтрует только группы заказчиков, имеющие не более трех заказов
- SELECT: для остальных групп запрос возвращает идентификатор customer ID заказчика и число заказов, назначая столбцу имя numorders.
- Запрос представляет строку результатов, сортированную по numorders.
В листинге 2 приведен сложный тестовый запрос.
Пока я рекомендую распечатать и простой, и сложный запросы и держать их под рукой при чтении следующих статей серии.
Что дальше
Понимание логической обработки запросов — ключ к разработке производительного кода SQL. Кроме того, чрезвычайно важно понимать определенные ограничения языка и уметь искать обходные пути. В следующих статьях серии мы углубимся в подробности, рассматривая отдельные предложения. А пока предлагаю вам домашнее задание — ответить на следующие вопросы:
- В чем разница между предложением ON и предложением WHERE?
- Существует ли гарантия, что выражения в предложении WHERE будут вычисляться в определенном порядке?
- Для чего служат NULL-значения и какие сложности они вносят в язык?
- При объединении таблицы с производной таблицей может ли запрос к производной таблице ссылаться на столбцы из другой таблицы в объединении и почему?
- Можно ли использовать псевдоним столбца, который был определен в предложении SELECT, в предложении WHERE и почему?
- Можно ли использовать псевдоним, который был определен в предложении SELECT, в других выражениях в предложении SELECT и почему?
- Можно ли использовать псевдоним, который был определен в предложении SELECT, в предложении ORDER BY и почему?
- Как сделать псевдоним столбца доступным для таких предложений, как WHERE, GROUP BY, HAVING, SELECT?
- В чем разница между природой результата запроса, когда в запросе имеется предложение ORDER BY представления и когда оно отсутствует?
- В чем разница между групповой агрегатной функцией и оконной агрегатной функцией?
- Если во внутреннем запросе присутствует предложение ORDER BY, гарантирован ли порядок представления внешнего запроса?
- Если в запросе отсутствует предложение ORDER BY представления, существуют ли какие-нибудь обстоятельства, при которых гарантирован порядок представления запроса?
Листинг 1. Простой тестовый запрос
SELECT C.custid, COUNT( O.orderid ) AS numorders FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid = O.custid WHERE C.country = N'Spain' GROUP BY C.custid HAVING COUNT( O.orderid ) <= 3 ORDER BY numorders;
Листинг 2. Сложный тестовый запрос
SELECT TOP (4) WITH TIES C.custid, A.custlocation, COUNT( DISTINCT O.orderid ) AS numorders, SUM( A.val ) AS totalval, SUM( A.val ) / SUM( SUM( A.val ) ) OVER() AS pct FROM Sales.Customers AS C LEFT OUTER JOIN ( Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON O.orderid = OD.orderid AND O.orderdate >= '20160101' ) ON C.custid = O.custid CROSS APPLY ( VALUES( CONCAT(C.country, N'.' + C.region, N'.' + C.city), OD.qty * OD.unitprice * (1 - OD.discount) ) ) AS A(custlocation, val) WHERE A.custlocation IN (N'Spain.Madrid', N'France.Paris', N'USA.WA.Seattle') GROUP BY C.custid, A.custlocation HAVING COUNT( DISTINCT O.orderid ) <= 3 ORDER BY numorders;