Аббревиатура AVX расшифровывается как Advanced Vector Extensions. Это наборы инструкций для процессоров Intel и AMD, идея создания которых появилась в марте 2008 года. Впервые такой набор был встроен в процессоры линейки Intel Haswell в 2013 году. Поддержка команд в Pentium и Celeron появилась лишь в 2020 году.
Прочитав эту статью, вы более подробно узнаете, что такое инструкции AVX и AVX2 для процессоров, а также — как узнать поддерживает ли процессор AVX.
AVX и AVX2 – что это такое
AVX/AVX2 — это улучшенные версии старых наборов команд SSE. Advanced Vector Extensions расширяют операционные пакеты со 128 до 512 бит, а также добавляют новые инструкции. Например, за один такт процессора без инструкций AVX будет сложена 1 пара чисел, а с ними — 10. Эти наборы расширяют спектр используемых чисел для оптимизации подсчёта данных.
Наличие у процессоров поддержки AVX весьма желательно. Эти инструкции предназначены, прежде всего, для выполнения сложных профессиональных операций. Без поддержки AVX всё-таки можно запускать большинство игр, редактировать фото, смотреть видео, общаться в интернете и др., хотя и не так комфортно.
Как узнать, поддерживает ли процессор AVX
Далее будут показаны несколько простых способов узнать это. Некоторые из методов потребуют установки специального ПО.
1. Таблица сравнения процессоров на сайте Chaynikam.info.
Для того чтобы узнать, поддерживает ли ваш процессор инструкции AVX, можно воспользоваться предлагаемым способом. Перейдите на этот сайт. В правом верхнем углу страницы расположена зелёная кнопка Добавить процессор. Нажмите её.
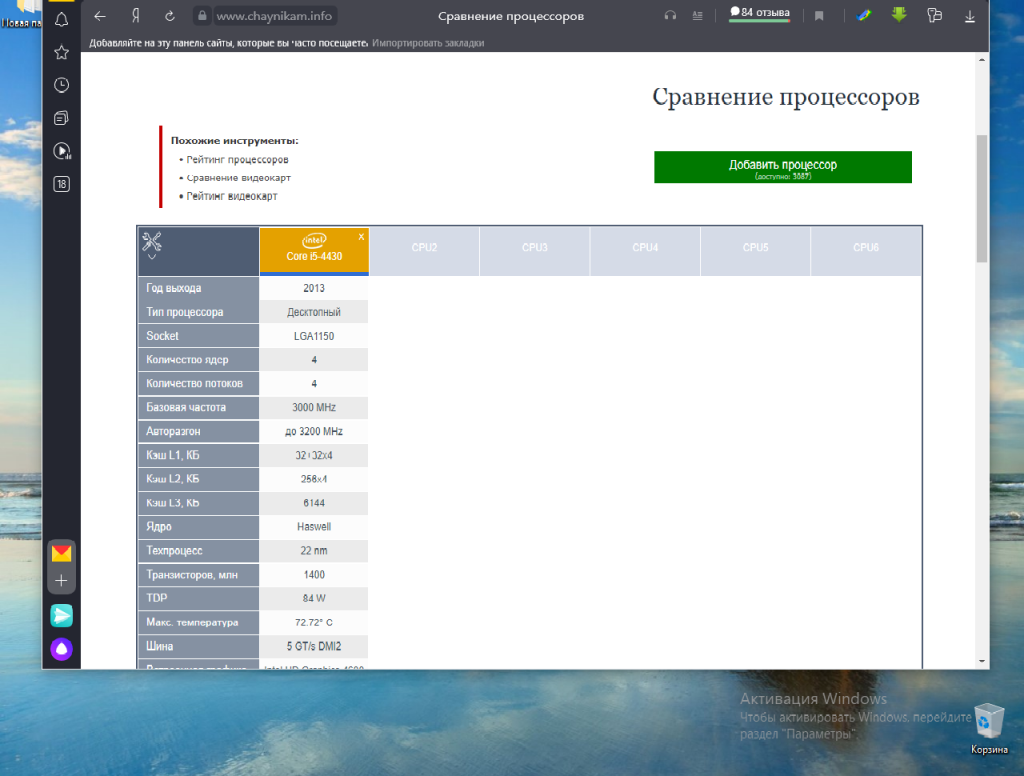
В открывшемся окне вам будет предложено указать параметры выбора нужного процессора. Все указывать не обязательно.
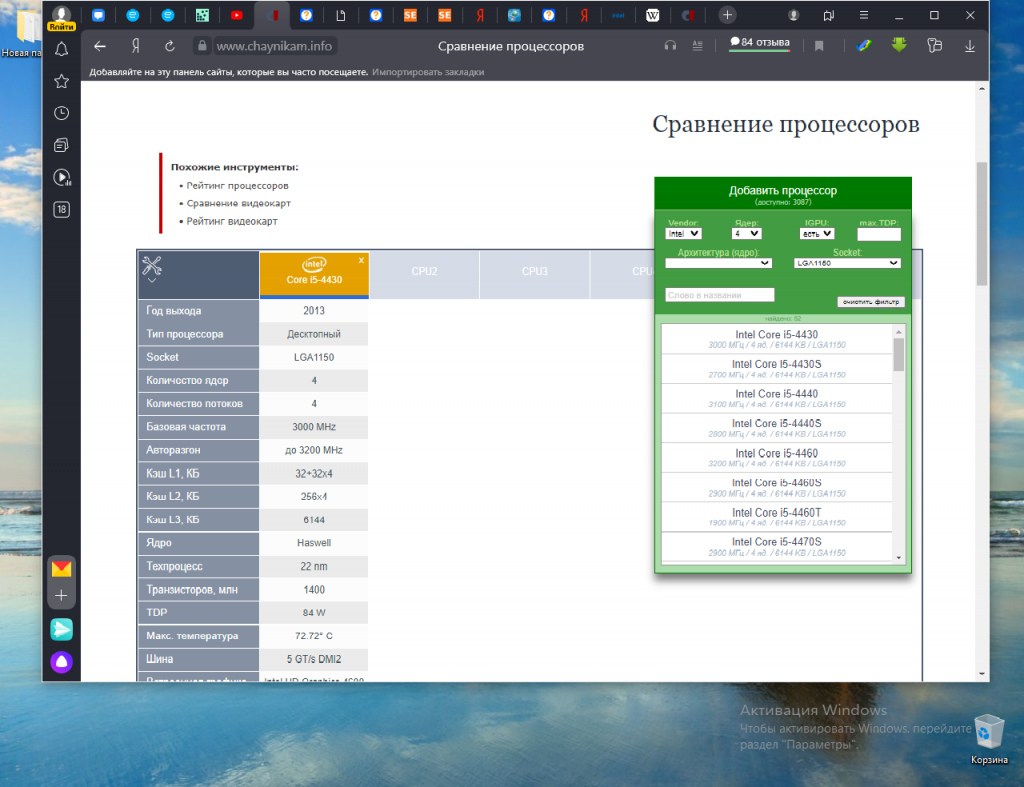
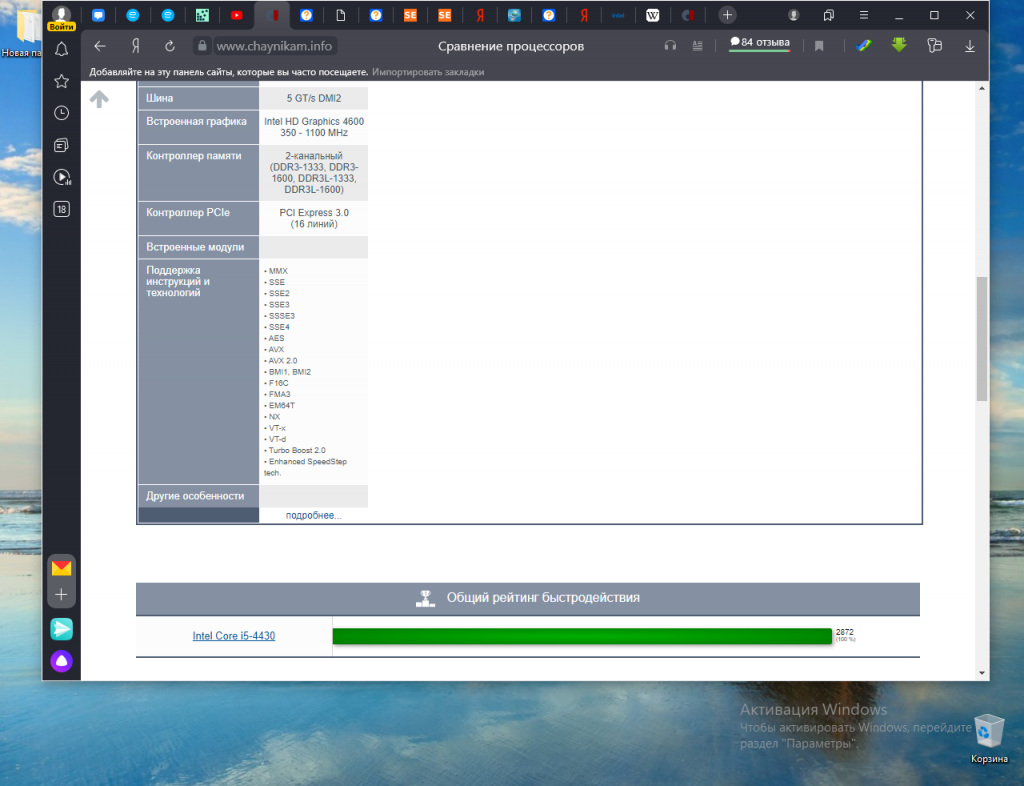
В результате выполнения поиска будет сформирована таблица с параметрами выбранного из списка процессора. Прокрутите таблицу вниз. В строке Поддержка инструкций и технологий будет показана подробная информация.
2. Утилита CPU-Z.
Один из самых простых и надёжных способов узнать поддерживает ли процессор AVX инструкции, использовать утилиту для просмотра информации о процессоре — CPU-Z. Скачать утилиту можно на официальном сайте. После завершения установки ярлык для запуска утилиты появится на рабочем столе. Запустите её.
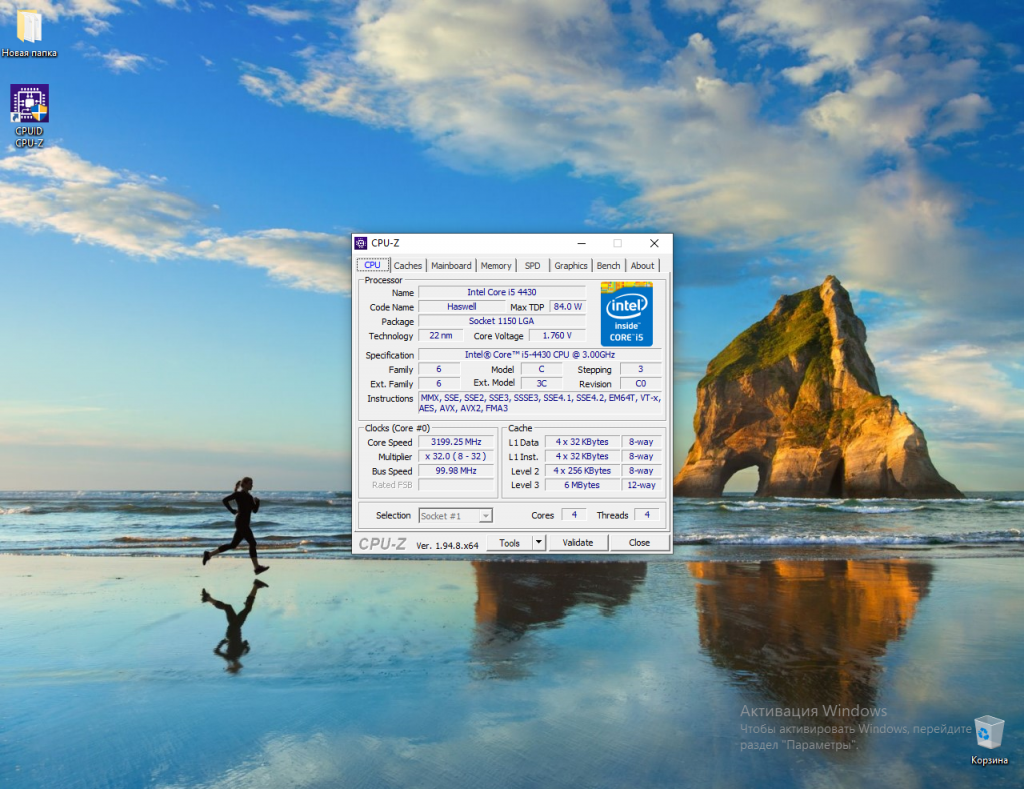
В строке Instructions показаны все инструкции и другие технологии, поддерживаемые вашим процессором.
3. Поиск на сайте производителя.
Ещё один способ узнать, есть ли AVX на процессоре, воспользоваться официальным сайтом производителя процессоров. В строке поиска браузера наберите название процессора и выполните поиск. Если у вас процессор Intel, выберите соответствующую страницу в списке и перейдите на неё. На этой странице вам будет предоставлена подробная информация о процессоре.
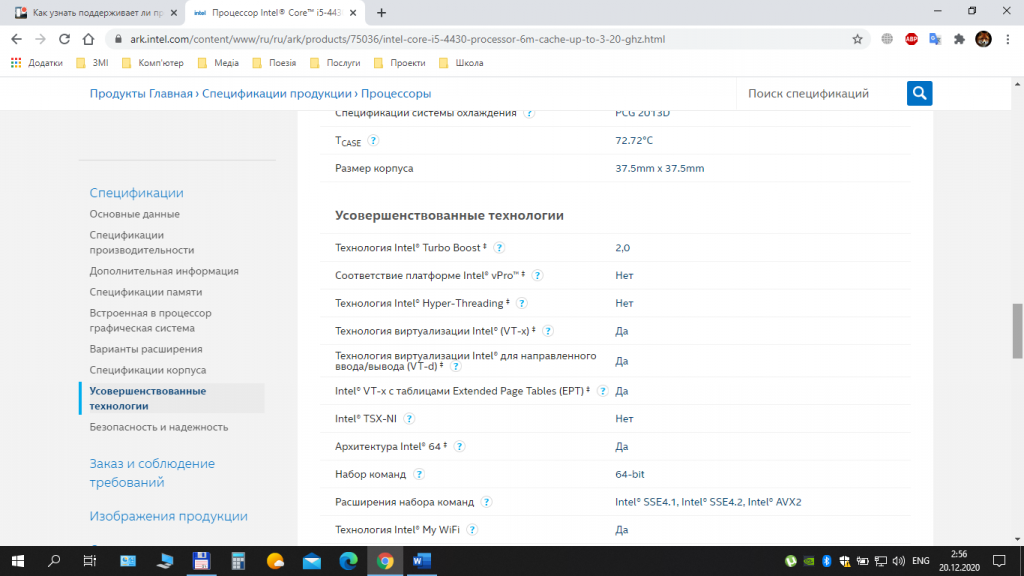
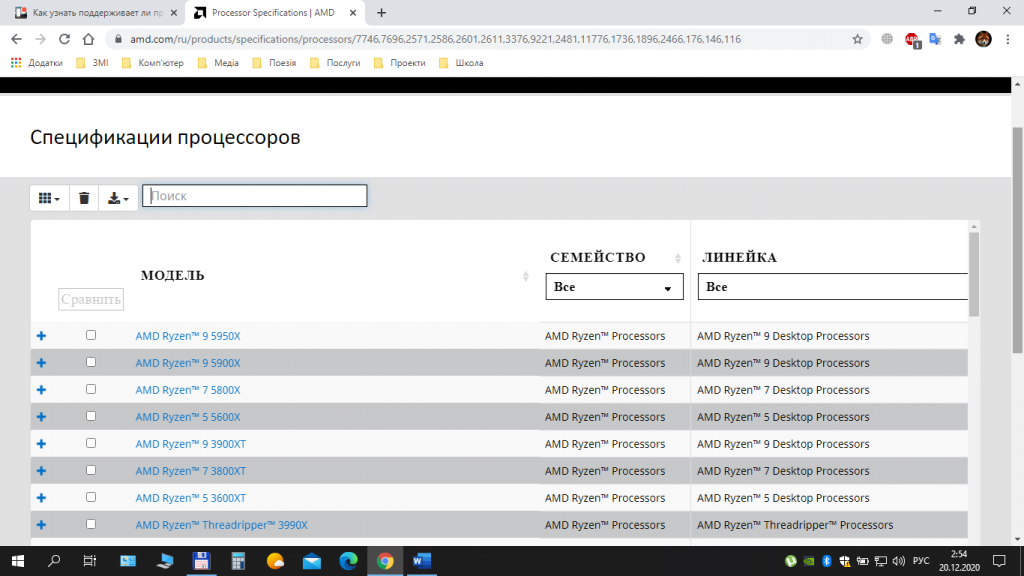
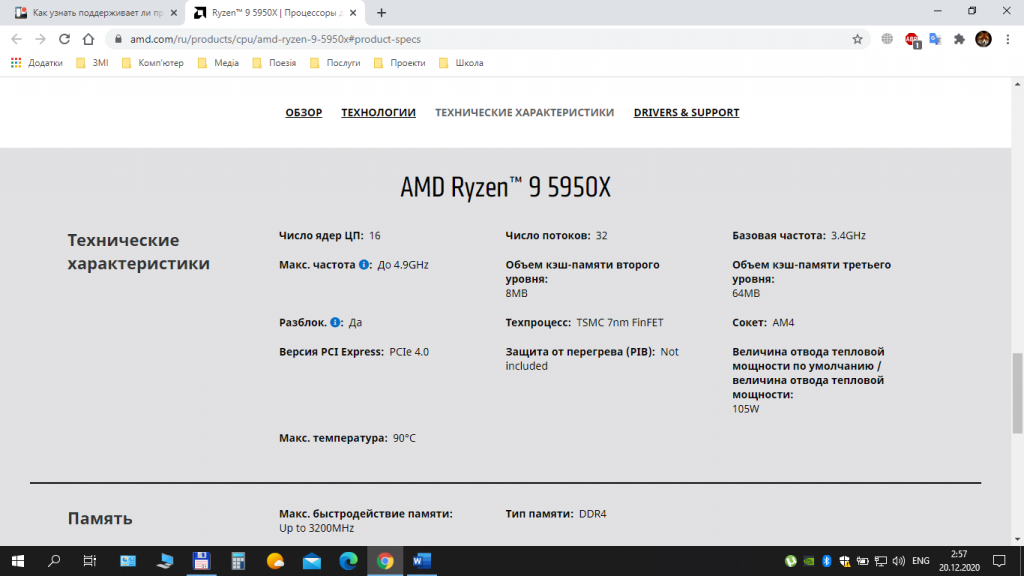
Если у вас процессор от компании AMD, то лучше всего будет воспользоваться сайтом AMD. Выберите пункт меню Процессоры, далее — пункт Характеристики изделия и затем, выбрав тип (например, Потребительские процессоры), выполните переход на страницу Спецификации процессоров. На этой странице выполните поиск вашего процессора по названию и посмотрите подробную информацию о нём.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.
Была ли эта статья полезной?
ДаНет
Оцените статью:
 (8 оценок, среднее: 5,00 из 5)
(8 оценок, среднее: 5,00 из 5)
![]() Загрузка…
Загрузка…
Об авторе

Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.
В мире компьютерных технологий нет ничего странного в обилии всевозможных аббревиатур: CPU, GPU, RAM, SSD, BIOS, CD-ROM, и многих других. И почти каждый день появляются всё новые и новые сокращения названий каких-то технологий, что является неизбежным следствием бесконечного стремления инженеров улучшить функции и возможности наших вычислительных устройств.
Сегодня речь пойдёт о таких расширениях набора команд процессоров, как MMX, SSE и AVX. Многим знакомы эти сокращения, и мы выясним, действительно ли это какие-то интересные разработки, или же это не более чем бессмысленные маркетинговые уловки.
Ну о-о-очень первые дни
Середина 80-х прошлого столетия. Рынок процессоров был очень похож на сегодняшний. Intel бесспорно преобладала, но столкнулась с жесткой конкуренцией со стороны AMD. Домашние компьютеры, такие как Commodore 64, использовали базовые 8-битные процессоры, тогда как настольные ПК начинали переходить с 16-битных на 32-битные чипы.
Эти числа означают размер значений данных, которые могут быть обработаны математически, при этом чем выше эти значения, тем выше точность и возможности. Они также определяет размер основных регистров в микросхеме: небольших участков памяти, используемых для хранения рабочих данных.
Такие процессоры являются также скалярными и целочисленными. Что это означает? Скаляр – это когда над одним элементом данных выполняется только одна любая математическая операция. Обычно это обозначается как SISD (single instruction, single data, «одиночный поток команд – одиночный поток данных»).
Таким образом, инструкция по сложению двух значений данных просто обрабатывается для этих двух чисел. А если вам, например, нужно прибавить одно и то же значение к группе из 16 чисел, то для этого потребуется выполнить все 16 наборов инструкций – для каждого числа из этой группы по отдельности. По-другому процессоры тех лет складывать ещё не умели.

Intel 80386DX с частотой 16МГц (1985).
Целое (Integer) – в математике, это такое число, которое не имеет дробной части. Например, 8 или -12. Процессоры типа интеловского 80386SX не имели врожденной способности сложить, скажем, 3.80 и 7.26 – такие дробные числа называются числами с плавающей точкой (или запятой, в русском языке это без разницы) – по-английски FP, floating point или просто floats. Чтобы справиться с ними, нужен был другой процессор, например 80387SX, и отдельный набор инструкций – список команд, который сообщает процессору, что делать.
В те времена под инструкциями x86 понимали наборы команд для целочисленных (integer) операций, а под инструкциями x87 – для чисел с плавающей точкой (float). В наши дни все операции умеет выполнять один процессор, поэтому мы используем термин x86 для обозначения набора инструкций обоих типов данных.
Использование отдельных сопроцессоров для обработки разных типов данных было нормой, пока Intel не представила 80486: их первый CPU для персоналок со встроенным математическим сопроцессором для обработки вещественных данных (FPU, Floating Point Unit).

Intel 80486: Жёлтым цветом выделен блок FPU для обработки чисел с плавающей точкой.
Как вы можете видеть, этот блок совсем немного занимает места в процессоре, но рывок в производительности, благодаря этому решению, был огромен.
Но в целом принцип работы оставался скалярным, и таким он перешел и к преемнику 486-го: оригинальному Intel Pentium.
И пройдёт ещё три года после релиза этого первого Пентиума, прежде чем Intel представит миру Pentium MMX. Это произошло в октябре 1996 года.
V – значит «векторный». А MMX что значит?
В мире математики числа можно группировать в наборы различных видов и размеров – одна такая упорядоченная совокупность называется арифметическим вектором. Проще всего представить его себе в виде списка значений, расположенных горизонтально или вертикально. Технология MMX привнесла в мир процессоров возможность выполнять векторные математические вычисления.
Однако она была изначально довольно ограниченной, поскольку оперировала только целыми числами и фактически эксплуатировала для своих целей регистры FPU. Поэтому программисты, желающие использовать какие-то инструкции MMX, вынуждены иметь в виду, что при выполнении таких инструкций любые вычисления с плавающей запятой не могут выполняться одновременно с ними.
Знаменитая реклама технологии Intel MMX (1997).
FPU Pentium имел 64-битные регистры, и в операциях MMX каждый из них мог вместить два 32-битных, четыре 16-битных или восемь 8-битных целых числа. Именно эти группы чисел и являются векторами, и каждая инструкция, предназначенная для них, будет выполняться сразу над всеми значениями в группе.
Такой принцип получил название SIMD (single instruction, multiple data, «одиночный поток команд, множественный поток данных») и знаменует собой большой шаг вперед в развитии возможностей процессоров для персональных компьютеров.
Ну а какие приложения выигрывают от использования такого принципа? Практически все, которым приходится выполнять одинаковые вычисления над группой однородных данных, и в первую очередь это некоторые функции в 3D-моделировании и мультимедийных технологиях, а также в системах обработки стандартных сигналов.
Например, MMX можно применить для ускорения умножения матриц при обработке вершин в 3D, или для смешивания видеопотоков при работе с хромакеем или альфа-композитингом.

Процессор AMD K6-2 – где-то там есть 3DNow!
К сожалению, внедрение MMX продвигалось довольно медленными темпами из-за негативного влияния этой технологии на производительность операций с плавающей точкой. AMD частично решила эту проблему, создав свою собственную версию под названием 3DNow! примерно через два года после появления MMX. Технология от AMD предлагала больше инструкций SIMD и умела обрабатывать числа с плавающей точкой, но также страдала от недостатка понимания программистами.
Ах, да! Как же официально расшифровывается аббревиатура MMX? Согласно Intel – никак!
Проще пареной SSE
Ситуация переломилась в лучшую сторону с приходом в 1999 году процессора Intel Pentium III. Он принёс с собой блестящую реализацию векторной функции под названием SSE (Streaming SIMD Extensions, «потоковые расширения SIMD»). На этот раз это был дополнительный набор из восьми 128-битных регистров, отдельных от регистров в FPU, и стек дополнительных инструкций для обработки чисел с плавающей точкой.
Использование независимых регистров означает, что больше нет такой сильной зависимости от FPU, хотя Pentium III не мог выполнять инструкции SSE одновременно с инструкциями FP. А также, новая функция поддерживает только один тип данных в регистрах: четыре 32-битных FP-числа.
Но переход к использованию FP-инструкций SIMD позволил значительно увеличить производительность в таких приложениях, как кодирование/декодирование видео, обработка изображений и звука, сжатие файлов и многих других.

Pentium IV: желтым цветом выделен блок регистров SSE2.
Усовершенствованная версия SSE2 появилась в 2001 году вместе с Pentium 4, и на этот раз поддержка типов данных была намного лучше: четыре 32-битных или два 64-битных FP-числа, а также шестнадцать 8-битных, восемь 16-битных, четыре 32-битных или два 64-битных целых числа. Регистры MMX остались в процессоре, но все операции MMX и SSE могли выполняться с использованием независимых 128-битных регистров SSE.
Модификация SSE3 появилась на свет в 2003 году, имея больше инструкций и возможность выполнять некоторые математические вычисления между значениями внутри одного регистра.
Ещё через 3 года мы познакомились с архитектурой Intel Core, принёсшей ещё одну ревизию технологии SIMD (SSSE3 – Supplemental SSE, «расширенные SSE»), и чуть позже в том же году – финальную версию, SSE4.

В 2007 году AMD применила собственную версию расширений CPU-инструкций SSE4 в своей архитектуре Barcelona. С названием в AMD париться не стали, и назвали свою версию просто SSE4a.
С линейкой Nehalem Core в 2008 году было выпущено незначительное обновление этой версии, которую Intel обозначила как SSE4.2 (а под SSE4.1 стали понимать исходную версию этого обновления). Обновления не затронули регистры, а лишь добавили больше инструкций в таблицу, расширив диапазон возможных математических и логических операций.
AMD, со своей стороны, сперва предложила новую версию SSE5, но позже решила разделить ее на три отдельных расширения, одно из которых довольно проблемное – подробнее об этом чуть позже.
К концу 2008 года и Intel, и AMD поставляли процессоры, которые уже могли обрабатывать все версии наборов инструкций от MMX до SSE4.2, и многие приложения (в основном игры) начали требовать этих функций для работы.
Время для новых букв
2008 год также был годом, когда Intel объявила о том, что они работают над значительным апгрейдом своей системы SIMD, и в 2011 году выкатила линейку процессоров Sandy Bridge с поддержкой набора инструкций AVX (Advanced Vector Extensions, «продвинутые векторные расширения»).
Всё удвоилось: вдвое больше векторных регистров и вдвое больше их размер.
Шестнадцать 256-битных регистров вмещают только восемь 32-битных или четыре 64-битных вещественных числа, поэтому в плане форматов данных, этот набор инструкций более ограничен в сравнении с SSE, но ведь и SSE никто не отменял. К тому времени программная поддержка векторных операций для CPU была уже хорошо отлажена, начиная с фундаментального мира компиляторов, заканчивая сложными приложениями.

Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.


 2-ядерный Intel Skylake
2-ядерный Intel Skylake















