По материалам MSDN
Статья представляет собой краткий справочник по использованию утилит командной строки для репликации MS SQL Server 2000.
Одну из ведущих ролей в репликации MS SQL Server играют агенты, которые являются утилитами командной строки. В данной статье мы рассмотрим четыре агента репликации: distrib.exe — Replication Distribution Agent, snapshot.exe — Replication Snapshot Agent, replmerg.exe — Replication Merge Agent и logread.exe — Replication Log Reader Agent.
Обычно, все эти четыре утилиты можно найти в каталоге C:Program FilesMicrosoft SQL Server80COM . Для того, что бы посмотреть параметры их вызова, необходимо запустить соответствующие исполняемые файлы с ключом «-?». На Вашем экране будет представлен синтаксис их запуска и перечень возможных ключей. Эта информация собрана в находящейся ниже по тексту таблице.
Merge Replication Dynamic
Snapshot Parameters:
Обратите внимание : Параметры могут быть определены в любом порядке. Когда дополнительные параметры не определены, используются значения предопределенных параметров в системном реестре локального компьютера.
Утилита Replication Distribution Agent получает конфигурацию и запускает Distribution Agent, который перемещает снимок (для репликации снимков и репликации транзакций), определённый в таблицах базы данных дистрибутора (для репликации транзакций), в таблицы назначения подписчика. Distribution Agent запускается для каждой публикации и исполняется на подписчике при pull-подписке, а при push-подписке, он работает на дистрибуторе.
Если Вы запускаете службу SQL Server Agent под учетной записью локальной системы (значение по умолчанию), а не под учетной записью пользователя домена, служба сможет обращаться только к локальному компьютеру. Если Distribution Agent, работа которого управляется SQL Server Agent, будет при этом использовать для доступа к экземпляру SQL сервера Windows Authentication Mode, Distribution Agent не сможет работать. Параметр по умолчанию — SQL Server Authentication.
Утилита Replication Snapshot Agent получает конфигурацию и запускает Snapshot Agent, который готовит файлы снимка, содержащие схему (метаданные) и данные изданных таблиц и объектов базы данных, сохраняет файлы в папке моментальных снимков и создаёт синхронизирующее по расписанию задание в базе данных дистрибутора. Кроме того, Snapshot Agent фиксирует информацию о состоянии синхронизации в базе данных дистрибутора. Самостоятельно Snapshot Agent не занимается распространением созданных им снимков. При репликации снимками, этот агент запускается настолько часто, на сколько необходимо обеспечить приемлемую периодичность обеспечения синхронности подписанных баз данных. Для репликации транзакций или слиянием он может обновляться реже, вплоть до того момента, когда возникнет необходимость подключения нового подписчика.
Утилита Replication Merge Agent получает конфигурацию и запускает Merge Agent, который применяет первоначальный, моментальный снимок, указанный в таблицах базы данных подписчика. Также он обеспечивает репликацию слиянием инкрементных изменений данных, которые произошли на издателе после создания первоначального снимка или последнего сеанса синхронизации, и урегулирует конфликты согласно установленных Вами правил или с использованием Вашего самодельного резольвера.
Для репликации слиянием Merge Agent исполняет ещё и роли Distribution Agent и Snapshot Agent, которые при таком виде репликации не используются.
Утилита Replication Log Reader Agent получает конфигурацию и запускает Log Reader Agent, который контролирует журнал регистрации транзакций каждой базы данных, указанной для репликации, и копирует транзакции, отмеченные для репликации из журнала транзакций в базу данных дистрибутора. При репликации транзакций, на издателе запускается свой Log Reader Agent для каждой базы данных, использующей этот вид репликации.
Transact-SQL — изменение и удаление данных

Инструкция UPDATE используется для модифицирования строк таблицы. Эта инструкция имеет следующую общую форму:
Строки таблицы tab_name выбираются для изменения в соответствии с условием в предложении WHERE. Значения столбцов каждой модифицируемой строки изменяются с помощью предложения SET инструкции UPDATE, которое соответствующему столбцу присваивает выражение (обычно) или константу. Если предложение WHERE отсутствует, то инструкция UPDATE модифицирует все строки таблицы. С помощью инструкции UPDATE данные можно модифицировать только в одной таблице.
В примере ниже инструкция UPDATE изменяет всего лишь одну строку таблицы Works_on, поскольку комбинация столбцов EmpId и ProjectNumber является первичным ключом этой таблицы и, следственно, она однозначна. В данном примере изменяется должность сотрудника, значение которого было ранее неизвестно или имело значение NULL:
В примере ниже значения строкам таблицы присваиваются посредством выражения. Запрос пересчитывает бюджеты всех проектов с долларов на евро:
В данном примере изменяются все строки таблицы Project, поскольку в запросе отсутствует предложение WHERE.
В примере ниже в предложении WHERE инструкции UPDATE используется вложенный запрос. Поскольку применяется оператор IN, то этот запрос может возвратить более одной строки:
Согласно этому запросу, для сотрудницы Вершининой Натальи во всех ее проектах в столбце ее должности присваивается значение NULL. Запрос в этом примере можно также выполнить посредством предложения FROM инструкции UPDATE. В предложении FROM указываются имена таблиц, которые обрабатываются инструкцией UPDATE. Все эти таблицы должны быть в дальнейшем соединены. Применение предложения FROM показано в примере ниже. Логически, этот пример идентичен предыдущему:
В примере ниже показано использование выражения CASE в инструкции UPDATE. (Подробное рассмотрение этого выражения описывалось ранее.) В данном примере нужно увеличить бюджет всех проектов на определенное число процентов (20, 10 или 5), в зависимости от исходной суммы бюджета: чем меньше бюджет, тем больше должно быть его процентное увеличение:
Инструкция DELETE
Инструкция DELETE удаляет строки из таблицы. Подобно инструкции INSERT, эта инструкция также имеет две различные формы:
Удаляются все строки, которые удовлетворяют условие в предложении WHERE. Явно перечислять столбцы в инструкции DELETE не то чтобы нет необходимости, а даже не разрешается, поскольку эта инструкция оперирует строками, а не столбцами. Использование первой формы инструкции DELETE показано в примере ниже, в котором происходит удаление из таблицы Works_on всех сотрудников с должностью ‘Менеджер’:
Предложение WHERE инструкции DELETE может содержать вложенный запрос, как это показано в примере ниже:
Поскольку сотрудница Вершинина уволилась, из базы данных удаляются все записи, связанные с ней. Запрос из этого примера можно также выполнить с помощью предложения FROM, как это показано ниже. В данном случае семантика этого предложения такая же, как и предложения FROM в инструкции UPDATE.
Использование предложения WHERE в инструкции DELETE не является обязательным. Если это предложение отсутствует, то из таблицы удаляются все строки:
Инструкции DELETE и DROP TABLE существенно отличаются друг от друга. Инструкция DELETE удаляет (частично или полностью) содержимое таблицы, тогда как инструкция DROP TABLE удаляет как содержимое, так и схему таблицы. Таким образом, после удаления всех строк посредством инструкции DELETE таблица продолжает существовать в базе данных, а после выполнения инструкции DROP TABLE таблица больше не существует.
Другие инструкции и предложения Transact-SQL для модификации таблиц
Сервер SQL Server поддерживает следующие дополнительные инструкции и предложения для модификации таблиц:
инструкцию TRUNCATE TABLE;
Эти инструкции и предложение рассматриваются в последующих подразделах.
Инструкция TRUNCATE TABLE
Инструкция TRUNCATE TABLE является более быстрой версией инструкции DELETE без предложения WHERE. Эта инструкция удаляет все строки таблицы более быстро, чем инструкция DELETE, поскольку она удаляет содержимое постранично, тогда как инструкция DELETE делает это построчно. Инструкция TRUNCATE TABLE является расширением Transact-SQL стандарта SQL. Еще одним важным отличием этой инструкции является то, что она сбрасывает индекс столбца, для которого указано свойство автоинкремента IDENTITY.
Инструкция TRUNCATE TABLE имеет следующий синтаксис:
Инструкция MERGE
Инструкция MERGE объединяет последовательность инструкций INSERT, UPDATE и DELETE в одну элементарную инструкцию, в зависимости от существования записи (строки). Иными словами, можно синхронизировать две разные таблицы, чтобы модифицировать содержимое таблицы назначения в зависимости от различий, обнаруженных в таблице-источнике.
Основной областью применения для инструкции MERGE является среда хранилищ данных, где таблицы необходимо периодически обновлять, чтобы отражать новые данные, прибывающие с систем оперативной обработки транзакций OLTP (On-Line Transaction Processing). Эти данные могут содержать изменения существующих строк таблиц и/или новый строки, которые нужно вставить в таблицы. Если строка в новых данных соответствует записи, которая уже имеется в таблице, выполняется инструкция UPDATE или DELETE. В противном случае выполняется инструкция INSERT.
Альтернативно, вместо инструкции MERGE можно использовать последовательность инструкций INSERT, UPDATE и DELETE, в которых для каждой строки решается, какую операцию выполнять: вставку, удаление или обновление. Но этот подход имеет значительный недостаток, связанный с производительностью: в нем требуется выполнять несколько проходов по данным, а данные обрабатываются по принципу «запись за записью».
Предложение OUTPUT
По умолчанию единым видимым результатом выполнения инструкции INSERT, UPDATE или DELETE является только сообщение о количестве модифицированных строк, например «3 rows DELETED» (удалены 3 строки) и система не сохраняет информацию о модифицированных данных. Если такой видимый результат не удовлетворяет вашим требованиям, то можно использовать предложение OUTPUT, которое выводит модифицированные, вставленные или удаленные строки.
Предложение OUTPUT также применимо с инструкцией MERGE, для которой оно выводит все модифицированные строки в виде таблицы.
Результаты выполненных операций соответствующих инструкций предложение OUTPUT выводит в таблицах inserted и deleted. Кроме этого, чтобы заполнить таблицы, в предложении OUTPUT требуется использовать выражение INTO. Поэтому для сохранения результата используется табличная переменная.
В примере ниже показано использование инструкции OUTPUT с инструкцией DELETE:
При условии, что содержимое таблицы находится в исходном состоянии, выполнение запроса в примере дает следующий результат:

В этом примере сначала объявляется табличная переменная @deleteTable с двумя столбцами: Id и LastName. В этой таблице будут сохранены удаленные строки. Синтаксис инструкции DELETE расширен предложением OUTPUT: «OUTPUT deleted.Id, deleted.LastName INTO @deleteTable». Посредством этого предложения система сохраняет удаленные строки в таблице deleted, содержимое которой потом копируется в переменную @deleteTable.
В примере ниже показано использование предложения OUTPUT в инструкции UPDATE:
Как удалить репликацию ms sql
Профиль
Группа: Участник
Сообщений: 642
Регистрация: 17.5.2006
Репутация: нет
Всего: 8
Возможно ли создать репликацию между этими двумя базами?
P.S Если нет, то я пробовал слинковать MS ACESS c MS SQL. Беда была в том, что в MS SQL я не смог создовать процедуры, так как в MS ACCESS названия таблиц на русском языке. И выдавалась какая то ошибка ANSI. Я думаю спецы могут знать что это за ошибка.
Профиль
Группа: Завсегдатай
Сообщений: 1330
Регистрация: 24.2.2005
Где: Орёл
Репутация: 2
Всего: 44
Профиль
Группа: Участник
Сообщений: 642
Регистрация: 17.5.2006
Репутация: нет
Всего: 8
Как только не пробовал
| distrib.exe [-?] | snapshot.exe [-?] | replmerg.exe [-?] | logread.exe [-?] |
| Код |
| CREATE PROCEDURE dbo.ZvkList AS SELECT * FROM ACCESSDB. [Заявки] |
| Код |
| CREATE PROCEDURE dbo.ZvkList AS SELECT * FROM ACCESSDB. «Заявки» |
| Код |
| CREATE PROCEDURE dbo.ZvkList AS SELECT * FROM «ACCESSDB. Заявки» |
«Check Syntax» проходит на ура, а вот если жму на кнопку OK , то выскакивает
| Цитата |
| Error 7475: Heterogeneous queries require the ANSI_NULLS and ANSI_WARNINGS options to be set for the connection. This ensures consistent query semantics. Enable these options and then reissue your query. |
В свойствах сервера выставлял галки ANSI_NULLS и ANSI_WARNINGS. Не помогло.
Профиль
Группа: Завсегдатай
Сообщений: 1330
Регистрация: 24.2.2005
Где: Орёл
Репутация: 2
Всего: 44
Профиль
Группа: Участник
Сообщений: 642
Регистрация: 17.5.2006
Репутация: нет
Всего: 8
Профиль
Группа: Завсегдатай
Сообщений: 1330
Регистрация: 24.2.2005
Где: Орёл
Репутация: 2
Всего: 44
| Цитата(HappyLife @ 7.9.2007, 13:55 ) |
| DimW, нет, эти самые точки означают что база данных слинкованная а не локальная. Это синтаксис MS SQL |
сори, кто бы мог подумать
Профиль
Группа: Модератор
Сообщений: 20541
Регистрация: 8.4.2004
Где: Зеленоград
Репутация: 13
Всего: 453
О(б)суждение моих действий — в соответствующей теме, пожалуйста. Или в РМ. И высшая инстанция — Администрация форума.
Данный форум предназначен для обсуждения вопросов о базах данных не попадающих под тематику других форумов:
- вопросам по СУБД для которых нет отдельных подфорумов
- вопросам которые затрагивают несколько разных СУБД (например проблема выбора)
- инструменты для работы с СУБД
- вопросы проектирования БД
- теоретически вопросы о СУБД
Данный форум не предназначен для:
- вопросов о поиске разлиных БД (если не понимаете чем БД отличается от СУБД то: а) вам не сюда; б) Google в помощь)
- обсуждения проблем с доступом к СУБД из различных ЯП (для этого есть соответсвующие форумы по каждому ЯП)
- обсуждения проблем с написание SQL запросов, для этого есть форум Составление SQL-запросов
- просьб о написании курсовой, реферата и т.п., для этого есть Центр помощи или фриланс биржа
- объявлений о найме специалистов, для этого есть раздел Объявления о найме специалистов
Если вы не соблюдаете эти правила, не удивляйтесь потом не найдя свою тему/сообщение.
Полезные советы:
При написании сообщения постарайтесь дать теме максимально понятное название. В теме максимально подробно опишите проблему. Если применимо укажите: название базы данных и версии (MySQL 4.1, MS SQL Server 2000 и т.п.); используемых язык программирования; способа доступа (ADO, BDE и т.д.); сообщения об ошибках.
Для вставки кода используйте теги [code=sql] [/code].
Литературу по базам данных можно поискать здесь.
Действия модераторов можно обсудить здесь.
Если Вам понравилась атмосфера форума, заходите к нам чаще! С уважением, LSD, Zloxa.
| 0 Пользователей читают эту тему (0 Гостей и 0 Скрытых Пользователей) |
| 0 Пользователей: |
| « Предыдущая тема | СУБД, общие вопросы | Следующая тема » |
[ Время генерации скрипта: 0.1090 ] [ Использовано запросов: 21 ] [ GZIP включён ]
Как удалить репликацию ms sql
Скрипт SQL Server для удаления репликации?
Меня попросили написать сценарий SQL, который можно запустить, чтобы остановить репликацию и удалить подписчика/подписку.
Это вообще возможно? Или вам нужно использовать графический интерфейс?
Ответы

Какую версию SQL Server вы используете.
Google также предоставляет статью MSDN в результатах
Как отключить публикацию и распространение (программирование репликации на языке Transact-SQL) — http://msdn.microsoft.com/en-us/library/ms147921.aspx

Если вы хотите полностью удалить репликацию, включая все «биты». Или на вашем сервере есть только одна публикация, которую вы пытаетесь удалить.
Я бы порекомендовал:
- Подключитесь к издателю или распространителю, который вы хотите отключить в Microsoft SQL Server Management Studio, а затем разверните узел сервера.
- Щелкните правой кнопкой мыши папку «Репликация» и выберите «Отключить публикацию и распространение».
- Выполните действия, описанные в мастере отключения публикации и распространения, и вместо обработки выберите параметр для создания сценариев .
Преимущество этого заключается не только в полной очистке вещей. Но также удаление базы данных распространителя, которая, если вы когда-либо имели дело раньше, как известно, засорена остатками прошлых репликаций.
Полную документацию можно найти здесь .

и используйте номер процесса, чтобы убить его, как показано ниже: kill 65
Связанные вопросы
Добавить столбец со значением по умолчанию в существующую таблицу в SQL Server
Вставить результаты хранимой процедуры во временную таблицу
SQL-запрос для выбора дат между двумя датами
Как я могу выполнить инструкцию UPDATE с JOIN в SQL Server?
Перед созданием временной таблицы проверьте, существует ли временная таблица, и удалите, если она существует.
О чем данный учебник
Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется при работе с базами данных наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды (IDE) для работы с базой данных, и нет надобности изучать визуальный инструментарий заточенный для работы с конкретным типом баз данных (MS SQL, Oracle, MySQL, Firebird, …). Это удобно и тем, что весь текст находится перед глазами, и не нужно бегать по многочисленным вкладкам для того чтобы создать, например, индекс или ограничение. При постоянной работе с базой данных, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение). К тому же скрипты удобно использовать в случае, когда изменения, делаемые в одной базе данных (например, тестовой), необходимо перенести в таком же виде в другую базу (продуктивную).
Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
- DDL – Data Definition Language (язык описания данных)
- DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
Т.к. я являюсь практиком, как таковой теории в данном учебнике будет мало, и все конструкции будут объясняться на практических примерах. К тому же я считаю, что язык программирования, а особенно SQL, можно освоить только на практике, самостоятельно пощупав его и поняв, что происходит, когда вы выполняете ту или иную конструкцию.
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:

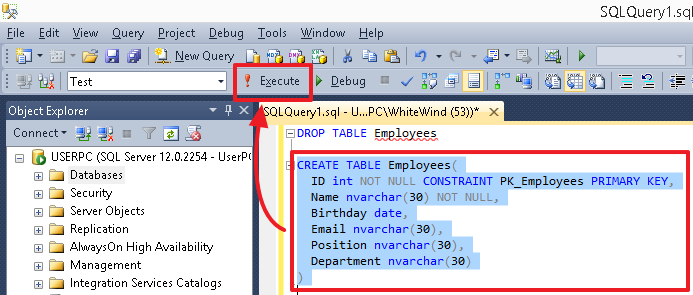
Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.
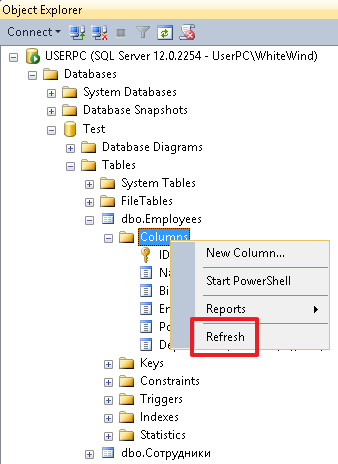
После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.
Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.
СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL — язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML — подмножество языка SQL:
- Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
- Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
-- однострочный комментарий
и
/*
многострочный
комментарий
*/
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:
| Табельный номер | ФИО | Дата рождения | Должность | Отдел | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | i.ivanov@test.tt | Директор | Администрация |
| 1001 | Петров П.П. | 03.12.1983 | p.petrov@test.tt | Программист | ИТ |
| 1002 | Сидоров С.С. | 07.06.1976 | s.sidorov@test.tt | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | 17.04.1982 | a.andreev@test.tt | Старший программист | ИТ |
В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
- Табельный номер – целое число
- ФИО – строка
- Дата рождения – дата
- E-mail – строка
- Должность – строка
- Отдел – строка
Тип столбца – характеристика, которая говорит о том какого рода данные может хранить данный столбец.
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
|---|---|---|
| Строка переменной длины | varchar(N) и nvarchar(N) |
При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30). Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта. Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N) и nchar(N) |
От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603 Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323 Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
CREATE DATABASE Test
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
DROP DATABASE Test
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
USE Test
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники](
[Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
[E-mail] nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30)
)
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
На заметку
В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники]
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
- ID – Табельный номер (Идентификатор сотрудника)
- Name – ФИО
- Birthday – Дата рождения
- Email – E-mail
- Position – Должность
- Department – Отдел
Очень часто для наименования поля идентификатора используется слово ID.
Теперь создадим нашу таблицу:
CREATE TABLE Employees(
ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
-- обновление поля ID
ALTER TABLE Employees ALTER COLUMN ID int NOT NULL
-- обновление поля Name
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
На заметку
Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.Чтобы не быть голословным, приведу несколько примеров тех же команд для СУБД ORACLE:
-- создание таблицы CREATE TABLE Employees( ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38) Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…)) ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:
NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символовКакая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
INSERT Employees(ID,Position,Department) VALUES
(1000,N'Директор',N'Администрация'),
(1001,N'Программист',N'ИТ'),
(1002,N'Бухгалтер',N'Бухгалтерия'),
(1003,N'Старший программист',N'ИТ')
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
DROP TABLE Employees
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Или просто:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).
Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение
)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID)
)
Или:
CREATE TABLE Employees(
ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:
- CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
- DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
- ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
- ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp(
ID int,
Name nvarchar(30)
)
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
DROP TABLE #Temp
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
SELECT ID,Name
INTO #Temp
FROM Employees
На заметку
В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.
Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
На заметку
В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
-- заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
То же самое проделаем для таблицы Departments:
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
SELECT * FROM Positions
| ID | Name |
|---|---|
| 1 | Бухгалтер |
| 2 | Директор |
| 3 | Программист |
| 4 | Старший программист |
SELECT * FROM Departments
| ID | Name |
|---|---|
| 1 | Администрация |
| 2 | Бухгалтерия |
| 3 | ИТ |
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
-- добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Теперь пропишем ссылки (ссылочные ограничения — FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
И то же самое сделаем для второго поля:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
Так же в некоторых случаях ссылку можно организовать по нескольким полям:
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
| ID | Name | Birthday | Position | Department | PositionID | DepartmentID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | Директор | Администрация | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | Программист | ИТ | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | Бухгалтер | Бухгалтерия | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | Старший программист | ИТ | 4 | 3 |
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position,Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
|---|---|---|---|
| 1000 | Иванов И.И. | Директор | Администрация |
| 1001 | Петров П.П. | Программист | ИТ |
| 1002 | Сидоров С.С. | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | Старший программист | ИТ |
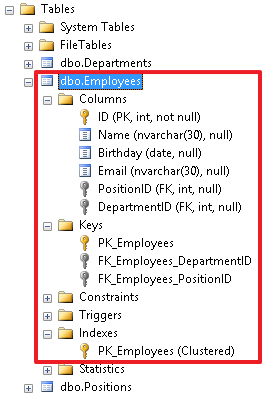
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.
Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:
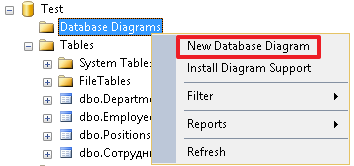
В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):
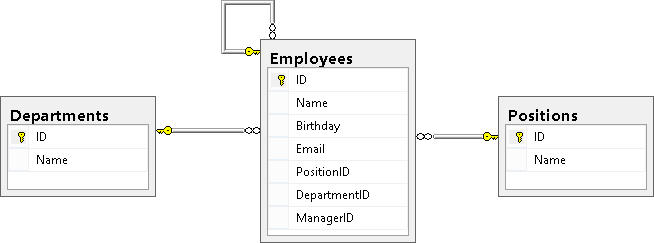
Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
)
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Удалим отдел с идентификатором 3 из таблицы Departments:
DELETE Departments WHERE ID=3
Посмотрим на данные таблицы Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments
SET
ID=30
WHERE ID=3
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N'ИТ')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
TRUNCATE TABLE Employees
И снова перезальем в нее данные используя предыдущую команду INSERT:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:
- Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
- ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
- ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY(поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:
UPDATE Employees SET Email='i.ivanov@test.tt' WHERE ID=1000
UPDATE Employees SET Email='p.petrov@test.tt' WHERE ID=1001
UPDATE Employees SET Email='s.sidorov@test.tt' WHERE ID=1002
UPDATE Employees SET Email='a.andreev@test.tt' WHERE ID=1003
А теперь можно наложить на это поле ограничение-уникальности:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Сергеев С.С.','s.sergeev@test.tt')
Посмотрим, что получилось:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | s.sergeev@test.tt | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees(ID,Email) VALUES(2000,'test@test.tt')
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
INSERT Employees(ID,Email) VALUES(1500,'test@test.tt')
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.
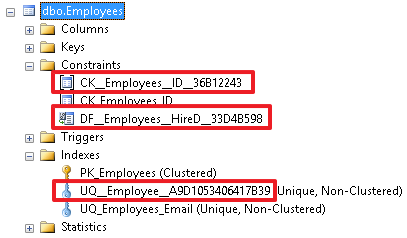
При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3)
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK_Employees и UQ_Employees_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
Для примера сделаем индекс ограничения PK_Employees некластерным, а индекс ограничения UQ_Employees_Email кластерным. Первым делом удалим данные ограничения:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ_Employees_Email:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
|---|---|---|---|---|---|---|
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:
- PRIMARY KEY – первичный ключ;
- FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
- UNIQUE – позволяет создать уникальность;
- CHECK – позволяет осуществлять корректность введенных данных;
- DEFAULT – позволяет задать значение по умолчанию;
- Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
Так же мы частично затронули тему индексов и разобрали понятие кластерный (CLUSTERED) и некластерный (NONCLUSTERED) индекс.
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.
Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1,NULL),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3,1003),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2,1000),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексов
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.
Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.
Главное — понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Часть вторая — habrahabr.ru/post/255523
Следующие примеры синтаксиса SQL поддерживаются ядром базы данных SQL в Adobe AIR. Примеры содержат объяснения разных типов инструкций и предложений, выражений, встроенных функций и операторов. Рассматриваются следующие темы:
Общий синтаксис SQL
|
|
AVG(X) |
Возвращает среднее значение всех ненулевых строк X в группе. Строковые значения и значения больших двоичных объектов (BLOB), которые не похожи на числа, интерпретируются как 0. Результатом функции AVG() всегда является значение с плавающей запятой, даже если все вводные числа являются целыми. |
|
COUNT(X) COUNT(*) |
Первая форма возвращает количество ненулевых строк X в группе. Вторая форма (с аргументом *) возвращает общее число строк в группе. |
|
MAX(X) |
Возвращает максимальное из всех значений в группе. Для определения максимального значения используется обычный порядок сортировки. |
|
MIN(X) |
Возвращает минимальное ненулевое значение из всех значений в группе. Для определения минимального значения используется обычный порядок сортировки. Если все значения в группе нулевые, возвращается значение NULL. |
|
SUM(X) TOTAL(X) |
Возвращает числовую сумму всех ненулевых значений в группе. Если все значения нулевые, функция SUM() возвращает NULL, а функция TOTAL() возвращает 0.0. Результат функции TOTAL() всегда является значением с плавающей запятой. Результат функции SUM() является целым числом, если все ненулевые значения являются целыми числами. Если любое число, переданное функции SUM(), не является целым и не равно нулю, то SUM() возвращает значение с плавающей запятой. Действительная сумма может быть округлена до приближенного значения. |
В любой предшествующей агрегатной функции, которая принимает один аргумент, перед этим аргументом может стоять ключевое слово DISTINCT. В таком случае повторяющиеся элементы отфильтровываются перед передачей результата следующей агрегатной функции. Например, вызов функции COUNT(DISTINCT x) возвращает число разных значений в столбце X, а не общее число ненулевых значений.
Скалярные функции
Скалярные функции выполняют операции со значениями только одной строки.
|
ABS(X) |
Возвращает абсолютное значение аргумента X. |
|
COALESCE(X, Y, …) |
Возвращает копию первого ненулевого аргумента. Если все аргументы нулевые, возвращается результат NULL. Должно быть не меньше двух аргументов. |
|
GLOB(X, Y) |
Эта функция служит для реализации синтаксиса X GLOB Y. |
|
IFNULL(X, Y) |
Возвращает копию первого ненулевого аргумента. Если оба аргумента нулевые, возвращается результат NULL. Эта функция действует аналогично COALESCE(). |
|
HEX(X) |
Аргумент интерпретируется как значение типа хранения BLOB. В качестве результата возвращается шестнадцатеричное представление содержимого этого значения. |
|
LAST_INSERT_ROWID() |
Возвращает идентификатор (сгенерированный первичный ключ) последней строки, вставленной в базу данных с помощью текущего экземпляра SQLConnection. Это значение идентично значению, возвращаемому свойством SQLConnection.lastInsertRowID . |
|
LENGTH(X) |
Возвращает длину строки X (число символов). |
|
LIKE(X, Y [, Z]) |
Эта функция служит для реализации синтаксиса X LIKE Y [ESCAPE Z] в SQL. Если используется необязательное предложение ESCAPE, то функция вызывается с тремя аргументами. В противном случае она вызывается только с двумя аргументами. |
|
LOWER(X) |
Возвращает копию строки X, все символы которой преобразованы в нижний регистр. |
|
LTRIM(X) LTRIM(X, Y) |
Возвращает строку, полученную в результате удаления пробела с левой стороны X. Если указан аргумент Y, функция удаляет все символы в Y, которые находятся с левой стороны от X. |
|
MAX(X, Y, …) |
Возвращает аргумент с максимальным значением. В качестве аргументов могут использоваться как числа, так и строки. Максимальное значение определяется с использованием порядка сортировки по умолчанию. Обратите внимание, что MAX() является простой функцией, когда имеет 2 или более аргументов, но если используется только один аргумент, она работает как агрегатная функция. |
|
MIN(X, Y, …) |
Возвращает аргумент с минимальным значением. В качестве аргументов могут использоваться как числа, так и строки. Минимальное значение определяется с использованием порядка сортировки по умолчанию. Обратите внимание, что MIN() является простой функцией, когда имеет 2 или более аргументов, но если используется только один аргумент, она работает как агрегатная функция. |
|
NULLIF(X, Y) |
Возвращает первый аргумент, если аргументы разные. В противном случае возвращает NULL. |
|
QUOTE(X) |
Эта подпрограмма возвращает строку, которая является значением ее аргумента, пригодного для включения в другую инструкцию SQL. Строки окружены одинарными кавычками. При необходимости для внутренних кавычек применяется маскировка. Классы хранения BLOB кодируются как шестнадцатеричные литералы. Эта функция полезна для обеспечения возможности отмены или повтора действия при создании триггеров. |
|
RANDOM(*) |
Возвращает псевдопроизвольное целое число из диапазона от 9223372036854775808 до 9223372036854775807. Это произвольное значение не обеспечивает надежное шифрование. |
|
RANDOMBLOB(N) |
Возвращает большой двоичный объект размером N байт, который содержит псевдопроизвольные байты. В качестве N должно использоваться положительное целое число. Это произвольное значение не обеспечивает надежное шифрование. Если в N имеет отрицательное значение, возвращается один байт. |
|
ROUND(X) ROUND(X, Y) |
Округляет число X до Y знаков справа от разделителя десятичной дроби. Если аргумент Y опущен, используется значение 0. |
|
RTRIM(X) RTRIM(X, Y) |
Возвращает строку, полученную в результате удаления пробела с правой стороны X. Если указан аргумент Y, функция удаляет все символы в Y, которые находятся с правой стороны от X. |
|
SUBSTR(X, Y, Z) |
Возвращает подстроку вводной строки X, которая начинается с Y-го символа и имеет длину Z символов. Крайний левый символ строки X имеет индекс 1. Если Y является отрицательным числом, первый символ подстроки определяется путем отсчета от правого края, а не левого. |
|
TRIM(X) TRIM(X, Y) |
Возвращает строку, полученную в результате удаления пробела с правой стороны X. Если указан аргумент Y, функция удаляет все символы в Y, которые находятся с правой стороны от X. |
|
TYPEOF(X) |
Возвращает тип выражения X. Возможные возвращаемые значения: null, integer, real, text и blob. Дополнительные сведения о типах данных см. в разделе «Поддержка типов данных». |
|
UPPER(X) |
Возвращает копию вводной строки X, преобразованную в верхний регистр. |
|
ZEROBLOB(N) |
Возвращает большой двоичный объект, содержащий N байт со значением 0x00. |
Функции форматирования даты и времени
Функции форматирования даты и времени представляют собой группу скалярных функций, которые служат для создания форматированных данных даты и времени. Обратите внимание, что эти функции выполняют операции со значениями, содержащими строки и числа, и возвращают соответствующие результаты. Эти функции не предназначены для использования с типом данных DATE. Если их использовать для данных в столбце, для которого объявлен тип данных DATE, они работают некорректно.
|
DATE(T, …) |
Функция DATE() возвращает строку, содержащую дату в формате YYYY-MM-DD (ГГГГ-ММ-ДД). Первый параметр (T) определяет строку времени в формате, описанном в разделе «Форматы времени». После строки времени можно указать любое число модификаторов. Модификаторы перечислены в разделе «Модификаторы». |
|
TIME(T, …) |
Функция TIME() возвращает строку, содержащую время в формате HH:MM:SS (ЧЧ:ММ:СС). Первый параметр (T) определяет строку времени в формате, описанном в разделе «Форматы времени». После строки времени можно указать любое число модификаторов. Модификаторы перечислены в разделе «Модификаторы». |
|
DATETIME(T, …) |
Функция DATETIME() возвращает строку, содержащую дату и время в формате YYYY-MM-DD HH:MM:SS (ГГГГ-ММ-ДД ЧЧ:ММ:СС). Первый параметр (T) определяет строку времени в формате, описанном в разделе «Форматы времени». После строки времени можно указать любое число модификаторов. Модификаторы перечислены в разделе «Модификаторы». |
|
JULIANDAY(T, …) |
Функция JULIANDAY() возвращает число, обозначающее количество дней, прошедшее с полудня по Гринвичу 24 ноября 4714 года до нашей эры, и заданную дату. Первый параметр (T) определяет строку времени в формате, описанном в разделе «Форматы времени». После строки времени можно указать любое число модификаторов. Модификаторы перечислены в разделе «Модификаторы». |
|
STRFTIME(F, T, …) |
Подпрограмма STRFTIME() возвращает дату, отформатированную в соответствии со строкой формата, указанной в качестве первого аргумента F. Строка формата поддерживает следующие подстановки: %d — день месяца %f — дробные секунды SS.SSS %H — час 00-24 %j — день года 001-366 %J — номер дня по юлианскому календарю %m — месяц 01-12 %M — минута 00-59 %s — число секунд с 1970-01-01 %S — секунды 00-59 %w — день недели 0-6 (воскресенье = 0) %W — неделя года 00-53 %Y — год 0000-9999 %% — % Второй параметр (T) определяет строку времени в формате, описанном в разделе «Форматы времени». После строки времени можно указать любое число модификаторов. Модификаторы перечислены в разделе «Модификаторы». |
Форматы времени
Строка времени может иметь любой из перечисленных ниже форматов.
|
YYYY-MM-DD |
2007-06-15 |
|
YYYY-MM-DD HH:MM |
2007-06-15 07:30 |
|
YYYY-MM-DD HH:MM:SS |
2007-06-15 07:30:59 |
|
YYYY-MM-DD HH:MM:SS.SSS |
2007-06-15 07:30:59.152 |
|
YYYY-MM-DDTHH:MM |
2007-06-15T07:30 |
|
YYYY-MM-DDTHH:MM:SS |
2007-06-15T07:30:59 |
|
YYYY-MM-DDTHH:MM:SS.SSS |
2007-06-15T07:30:59.152 |
|
HH:MM |
07:30 (дата 2000-01-01) |
|
HH:MM:SS |
07:30:59 (дата 2000-01-01) |
|
HH:MM:SS.SSS |
07:30:59:152 (дата 2000-01-01) |
|
now |
Текущая дата и время по универсальному времени (UCT). |
|
DDDD.DDDD |
Номер дня по юлианскому календарю, представленный в виде числа с плавающей запятой. |
Символ T в этих форматах является символом литерала «T», который разделяет дату и время. Форматы, которые содержат только время, предполагают дату 2001-01-01.
Модификаторы
После строки времени может следовать ноль или больше модификаторов, которые изменяют дату или ее интерпретацию. Доступные модификаторы перечислены ниже.
|
NNN days |
Число дней, которые требуется добавить ко времени. |
|
NNN hours |
Число часов, которые требуется добавить ко времени. |
|
NNN minutes |
Число минут, которые требуется добавить ко времени. |
|
NNN.NNNN seconds |
Число секунд и миллисекунд, которые требуется добавить ко времени |
|
NNN months |
Число месяцев, которые требуется добавить ко времени. |
|
NNN years |
Число лет, которые требуется добавить ко времени. |
|
start of month |
Смещает время назад к началу месяца. |
|
start of year |
Смещает время назад к началу года. |
|
start of day |
Смещает время назад к началу дня. |
|
weekday N |
Смещает время вперед к указанному дню недели. (0 = воскресенье, 1 = понедельник и т. д.) |
|
localtime |
Преобразует дату в местное время. |
|
utc |
Преобразует дату в универсальное время (UCT). |
Операторы
SQL поддерживает большой набор операторов, включая общие операторы, которые используются в большинстве языков программирования, а также несколько операторов, которые применяются только в SQL.
Общие операторы
В блоках SQL разрешается использовать следующие двоичные операторы, перечисленные в порядке приоритета от самого высокого до самого низкого.
* / % + - << >> & | < >= > >= = == != <> IN AND OR
Ниже перечислены поддерживаемые унарные префиксные операторы.
! ~ NOT
Оператор COLLATE можно рассматривать как унарный постфиксный оператор. Оператор COLLATE имеет самый высокий приоритет. Он всегда обеспечивает более крепкую привязку, чем любой другой унарный префиксный оператор или двоичный оператор.
Обратите внимание, что существует два варианта операторов равенства и неравенства. Равенство может быть выражено как = или ==. В качестве оператора неравенства может использоваться != или <>.
Оператор || является оператором сцепления строк, он объединяет две строки операндов.
Оператор % выводит остаток левого операнда по модулю правого операнда.
Результат любого двоичного оператора является числовым значением, за исключением оператора сцепления ||, результатом которого является строка.
Операторы SQL
LIKE
Оператор LIKE выполняет сравнение для сопоставления с шаблоном.
expr ::= (column-name | expr) LIKE pattern pattern ::= '[ string | % | _ ]'
Операнд справа от оператора LIKE содержит шаблон, а левый операнд содержит строку, которую требуется сравнить с шаблоном. Символ процента (%) в шаблоне является символом подстановки. Он заменяет любую последовательность из нуля или более символов в строке. Символ подчеркивания (_) в шаблоне соответствует любому одному символу в строке. Любой другой символ соответствует самому себе или своему эквиваленту нижнего или верхнего регистра, то есть сопоставление выполняется без учета регистра. (Примечание. Ядро базы данных распознает верхний и нижний регистр только для 7-битовых латинских символов. По этой причине оператор LIKE учитывает регистр для 8-битовых символов iso8859 и для символов UTF-8. Например, выражение ‘a’ LIKE ‘A’ возвращает значение TRUE, а ‘æ’ LIKE ‘Æ’ возвращает FALSE). Чувствительность к регистру латинских символов можно изменить с помощью свойства SQLConnection.caseSensitiveLike.
Если присутствует необязательное предложение ESCAPE, то выражение, следующее за ключевым словом ESCAPE, должно содержать строку, состоящую из одного символа. Этот символ можно использовать в шаблоне LIKE для сопоставления символов процента или прочерка литерала. Символ маскировки, за которым следует символ процента, прочерка или он сам, соответствует символу процента, прочерка или маскировки литерала в строке.
GLOB
Оператор GLOB похож на LIKE, но использует синтаксис глобализации файлов Unix для подстановочных знаков. В отличие от LIKE, оператор GLOB учитывает регистр.
IN
Оператор IN вычисляет, равен ли левый операнд одному из значений в правом операнде (из набора значений в круглых скобках).
in-expr ::= expr [NOT] IN ( value-list ) |
expr [NOT] IN ( select-statement ) |
expr [NOT] IN [database-name.] table-name
value-list ::= literal-value [, literal-value]*
Правый операнд может содержать разделенные запятыми значения литералов или результат инструкции SELECT. Объяснения и ограничения использования инструкции SELECT в качестве правого операнда оператора IN см. в подразделе «Инструкция SELECT» раздела «Выражения».
BETWEEN…AND
Оператор BETWEEN…AND равносилен использованию двух выражений с операторами >= и <=. Например, выражение x BETWEEN y AND z эквивалентно выражению x >= y AND x <= z.
NOT
Оператор NOT выполняет функцию отрицания. Перед операторами GLOB, LIKE и IN может стоять ключевое слово NOT, которое меняет смысл проверки на обратный (другими словами, требуется проверить, что значение не соответствует указанному шаблону).
Параметры
Параметр указывает местозаполнитель в выражении для значения литерала, который заполняется во время выполнения путем присвоения значения в ассоциативный массив SQLStatement.parameters. Параметры могут принимать три формы.
|
? |
Знак вопроса обозначает индексированный параметр. Параметрам присваиваются числовые значения индекса (от нуля) в соответствии с их порядком в инструкции. |
|
:AAAA |
Двоеточие, за которым следует имя идентификатора, сохраняет место для именованного параметра с именем AAAA. Именованные параметры также нумеруются в соответствии с их порядком в инструкции SQL. Во избежание путаницы лучше не смешивать именованные параметры с нумерованными. |
|
@AAAA |
Символ «собака» равносилен двоеточию. |
Неподдерживаемые возможности SQL
Ниже приводится список стандартных элементов SQL, которые не поддерживаются в Adobe AIR.
- Ограничения FOREIGN KEY
- Ограничения FOREIGN KEY подвергаются синтаксическому анализу, но не применяются.
- Триггеры
- Триггеры FOR EACH STATEMENT не поддерживаются (все триггеры должны быть FOR EACH ROW). Триггеры INSTEAD OF не поддерживаются в таблицах (их использование допускается только в видах). Рекурсивные триггеры (то есть те, которые запускают сами себя) не поддерживаются.
- ALTER TABLE
- Поддерживаются только варианты RENAME TABLE и ADD COLUMN команды ALTER TABLE. Другие типы операций ALTER TABLE, такие как DROP COLUMN, ALTER COLUMN, ADD CONSTRAINT и т. д., игнорируются.
- Вложенные транзакции
- Допускается только одна активная транзакция.
- RIGHT и FULL OUTER JOIN
- RIGHT OUTER JOIN и FULL OUTER JOIN не поддерживаются.
- Обновляемый вид
- Виды доступны только для чтения. Для видов нельзя выполнять инструкции DELETE, INSERT или UPDATE. Поддерживается триггер INSTEAD OF, который запускается при попытке удаления, вставки или обновления вида (DELETE, INSERT или UPDATE). С его помощью можно обновлять базовые таблицы в теле триггера.
- GRANT и REVOKE
- База данных представляет собой обычный файл на диске. К ней можно применять только обычные права доступа к файлу, которые поддерживаются существующей операционной системой. Команды GRANT и REVOKE, которые широко используются в клиентских и серверных RDBMS, не реализуются.
Следующие элементы SQL и возможности SQLite поддерживаются в некоторых версиях SQLite, но не поддерживаются в Adobe AIR. Большинство этих возможностей обеспечиваются с помощью методов класса SQLConnection.
- Элементы SQL, связанные с транзакциями (BEGIN, END, COMMIT, ROLLBACK)
- Эти возможности обеспечиваются с помощью методов класса SQLConnection, связанных с транзакциями: SQLConnection.begin(), SQLConnection.commit() и SQLConnection.rollback().
- ANALYZE
- Эта функция обеспечивается с помощью метода SQLConnection.analyze().
- ATTACH
- Эта функция обеспечивается с помощью метода SQLConnection.attach().
- COPY
- Эта инструкция не поддерживается.
- CREATE VIRTUAL TABLE
- Эта инструкция не поддерживается.
- DETACH
- Эта функция обеспечивается с помощью метода SQLConnection.detach().
- PRAGMA
- Эта инструкция не поддерживается.
- VACUUM
- Эта функция обеспечивается с помощью метода SQLConnection.compact().
- Доступ к системным таблицам не поддерживается.
- Системные таблицы, включая sqlite_master и другие таблицы с префиксом «sqlite_», недоступны в инструкциях SQL. Среда выполнения включает API-интерфейс схемы, который обеспечивает объектно-ориентированный метод доступа к данным схемы. Дополнительные сведения см. в описании метода SQLConnection.loadSchema().
- Функции регулярных выражений (MATCH() и REGEX())
- Эти функции недоступны в инструкциях SQL.
Следующие функциональные возможности отличаются во многих версиях SQLite и Adobe AIR.
- Индексированные параметры инструкций
- Во многих версиях параметры инструкций индексируются от единицы. Однако в Adobe AIR параметры инструкции индексируются от нуля (то есть первому параметру присваивается индекс 0, второму — 1 и т. д.).
- Определения столбцов INTEGER PRIMARY KEY
- Во многих версиях в качестве действительного столбца первичного ключа таблицы используются только столбцы, которые явно определены как INTEGER PRIMARY KEY. В таких версиях указание других типов данных, которые являются синонимами INTEGER (например, int), не приводит к тому, что столбец используется в качестве внутреннего первичного ключа. Однако в Adobe AIR тип данных int (или другие синонимы INTEGER) рассматриваются как точное соответствие INTEGER. По этой причине столбец, определенный как int PRIMARY KEY, используется в качестве внутреннего первичного ключа таблицы. Дополнительные сведения см. в разделах «CREATE TABLE» и «Сходство столбцов».
Дополнительные возможности SQL
Следующие типы сходства столбцов по умолчанию в SQLite не поддерживаются, но поддерживаются в Adobe AIR. (Обратите внимание, что, как и во всех ключевых словах в SQL, в этих именах типов данных не учитывается регистр).
- Boolean
- соответствует классу Boolean.
- Date
- соответствует классу Date.
- int
- соответствует классу int (эквивалентно сходству столбца INTEGER).
- Number
- соответствует классу Number (эквивалентно сходству столбца REAL).
- Object
- соответствует классу Object или любому подклассу, сериализацию и десериализацию которого можно выполнить с помощью AMF3. (Сюда относится большинство классов, в том числе пользовательских, кроме некоторых классов, которые включают экранные объекты и объекты и объекты, свойства которых содержат экранные объекты.)
- String
- соответствует классу String (эквивалентно сходству столбца TEXT).
- XML
- соответствует классу XML в ActionScript (E4X).
- XMLList
- соответствует классу XMLList в ActionScript (E4X).
Следующие значения литералов не поддерживаются по умолчанию в SQLite, но поддерживаются в Adobe AIR.
- true
- используется для представления логического значения литерала true, предназначено для работы со столбцами BOOLEAN.
- false
- используется для представления логического значения литерала false, предназначено для работы со столбцами BOOLEAN.
Операторы администрирования данными
|
Оператор |
Действие |
|
DECLARE |
Определяет |
|
OPEN |
Открывает |
|
FETH |
Устанавливает |
|
CLOSE |
Закрывает |
|
PREPARE |
Генерирует |
|
EXECUTE |
Выполняет |
[WHERE
(Условия
отбора данных)]
[GROUP
BY
(Список полей, выводимых в результат
выполнения запроса)]
[HAVING
(Условия для группировки данных в
запросе)]
[ORDER
BY
(Список полей, по которым упорядочивается
вывод данных в запросе)]
В
рассмотренной структуре инструкции
SELECT
ALL
ключевое
слово, которое означает, что в результирующий
набор записей
включаются все записи таблицы или
запроса, которые удовлетворяют
условиям запроса.
Ключевые
слова могут отсутствовать в запросе.
-
Основные группы
операторов языка запросов SQL.
В
зависимости от характера выполняемых
действий операторы SQL
можно разделить на следующие группы:
-
операторы
определения данных; -
операторы
манипулирования данными; -
операторы
(язык) запросов; -
операторы
управления действиями (транзакциями); -
операторы
администрирования данными; -
операторы
управления (управления курсором).
47.
Назначение и возможности программы MS
SQL
Server
7.0.
SQL
Server
7.0 предназначен для локальных баз данных
и для баз данных масштаба предприятия
( когда имеются сотни пользователей и
миллионы строк данных. SQL
Server
7.0 может работать как под управлением
операционной системы Windows
NT,
так и под управлением Windows
95/98. Программа SQL
Server
7.0 позволяет облегчить работу администратора
БД и упростить процесс разработки и
сопровождения баз данных.
-
Динамическое
самоуправление SQL
Server.
SQL
Server
7.0 облегчает администрирование сервера,
обеспечивая для некоторых параметров
конфигурации режим автоматического
конфигурирования. Сервер отслеживает
потребность в тех или иных ресурсах и
динамически изменяет параметры своей
настройки. Например, если одна из баз
данных больше не больше
не используется и автоматически
закрывается сервером,
то требования к оперативной памяти и
процессорному
времени снижаются. При использовании
статических
значений для конфигурирования сервера
неиспользуемые ресурсы
все равно будут зарезервированы
операционной SQL
Server
и не могут быть использованы другими
приложениями. В режиме автоматического
конфигурирования SQL
Server
будет возвращать неиспользуемые ресурсы
операционной системе, что увеличит
производительность как самой системы,
так и прикладных программ. В результате
выполнения операций вставки и удаления
объем памяти, занимаемый базой данных,
постоянно меняется. Диспетчер блокировок
в программе SQL
Server
динамически управляет объемом используемых
им ресурсов при работе с большими базами
данных,
что избавляет администратора от
необходимости вручную изменять
параметры конфигурирования сервера.
Возможность
автоматического конфигурирования
особенно полезна при реализации SQL
Server
на небольших системах, таких как ноутбук.
При этом пользователь может более
продуктивно работать
с продуктом, не беспокоясь о конфигурировании
сервера. Если вы чувствуете себя
достаточно опытным администратором,
который не боится трудностей, то можете
отказаться от автоматического
управления SQL
Server.
В этом случае вы получите полный
контроль над конфигурированием системы.
-
Обработчик
запросов.
В
обработчике запросов SQL
Server
7.0 были
реализованы новые методы поиска,
повышающие скорость обработки
комплексных запросов. В отличие от
предыдущей версии,
в которой использовался единственный
метод соединения при
помощи вложенных циклов, обработчик
запросов SQL
Server
7.0 использует методы реляционного
соединения одинаково хэшированных
отношений (hash
join),
реляционного соединения отсортированных
отношений слиянием (merge
join)
и агрегирования на основе хэширования
(hash
aggregation).
Причем внутри одного
запроса могут использоваться различные
методы соединения. Перед
тем как приступить к извлечению данных
из таблиц, их можно
предварительно отфильтровать. Это стало
возможным благодаря тому, что SQL
Server
использует технику пересечения и
объединения
индексов для таблиц с несколькими
индексами. Все индексы
для одной таблицы ведутся одновременно,
а учет ограничений
включается в план выполнения запроса.
SQL
Server
поддерживает параллельное выполнение
запросов. Если
сервер имеет несколько процессоров, то
выполнение запроса
будет равномерно распределено между
ними. SQL
Server
сам решает,
когда параллельное выполнение запроса
приведет к увеличению
скорости его обработки, и составляет
план выполнения запроса.
В
новой версии SQL
Server
реализована поддержка распределенных
транзакций, что позволяет включать в
один запрос удаленные
серверы. Обработчик запросов использует
технологию OLE
DB
для взаимодействия с другими источниками
данных. Это обеспечивает
более тесную интеграцию с другими
продуктами Microsoft
и облегчает процесс разработки приложений
для SQL
Server.
-
Поддержка
баз данных больших объемов.
Предыдущие
версии SQL
Server
поддерживали базы данных объемом до
300 Мбайт, SQL
Server
7.0 может работать с базами объемом в
несколько терабайт. В этой версии
реализована поддержка стандарта записи
на магнитную ленту Microsoft
Tape
Format.
Это позволяет использовать общее
устройство
резервного копирования для хранения
архивов SQL
Server
и
архивов операционной системы.
-
Система
безопасности SQL
Server.
В
новой версии SQL
Server
реализуется более плотная интеграция
с Windows
NT.
Для этого можно создавать роли,
включая в них не только учетные записи
Г,
но и собственные учетные записи SQL
Server.
Пользователь может
быть участником многих ролей, что
позволяет более эффективно
управлять доступом к отдельным объектам
баз даных. Появились новые
стандартные роли, обеспечивающие более
гибкое распределение
полномочий среди персонала, обслуживающего
сервер.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #