Результатом выполнения оператора SELECT является таблица. К этой таблице может быть снова применен оператор SELECT и т.д., то есть такие операторы могут быть вложены друг в друга. Вложенные операторы SELECT называют подзапросами.
Синтаксис оператора SELECT использует следующие основные предложения:
SELECT <список столбцов>
FROM <список таблиц>
[WHERE <условие выбора строк>]
[GROUP BY <условие группировки>]
[HAVING <условие выбора групп>]
[ORDER BY <условие сортировки>]Кратко пояснить смысл предложений оператора SELECT можно следующим образом:
SELECT— выбрать данные из указанных столбцов и (если необходимо) выполнить перед выводом их преобразование в соответствии с указанными выражениями и (или) функциямиFROM— из перечисленных таблиц, в которых расположены эти столбцыWHERE— где строки из указанных таблиц должны удовлетворять указанному перечню условий отбора строкGROUP BY— группируя по указанному перечню столбцов с тем, чтобы получить для каждой группы единственное значениеHAVING— имея в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора группORDER BY— сортируя по указанному перечню столбцов
Как видно из синтаксиса рассматриваемого оператора, обязательными являются только два первых предложения: SELECT и FROM.
Рассмотрим каждое предложение оператора SELECT.
Спонсор поста
База данных для примеров
Дальше будет много примеров и логично постоянно использовать одну и ту же БД. Так что на основании базы данных ниже будут продемонстрированы все примеры, не только в этой статье, но и в других.
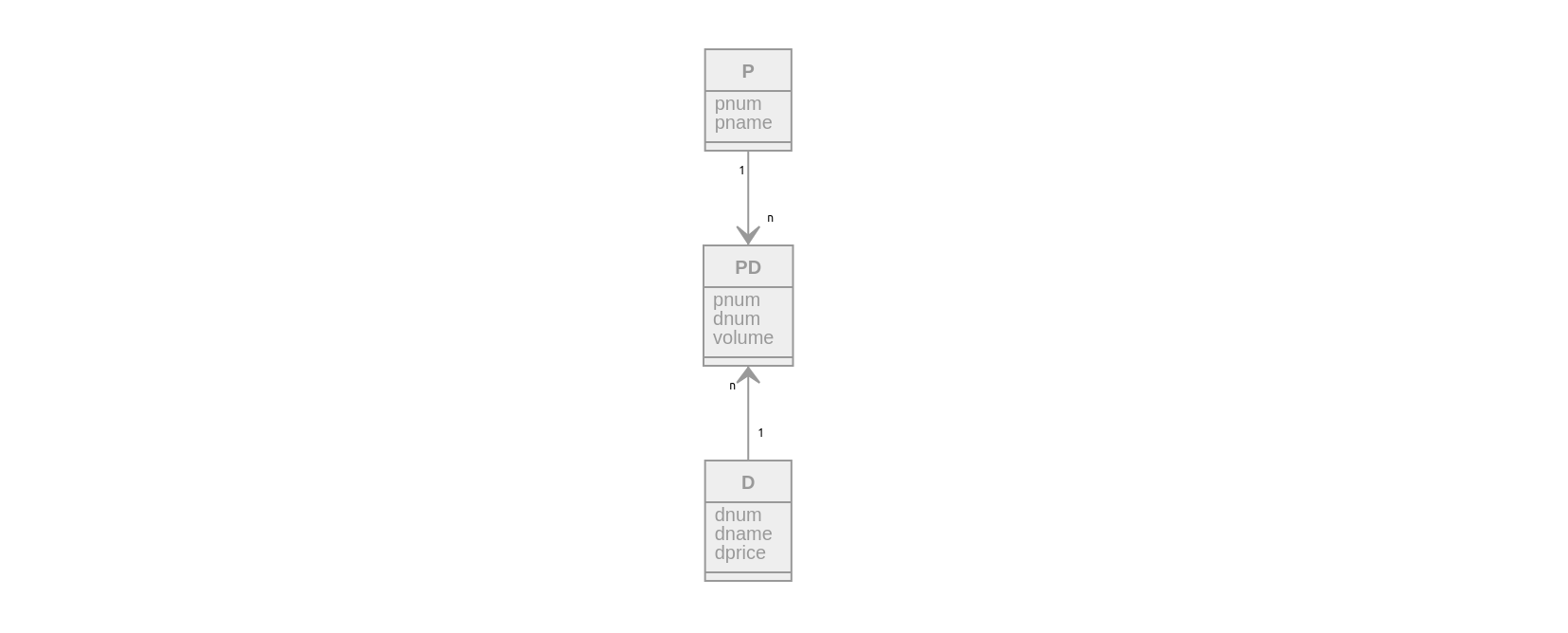
Постановка задачи: пусть требуется разработать БД для предметной области «Поставка деталей»!
Требуется хранить следующую информацию:
- О поставщиках (P) pnum, pname
- О деталях (D) pnum, dname, dprice
- О поставках (PD) volume
Значения таблицы P
| pnum | pname |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| 3 | Сидоров |
| 4 | Кузнецов |
Значения таблицы D
| pnum | dname | dprice |
|---|---|---|
| 1 | Болт | 10 |
| 2 | Гайка | 20 |
| 3 | Винт | 30 |
Значения таблицы PD
| pnum | dnum | volume |
|---|---|---|
| 1 | 1 | 100 |
| 1 | 2 | 100 |
| 1 | 3 | 300 |
| 2 | 1 | 150 |
| 1 | 2 | 250 |
| 3 | 1 | 1000 |
После служебного слова SELECT перечисляются имена столбцов, значения которых будут входить в результат выполнения запроса.
Столбцы в результирующей таблице размещаются в том порядке, в котором они были указаны в предложении SELECT. Имена столбцов указываются через запятую.
Если имя столбца содержит пробелы или разделители, то его необходимо заключить в квадратные скобки.
При обработке данных из разных таблиц может возникнуть ситуация, когда столбцы разных таблиц имеют одинаковые имена. В этом случае имя столбца необходимо записывать как составное, указывая перед ним имя соответствующей таблицы: <Имя таблицы>.<Имя столбца>
Предложение FROM
В предложении FROM перечисляются имена таблиц, которые содержат столбцы, указанные после слова SELECT.
Пример 1.
Вывести список наименований деталей из таблицы D (“Детали”).
SELECT dname
FROM DПример 2.
Получить всю информацию из таблицы D (“Детали”).
Получить результат можно двумя способами:
-
Явным указанием всех столбцов таблицы.
SELECT dnum, dname, dprice FROM D -
Полный список столбцов таблицы заменяет символ
*.SELECT * FROM D
В результате и первого и второго запроса получаем новую таблицу, представляющую собой полную копию таблицы D (“Детали”).
Можно осуществить выбор отдельных столбцов и их перестановку.
Пример 3.
Получить информацию о наименовании и номере поставщика.
SELECT pname, pnum
FROM PПример 4.
Определить номера поставщиков, которые поставляют детали в настоящее время (то есть номера тех поставщиков, которые присутствуют в таблице PD (“Поставки”)).
SELECT pnum
FROM PDРезультат:
| pnum |
|---|
| 1 |
| 1 |
| 1 |
| 2 |
| 2 |
| 3 |
Дополнительно о SELECT
Теперь, когда мы научились делать простые запросы с SELECT и FROM, можно ненадолго снова вернуться к SELECT.
Агрегатные функции
В операторе SELECT можно использовать агрегатные функции, которые дают единственное значение для целой группы строк в таблице.
Агрегатная функция записывается в следующем виде: <имя функции>(<имя столбца>)
Пользователю доступны следующие агрегатные функции:
SUM‑ вычисляет сумму множества значений указанного столбца;COUNT‑ вычисляет количество значений указанного столбца;MIN/MAX‑ определяет минимальное/максимальное значение в указанном столбце;AVG‑ вычисляет среднее арифметическое значение множества значений столбца;FIRST/LAST‑ определяет первое/последнее значение в указанном столбце.
Пример 5.
Определить общий объем поставляемых деталей.
SELECT SUM(volume)
FROM PD| Expr1000 |
|---|
| 2000 |
Вычисляемые столбцы
Столбцы результирующей таблицы, которых не существовало в исходных таблицах, называются вычисляемыми. Таким столбцам СУБД присваивает системные имена, что не всегда является удобным.
При вычислении результатов любой агрегатной функции СУБД сначала исключает все NULL-значения, после чего требуемая операция применяется к оставшимся значениям.
Для функции COUNT возможен особый вариант использования — COUNT(*). Его назначение состоит в подсчете всех строк в результирующей таблице, включая NULL-значения.
Следует запомнить, что агрегатные функции нельзя вкладывать друг в друга. Такая конструкция работать не будет: MAX(SUM(VOLUME))
Переименование столбца
Язык SQL позволяет задавать новые имена столбцам результирующей таблицы, для чего используется операция AS. Переименование также используют для изменения сложных имен столбцов таблицы.
Например, присвоить новое имя вычисляемому столбцу в предыдущем примере позволит выполнение следующего запроса.
SELECT SUM(volume) AS SUM
FROM PD| Sum |
|---|
| 2000 |
Пример 6.
Определить количество поставщиков, которые поставляют детали в настоящее время.
SELECT COUNT(pnum) AS COUNT
FROM PD| Count |
|---|
| 6 |
Несмотря на то, что реальное число поставщиков деталей в таблице PD равно 3, СУБД возвращает число 6. Такой результат объясняется тем, что СУБД подсчитывает все строки в таблице PD, не обращая внимание на то, что в строках есть одинаковые значения.
Операция DISTINCT
Если до применения агрегатной функции необходимо исключить дублирующиеся значения, следует перед именем столбца указать ключевое слово DISTINCT.
SELECT COUNT(DISTINCT pnum) AS COUNT
FROM PD| Count |
|---|
| 3 |
DISTINCT можно задать только один раз для одного предложения SELECT.
Противоположностью DISTINCT является операция ALL. Она имеет противоположное действие «показать все строки таблицы» и предполагается по умолчанию.
Операция TOP
Итоговый набор записей, получаемых после выполнения запроса можно ограничить первыми N строками или первыми N процентами от общего количества строк результата.
Для этого используется операция TOP, которая записывается в предложении SELECT следующим образом: SELECT TOP N [PERCENT] <список столбцов>
Пример 7.
Определить номера первых двух деталей таблицы D.
SELECT TOP 2 dnum
FROM DСтандарт SQL требует, чтобы при сортировке NULL-значения трактовались либо как превосходящие, либо как уступающие по сравнению со всеми остальными значениями. Так как конкретный вариант стандартом не оговаривается, то в зависимости от используемой СУБД при сортировке NULL-значения следуют до или после остальных значений. В MS SQL Server NULL-значения считаются уступающими по сравнению с остальными значениями.
Предложение WHERE
После служебного слова WHERE указываются условия выбора строк, помещаемых в результирующую таблицу. Существуют различные типы условий выбора:
Типы условий выбора:
- Сравнение значений атрибутов со скалярными выражениями, другими атрибутами или результатами вычисления выражений.
- Проверка значения на принадлежность множеству.
- Проверка значения на принадлежность диапазону.
- Проверка строкового значения на соответствие шаблону.
- Проверка на наличие
null-значения.
Сравнение
В языке SQL используются традиционные операции сравнения =,<>,<,<=,>,>=.
В качестве условия в предложении WHERE можно использовать сложные логические выражения, использующие атрибуты таблиц, константы, скобки, операции AND, OR, отрицание NOT.
Пример 8.
Определить номера деталей, поставляемых поставщиком с номером 2.
SELECT dnum
FROM PD
WHERE pnum = 2Пример 9.
Получить информацию о поставщиках Иванов и Петров.
SELECT *
FROM P
WHERE pname='Иванов' OR pname='Петров'Строковые значения атрибутов заключаются в апострофы.
Проверка на принадлежность множеству
Операция IN проверяет, принадлежит ли значение атрибута заданному множеству.
Пример 10.
Получить информацию о поставщиках ‘Иванов’ и ‘Петров’.
SELECT *
FROM P
WHERE pname IN ('Иванов','Петров')Пример 11.
Получить информацию о деталях с номерами 1 и 2.
SELECT *
FROM D
WHERE dnum IN (1, 2)Проверка на принадлежность диапазону
Операция BETWEEN определяет минимальную и максимальную границу диапазона, в которое должно попадать значение атрибута. Обе границы считаются принадлежащими диапазону.
Пример 12.
Определить номера деталей, с ценой от 10 до 20 рублей.
SELECT dnum
FROM D
WHERE dprice BETWEEN 10 AND 20Пример 13.
Вывести наименования поставщиков, начинающихся с букв от ‘К’ по ‘П’.
SELECT pname
FROM P
WHERE pname BETWEEN 'К' AND 'Р'Сравнение символов
Буква Р в условии запроса объясняется тем, что строки сравниваются посимвольно. Для каждого символа при этом определяется код. Для нашего случая справедливо условие: П < Петров < Р
Проверка строкового значения на соответствие шаблону
Операция LIKE используется для поиска подстрок. Значения столбца, указываемого перед служебным словом LIKE сравниваются с задаваемым после него шаблоном. Форматы шаблонов различаются в конкретных СУБД.
Для СУБД MS SQL Server:
- Символ
%заменяет любое количество любых символов. - Символ
_заменяет один любой символ. [<множество символов>]‑ вместо символа строки может быть подставлен один любой символ из множества возможных, указанных в ограничителях.[^<множество символов>]‑ вместо символа строки может быть подставлен любой из символов кроме символов из множества, указанного в ограничителях.
Множество символов в квадратных скобках можно указывать через запятую, либо в виде диапазона.
Пример 14.
Вывести фамилии поставщиков, начинающихся с буквы И.
SELECT pname
FROM P
WHERE pname LIKE 'И%'Пример 15.
Вывести фамилии поставщиков, начинающихся с букв от К по П.
SELECT pname
FROM P
WHERE dname LIKE '[К-П]%'Проверка на наличие null-значения
Операции IS NULL и IS NOT NULL используются для сравнения значения атрибута со значением NULL.
Пример 16.
Определить наименования деталей, для которых не указана цена.
SELECT dname
FROM D
WHERE dprice IS NULLПример 17.
Определить номера поставщиков, для которых указано наименование.
SELECT pnum
FROM P
WHERE pname IS NOT NULLПредложение GROUP BY
Использование GROUP BY позволяет разбивать таблицу на логические группы и применять агрегатные функции к каждой из этих групп. В результате получим единственное значение для каждой группы.
Обычно предложение GROUP BY применяют, если формулировка задачи содержит фразу «для каждого…», «каждому..» и т.п.
Пример 18.
Определить суммарный объем деталей, поставляемых каждым поставщиком.
SELECT pnum, SUM(VOLUME) AS SUM
FROM PD
GROUP BY pnum| pnum | sum |
|---|---|
| 1 | 600 |
| 2 | 400 |
| 3 | 1000 |
Выполнение запроса можно описать следующим образом: СУБД разбивает таблицу PD на три группы, в каждую из групп помещаются строки с одинаковым значением номера поставщика. Затем к каждой из полученных групп применяется агрегатная функция SUM, что дает единственное итоговое значение для каждой группы.
Рассмотрим два похожих примера. В примере 19 определяется минимальный объем поставки каждого поставщика. В примере 20 определяется объем минимальной поставки среди всех поставщиков.
Пример 19:
SELECT pnum, MIN(VOLUME) AS MIN
FROM PD
GROUP BY pnumПример 20:
SELECT MIN(VOLUME) AS MIN
FROM PРезультаты запросов представлены в следующей таблице:
| pnum | min | max |
|---|---|---|
| 1 | 100 | 100 |
| 2 | 150 | |
| 3 | 1000 |
Следует обратить внимание, что в первом примере мы можем вывести номера поставщиков, соответствующие объемам поставок, а во втором примере – не можем.
Все имена столбцов, перечисленные после ключевого слова SELECT должны присутствовать и в предложении GROUP BY, за исключением случая, когда имя столбца является аргументом агрегатной функции.
Однако в предложении GROUP BY могут быть указаны имена столбцов, не перечисленные в списке вывода после ключевого слова SELECT.
Если предложение GROUP BY расположено после предложения WHERE, то группы создаются из строк, выбранных после применения WHERE.
Пример 21.
Для каждой из деталей с номерами 1 и 2 определить количество поставщиков, которые их поставляют, а также суммарный объем поставок деталей.
SELECT dnum, COUNT(pnum) AS COUNT, SUM(volume) AS SUM
FROM PD
WHERE dnum=1 OR dnum=2
GROUP BY dnumРезультат запроса:
| dnum | COUNT | SUM |
|---|---|---|
| 1 | 3 | 1250 |
| 2 | 2 | 450 |
Чтобы организовать вложенные группировки, после GROUP BY следует указать несколько группирующих столбцов через запятую. В этом случае реальный подсчет данных будет происходить по той группе, которая указана последней.
Предложение HAVING
Предложение HAVING определяет критерий, согласно которому, определенные группы, сформированные с помощью предложения GROUP BY, исключаются из результирующей таблицы.
Выполнение предложения HAVING сходно с выполнением предложения WHERE. Но предложение WHERE исключает строки до того, как выполняется группировка, а предложение HAVING — после. Поэтому предложение HAVING может содержать агрегатные функции, а предложение WHERE — не может.
Пример 22.
Определить номера поставщиков, поставляющих в сумме более 500 деталей.
SELECT pnum, SUM(volume) AS SUM
FROM PD
GROUP BY pnum
HAVING SUM(volume) > 500| pnum | SUM |
|---|---|
| 1 | 600 |
| 3 | 1000 |
Пример 23.
Определить номера поставщиков, которые поставляют только одну деталь.
SELECT pnum, COUNT(dnum) AS COUNT
FROM PD
GROUP BY pnum
HAVING COUNT(dnum) = 1| pnum | SUM |
|---|---|
| 3 | 1 |
Предложение ORDER BY
При выполнении запроса СУБД возвращает строки в случайном порядке. Предложение ORDER BY позволяет упорядочить выходные данные запроса в соответствии со значениями одного или нескольких выбранных столбцов.
Можно задать возрастающий — ASC (от слова Ascend) или убывающий — DESC (от слова Descend) порядок сортировки. По умолчанию принят возрастающий порядок сортировки.
Пример 24.
Отсортировать таблицу PD в порядке возрастания номеров поставщиков, а строки с одинаковыми значениями pnum отсортировать в порядке убывания объема поставок.
SELECT pnum, volume, dnum
FROM PD
ORDER BY pnum ASC, volume DESC| pnum | volume | dnum |
|---|---|---|
| 1 | 300 | 3 |
| 1 | 200 | 2 |
| 1 | 100 | 1 |
| 2 | 250 | 2 |
| 2 | 150 | 1 |
| 3 | 1000 | 1 |
Операцию TOP удобно применять после сортировки результирующего набора с помощью предложения ORDER BY.
Пример 25.
Определить номера первых двух деталей с наименьшей стоимостью.
SELECT TOP 2 dnum
FROM D
ORDER BY dprice ASCСледует отметить, что если в таблице D будут две детали без указания цены, то именно их и отобразит предыдущий запрос. Поэтому при наличии NULL-значений их необходимо исключать с помощью предложения WHERE.
SELECT TOP 2 dnum
FROM D
WHERE dprice IS NOT NULL
ORDER BY dprice ASCЗаключение
В статье было рассмотрен оператор выборки SELECT. Знание оператора SELECT является ключевым при написании любых SQL-запросов. Он позволяет производить выборку данных из таблиц и преобразовывать результаты в соответствии с нужными выражениями и функциями.
Результатом выполнения оператора SELECT является таблица, которую можно вложить в другой оператор SELECT в качестве подзапроса.
Синтаксис оператора SELECT содержит несколько предложений, из которых обязательными являются только SELECT и FROM. Остальные предложения, такие как WHERE, GROUP BY, HAVING и ORDER BY, могут использоваться по желанию для уточнения выборки данных.
Ситуация, когда требуется сделать выборку по определённому условию,
встречается очень часто. Для этого в операторе SELECT существует оператор WHERE, после которого следуют
условия для ограничения строк. Если запись удовлетворяет этому условию, то
попадает в результат, иначе отбрасывается.
Общая структура запроса с оператором WHERE
SELECT [DISTINCT] поля_таблиц FROM наименование_таблицы WHERE условие_на_ограничение_строк [логический_оператор другое_условие_на_ограничение_строк];Например, запрос с использованием оператора WHERE может выглядеть следующим образом:
SELECT * FROM Student WHERE first_name = "Grigorij" AND YEAR(birthday) > 2000;В нем используются:
- два оператора сравнения
first_name = «Grigorij» и YEAR(birthday) > 2000; - один логический оператор AND
Как результат, в выборке мы получаем данные студентов, которые имеют имя «Grigorij» и в тоже время чей год рождения больше 2000.
Операторы сравнения
Операторы сравнения служат для сравнения 2 выражений, результатом которого может являться:
- true (что эквивалентно 1)
- false (что эквивалентно 0)
- NULL
Результатом сравнения любого значения с NULL является NULL. Исключением является оператор эквивалентности.
Попробуйте выполнить запрос и самостоятельно поиграться с этими операторами в песочнице:
SELECT 2 = 1, 'a' = 'a', NULL <=> NULL, 2 <> 2, 3 < 4, 10 <= 10, 7 > 1, 8 >= 10;Логические операторы
Логические операторы необходимы для связывания операторов сравнения.
Давайте для примера выведем все полёты, которые были совершены на самолёте «Boeing», но, при этом, вылет был не из Лондона:
SELECT * FROM Trip WHERE plane = 'Boeing' AND NOT town_from = 'London';
SELECT WHERE
Если в табличном выражении присутствует раздел WHERE, то следующим вычисляется он.
Условие, следующее за ключевым словом WHERE, может включать предикат условия поиска, булевские операторы AND (и), OR (или) и NOT(нет) и скобки, указывающие требуемый порядок вычислений.
Вычисление раздела WHERE производится по следующим правилам: Пусть R — результат вычисления раздела FROM. Тогда условие поиска применяется ко всем строкам R, и результатом раздела WHERE является таблица SQL, состоящая из тех строк R, для которого результатом вычисления условия поиска является true. Если условие выборки включает подзапросы, то каждый подзапрос вычисляется для каждого кортежа таблицы R (в стандарте используется термин “effectively” в том смысле, что результат должен быть таким, как если бы каждый подзапрос действительно вычислялся заново для каждого кортежа R).
Среди предикатов условия поиска в соответствии со стандартом могут находиться следующие предикаты: предикат сравнения, предикат between, предикат in, предикат like, предикат null, предикат с квантором и предикат exists.
При проверке условия выборки числа сравниваются алгебраически: отрицательные числа считаются меньше, чем положительные, независимо от их абсолютной величины. Строки сравниваются в соответствии с их представлением в коде ANSI. При сравнении двух строк, имеющих разные длины, предварительно более короткая строка дополняется справа пробелами для того, чтобы обе строки имели одинаковую длину.
Предикат сравнения с выражениями или результатами подзапроса. Условие определяется из двух выражений, разделенных одним из знаков операции отношения: =, <>(не равно), >, >=, < и <=.
Арифметические выражения левой и правой частей предиката сравнения строятся по общим правилам построения арифметических выражений и могут включать в общем случае имена столбцов таблиц из раздела FROM и константы. Типы данных арифметических выражений должны быть сравнимыми (например, если тип столбца a таблицы A является типом символьных строк, то предикат “a = 5” недопустим).
Если правый операнд операции сравнения задается подзапросом, то дополнительным ограничением является то, что мощность результата подзапроса должна быть не более единицы. Если хотя бы один из операндов операции сравнения имеет неопределенное значение, или если правый операнд является подзапросом с пустым результатом, то значение предиката сравнения равно unknown.
Для обеспечения переносимости прикладных программ нужно внимательно оценивать специфику работы с неопределенными значениями в конкретной СУБД.
Примеры выборки SELECT с разделом WHERE
SELECT WHERE. Пример 1.
Выборка кода и фамилии покупателей, проживающих в Москве.
SELECT CUSTOMERNO, FIRSTNAME, LASTNAME FROM CUSTOMER WHERE CITY = ‘Москва’;
SELECT WHERE. Пример 2.
Выборка из таблицы emp данных по служащим отдела с номером 40:
SELECT * FROM emp WHERE deptno = 40;
SELECT WHERE. Пример 3.
Извлечение из таблицы записи с полями имя, должность, размер оклада и номер отдела для всех служащих за исключением продавцов из отдела с номером 30:
SELECT ename, job, sal, deptno FROM emp WHERE NOT deptno = 30;
В этой статье вы научитесь выбирать данные из таблицы с определенным условием с помощью WHERE.
В предыдущей статье мы узнали, как получить все записи из таблицы или столбцов таблицы. Но в реальном мире обычно нужно выбрать, обновить или удалить только те записи, которые удовлетворяют определенным условиям. Например, могут понадобиться только пользователи, принадлежащие к определенной возрастной группе, живущие в определенной стране и т.д.
Условие WHERE используется с операторами SELECT, UPDATE и DELETE. В этой статье мы остановимся на использовании WHERE с SELECT.
Синтаксис
Условие WHERE используется с оператором SELECT для извлечения только тех записей, которые удовлетворяют заданным условиям.
Базовый синтаксис выглядит так:
SELECT список_столбцов FROM имя_таблицы WHERE условие;
список_столбцов — это имена столбцов/полей, таких как имя, возраст, страна и т.д. таблицы базы данных, значения которых вы хотите получить.
Если вам нужны значения из всех столбцов, имеющихся в таблице, можете использовать следующий синтаксис:
SELECT * FROM имя_таблицы WHERE условие;
Операторы для условий
Для условий используются операторы сравнения: =, !=, >, <, >= и <=.
| Оператор | Описание | Пример |
|---|---|---|
= |
Равно | WHERE id = 2 |
> |
Больше чем | WHERE age > 30 |
< |
Меньше чем | WHERE age < 18 |
>= |
Больше или равно | WHERE rating >= 4 |
<= |
Меньше или равно | WHERE price <= 100 |
LIKE |
Сопоставление паттерна | WHERE name LIKE 'An' |
IN |
Проверяет, совпадает ли указанное значение с любым значением в списке или подзапросе | WHERE country IN ('RUSSIA', 'BELARUS') |
BETWEEN |
Проверяет, находится ли указанное значение в данном диапазоне значений | WHERE rating BETWEEN 3 AND 5 |
Используем WHERE
В прошлой статье мы тренировались на датасете Austin_Animal_Center_Intakes.csv (Google Disc →). Скачайте и установите таблицу в свою СУБД.
Допустим, мы хотим узнать все месяцы, в которых было принято более 1 000 особей одного вида животных. Это поможет сделать следующий SQL-запрос:
SELECT year,
month,
animal_type,
count
FROM austin_animal_center_intakes_by_month
WHERE COUNT > 1000
Результат:
| year | month | animal_type | count |
|---|---|---|---|
| 2016 | 5 | Dog | 1,020 |
| 2015 | 5 | Cat | 1,009 |
| 2015 | 6 | Cat | 1,103 |
| 2015 | 6 | Dog | 1,014 |
Вы также можете использовать WHERE с = и != для ограничения результатов для текстовых полей. Например, если нужно просмотреть информацию только о кошках, взятых в центр животных Остина, можно выполнить такой запрос:
SELECT year,
month,
count,
animal_type
FROM austin_animal_center_intakes_by_month
WHERE animal_type = "Cat"
Примечаение. Для числовых значений сравниваемое число (1000 в первом примере) не заключено в кавычки. При сравнении текстовых строк сравниваемый текст должен быть заключен в двойные кавычки («Cat» во втором примере). Запросы с текстовыми строками также чувствительны к регистру. Если выполнить второй запрос с «cat» вместо «Cat», то SQL ничего не найдет.
Результат:
| year | month | count | animal_type |
|---|---|---|---|
| 2013 | 10 | 542 | Cat |
| 2015 | 11 | 488 | Cat |
| 2015 | 12 | 320 | Cat |
| 2016 | 1 | 304 | Cat |
| 2016 | 2 | 279 | Cat |
| 2014 | 1 | 335 | Cat |
| 2016 | 3 | 333 | Cat |
Примечание. Результаты запросов с использованием символов >, <, >= и <= для столбцов со строковыми значениями могут оказаться неожиданными. Текстовые строки рассматриваются как числа с алфавитным порядком — больше строка или меньше определяется именно по нему. Если мы выполним запрос к таблице Intakes для всех типов животных
> "Cat", результаты будут включать всех собак («Dog» > «Cat»), диких животных («Wildlife» > «Cat») и других животных («Other» > «Cat»), но не кошек («Cat» > «Cat» → false, т. к. «Cat» = «Cat»).
Время на прочтение
5 мин
Количество просмотров 1.2M
Подписаться в telegram: t.me/korocheproduct
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM CustomersВыбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM CustomersWHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers
WHERE City = 'London'Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers
GROUP BY CityГруппировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers
GROUP BY Country, CityГруппировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails
GROUP BY ProductIDГруппировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers
WHERE Country = 'Germany'
GROUP BY CityПереименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers
group by CityHAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers
group by City
HAVING count(CustomerID) >= 5 В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers
group by City
HAVING number_of_clients >= 5Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers
ORDER BY CityОсуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers
ORDER BY Country, CityПо умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers
order by CustomerID DESCОбратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers
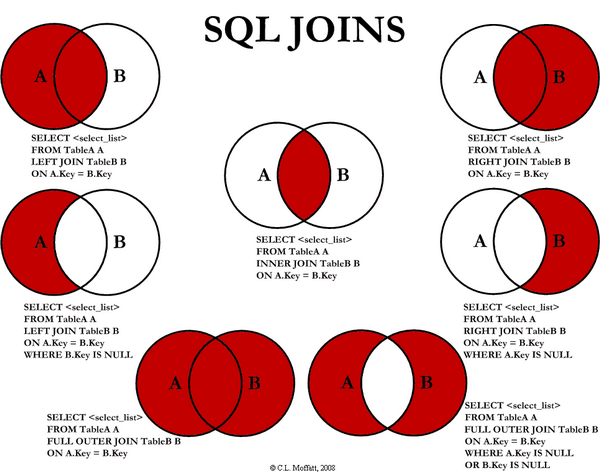
order by Country DESC, CityJOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders
JOIN Customers ON Orders.CustomerID = Customers.CustomerIDНередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders
join Customers on Orders.CustomerID = Customers.CustomerID
where Customers.CustomerID >10Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:
В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!